
변수 분포 문제
일반화된 모델을 학습하는데 어려움이 있는 분포를 가지는 변수가 있어, 일반화된 모델을 학습하지 못하는 문제 발생.
문제 정의
모델링에 있어 가장 적합한 확률 분포는 정규 분포이나 실제 데이터는 변수가 특정 방향으로 치우쳐 있는 경우가 많다.
한 쪽으로 치우친 변수에서 치우친 반대 방향의 값(꼬리 부분)들이 이상치처럼 작용할 수 있으므로 이 치우침을 제거할 필요가 있다.
왜도
변수 치우침을 확인하기 적절한 척도로는 왜도(skewness)가 있다.
왜도는 분포의 비대칭도(보통 절대값이 1.5 이상)를 나타내는 통계량이다.
scipy.stats
- mode : 최빈값 구하는 함수
- skew : 왜도를 구하는 함수
- kurtosis : 첨도를 구하는 함수
변수 치우침 제거
변수 치우침을 해결하는 기본 아이디어는 값 간 차이를 줄어는 것.
- 왜도의 절대값이 1.5 이상의 데이터 제거/치환
- 로그와 루트 등 활용
실습
데이터 확인
다음과 같은 데이터로 실습을 해보자.
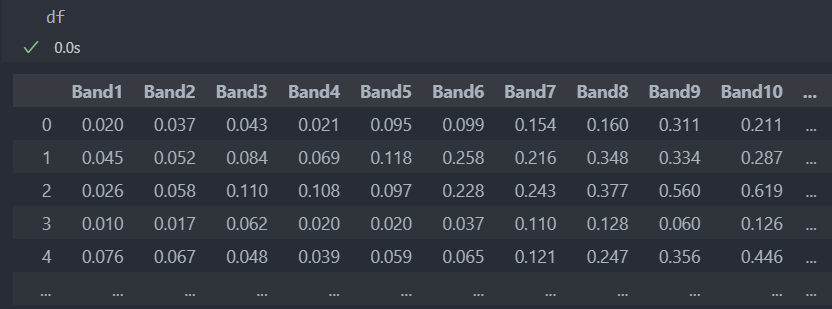
먼저 데이터를 data/label, 학습/평가 데이터로 나누자.
# 특징과 라벨 분리
X = df.drop('Y', axis = 1)
Y = df['Y']
# 학습 데이터와 평가 데이터로 분리
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)
# 학습을 위해 라벨을 문자에서 숫자로 바꿔야 한다.
Train_Y.replace({"M":-1, "R":1}, inplace = True)
Test_Y.replace({"M":-1, "R":1}, inplace = True)그리고 각 컬럼별 왜도를 살펴보고
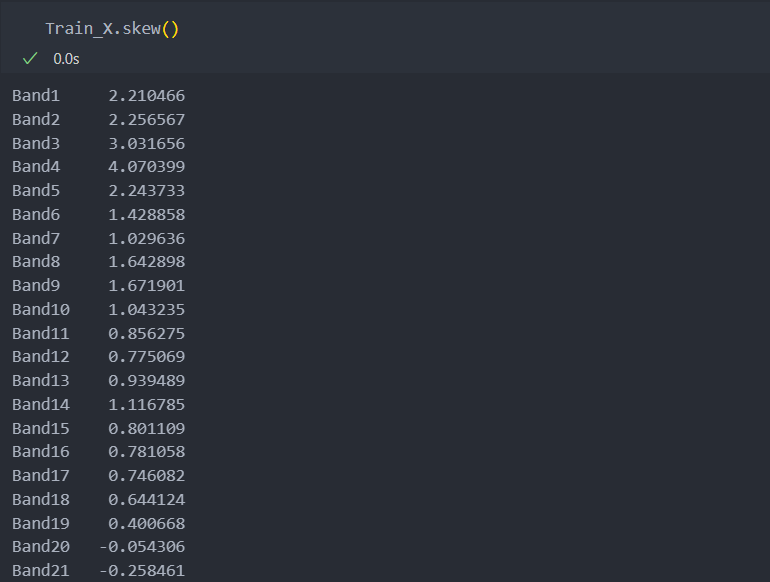
여러 컬럼들 중 왜도가 작은 순에서 큰 순으로 히스토그램을 4개 그려보자.
왜도가 커질수록 변수가 한쪽으로 쏠리는 것을 볼 수 있다.
F1 score 비교
기존
치우침을 제거하지 않고 기존의 데이터 그대로 사용하여 신경망 MLPClassifier의 F1 score를 확인해 보자.
# 원본 데이터로 모델링
from sklearn.metrics import f1_score
from sklearn.neural_network import MLPClassifier as MLP
model = MLP(random_state = 153, max_iter = 1000).fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
score = f1_score(Test_Y, pred_Y)
print('b_score', score)
b_score: 0.816326530612245치우친 변수 제거
왜도의 절대값이 1.5 이상인 것들을 제거하고 로그를 활용하여 치우침을 제거하자.
# 왜도의 절대값이 1.5 이상인 컬럼만 가져오기
biased_variables = Train_X.columns[Train_X.skew().abs() > 1.5]
# 1.5이상인 컬럼들의 치우침 제거
Train_X[biased_variables] = Train_X[biased_variables] - Train_X[biased_variables].min() + 1
Train_X[biased_variables] = np.log10(Train_X[biased_variables])
# 테스트도 데이터도 같은 방법으로 전처리를 수행
Test_X[biased_variables] = Test_X[biased_variables] - Test_X[biased_variables].min() + 1
Test_X[biased_variables] = Test_X[biased_variables].apply(np.log)제거한 이 후 데이터의 F1 scor(a_score)이다.
score가 조금 좋아졌음을 알 수 있다.
# 치우침 제거 후
model = MLP(random_state = 153, max_iter = 1000).fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
score = f1_score(Test_Y, pred_Y)
print('a_score: ', score)
a_score: 0.8333333333333334
데이터 굽는 타자기