변수 분포 문제
일반화된 모델을 학습하는데 어려움이 있는 분포를 가지는 변수가 있어, 일반화된 모델을 학습하지 못하는 문제 발생.
문제 정의
특징 간 스케일이 달라서 발생하는 문제로, 스케일이 큰 변수에 의해 혹은 스케일이 작은 변수에 의해 모델이 크게 영향을 받는 문제.
- 스케일이 큰 변수에 영향을 받는 모델 : k-최근접 이웃(거리 기반이기 때문)
- 스케일이 작은 변수에 영향을 받는 모델 : 회귀모델, SVM, 신경망
- 스케일에 영향을 받지 않는 모델 : 나이브베이즈, 의사결정나무
변수 간 스케일 차이를 줄이는 법
Standard Scaling(표준화)
특징의 정규 분포를 가정하는 모델(ex. 회귀모델, 로지스틱회귀모델)
이상치가 존재할 경우 모델의 성능을 저하시킬 수 있어서 정규분포를 가지는 데이터에서 쓰든가, 아니면 이상치를 제거 후 사용.
StandardScaler = (데이터 - 평균) / 표준편차
Min-Max Scaling(정규화)
특정 분포를 가정하지 않는 모델(ex. 신경망, k-최근접 이웃)
특정 특성이 다른 특성에 영향력을 크게 미치지 않는다.
이상치에 민감하지 않아서 이상치가 포함된 모델에서도 잘 동작한다.
MinMaxScaler = (데이터 - 최소값) / (최대값 - 최소값) - 0에서 1사이의 값을 가진다.
인스턴스
sklearn.preprocessing.MinMaxScaler & StandardScaler
메서드
- fit : 변수별 통계량 계산
- transform : 변수별 통계량을 바탕으로 스케일링 수행
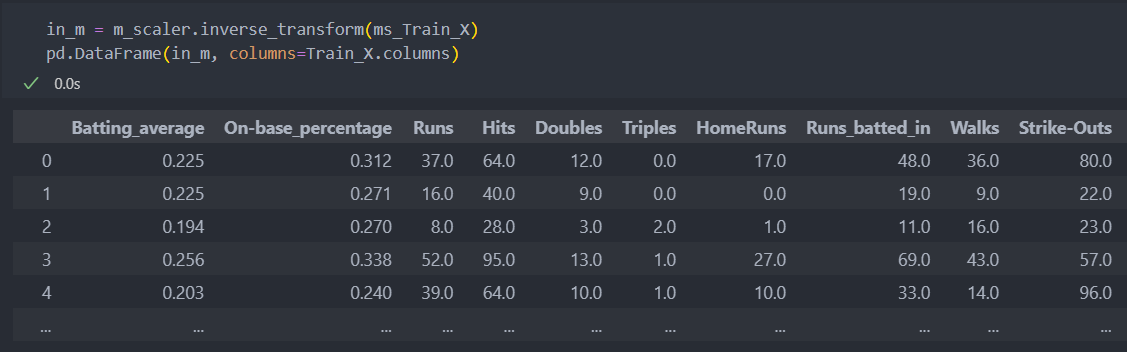
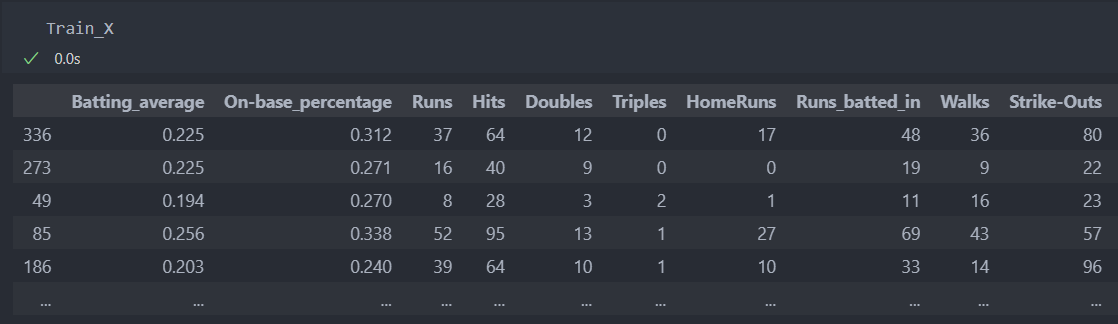
- inverse_transform : 스케일링된 값을 원래의 값으로 변환
실습
다음의 데이터를 가지고 실습을 해보자.
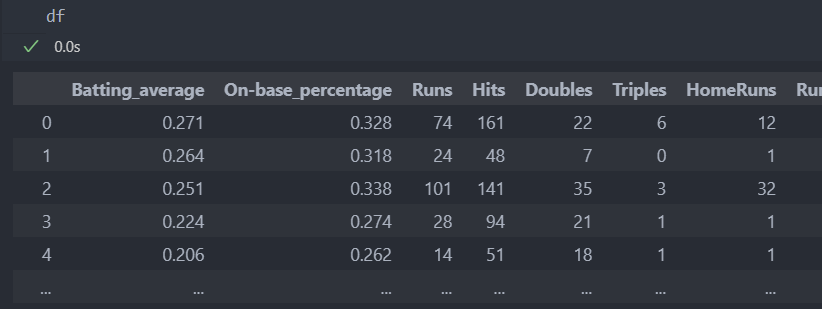
먼저 데이터를 분리하고 진행한다.
# 특징과 라벨 분리
X = df.drop('Salary', axis = 1)
Y = df['Salary']
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
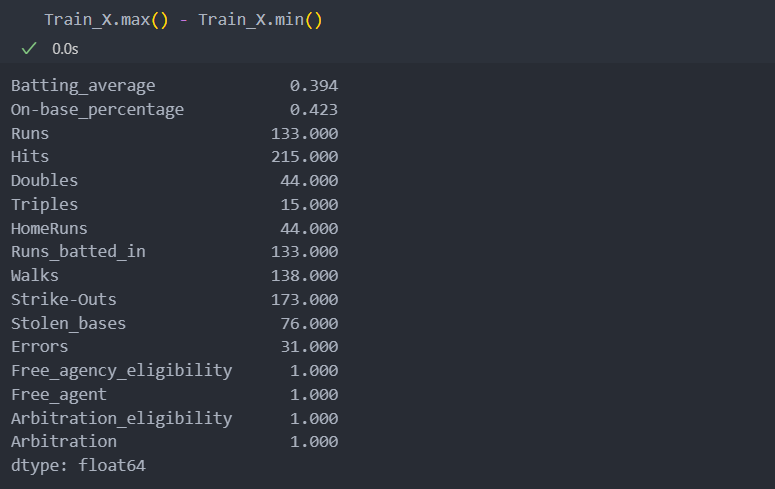
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)스케일의 차이를 보기 위해 최대값과 최소값으로 확인해보자.
컬럼별 스케일의 차이가 큰 것을 확인할 수 있고 스케일링을 진행해야 함을 알 수 있다.
스케일이 차이가 크다면, 스케일이 작은 변수의 특징이 무시되었을 가능성이 있다.
스케일링 후의 score와 비교하기 위해, 스케일링 하기 전 score를 확인해보자.
# 스케일링 전에 성능 확인
from sklearn.neighbors import KNeighborsRegressor as KNN
from sklearn.metrics import mean_absolute_error as MAE
model = KNN().fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
score = MAE(Test_Y, pred_Y)
print('score: ', score)
결과:
score: 619.0047058823529MinMaxScaler와 StandardScaler를 사용하여 스케일링을 진행해보자.
# 스케일링 수행
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
# 스케일러 인스턴스 및 계산
m_scaler = MinMaxScaler().fit(Train_X)
s_scaler = StandardScaler().fit(Train_X)
# MinMaxScaler 스케일링 적용
ms_Train_X = m_scaler.transform(Train_X)
ms_Test_X = m_scaler.transform(Test_X)
# StandardScaler 스케일링 적용
ss_Train_X = s_scaler.transform(Train_X)
ss_Test_X = s_scaler.transform(Test_X)스케일링을 적용한 값을 다시 모델을 사용하여 score를 보자.
스케일링 후 좋아졌음을 알 수 있다.(mean_absolute_error: 에러값이기에 작을 수록 좋다)
하지만 스케일링 후에 나빠지는 경우도 있기에, '무조건 좋아진다'라고 할 수 없다.
ex. 원래 영향력이 없는 컬럼이 스케일값도 작아서 무시되다가, 스케일링 후에 모델에 적용되어 성능이 저하될 수 있다.
그래서 전처리 뿐만이 아니라 데이터 자체에 대한 이해도를 높이려고 해야 한다.
# MinMaxScaler 스케일링 적용한 데이터
model = KNN().fit(ms_Train_X, Train_Y)
m_pred_Y = model.predict(ms_Test_X)
# StandardScaler 스케일링 적용헌 데이터
model = KNN().fit(ss_Train_X, Train_Y)
s_pred_Y = model.predict(ss_Test_X)
# score 계산
m_score = MAE(m_pred_Y, pred_Y)
s_score = MAE(s_pred_Y, pred_Y)
print('m_score: ', m_score)
print('s_score: ', s_score)
# 결과:
m_score: 538.5623529411764
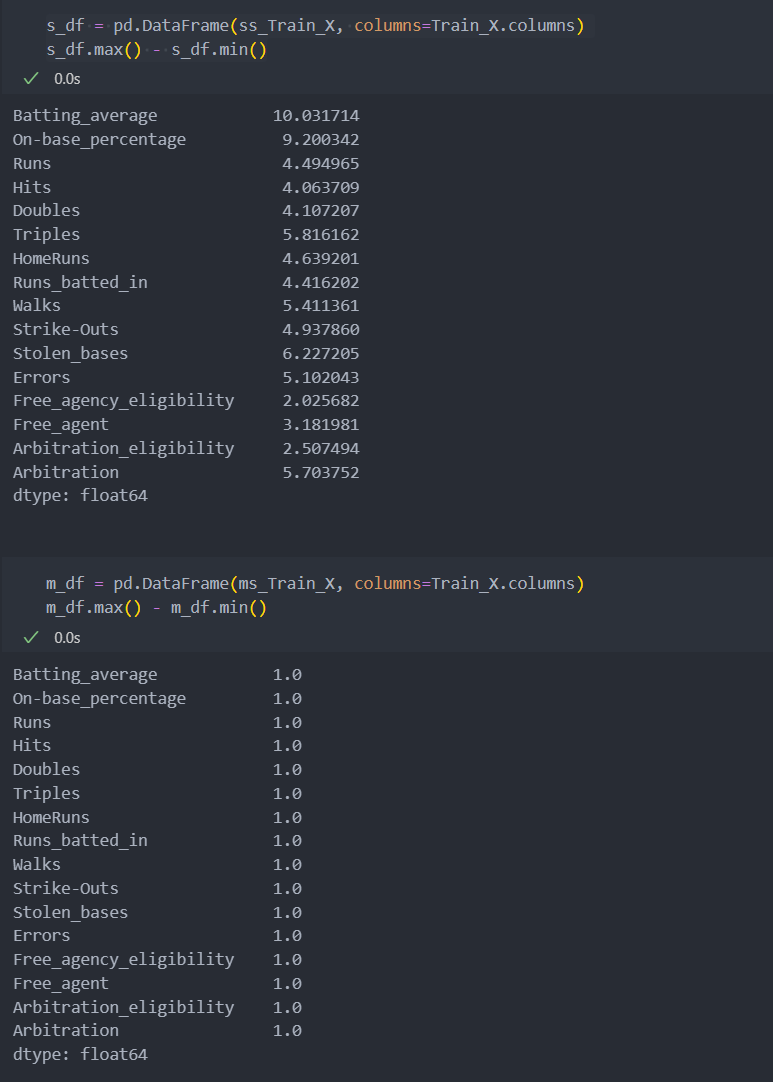
s_score: 500.5458823529413스케일링 후의 데이터를 확인해 보자.
StandardScaler로 스케일링 한 후의 변수 간 스케일값이 잘 분포됨을 알 수 있다.
MinMaxScaler는 '최대값1 - 최소값0'이기에 1로 잘 변환되었다.
스케일링 된 값을 다시 되돌리는 것은 인스턴스하여 계산한 스케일러를 가져와서 변환된 데이터를 넣어주면 기존의 데이터로 되돌릴 수 있다.