차원의 저주
차원이 증가함에 따라 필요한 데이터의 양과 시간 복잡도가 기하급수적으로 증가하는 문제.
- 차원이 증가함에 따라 모델 학습 시간이 정비례하게 증가함
- 차원이 증가함에 따라서 각 결정 공간에 포함되는 샘플 수가 적어져, 과적합으로 인해 성능 저하 발생.
특징 선택 : 필터링 기반의 특징 선택
특징과 라벨이 얼마나 관련이 있는지를 나타내는 '클래스 관련성'이 높은 특징을 우선 선택
클래스 관련성
클래스 관련성(class relevance)란, 한 특징이 클래스를 얼마나 잘 설명하는지를 나타내는 척도로써 상관계수, 카이제곱 통계량 상호정보량 등의 특징과 라벨 간 독립성을 나타내는 통계량을 사용하여 측정한다.
클래스 관련성이 높은 특징은 분류 및 예측에 도움이 되는 특징이다.
sklearn.feature_selection.SelectKBest
주요입력
- scoring_func : 클래스 관련성 측정 함수(카이제곱과 F 통계량이 주로 쓰인다)
-카이제곱 통계량 : 'chi2' - 변수가 범주형이고 라벨이 분류 문제
-F 통계량 : 'f_classif' - 변수가 연속형이고 라벨이 분류 문제
-F 통계량 : 'f_regression' - 변수가 연속형이고 라벨이 회귀 문제
-상호 정보량 : 'mulual_info_classif' - 변수가 연속/범주형이고 라벨이 분류 문제
-상호 정보량 : 'mulual_info_regression' - 변수가 연속/범주형이고 라벨이 회귀 문제- k : 선택하는 특징 개수
메서드
- .fit/.transform/.fit_transform
- .get_support(): 선택된 특징의 인덱스를 bool 타입으로 반환
주요속성
- score_ : scoring_func으로 측정한 특징별 점수
- pvalues_ : scoring_func으로 측정한 특징별 p-value(1에 가까울수록 독립, 0에 가까울수록 관련성 높음)
실습
특징 유형이 같은 경우
데이터 확인
다음의 데이터를 가지고 실습을 진행해보자.
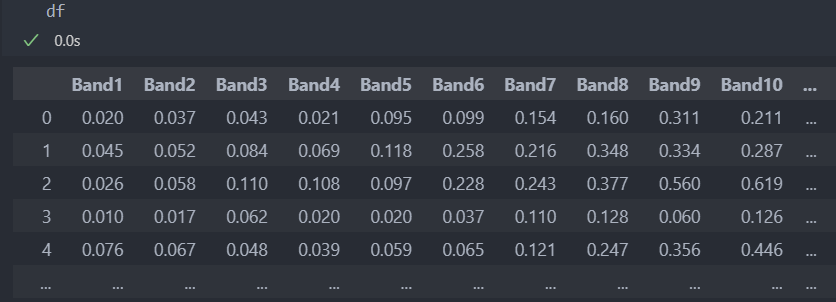
먼저 데이터를 나눈다.
# 특징과 라벨 분리
X = df.drop('Y', axis = 1)
Y = df['Y']
# 라벨을 문자에서 수치형으로 변환
Y.replace({"M":-1, "R":1}, inplace = True)
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)데이터의 shape를 확인해보니, 특징이 데이터에 비해 매우 많아서 특징 선택이 필요해보인다.

특징 선택
KNN 모델을 사용하여 F1 score로 특징 선택을 하기 전 비교를 위해 성능을 알아보자.
60개의 특징을 모두 사용한 F1 score는 78%정도이다.
# KNN 모델
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import f1_score
model = KNN().fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
print('f1_score: ', f1_score(Test_Y, pred_Y))
결과:
f1_score: 0.7804878048780488이제 특징을 선택해서 진행해보자.
데이터의 특징들은 연속형 데이터이기에, 연속형이며 분류 문제에 대한 f_classif를 사용하도록 한다.
# 특징 선택 수행
from sklearn.feature_selection import SelectKBest
# F-통계량 '연속형' 이진분류를 위해 f_classif 사용
selector = SelectKBest(f_classif, k = 30) # 특징은 30개 사용
selector.fit(Train_X, Train_Y) # 학습
selected_features = Train_X.columns[selector.get_support()] # get_support()로 선택된 특징 k개 가져오기
#선택된 k(30)개의 특징으로 DataFrame을 생성한다.
# 방법 1 : 학습을 통해 선택된 특징만 transform으로 가져옴
s_Train_X = pd.DataFrame(selector.transform(Train_X), columns = selected_features)
s_Test_X = pd.DataFrame(selector.transform(Test_X), columns = selected_features)
# 방법 2 : 기존 데이터에서 선택된 특징의 컬럼 인덱스로(추천 방법)
s_Train_X = Train_X[selected_features]
s_Test_X = Test_X[selected_features]기존의 특징에서 1/2를, 특징을 30개를 선택 후 다시 KNN을 사용하여 성능을 보자.
아래와 같이 특징이 60 -> 30으로 줄어든 것을 볼 수 있다.

그리고 특징을 줄였더니 f1_score가 85%로 성능이 상승되었음을 알 수 있다.
# 특징 선택 후 성능 확인
# KNN 모델 사용
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import f1_score
# 모델 인스턴스
model = KNN().fit(s_Train_X, Train_Y)
pred_Y = model.predict(s_Test_X)
print('f1_score: ', f1_score(Test_Y, pred_Y))
결과:
f1_score: 0.8571428571428571특징 선택의 최적 개수 확인
30개가 아닌 가지고 있는 특징에서 5개부터 50개까지 특징을 선택하여 가장 score가 높은 특징 개수는 몇개인지 확인해보자.
가장 높은 점수를 가지는 특징 개수 k는 28인데 30개 일 때와 같은 점수인 것을 확인할 수 있다.
비록 k가 2개의 차이지만, 다른 데이터에서는 그 수의 차이가 더 날 수도 있다.
이는 시간 복잡도를 낮춰주는 결과를 준다.
# 특징 개수 튜닝
# 특징 개수 튜닝
best_score = 0
score_list = []
k_list = []
for k in range(5, 50): # 특징 개수를 5개 단위로
selector = SelectKBest(f_classif, k = k)
selector.fit(Train_X, Train_Y)
selected_features = Train_X.columns[selector.get_support()]
s_Train_X = pd.DataFrame(selector.transform(Train_X), columns = selected_features)
s_Test_X = pd.DataFrame(selector.transform(Test_X), columns = selected_features)
model = KNN().fit(s_Train_X, Train_Y)
pred_Y = model.predict(s_Test_X)
score = f1_score(Test_Y, pred_Y)
if score > best_score:
best_score = score
best_k = k
best_features = selected_features
score_list.append(score)
k_list.append(k)
print('best_score: ', best_score, ' | best_k: ', best_k)
결과:
best_score: 0.8571428571428571 | best_k: 28위의 결과를 가지고 특징 선택 개수별 점수를 라인 그래프로 그려보면 아래와 같다.
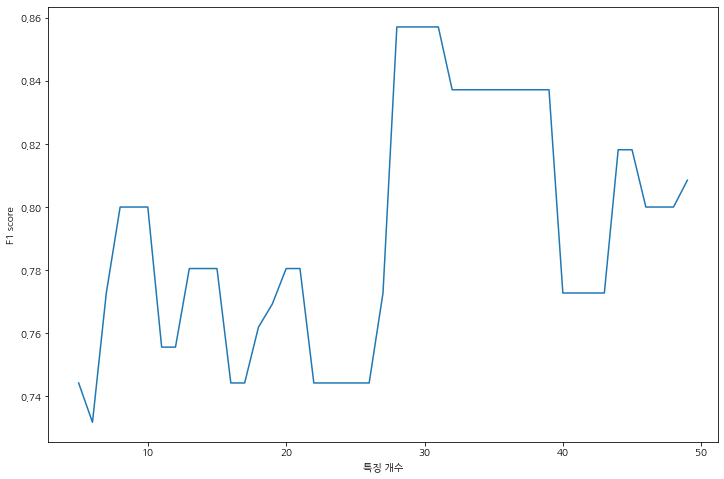
그리고 선택된 특징 28개의 이름은 다음과 같다.
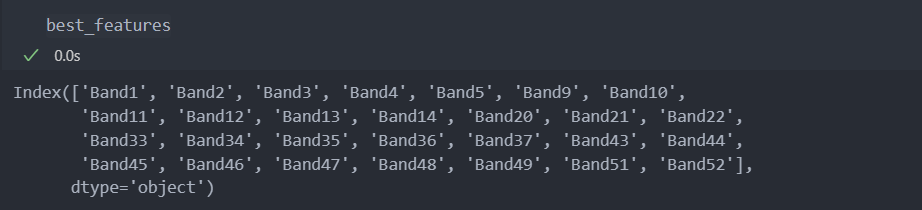
특징 유형이 다른 경우
데이터 확인
다음의 데이터를 가지고 실습을 진행해보자.
먼저 데이터를 분리하고 나누자.
# 특징과 라벨 분리
X = df.drop('Class', axis = 1)
Y = df['Class']
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)데이터의 shape를 살펴보자.
데이터에 비해서 컬럼이 조금 많음을 볼 수 있다.

특징 선택
KNN 모델을 사용하여 F1 score로 특징 선택을 하기 전 비교를 위해 성능을 알아보자.
14개의 특징을 모두 사용한 F1 score는 54%정도이다.
# 특징 선택 전 성능 확인
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import f1_score
# 모델 인스턴스
model = KNN().fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
print(f1_score(Test_Y, pred_Y))
결과:
f1_score: 0.5428571428571428특징들의 유형이 연속형과 범주형으로 섞여있어 유형을 구별하고 진행한다.
사실 단순히 특징의 클래스가 많으면 연속, 적으면 범주형이라고 단정 짓기는 어렵고 세세하게 컬럼들을 하나하나 살펴볼 필요성이 있다.
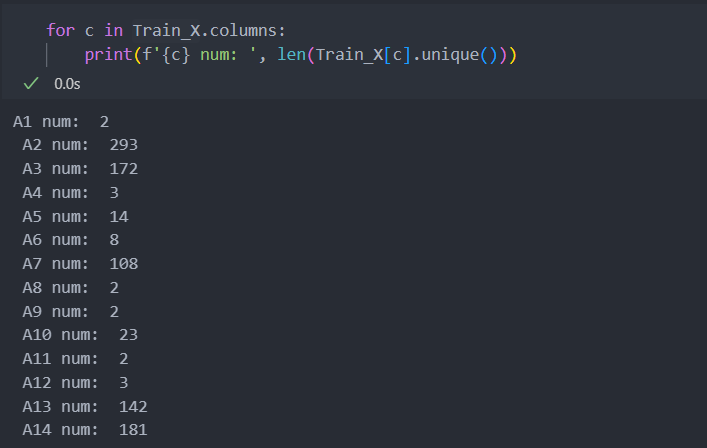
각 특징들의 unique값, 즉 상태 공간의 크기를 '3'을 기준으로 작으면 범주, 크면 연속형으로 구별해서 진행해보자.
# 유니크한 값의 개수를 바탕으로 연속형과 이진형 변수 구분
continuous_cols = [col for col in Train_X.columns if len(Train_X[col].unique()) > 3]
binary_cols = [col for col in Train_X.columns if len(Train_X[col].unique()) <= 3]연속형 변수에는 F 통계량을 범주형 변수에는 카이제곱 통계량을 사용한다.
그리고 통계량의 p-value를 기준으로 선택을 해보자.
통계량의 결과는 통계량(statistics)과 p-value를 반환한다.(f_classif(X, Y) => (statistics, p-value))
from sklearn.feature_selection import *
# 분류 문제에서 연속형 변수에 대해서는 f_classif(F 통계량)을, 이진형 변수에 대해서는 chi2(카이제곱)를 적용, p-value만 반환받는다.
continous_cols_pvals = f_classif(Train_X[continuous_cols], Train_Y)[1]
binary_cols_pvals = chi2(Train_X[binary_cols], Train_Y)[1]범주형과 연속형으로 나눈 특징들의 p-value를 가지고 오름차순으로 정렬하여 p-value가 작은 것들을 '선택'해서 쓰도록 한다.
# 각각을 array에서, p-value와 특징 이름을 1:1 매칭을 위해 Series로 변환 (value: pvalue, index: colum name)
cont_pvals = pd.Series(continous_cols_pvals, index = continuous_cols)
binary_pvals = pd.Series(binary_cols_pvals, index = binary_cols)
# cont_pvals과 binary_pvals을 합친 뒤, 오름차순으로 정렬
pvals = pd.concat([cont_pvals, binary_pvals]) # 이어붙이기
pvals.sort_values(ascending = True, inplace = True) # 오름차순(p-value가 낮을 수록 좋은 통계량이라 판단)p-value가 낮은 순으로 해당하는 특징을 가져와서 성능을 비교해보자.
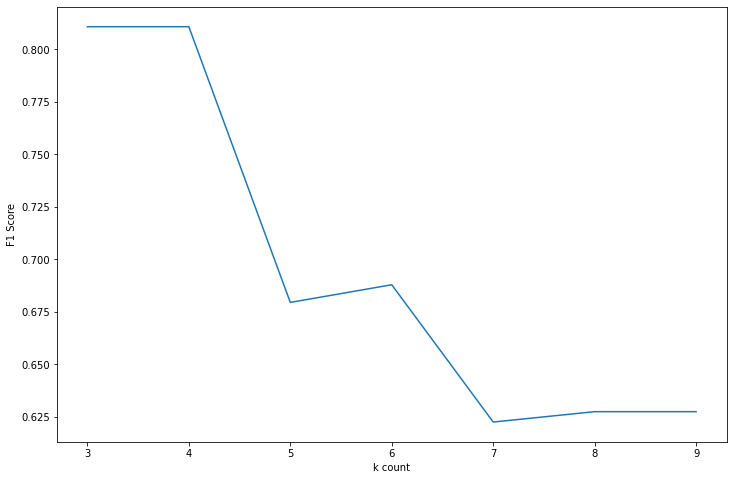
특징 3개부터 9개까지 특징들 수를 늘려가며 score의 변화와, 그 중 가장 score가 좋은 특징 개수도 확인해보자.
best_score = 0
k_list = []
score_list = []
for k in range(3, 10): # 특징 개수 3개부터 9개까지
s_Train_X = Train_X[pvals.iloc[:k].index] # k개까지의 각 특징(컬럼)의 인덱스로 데이터 만들기
s_Test_X = Test_X[pvals.iloc[:k].index]
model = KNN().fit(s_Train_X, Train_Y) # 모델 인스턴스
pred_Y = model.predict(s_Test_X)
score = f1_score(Test_Y, pred_Y)
k_list.append(k)
score_list.append(score)
if score > best_score:
best_score = score
best_k = k
print('best_k: ', best_k, '| best_score: ', best_score)
결과:
best_k: 3 | best_score: 0.8108108108108107가장 좋은 특징 수는 3개로 score가 81%정도다.
아래는 특징 개수별 점수의 변화 추이를 라인 그래프로 나타내었다.