모델 개발 프로세스
실제 프로세스에서는 데이터 탐색과 전처리 사이에 피드백 루프가 존재한다.
탐색을 한 번에 다하고 전처리를 한 번에 다 하는 것이 아니다.
- 데이터 탐색1 -> 데이터 전처리1(파라미터 튜닝) -> 데이터 탐색2 -> 데이터 전처리2(파라미터 튜닝) -> ... ->
과정
1. 필수 전처리
일반적으로 필수 전처리는 특별한 튜닝이 필요하지 않으므로 순차적 진행.
- 데이터 탐색(데이터 파편화 여부 확인) -> 데이터 전처리(데이터 통합)
- 데이터 탐색(결측 여부 확인) -> 데이터 전처리(결측치 제거/대체/예측)
- 데이터 탐색(범주형 변수 확인) -> 데이터 전처리(범주형 변수 처리 : 더미화, 연속형 변수 처리)
- 데이터 탐색(라벨 문자 여부 확인) -> 데이터 전처리(라벨 변환)
2. 성능 향상을 위한 전처리
일반적으로 성능 향상을 위한 전처리는 튜닝도 같이 수행
- 데이터 탐색(특징과 라벨 간 상관 관계 확인) -> 데이터 전처리(신규 특징 추가)
- 데이터 탐색(이상치 확인) -> 데이터 전처리(이상치 제거/치환) - 상황/모델에 따라
- 데이터 탐색(특징 간 상관 관계 확인) -> 데이터 전처리(특징 간 상관성 제거) - 상황/모델에 따라
- 데이터 탐색(왜도 확인) -> 데이터 전처리(변수 치우침 제거)
- 데이터 탐색(특징 간 스케일 차이 확인) -> 데이터 전처리(스케일링)
- 데이터 탐색(클래스 불균형 확인) -> 데이터 전처리(거리 기반 재샘플링 및 비용민감 모델 고려)
- 데이터 탐색(데이터 크기 확인) -> 데이터 전처리(특징 선택 & 모델 목록 정의)
3. 파라미터 그리드 설계
- 이상치 제거 파라미터 : IQR 기준치, DBSCAN
- 재샘플링 모델 및 파라미터 : SMOTE , NearMiss, Other
- 특징 선택 파라미터 : 특징 개수
- 모델 및 모델 파라미터 :
-Linear Regression
-Lasso/Ridge
-Neural network
-SVM
-Decision Tree
-Random Forest
-...
프로세서 실습
다음의 고객 이탈 여부 데이터를 가지고 전체 과정을 실습해보자.
먼저 데이터를 data/label로 나누고 학습/평가 데이터로 나누자.
test data는 새로 들어오는 데이터라 가정하고 진행하겠다.
# 특징과 라벨 분리
X = df.drop(['customerID', 'Churn'], axis = 1) # customerID는 의미가 없는 것이므로 삭제
Y = df['Churn']
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
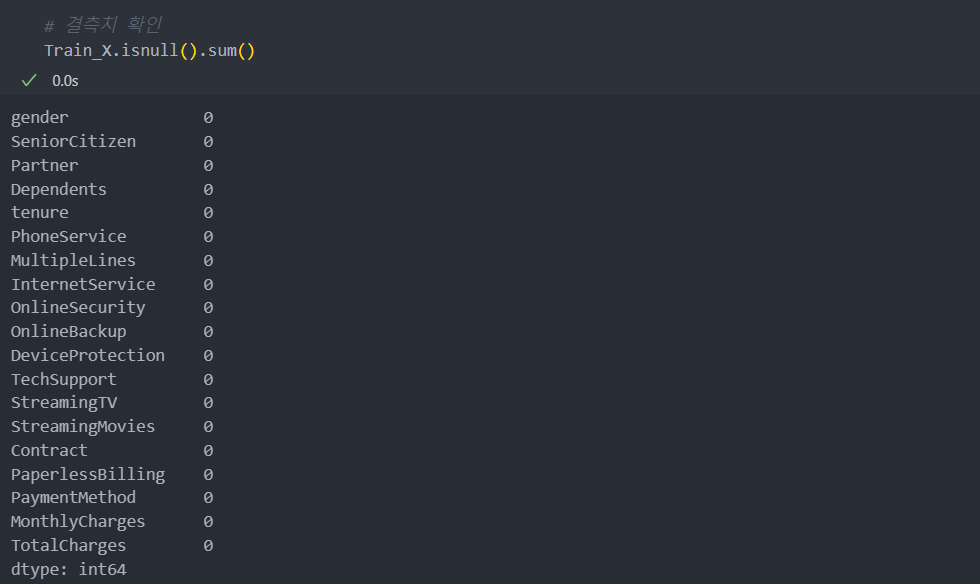
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)결측치 확인
결측치가 0으로 없음을 알 수 있다.
그런데 금액 부분인 TotalCharges가 object로 되어 있어 확인해야 한다.
NaN값 뿐만 아니라 수치형에 문자형이, 문자형에 수치형이 포함되어 있을 수 있기에 정렬하여 앞, 뒤의 배열을 확인해보자.
확인 결과 공백 문자가 들어가 있음을 알 수 있다.
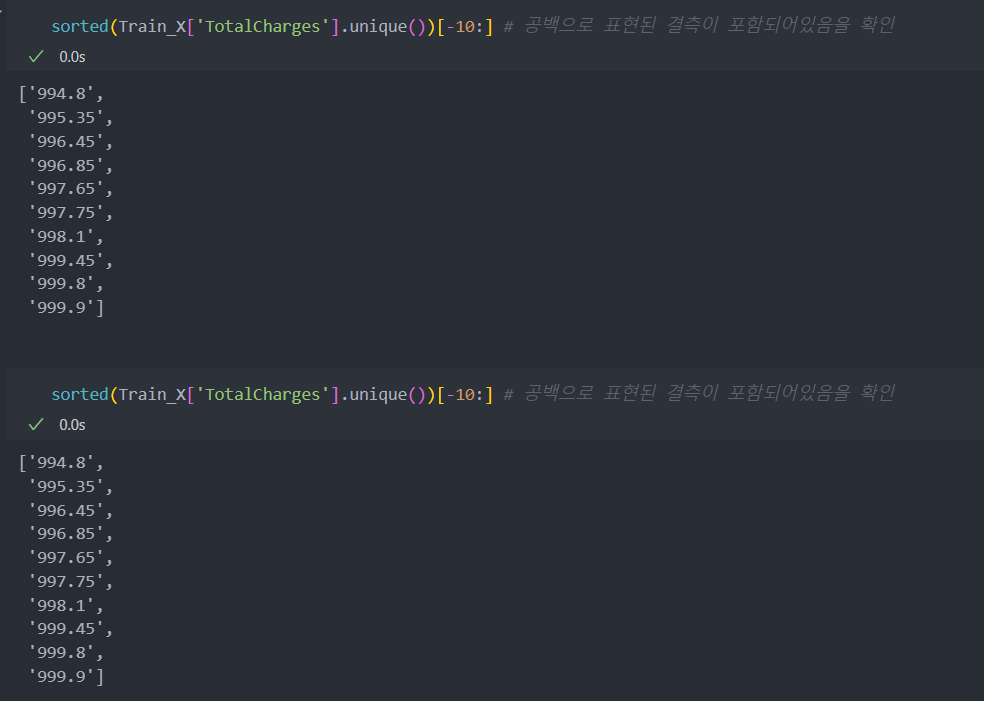
공백 문자가 있어 분석이 어려울 수 있으니 공백을 결측으로 변환한다.
모든 특징들에도 있을 수 있으니 모든 컬럼들의 공백을 결측치로 변화한다.
# 공백 문자 -> 결측치로 변환
for col in Train_X.columns:
Train_X[col].replace(' ', np.nan, inplace = True)
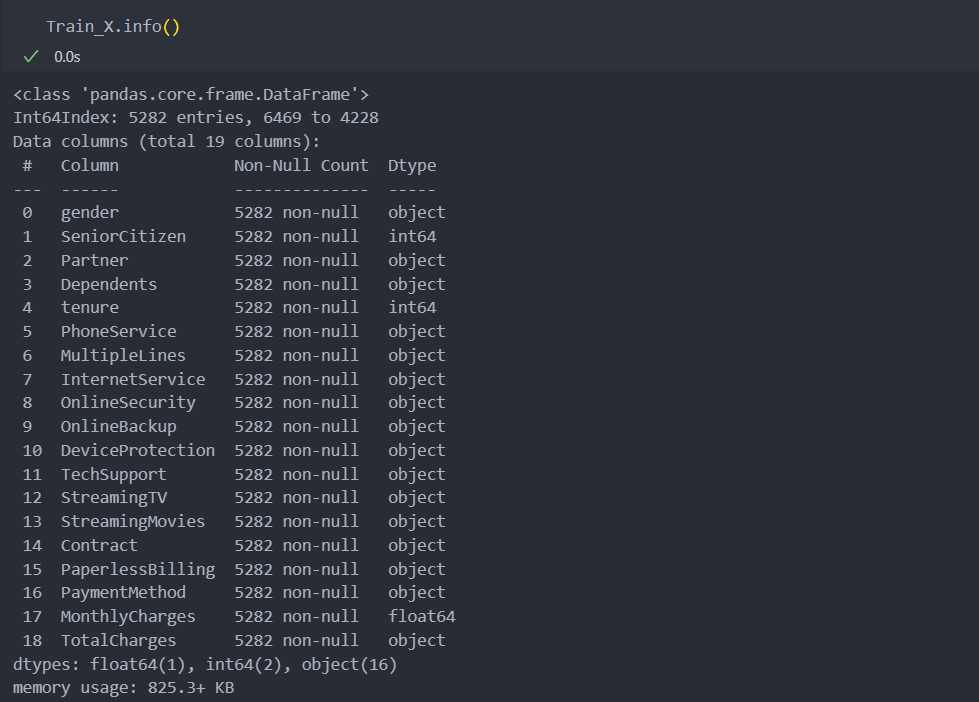
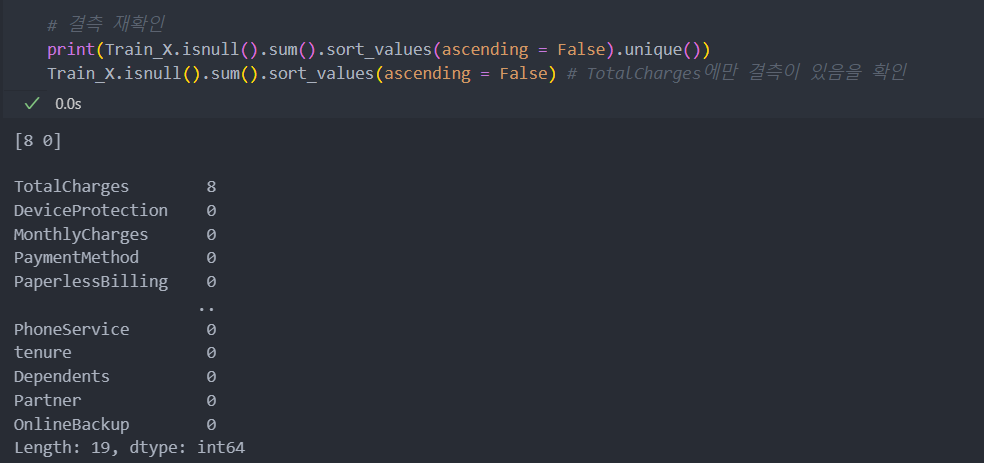
Test_X[col].replace(' ', np.nan, inplace = True)다시 결측치를 확인해보자.
TotalCharges에만 결측치가 있고 그 수도 많지는 않음을 알 수 있다.
TotalCharges는 MonthlyCharges 등 다른 변수들과 관련이 되어 있어 보이며, 새로 들어오는 데이터에도 결측치가 존재할 수 있으므로 삭제하지 않고 결측치 예측 모델을 사용하기로 한다.
그리고 TotalCharges는 연속형으로 float형으로 변환해준다.
Train_X['TotalCharges'] = Train_X['TotalCharges'].astype(float)결측치 예측 모델은 모든 변수가 숫자여야 한다.
OneHotCategoricalEncoder을 사용하여 범주형으로 예측되는 문자 변수들을 더미화(숫자로 변환)한다.
참조 : 범주형 변수
OneHotCategoricalEncoder의 variables는 '리스트' 타입으로 입력을 받는다.
# 범주형 변수 파악 : object 타입의 컬럼들 목록을 리스트로 받는다.
category_columns = Train_X.select_dtypes(include = 'object').columns.tolist()
# 범주형 변수 더미화
from feature_engine.categorical_encoders import OneHotCategoricalEncoder as OHE
# 인스턴스
make_dummy_model = OHE(variables = category_columns, drop_last = True).fit(Train_X)
# 적용
Train_X = make_dummy_model.transform(Train_X)
Test_X = make_dummy_model.transform(Test_X)적용한 결과이다.
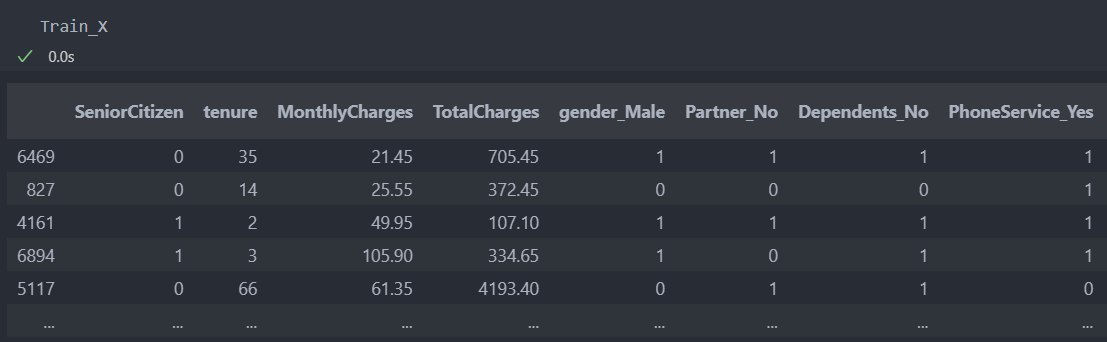
KNNImputer를 사용하여 결측치를 채워넣는다.(참조 : 결측치 예측 모델)
# 결측치 예측 모델 활용
from sklearn.impute import KNNImputer
# KNN Imputer 인스턴스화
KI = KNNImputer(n_neighbors = 5) # 이웃의 수 5
# KNN Imputer 학습
KI.fit(Train_X)
# 결측 대체
Train_X = pd.DataFrame(KI.transform(Train_X), columns = Train_X.columns)
Test_X = pd.DataFrame(KI.transform(Test_X), columns = Test_X.columns)모든 결측치가 채워진 것을 볼 수 있다.

라벨 확인
라벨 데이터를 확인해보면,
문자로 되어있어서 숫자로 변환해야 하고, 클래스 불균형이 1:3 정도로 심한 불균형은 없다는 것을 확인할 수 있다.

# 라벨 변환
Train_Y.replace({"No":-1, "Yes":1}, inplace = True)
Test_Y.replace({"No":-1, "Yes":1}, inplace = True)범주형 변수 확인
문자로 된 변수들을 더미화했기에 범주형 변수의 범주는 3 미만일 것이다.
3개의 컬럼을 제외하고 모두 범주형 변수라고 할 수 있겠다.
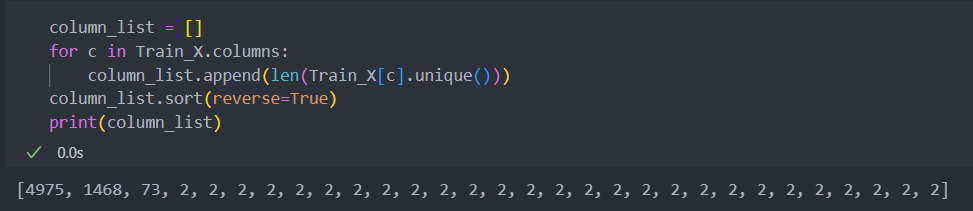
연속형 변수와 범주형 변수로 분리하도록 한다.
이상치 제거나 치우침 제거 등 연속형과 범주형은 적용 방식이 다르기 때문에 분리하여 진행하는 것이 좋다.
# 유니크한 값의 개수를 바탕으로 연속형과 이진형 변수 구분
continuous_cols = [col for col in Train_X.columns if len(Train_X[col].unique()) > 3]
binary_cols = [col for col in Train_X.columns if len(Train_X[col].unique()) <= 3]이상치 확인
IQR로 이상치가 있는지 확인해보자.(참조 : 이상치 탐색)
연속형 범주의 컬럼 3개의 각 값들이 이상치가 있는지 함수를 작성하여 확인해보자.
# 이상치 확인
def IQR_rule(val_list): # 한 특징에 포함된 값 (열 벡터)
# IQR 계산
Q1 = np.quantile(val_list, 0.25)
Q3 = np.quantile(val_list, 0.75)
IQR = Q3 - Q1
# IQR rule을 위배하지 않는 bool list 계산 (True: 이상치 X, False: 이상치 O)
not_outlier_condition = (Q3 + 1.5 * IQR > val_list) & (Q1 - 1.5 * IQR < val_list)
return not_outlier_condition # T/F 반환
# 전체 길이 - IQR True인 길이 = 이상치 길이
num_outliers = len(Train_X) - Train_X[continuous_cols].apply(IQR_rule).sum(axis = 0)
print(num_outliers) # 결과 특별한 이상치 없음 => 제거 X
결과:
tenure 0
MonthlyCharges 0
TotalCharges 0
dtype: int64변수 치우침 확인
참조 : 변수 치우침
범주형 변수는 치우치더라도 1아니면 0이기에 변환에 의미가 없다.
연속형 변수에 속하는 3개의 컬럼들을 확인하면 수치가 절대값 1.5를 넘어가는 수치가 없어 보인다.

그리고 데이터의 shape을 보면 샘플 수에 비해 컬럼이 많지 않아 컬럼 수를 더 생성하지 않아도 될 것 같다.

특징 선택 & 모델 목록 정의
대부분의 특징들이 이진형의 범주형 변수이기에 공간이 많이 필요한(샘플이 많이 필요한) 데이터들이 아니기에, 샘플은 충분하다고 볼 수 있다.
그래서 충분히 복잡한 모델을 쓰더라도 괜찮아 보이며, 과적합을 방지할 수 있는 많은 샘플들이 있다.
범주형과 연속형 중 범주형 변수들이 많아 각 특징이 제대로 반영되면 좋은 성능을 기대할 수 있는 앙상블 계열의 모델을 쓰도록 하자.
# 특징 선택과 모델 하이퍼 파라미터 튜닝
from sklearn.ensemble import RandomForestClassifier as RFC
from xgboost import XGBClassifier as XGB
from lightgbm import LGBMClassifier as LGBM
from sklearn.feature_selection import *
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import f1_score
# 모델 파라미터 그리드 설계(좀 더 작은 수로 미세하게 조절해 보자)
model_parameter_grid = dict()
model_parameter_grid[RFC] = ParameterGrid({"max_depth": [2, 3, 4], # 과적합 방지를 위해 max_depth는 크게 잡지 않는다.
"n_estimators": [50, 100]})
model_parameter_grid[XGB] = ParameterGrid({"max_depth": [2, 3, 4],
"n_estimators": [50, 100],
"learning_rate": [0.05, 0.1, 0.15, 0.2]}) # 일반적으로 0.1 ~ 0.2 사이
model_parameter_grid[LGBM] = ParameterGrid({"max_depth": [2, 3, 4],
"n_estimators": [50, 100],
"learning_rate": [0.05, 0.1, 0.15, 0.2]})이제 특징 선택을 진행하자.(참조 : 특징 선택)
분류 문제이기에, 범주형 변수는 카이제곱 통계량 chi2를, 연속형 변수는 F 통계량 f_classif을 사용한다.
# f_regression(X, Y) => 반환 : (statistics, p-value) 중에서 p-value를 사용
continous_cols_pvals = f_classif(Train_X[continuous_cols], Train_Y)[1]
binary_cols_pvals = chi2(Train_X[binary_cols], Train_Y)[1]반환받은 p-value(작은 값일 수록 좋은 수치)를 오름차순으로 정렬하여 몇 개의 특징을 쓰는 것이 좋은지 확인해 볼 것이다.
# 각각을 Series로 변환 (value: pvalue, index: colum name)
cont_pvals = pd.Series(continous_cols_pvals, index = continuous_cols)
binary_pvals = pd.Series(binary_cols_pvals, index = binary_cols)
# cont_pvals과 binary_pvals을 합친 뒤, 오름차순으로 정렬 (앞에 나오는 특징부터 좋은 특징)
pvals = pd.concat([cont_pvals, binary_pvals])
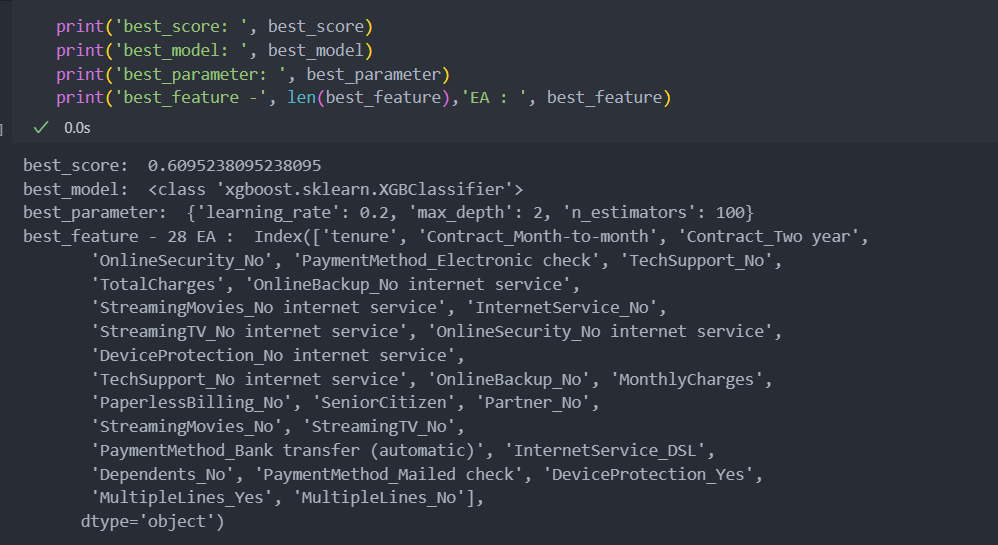
pvals.sort_values(ascending = True, inplace = True)모델들에 각각의 하이퍼 파라미터들을 적용시켜 best score를 확인해 보자.
# 튜닝 시작
best_score = 0
for k in range(30, 5, -1): # 특징(컬럼) 30개부터 6개까지 적용시켜서
print(k)
s_Train_X = Train_X[pvals.iloc[:k].index] # 특징 k개를 가져와서
s_Test_X = Test_X[pvals.iloc[:k].index]
for M in model_parameter_grid.keys(): # 각 모델에 대해
for P in model_parameter_grid[M]: # 각 모델에 대한 하이퍼 파라미터들을
model = M(**P).fit(s_Train_X, Train_Y) # 학습하고
pred_Y = model.predict(s_Test_X) # 적용하여
score = f1_score(Test_Y, pred_Y) # F1 score를 담아
if score > best_score: # best score를 확인
best_score = score
best_feature = s_Train_X.columns
best_model = M
best_parameter = P best score의 score와 model, parameters, 그리고 features를 살펴보면 다음과 같다.