
차원의 저주
차원이 증가함에 따라 필요한 데이터의 양과 시간 복잡도가 기하급수적으로 증가하는 문제.
- 차원이 증가함에 따라 모델 학습 시간이 정비례하게 증가함
- 차원이 증가함에 따라서 각 결정 공간에 포함되는 샘플 수가 적어져, 과적합으로 인해 성능 저하 발생.
특징 선택 : 특징이 적은 경우
분류 및 예측에 효과적인 특징만 선택하여 차원을 축소하는 방법.
특징이 많아야만 쓸 수 있는 것은 아니다.
오히려 특징이 적은 경우에 적용하여 쓸 수 있는 실습을 진행해보자.
다음과 같이 특징이 7개인 데이터가 있다.
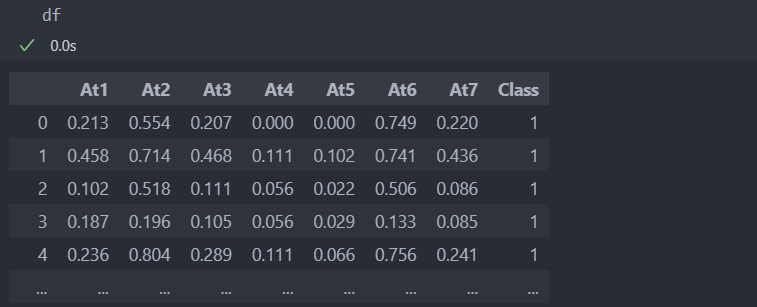
먼저 데이터를 분리하자.
# 특징과 라벨 분리
X = df.drop('Class', axis = 1)
Y = df['Class']
# 학습 데이터와 평가 데이터 분리
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)그리고 SVM 모델을 이용하여 테스트를 진행할 것이다.
특징을 1개부터 7개까지 선택할 수 있는 모든 경우의 수에 따라서,
다시 말해 7개로 생성할 수 있는 모든 특징들의 조합의 모든 경우를 살펴보겠다.
먼저 SVM F1 score를 반환하는 함수를 작성하고, 함수를 바탕으로 모든 조합의 score를 살펴보자.
from sklearn.svm import SVC
from sklearn.metrics import f1_score
# 특징에 따른 점수 반환 함수
def feature_test(Train_X, Test_X, Train_Y, Test_Y, features): # features들의 조합
s_Train_X = Train_X[features]
s_Test_X = Test_X[features]
model = SVC().fit(s_Train_X, Train_Y)
pred_Y = model.predict(s_Test_X)
return f1_score(Test_Y, pred_Y)
# features에 모든 특징을 넣어 점수를 확인.
base_score = feature_test(Train_X, Test_X, Train_Y, Test_Y, Train_X.columns) # 모든 특징을 썼을 때의 점수
print('base_score: ', base_score)
결과:
base_score: 0.7272727272727272모든 특징을 사용한 경우 72%라는 score를 반환받았는데, 이제 7개보다 적은 특징들의 조합을 itertools.combinations에 반복문을 사용하여 넣어보자.
import itertools
c_list = list(range(1, len(Train_X.columns))) # 1개부터 6개까지
outperform_ratio_list = [] # base_score보다 좋은 score를 반환받았을 때의 비율
best_score = 0
for c in range(1, len(Train_X.columns)): # c = 선택한 특징 개수
c_num = 0 # 특징을 c개 뽑았을 때, 원본보다 성능이 좋은 경우
c_dem = 0 # 특징을 c개 뽑는 경우의 수
for features in itertools.combinations(Train_X.columns, c): # 특징들의 모든 조합 / 모든 특징에서 c개의 수 만큼의 모든 특징 반환
score = feature_test(Train_X, Test_X, Train_Y, Test_Y, list(features)) # itertools은 tuple 형태로 값을 반환해서 형변환을 해준 것
if score > best_score: # best_score 찾기 위한
best_score = score
best_feature = list(features)
if score > base_score: # 새로 찾은 best_score가 base_score(모든 특징을 사용한 score)보다 좋은 경우
c_num += 1
c_dem += 1
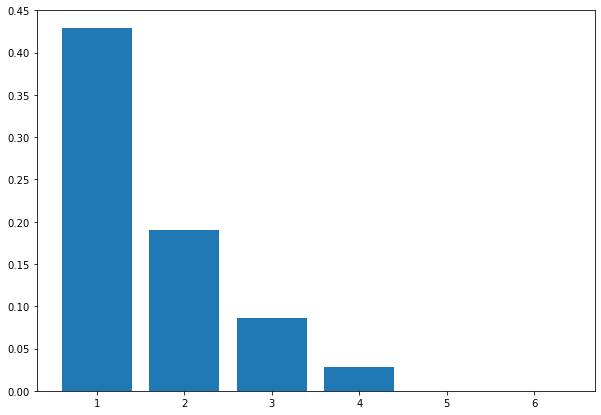
outperform_ratio_list.append(c_num / c_dem)특징 개수에 따른, 모든 특징을 사용했을 때보다 더 좋은 score가 반환되는 비율을 살펴보면 아래와 같다.
특징 1개를 썼을 때, 모든 특징을 쓴 score보다 더 좋은 수치들이 나옴을 알 수 있는데, 그 비율은 42%로 특징 1개만으로 더 좋은 score를 반환받을 수 있는 특징이 7개중 3개가 있다는 말이다.
그리고 가장 score가 높은 점수와 features는 다음과 같다.

이런 방법은 오히려 특징 수가 적을 때 가능한 방법으로 특징 수가 많다면 오히려 시간 복잡도가 기하급수적으로 상승한다.
1초에 1억 번의 모형을 학습할 수 있는 슈퍼 컴퓨터가 있다 하더라도,
1000개의 특징이 있는 데이터의 가장 좋은 조합을 선택하는데 약 400조년 걸린다.
