[데이터 전처리] 클래스 불균형 - 비용 민감 모델 활용
데이터 EDA & 전처리

클래스 불균형
클래스 변수가 하나의 값에 치우친 데이터로 학습한 분류 모델이 치우친 클래스에 대해 편향되는 문제.
- 클래스 불균형 문제가 있는 모델은 정확도는 높지만, 재현율이 매우 낮은 경향이 있다.
용어 정리
- 다수 클래스 : 대부분의 샘플이 속한 클래스
- 소수 클래스 : 대부분의 샘플이 속하지 않은 클래스 - 관심 대상
- 위양성 비용(False Positive) : 부정 클래스 샘플을 긍정 클래스 샘플로 분류해서 발생하는 비용
- 위음성 비용(False Negative) : 긍정 클래스 샘플을 부정 클래스 샘플로 분류해서 발생하는 비용
- 보통 위음성 비용이 위양성 비용보다 훨씬 크다
- 절대 부족 : 소수 클래스에 속한 샘플 개수가 절대적으로 부족한 상황
불균형 탐색
비율 탐색
불균형 불균형 비율이 9이상이면 평향된 모델이 학습될 가능성이 있음.
클래스 불균형 비율 = 다수 클래스에 속한 샘플 수 / 소수 클래스에 속한 샘플 수
k-최근접 이웃 활용
k-최근접 이웃은 이웃의 클래스 정보를 바탕으로 분류를 하기에 클래스 불균형에 매우 민감하다.
- k(이웃 수)값이 크면 클수록 민감하므로 보통 5~11 정도의 k를 설정
비용 민감 모델
학습 목적에서 위음성 비용과 위양성 비용을 다르게 설정하는 모델로, 보통 '위음성 비용'을 위양성 비용보다 크게 설정
위음성 비용 = w * 위양성 비용(w > 1)
확률 모델
- 로지스틱 회귀, 나이브 베이즈 등의 확률 모델들은 cut-off value, c를 조정하는 방식으로 비용 민감 모델 구현
-Pr(y|x) >= c -> 'Pos'
-Pr(y|x) <= c -> 'Neg' - 정확한 확률 추정은 불가능하지만 그 개념을 도입할 수 있는 모델(k-최근접 이웃, 신경망, 의사결정나무, 앙상블 모델 등)에도 적용 가능
비확률 모델
- 가중치를 나누어 조절하는 형태로 구현(서포트 백터 머신, 의사결정나무)
실습
1. 확률 모델
다음의 데이터로 실습을 진행해보자.
먼저 데이터를 data/label, 학습/평가 데이터로 분리한다.
# 특징과 라벨 분리
X = df.drop('Y', axis = 1)
Y = df['Y']
# 학습 데이터와 평가 데이터 분할
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)해당 데이터의 shape과 비율을 보자.
불균형 테스트
k-최근접 이웃을 사용하여 클래스가 불균형한지 테스트해보자.
아래와 같이 recall_score이 0%로 불균형이 심하다는 것을 확인할 수 있다.
# kNN을 사용한 클래스 불균형 테스트
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
# 인스턴스화
kNN_model = KNN(n_neighbors = 11).fit(Train_X, Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.0
accuracy_score: 0.9311224489795918비용 민감 모델 적용
비용 민감 모델 적응 전 로지스틱 회귀 모델로 테스트를 해보자.
KNN(클래스 불균형에 민감한 모델)에 비해서 recall_score은 조금 높고 accuracy_score은 조금 낮게 나온다.
# LogisticRegression 모델 불러오기 : 가벼운 모델이며 과적합이 발생할 확률도 적은 모델.
from sklearn.linear_model import LogisticRegression as LR
# 인스턴스화
model = LR(max_iter = 100000).fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.1111111111111111
accuracy_score: 0.8877551020408163이제 LogisticRegression에서 cut_off_value값을 조절하여 재현율을 높이는 방법을 알아보자.
아래의 결과와 같이 accuracy_score가 낮아진 것에 비해서 recall_score가 상대적으로 많이 오른 것을 볼 수 있다.
# cut off value를 조정
probs = model.predict_proba(Test_X)
probs = pd.DataFrame(probs, columns = model.classes_)
cut_off_value = 0.3
# probs.iloc[:, -1]는 1이 될 확률의 컬럼, 즉 기존 수치 0.5보다 값이 크면 1이 될 확률을 0.3으로 낮춰서 1이 될 확률을 높인다.
pred_Y = 2 * (probs.iloc[:, -1] >= cut_off_value) - 1 # True : 2*1(True)-1 = 1 / False : 2*0(False) -1 = -1
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.2222222222222222
accuracy_score: 0.8647959183673469변수 probs는 이렇게 반환되어 나온다.
LogisticRegression로 학습된 모델을 가지고 여러 cut_off_value 값을 조절하며 score를 확인해보자.
score를 반환하는 함수를 생성하여 여러 cut_off_value 값을 대입하여 score가 어떻게 변하는지 살펴보자.
score를 반환하는 함수를 작성하자.
# cut off value를 조정하는 함수 작성
def cost_sensitive_model(model, cut_off_value, Test_X, Test_Y):
probs = model.predict_proba(Test_X)
probs = pd.DataFrame(probs, columns = model.classes_)
pred_Y = 2 * (probs.iloc[:, -1] >= cut_off_value) - 1
recall = recall_score(Test_Y, pred_Y)
accuracy = accuracy_score(Test_Y, pred_Y)
return recall, accuracy함수를 바탕으로 cut_off_value 미세하게 조절하며 score의 변화를 살펴보고,
원하는 score에 맞게 cut_off_value를 정하도록 한다.
# cut off value에 따른 recall과 accuracy 변화 확인
from matplotlib import pyplot as plt
import numpy as np
%matplotlib inline
# model
model = LR(max_iter = 100000).fit(Train_X, Train_Y)
cut_off_value_list = np.linspace(0, 1, 101)
recall_list = []
accuracy_list = []
# cut_off_value을 반복문을 사용하여 확인
for c in cut_off_value_list:
recall, accuracy = cost_sensitive_model(model, c, Test_X, Test_Y)
recall_list.append(recall)
accuracy_list.append(accuracy)
plt.figure(figsize=(12, 8))
plt.plot(cut_off_value_list, recall_list, label = 'recall')
plt.plot(cut_off_value_list, accuracy_list, label = 'accuracy')
plt.legend()
plt.show()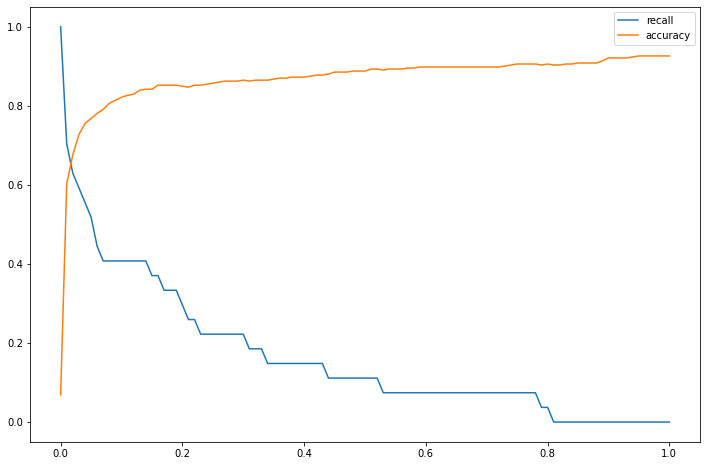
2. 비확률 모델
다음의 데이터로 실습을 진행해보자.
먼저 데이터를 data/label, 학습/평가 데이터로 분리하고 label을 숫자로 변환한다.
# 특징과 라벨 분리
X = df.drop('Class', axis = 1)
Y = df['Class']
# 학습 데이터와 평가 데이터 분할
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)
# 문자 label을 수치형으로 바꾸기
Train_Y.replace({"negative":-1, "positive":1}, inplace = True)
Test_Y.replace({"negative":-1, "positive":1}, inplace = True)해당 데이터의 shape과 비율을 보자.
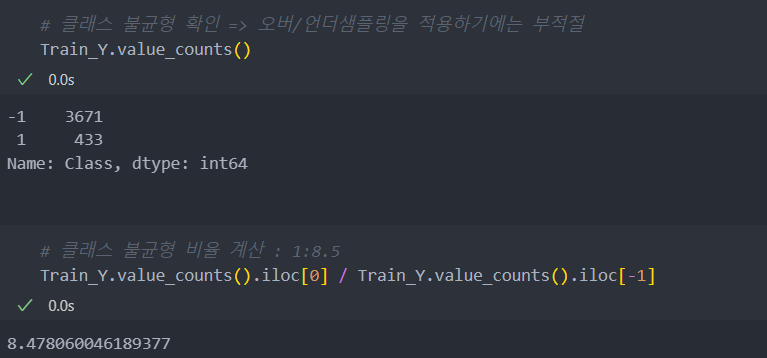
불균형 테스트
k-최근접 이웃을 사용하여 클래스가 불균형한지 테스트해보자.
결과 recall_score는 66%, accuracy_score는 96% 정도의 수치가 나온다.
recall_score는 66%로 불균형이 라벨의 비율에 비해서 심각한 수준은 아님을 알 수 있다.
# kNN을 사용한 클래스 불균형 테스트
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
# 인스턴스화
kNN_model = KNN(n_neighbors = 11).fit(Train_X, Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.6587301587301587
accuracy_score: 0.9634502923976608비용 민감 모델 적용
비확률 모델 서포트 백터 머신으로 테스트를 진행해보자.
SVC 모델의 하이퍼파라미터를 조절하지 않으면 KNN 모델보다 성능이 더 떨어지는 것을 볼 수 있다.
# 모델 불러오기
from sklearn.svm import SVC
# 인스턴스화
model = SVC().fit(Train_X, Train_Y)
pred_Y = model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.05555555555555555
accuracy_score: 0.9115497076023392이제 클래스의 가중치를 조절하여 서포트 백터 머신 모델에 적용시키면,
아래와 같이 recall_score가 96%로 높은 수치를 보여주는 반면 accuracy_score 63%로 수치가 떨어진 것을 볼 수 있다.
class_weight를 조절하여 원하는 score 수치를 이끌어낼 수 있도록 한다.
# 클래스 1의 비율이 적었기에, 1에 가중치를 더 주는 방향으로 클래스 웨이트 조정
model = SVC(class_weight = {1:8, -1:1}).fit(Train_X, Train_Y) # '클래스 1'에는 가중치 8, '클래스 -1'에는 가중치 1
pred_Y = model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.9603174603174603
accuracy_score: 0.6337719298245614