
클래스 불균형
클래스 변수가 하나의 값에 치우친 데이터로 학습한 분류 모델이 치우친 클래스에 대해 편향되는 문제.
- 클래스 불균형 문제가 있는 모델은 정확도는 높지만, 재현율이 매우 낮은 경향이 있다.
용어 정리
- 다수 클래스 : 대부분의 샘플이 속한 클래스
- 소수 클래스 : 대부분의 샘플이 속하지 않은 클래스 - 관심 대상
- 위양성 비용(False Positive) : 부정 클래스 샘플을 긍정 클래스 샘플로 분류해서 발생하는 비용
- 위음성 비용(False Negative) : 긍정 클래스 샘플을 부정 클래스 샘플로 분류해서 발생하는 비용
- 보통 위음성 비용이 위양성 비용보다 훨씬 크다
- 절대 부족 : 소수 클래스에 속한 샘플 개수가 절대적으로 부족한 상황
불균형 탐색
비율 탐색
불균형 불균형 비율이 9이상이면 평향된 모델이 학습될 가능성이 있음.
클래스 불균형 비율 = 다수 클래스에 속한 샘플 수 / 소수 클래스에 속한 샘플 수
k-최근접 이웃 활용
k-최근접 이웃은 이웃의 클래스 정보를 바탕으로 분류를 하기에 클래스 불균형에 매우 민감하다.
- k(이웃 수)값이 크면 클수록 민감하므로 보통 5~11 정도의 k를 설정
언더 샘플링
다수 클래스의 샘플을 삭제(보통 원본 샘플이 많을 때)
결정 경계에 가까운 다수 클래스 샘플 제거.
NearMiss
imblearn.under_sampling.NearMiss
가장 가까운 n개의 소수 클래스 샘플까지 평균 거리가 짧은 다수 클래스 샘플을 순서대로 제거.
주요인자
- sampling_strategy : 사전 형태로 입력하여 클래스별로 생성하는 샘플 개수 조절(입력하지 않으면 1:1 비율이 맞을 때까지 샘플 삭제)
- k_neighbors : 평균 거리를 구하는 소수 클래스 샘플 수
- version : NearMissdml version으로, 2를 설정하면 모든 소수 클래스 샘플까지의 평균 거리를 사용
- 메서드 : .fit_resample(X, Y) - X와 Y에 대해 NearMiss를 적용한 결과를 ndarray 형태로 반환
실습
다음의 데이터로 실습을 진행해보자.
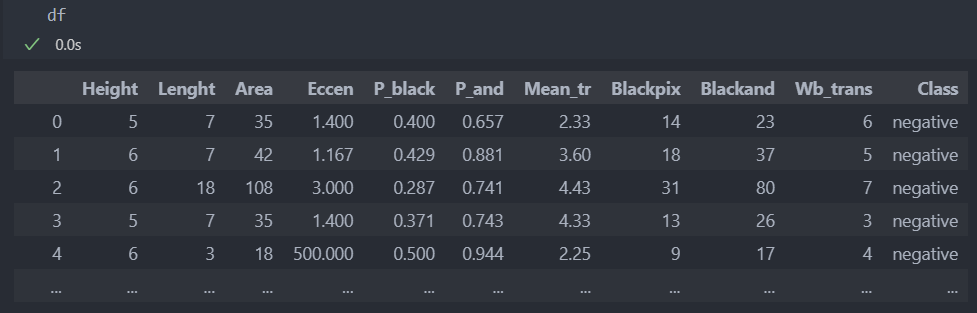
먼저 데이터를 data/label, 학습/평가 데이터로 분리하고, label은 P/N으로 되어있어 수치형으로 바꿔준다.
# 특징과 라벨 분리
X = df.drop('Class', axis = 1)
Y = df['Class']
# 학습 데이터와 평가 데이터 분할
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)
# label class 수치형으로 변환
Train_Y.replace({"negative":-1, "positive":1}, inplace = True)
Test_Y.replace({"negative":-1, "positive":1}, inplace = True)라벨 클래스의 불균형이 있으며 1(positive)의 비율이 11% 정도로 매우 작은 편이다.
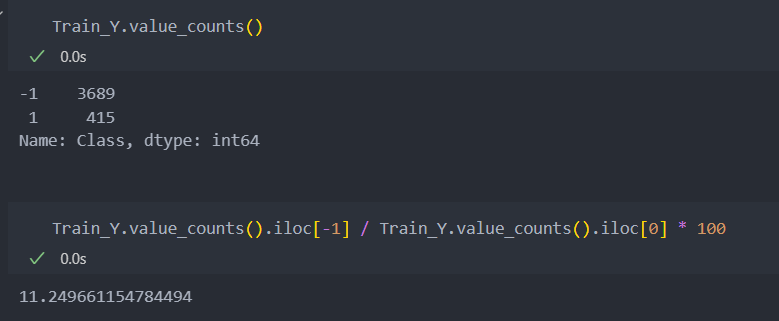
기존 클래스 비율로 진행
k-최근접 이웃을 사용하여 클래스가 불균형한지 테스트해보자.
accuracy_score은 96%이고 recall_score은 74%로 라벨 클래스로 보았을 때보다는 클래스 불균형이 심하지 않다고 판단할 수 있다.
# kNN을 사용한 클래스 불균형 테스트
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
# 모델 인스턴스
kNN_model = KNN(n_neighbors = 11).fit(Train_X, Train_Y)
# 결과 확인
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.7430555555555556
accuracy_score: 0.96345029239766081:1 비율로 클래스 언더 샘플링
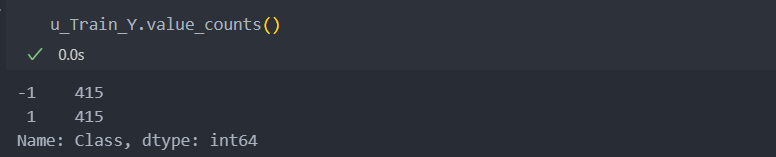
이제 언더 샘플링을 하여 비율은 1:1까지 삭제하여 진행해보자.
인자 sampling_strategy을 입력하지 않으면 자동으로 1:1까지 삭제시킨다.
from imblearn.under_sampling import NearMiss
# 인스턴스화
NM_model = NearMiss(version = 2) # version = 2: 모든 소수 클래스 샘플까지의 평균 거리를 활용
# NearMiss 적용
u_Train_X, u_Train_Y = NM_model.fit_resample(Train_X, Train_Y)
u_Train_X = pd.DataFrame(u_Train_X, columns = X.columns)
u_Train_Y = pd.Series(u_Train_Y)비율 1:1로 잘 삭제가 되었는지 확인해보자.
이제 KNN을 활용하여 score을 알아보자.
recall_score은 92%까지 매우 많이 상승했지만 accuracy_score가 22%로 너무 많이 감소하여, 오히려 다수 클래스가 제대로 분리되지 못하는 경우가 발생했음이 짐작된다.
# kNN 재적용을 통한 성능 변화 확인
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
# 인스턴스화
kNN_model = KNN(n_neighbors = 11).fit(u_Train_X, u_Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.9236111111111112
accuracy_score: 0.21856725146198831:5 비율로 클래스 언더 샘플링
리샘플링을 하지 않았을 때에도 재현율이 크게 떨어지지 않았고, 1:1까지 삭제하였을 때 accuracy_score가 너무 떨어져 성능이 좋지 않았다.
이번에는 인자 sampling_strategy 조절하여 비율을 1:5까지만 삭제하고 진행해보자.
from imblearn.under_sampling import NearMiss
# 인스턴스화
NM_model = NearMiss(version = 2, sampling_strategy = {1:u_Train_Y.value_counts().iloc[-1],
-1:u_Train_Y.value_counts().iloc[-1] * 5}) # 5:1 정도의 비율로 언더샘플링 재수행
# 언더 샘플링
u_Train_X, u_Train_Y = NM_model.fit_sample(Train_X, Train_Y)
u_Train_X = pd.DataFrame(u_Train_X, columns = X.columns)
u_Train_Y = pd.Series(u_Train_Y)언더 샘플링한 후 데이터의 수가 1:5로까지 삭제되었는지 확인해보자.
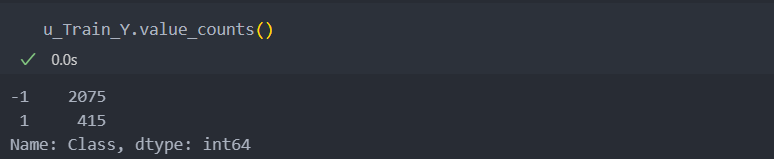
그리고 다시 score를 확인해보자.
1:1일 때 보다, recall_score는 88%로 조금 하락했지만, accuracy_score는 67%로 상승했음을 알 수 있다.
이것을 바탕으로 accuracy_score를 더 상승시키거나 조절할 때, 삭제할 샐플수를 조절하여 진행하면 된다.
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
# 인스턴스화
kNN_model = KNN(n_neighbors = 11).fit(u_Train_X, u_Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.8819444444444444
accuracy_score: 0.6703216374269005