
클래스 불균형
클래스 변수가 하나의 값에 치우친 데이터로 학습한 분류 모델이 치우친 클래스에 대해 편향되는 문제.
- 클래스 불균형 문제가 있는 모델은 정확도는 높지만, 재현율이 매우 낮은 경향이 있다.
용어 정리
- 다수 클래스 : 대부분의 샘플이 속한 클래스
- 소수 클래스 : 대부분의 샘플이 속하지 않은 클래스 - 관심 대상
- 위양성 비용(False Positive) : 부정 클래스 샘플을 긍정 클래스 샘플로 분류해서 발생하는 비용
- 위음성 비용(False Negative) : 긍정 클래스 샘플을 부정 클래스 샘플로 분류해서 발생하는 비용
- 보통 위음성 비용이 위양성 비용보다 훨씬 크다
- 절대 부족 : 소수 클래스에 속한 샘플 개수가 절대적으로 부족한 상황
불균형 탐색
비율 탐색
불균형 불균형 비율이 9이상이면 평향된 모델이 학습될 가능성이 있음.
클래스 불균형 비율 = 다수 클래스에 속한 샘플 수 / 소수 클래스에 속한 샘플 수
k-최근접 이웃 활용
k-최근접 이웃은 이웃의 클래스 정보를 바탕으로 분류를 하기에 클래스 불균형에 매우 민감하다.
- k(이웃 수)값이 크면 클수록 민감하므로 보통 5~11 정도의 k를 설정
오버 샘플링
소수 클래스의 샘플을 생성(보통 원본 샘플이 적을 때)
결정 경계에 가까운 소수 클래스 샘플 생성.
SMOTE
imblearn.over_sampling.SMOTE
소수 클래스 샘플을 임의로 선택하고, 선택된 샘플의 이웃 가운데 하나의 샘플을 또 임의로 선택하여 그 중간에 샘플을 생성하는 과정 반복.
주요인자
- sampling_strategy : 사전 형태로 입력하여 클래스별로 생성하는 샘플 개수 조절(입력하지 않으면 1:1 비율이 맞을 때까지 샘플 생성)
- k_neighbors : SMOTE에서 고려하는 이웃 수(보통 1, 3, 5로 잡음)
- 메서드 : .fit_resample(X, Y) - X와 Y에 대해 SMOTE를 적용한 결과를 ndarray 형태로 반환
실습
다음의 데이터로 실습을 진행해보자.
먼저 데이터를 data/label, 학습/평가 데이터로 분리한다.
# 특징과 라벨 분리
X = df.drop('Y', axis = 1)
Y = df['Y']
# 학습 데이터와 평가 데이터 분할
from sklearn.model_selection import train_test_split
Train_X, Test_X, Train_Y, Test_Y = train_test_split(X, Y)데이터의 특성은 많고 데이터 자체는 적다.

라벨을 보면 클래스 비율이 차이가 심해 클래스 불균형이 있을 가능성이 있고, 언더 샘플링으로 샘플수를 줄이기에는 데이터가 너무 적어서 오버 샘플링을 해야 한다.


기존 클래스 비율로 진행
k-최근접 이웃을 사용하여 클래스가 불균형한지 테스트해보자.
모델 결과의 accuracy_score가 92%인것에 반해, recall_score(재현율)이 0으로 불균형이 있다는 것을 확인할 수 있다.
클래스 불균형 문제가 있다면 recall_score은 0에 가까운 수치가 나오기에 판단하기에 용이하다.
# kNN을 사용한 클래스 불균형 테스트
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.metrics import *
kNN_model = KNN(n_neighbors = 11).fit(Train_X, Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
출력:
recall_score: 0.0
accuracy_score: 0.9234693877551021:1 비율로 오버 샘플링
SMOTE를 사용하여 오버 샘플링을 진행해보자.
from imblearn.over_sampling import SMOTE
# SMOTE 인스턴스 생성
oversampling_instance = SMOTE(k_neighbors = 3)
# 오버샘플링 적용
o_Train_X, o_Train_Y = oversampling_instance.fit_sample(Train_X, Train_Y)
# ndarray 형태가 되므로 다시 DataFrame과 Series로 변환 (남은 전처리가 없다면 하지 않아도 무방)
o_Train_X = pd.DataFrame(o_Train_X, columns = X.columns)
o_Train_Y = pd.Series(o_Train_Y)이제 비율을 확인해보면 1:1이 되었음을 알 수 있다.
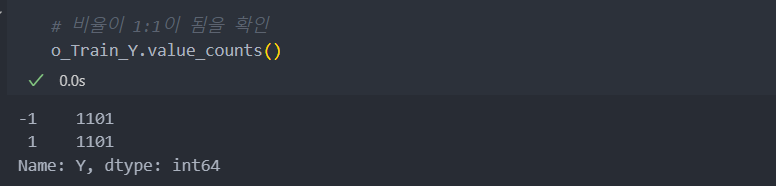
그리고 다시 KNN을 진행해보면 정확도가 줄어든 대신에 재현율이 오른 것을 볼 수 있다.
# 같은 모델로 다시 평가: 정확도는 감소했으나, 재현율이 크게 오름을 확인
kNN_model = KNN(n_neighbors = 11).fit(o_Train_X, o_Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.43333333333333335
accuracy_score: 0.56632653061224491:0.5 비율로 오버 샘플링
이제는 클래스 비율은 1:1이 아닌 1:0.5로 해서 진행해보자.
나머지는 같지만, sampling_strategy 인자는 dict()자료형으로 입력을 해주어야 한다.
from imblearn.over_sampling import SMOTE
# SMOTE 인스턴스 생성
oversampling_instance = SMOTE(k_neighbors = 3, sampling_strategy = {1:int(Train_Y.value_counts().iloc[0] / 2), # 기존의 -1 클래스의 크기에서 1/2 수 만큼 생성
-1:Train_Y.value_counts().iloc[0]}) # 기존의 -1 인 클래스 수와 동일하도록
# 오버샘플링 적용
o_Train_X, o_Train_Y = oversampling_instance.fit_resample(Train_X, Train_Y)
# ndarray 형태가 되므로 다시 DataFrame과 Series로 변환 (남은 전처리가 없다면 하지 않아도 무방)
o_Train_X = pd.DataFrame(o_Train_X, columns = X.columns)
o_Train_Y = pd.Series(o_Train_Y)
그리고 같은 모델로 다시 평가해보자.
1:1 때보다 정확도는 증가하고 재현율은 감소하는 것을 확인할 수 있고, 이것을 통해 적절한 클래스 오버 샘플링 수를 결정한다.
# 인스턴스화
kNN_model = KNN(n_neighbors = 11).fit(o_Train_X, o_Train_Y)
pred_Y = kNN_model.predict(Test_X)
print('recall_score: ', recall_score(Test_Y, pred_Y))
print('accuracy_score: ', accuracy_score(Test_Y, pred_Y))
결과:
recall_score: 0.3333333333333333
accuracy_score: 0.6760204081632653