* 밑바닥부터 시작하는 딥러닝 책을 참고하여 작성함
7.3 풀링 계층
풀링은 세로, 가로 방향의 공간을 줄이는 연산이다. 최대 풀링(max pooling)은 대상 영역 중에서 최댓값을 구하는 것이다. 설정한 스트라이드의 크기 대로 윈도우를 설정하고 그 간격으로 이동한다.
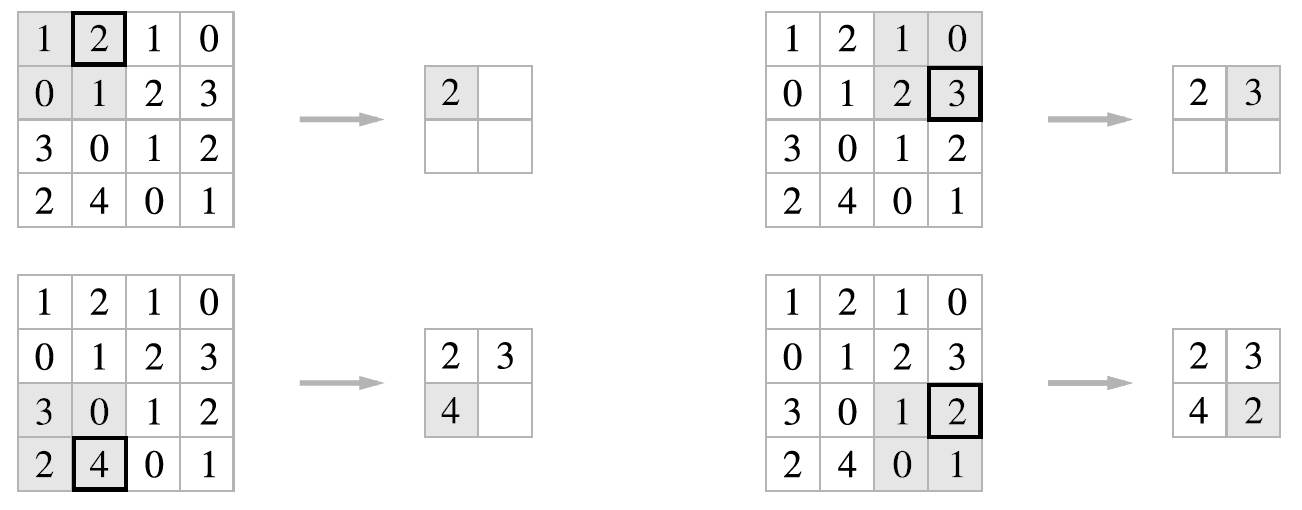
이 그림을 보면 2x2 최대 풀링을 스트라이드 2로 처리하는 것이다. 2x2 크기의 영역에서 가장 큰 원소 하나를 꺼내고 스트라이드 2로 설정했으므로 2x2 윈도우가 2칸 간격으로 이동한다.
7.3.1 풀링 계층의 특징
학습해야 할 매개변수가 없다
-
풀링은 대상 영역에서 최댓값이나 평균을 취하는 명확한 처리이므로 학습할 것이 없다.
-
채널수가 변하지 않는다.
-
입력의 변화에 영향을 적게 받는다.

7.4 합성곱/풀링 계층 구현하기
합성곱 계층과 풀링 계층은 복잡해 보이지만 사실 '트릭'을 사용하면 쉽게 구현 가능
7.4.1 4차원 배열
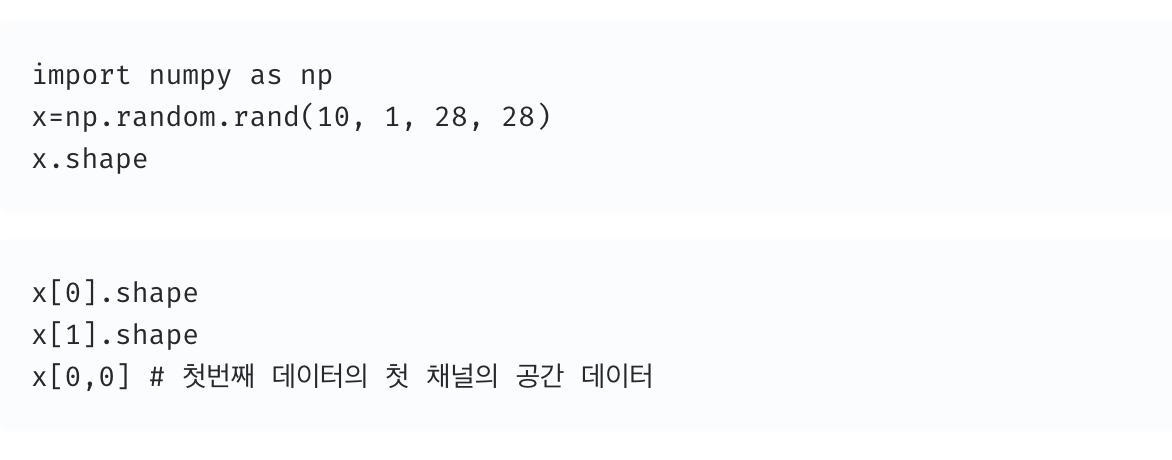
CNN은 계층 사이를 흐르는 데이터는 4차원
- 데이터 형상이 높이 28, 너비 28, 채널 1개, 데이터 10개를 구현한 것이다.
7.4.2 im2col로 데이터 전개하기
넘파이에 for 문을 사용하면 성능이 떨어지기 때문에 im2col이라는 편의 함수를 이용해본다. im2col은 입력 데이터를 필터링하기 좋게 전개하는 함수이다.
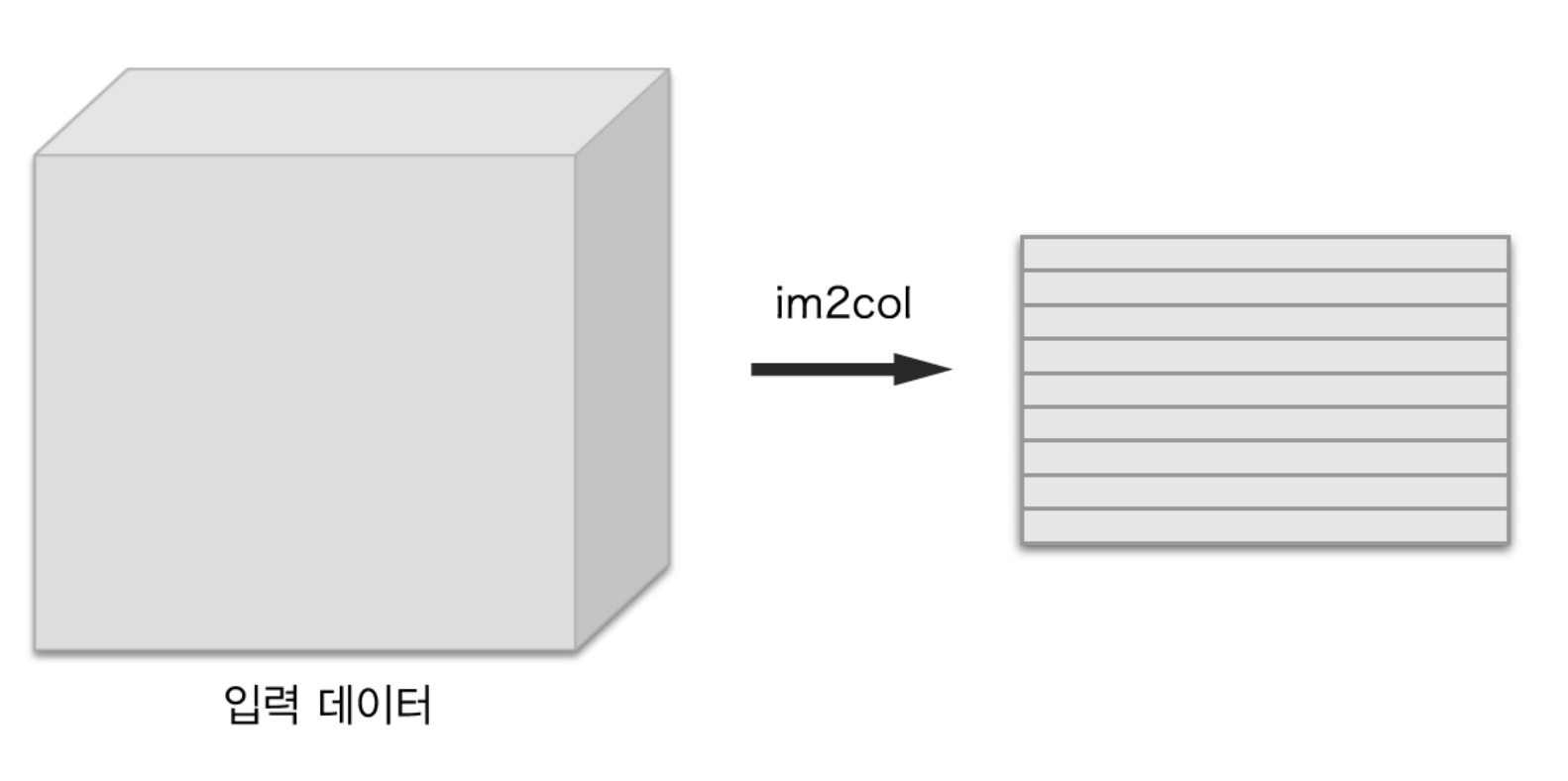
- 위 그림처럼 3차원 입력 데이터에 im2col을 적용하면 2차원 행렬로 바뀐다.
(정확히는 배치 안의 데이터 수까지 포함한 4차원 데이터를 2차원으로 변환)
im2col을 사용하면 원소의 수가 원래 블록의 원소 수보다 많아 져서 메모리를 많이 소비한다. 하지만 컴퓨터는 큰 행렬의 곱셈을 빠르게 계산할 수 있기 때문에 im2col을 이용한다. im2col로 데이터를 전개한 다음에는 합성곱 게층의 필터(가중치)를 1열로 전개하고 두 행렬의 내적을 계산하면 된다. 이렇게 출력한 결과는 2차원 행렬이다. CNN은 4차원 배열 데이터로 저장하기 때문에 reshape을 이용해서 4차원으로 변형한다.

7.4.3 합성곱 계층 구현하기


- im2col을 사용하여 합성곱계층을 구현한것
- 여기서 FN은 필터개수, C는 채널, FH는 필터높이, FW는 필터 너비
- 굵은 글씨 부분에 reshape에 -1을 지정해줬는데 이렇게 하게 되면 다차원 배열의 원소 수가 변환 후에도 똑같이 유지되도록 적절하게 묶어주는 역할을 함
- 원소의 수가 750개라고 하면 reshape(10,-1)을 호출하면 750개의 원소를 10묶음으로 해서 (10,75)인 배열로 만들어줌
- 마지막 출력 데이터를 적절한 형상으로 바꿔주는 것이 forward 구현의 마지막임
7.4.4 풀링 계층 구현하기
풀링의 경우엔 채널쪽이 독립적이라는 점이 합성곱 계층 때와는 다른점
- 채널별로 전개한 다음에 해당 행에서 최댓값, 혹은 평균값만을 골라내면 된다.
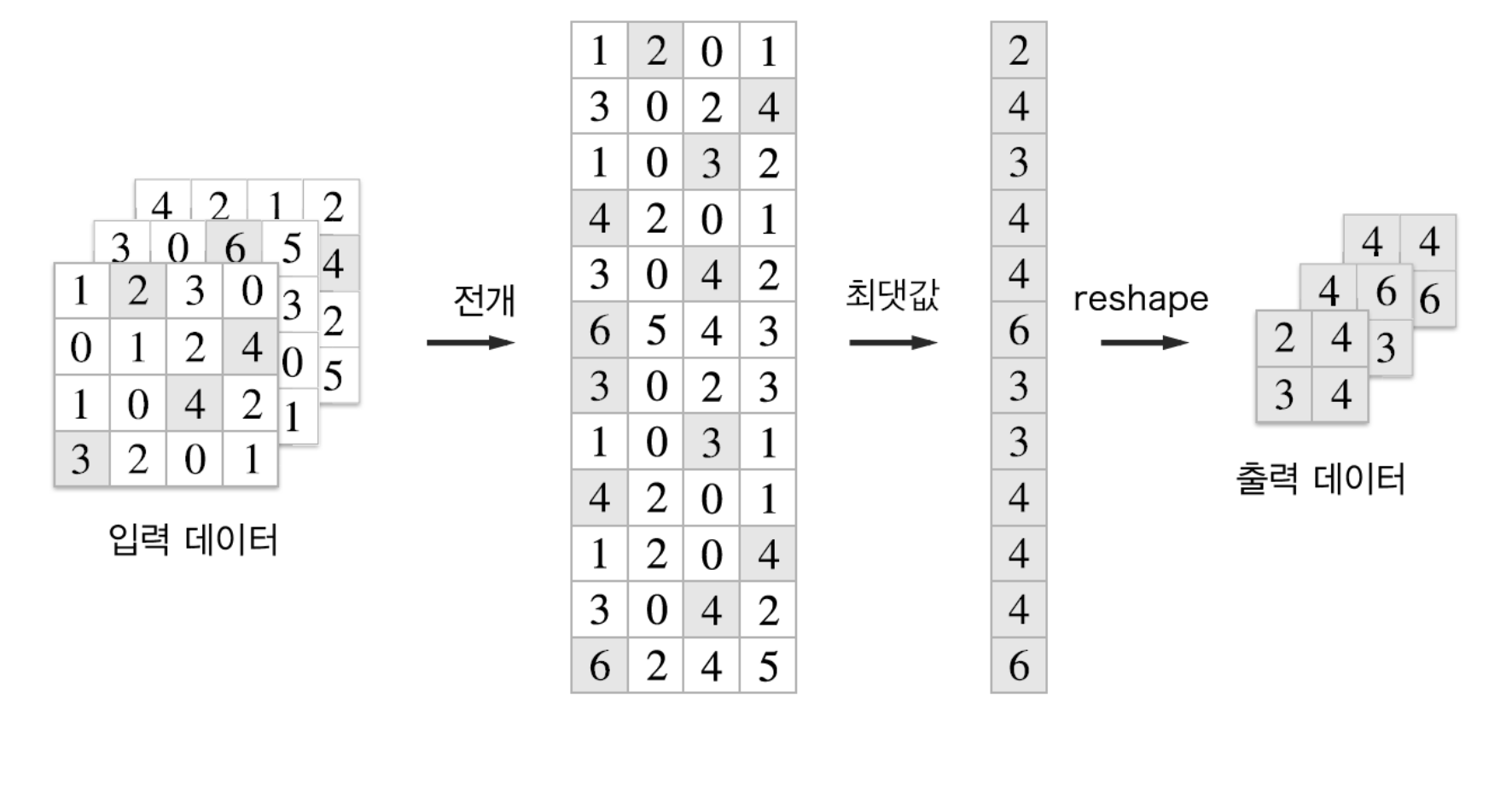
아래는 풀링계층의 forward 처리흐름을 파이썬으로 나타낸 것

<풀링계층 구현단계>
1. 입력데이터를 전개한다
2. 행 별 최댓값을 구한다.
3. 적절한 모양으로 성형한다.
