
분산 학습 및 추론을 쉽고 효율적, 또 효과적으로 만드는 딥러닝 최적화 라이브러리 DeepSpeed ZeRO
Reference
https://github.com/microsoft/DeepSpeed
https://www.deepspeed.ai/posts/
https://arxiv.org/pdf/1910.02054.pdf
1. 서론
최근 자연어처리에서의 추세를 보면 딥러닝 모델은 점점 더 커지고 있으며, 모델 크기의 증가는 상당한 정황률 향상을 제공 중입니다. NLP 분야에서는 BERT-Large(0.3B), GPT-2(1.5B), Megatron-LM(8.3B), T5(11B)와 같은 모델을 예시로 들 수 있습니다. 이러한 모델은 수십, 수백억 개의 파라미터로 구성되어 있기 때문에 이를 학습하기 위해서는 비용, 시간 및 코드 통합의 용이성 때문에 학습이 어렵습니다. 이 문제를 해결하기 위해서 Microsoft에서 DeepSpeed라는 딥러닝 최적화 라이브러리를 공개했습니다.
DeepSpeed는 규모, 속도, 비용 및 사용성을 개선하여 대규모 모델 학습을 크게 발전시켜 1,000억 개의 파라미터를 학습할 수 있는 능력을 제공합니다. 그 중, ZeRO(Zero Redundancy Optimizer)는 모델 및 데이터 병렬화에 필요한 리소스를 크게 줄이는 동시에 학습할 수 있는 파라미터의 수를 크게 늘릴 수 있는 새로운 병렬 최적화 도구입니다.
2. ZeRO?
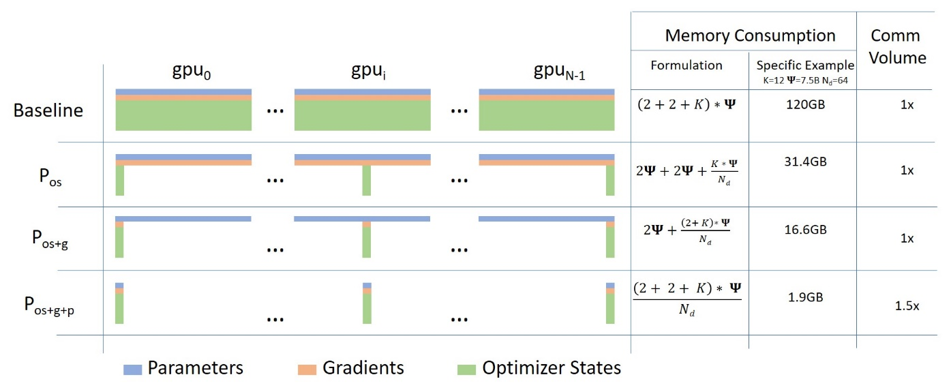
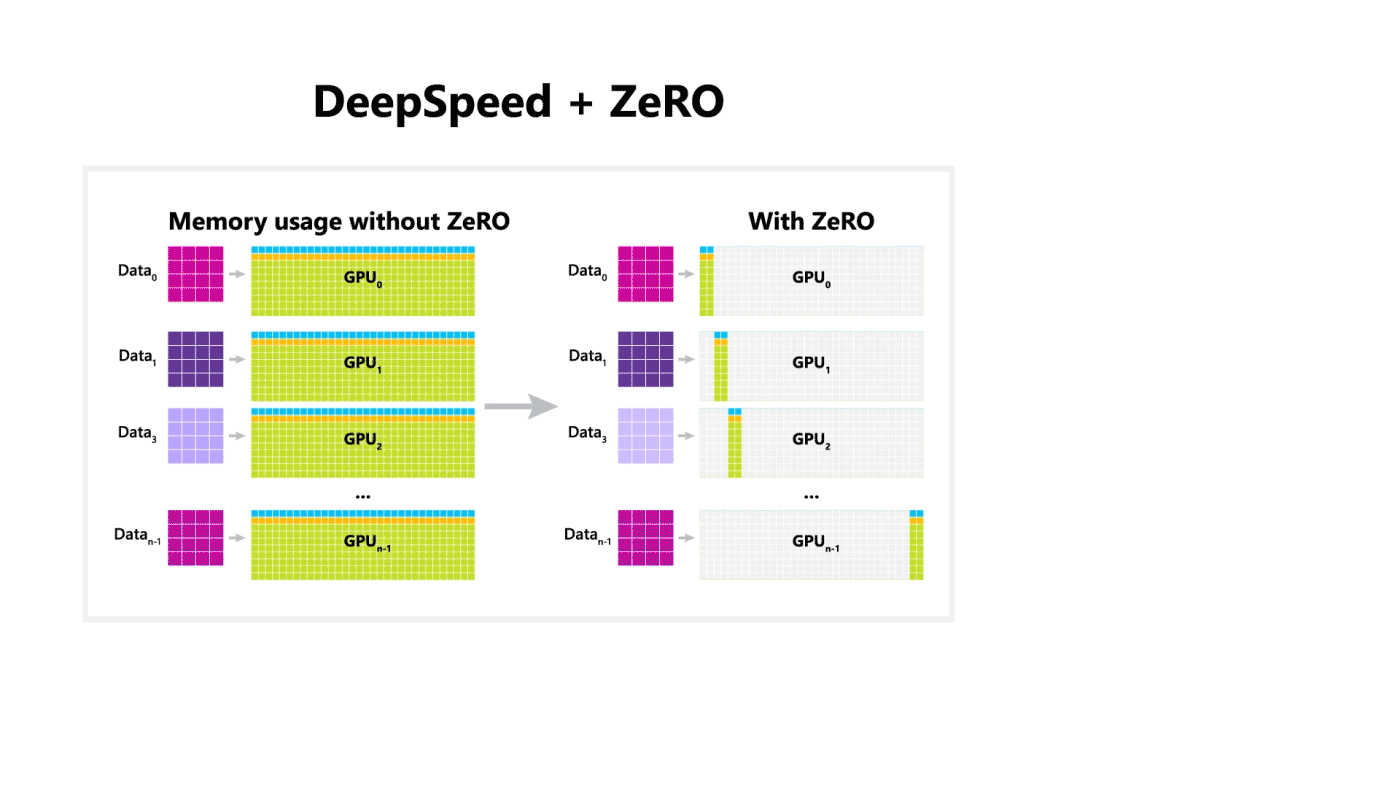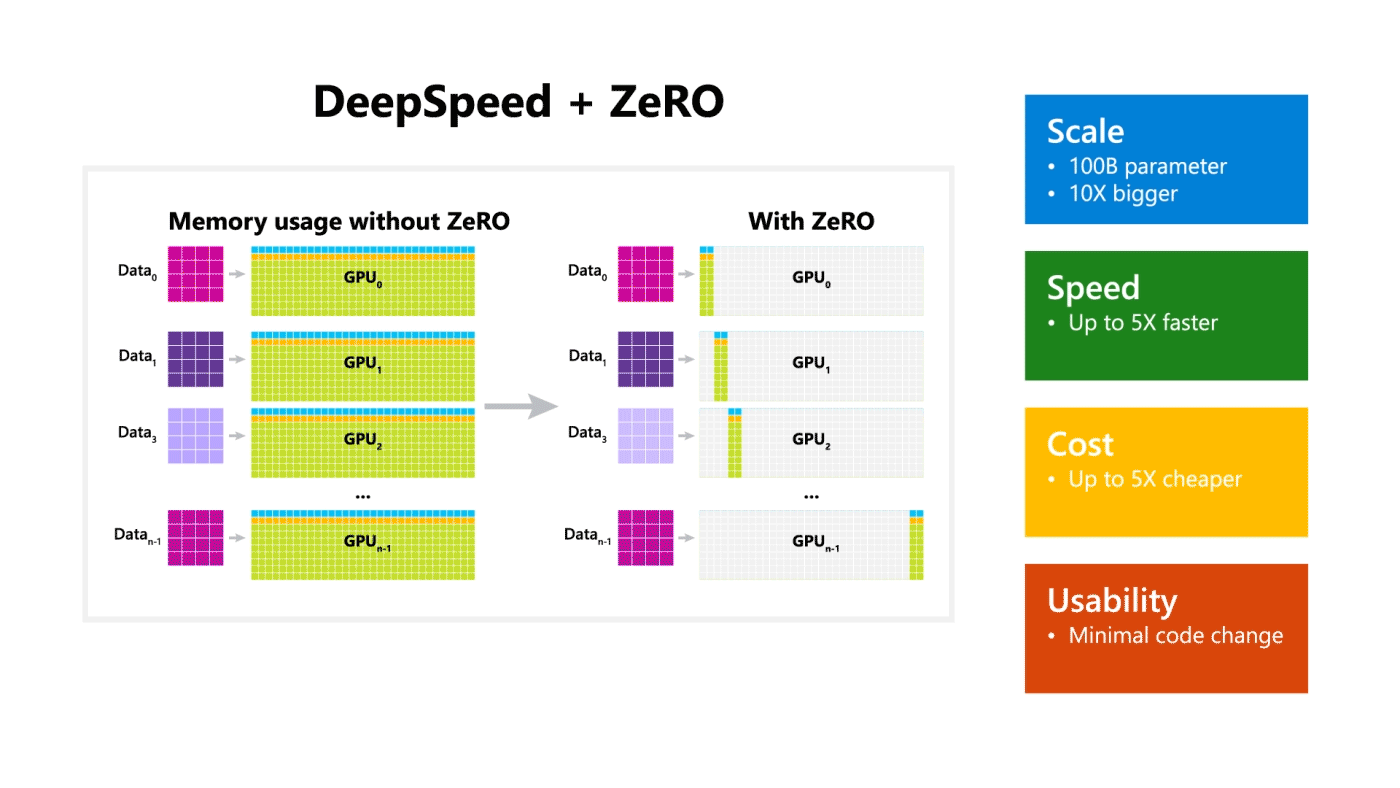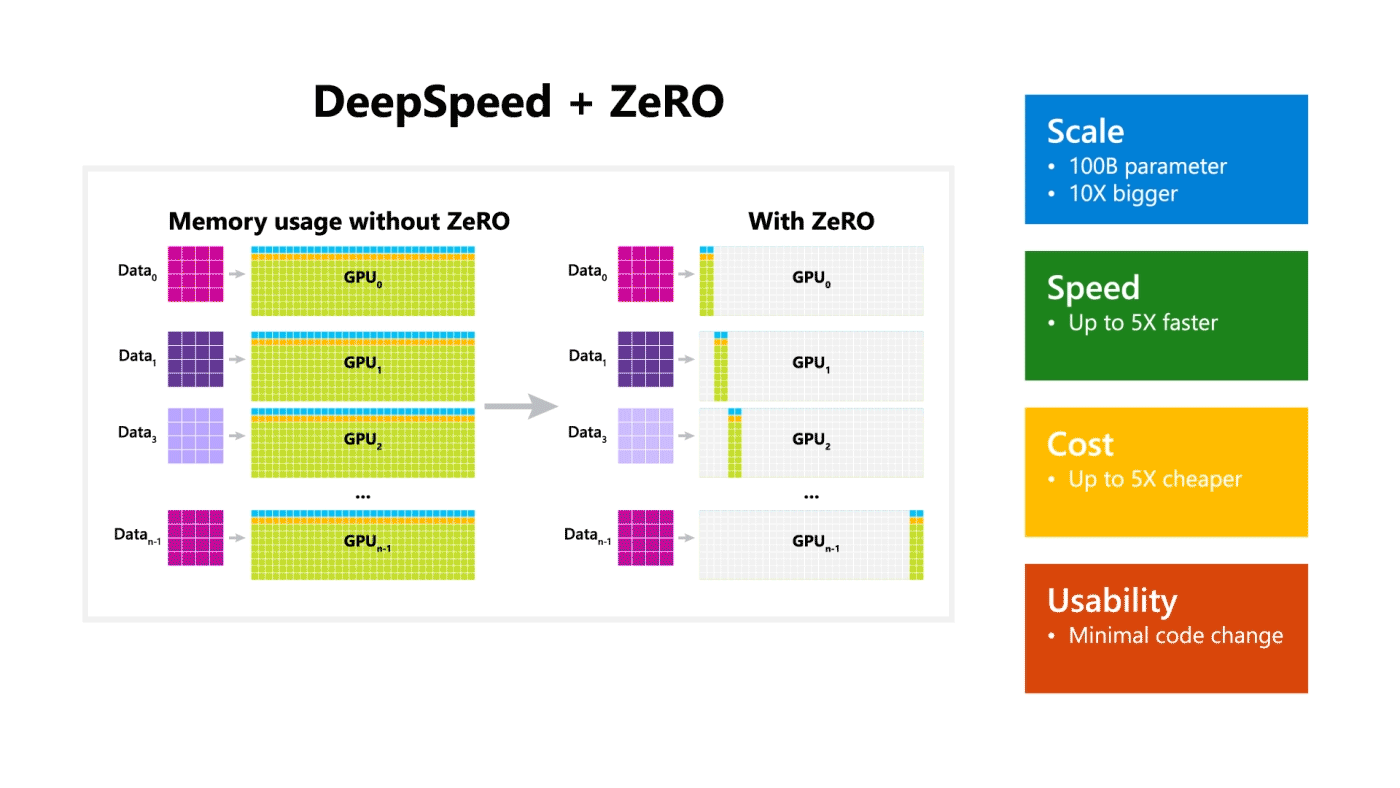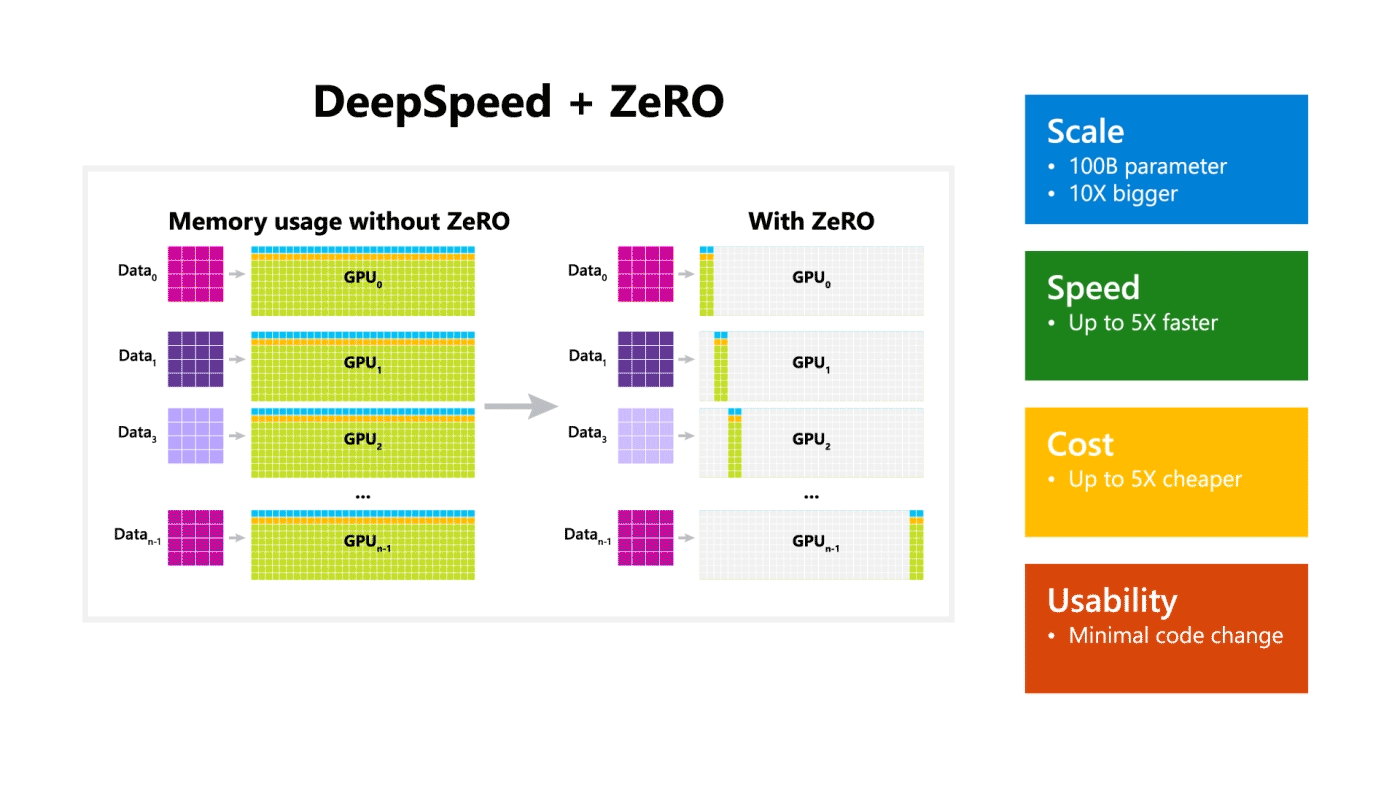
기존 딥러닝 모델의 분산 학습에서는 데이터는 분산되지만 모델을 학습시키기 위한 값(Optimizer State, Gradient, Paramter)은 각 GPU마다 복제해서 가지고 있어야 했습니다. 이는 위 그림의 Baseline을 참고하면 됩니다. MS에서는 약 1.5억 개의 파라미터로 구성된 GPT-2 모델은 3GB 정도의 메모리를 차지함에도 불구하고, 32GB GPU에서도 학습이 불가능하다는 것에서 의문을 가지고 상세 분석을 진행한 결과 나머지 메모리는 복제된 파라미터에 의해서 낭비된다는 점을 알아냈습니다.
따라서 ZeRO는 분산 학습 과정에서의 불필요한 메모리의 중복을 제거하여 같은 환경 내에서 대용량의 모델을 학습을 가능하도록 합니다. ZeRO에서는 3가지 주요 최적화 단계가 있습니다.
- Stage 1. Optimizer State Partitioning() - 메모리 4배 감소
- Stage 2. Add Gradient Partitioning() - 메모리 8배 감소
- Stage 3. Add Parameter Partitioning() - GPU의 개수와 메모리 감소 정도는 비례.(예를 들어, 64개의 GPU를 사용한다면 메모리 64배 감소)
ZeRO-1
ZeRO-1은 Optimizer Stage Partitioning을 구현하여 1,000억 개의 파라미터를 가진 모델을 지원할 수 있는 기능을 가졌습니다.
ZeRO-2
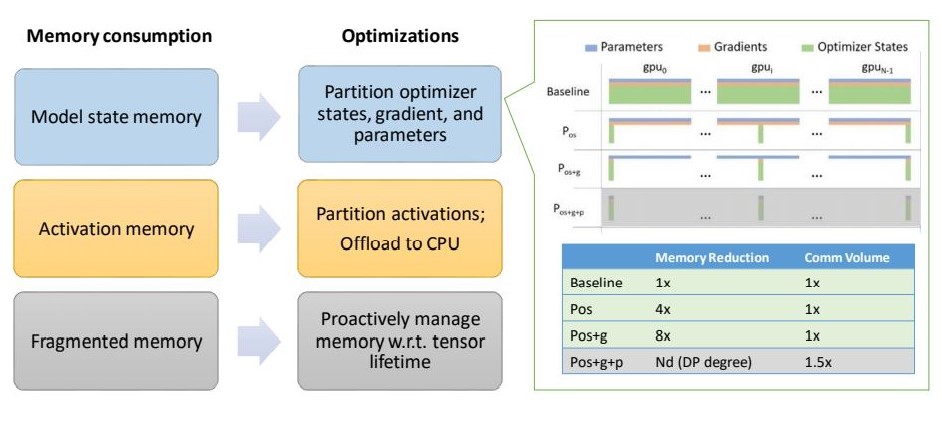
ZeRO-2는 기존 ZeRO-1에서 Optimizer Stage Partitioning 외에도 gradient, activation memory, fragmented memory의 메모리 공간을 줄이는 새로운 기술을 도입하여 메모리 최적화 범위를 확장합니다.
Model state memory
- ZeRO-2는 첫 번째 단계() 외에도 두 번째 단계인 partitioning gradients()를 지원함으로써 GPU 당 메모리 소비를 2배 더 줄입니다.
- 이는 기존 데이터 병렬 처리와 비교하면 동일한 통신 볼륨으로 최대 8배의 메모리를 절약합니다.
Activation memory
- activation partitioning을 통해 기존 모델 병렬화 방식에서 activation memory의 복제를 제거하는 기술을 도입합니다.
- 또한, 상황에 따라서 activation memory를 CPU로 보냅니다.(모델 사이즈가 매우 크거나, 메모리가 극도로 제한된 경우)
Fragmented memory
- 다양한 tensor의 수명 주기로 인해서 학습 중에 메모리 단편화가 발생한다는 것을 발견했습니다.
- 이로 인해 사용 가능한 메모리가 충분하더라도 메모리 할당에 실패할 때가 있기 때문에, ZeRO-2에서는 텐서의 서로 다른 수명을 기반으로 메모리를 관리하여 메모리 단편화를 방지합니다.
이 코드는 학습 최적화 라이브러리인 DeepSpeed와 함께 릴리즈 되었고, PyTorch와 호환됩니다.
ZeRO-1 vs ZeRO-2
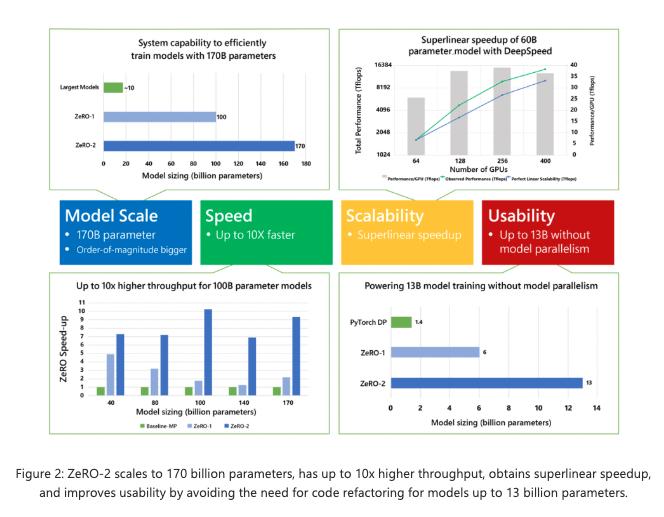
ZeRO-2는 4가지 측면에서 탁월(크기, 속도, 확장성 및 사용성)하다. 더 큰 규모의 모델을 지원하고 최대 10배 빠른 학습 속도, 확장성과 향상된 사용성을 통해 대규모 모델 학습을 가능하게 합니다. 이 네 가지 측면은 아래에서 자세히 설명합니다.
Model scale
- OpenAI GPT-2, NVIDIA Megatron-LM, Google T5와 같이 최신 State-of-the-art 모델들은 각각 1.5B, 8.3B, 11B의 파라미터를 가지고 있습니다.
- ZeRO-2는 이러한 모델들보다 크기가 더 큰 1,700억 개의 파라미터를 효율적으로 학습할 수 있는 시스템을 제공합니다.(그림 2의 왼쪽 상단)
- 실험은 400개의 NVIDIA V100 GPU를 사용하였고, 더 많은 GPU(예: 1,000개)로 ZeRO-2를 사용하면 2,000억 개의 파라미터도 가능.
Speed
- ZeRo-2는 ZeRO-1에 비해 향상된 메모리 효율성으로 처리량이 증가하고 학습이 더 빨라집니다. 그림 2(왼쪽 아래)는 ZeRO-2, ZeRO-1 및 기존 모델 병렬화의 시스템 처리량을 보여줍니다.
Megatron-LM은 tensor-slicing model parallelism를 사용한다. Megatron-LM의 tensor-slicing model parallelism에 DeepSpeed ZeRO-2의 data parallelism을 추가하면 DeepSpeed가 Megatron-LM보다 10x 더 빠르다.
Scalability
- NVIDIA GPU를 두 배로 추가하면 성능이 두 배 이상 향상되는 super-linear speed up을 달성할 수 있습니다(그림 2의 오른쪽 위).
- ZeRO-2는 데이터 병령화의 정도를 높임으로써 footprint of the model states의 메모리를 줄일 수 있었고, 이를 통해 GPU 당 더 큰 배치 사이즈를 사용할 수 있어서 성능 향상을 이룰 수 있습니다.
Democratizing large model training
- ZeRO-2는 일반적으로 모델 리팩토링을 필요로하는 model parallelism 없이 최대 130억 개의 파라미터를 효율적으로 학습할 수 있습니다(그림 2의 오른쪽 아래). 130억 개의 파라미터는 보통의 대용량 모델(예 : Google T5 등)보다 큽니다.
- 일반적인 data parallelism(예 : PyTorch Distributed Data Parallel)은 14억 개의 파라미터 모델로도 메모리가 부족한 반면, ZeRO-1은 최대 60억 개의 파라미터를 지원합니다.
BERT training
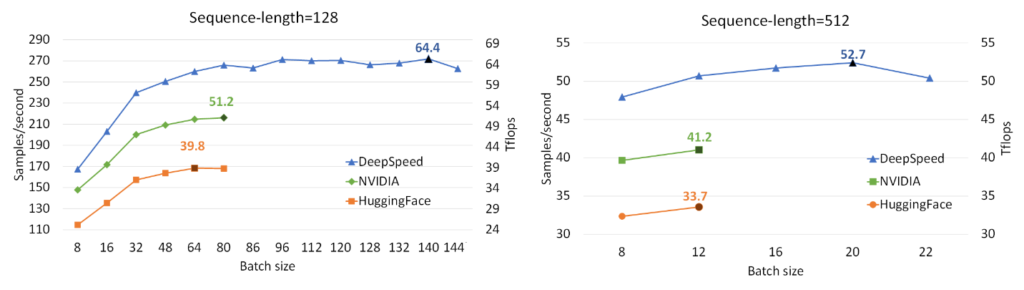
가장 빠른 BERT 학습 시간 달성 : 1,024개의 NVIDIA V100 GPU로 44분 소요
- 위 그림은 단일 V100 GPU에서 DeepSpeed ZeRO, NVIDIA BERT, HuggingFace BERT의 성능을 비교한 결과입니다.
- DeepSpeed는 max length 128, 512인 시퀀스 길이에 대해서 각각 64, 53 teraflops(초당 272, 52 샘플을 처리)의 처리량을 달성하여 NVIDIA BERT에 비해 최대 28%, HuggingFace BERT에 비해 최대 62% 향상된 처리량을 보여줍니다.
- 또한 메모리 부족 없이 최대 1.8배 더 큰 배치 사이즈를 사용할 수 있습니다.

- 위의 표는 각 GPU 개수에 따른 BERT-Large 모델의 학습 시간을 나타냅니다. 1,024개의 V100 GPU를 사용하면 44분만에 BERT pre-training을 마칩니다!
- NVIDIA가 1,472의 V100 GPU로 47분이 소요되었다는 것과 비교하면 DeepSpeed는 30% 적은 리소스를 사용하면서도 속도가 더 빠릅니다.
- 1,024개의 V100 GPU를 사용할 때, NVIDIA BERT는 67분, DeepSpeed는 44분이 소요되기 때문에 학습 시간도 30% 이상 단축됩니다. 마찬가지로 256개의 GPU에서 NVIDIA BERT는 236분, DeepSpeed는 144분이 소요됩니다.
✏️
다음 시간에는 기존 PyTorch에서의 분산 처리와 DeepSpeed에서의 분산 처리 코드가 어떻게 다른지, 또 어떤 방식으로 적용할 수 있는지를 정리해보도록 한다.

잘 정리해주셔서 감사합니다