
Reference
https://www.deepspeed.ai/getting-started/
https://huggingface.co/docs/transformers/main_classes/deepspeed
https://junbuml.ee/huggingface-deepspeed-fairscale
이전 트레이닝 방식
학습 device
- CPU
- Single GPU
- 1 Node, Multi GPU
- Multi Node, Multi GPU
+ TPU
분산 학습 방식
- DataParallel
- Distributed Data Parallel
보통 single GPU, 1 Node Multi GPU를 많이 사용하고 단일 GPU에서 트레이닝하기 어려운 큰 모델의 경우에는 multi gpu+Data Parallel을 사용하여 학습을 진행했었다.
Data Parallel
기본 Data Parallel을 사용할 때는 하나의 디바이스가 데이터를 쪼개어 나누고, 각 디바이스에서의 처리 결과를 다시 모아서 계산하기 때문에 하나의 디바이스가 다른 디바이스에 비해 메모리 사용량이 많아진다. (아래 사진에서의 GPU-1과 같은 상황)
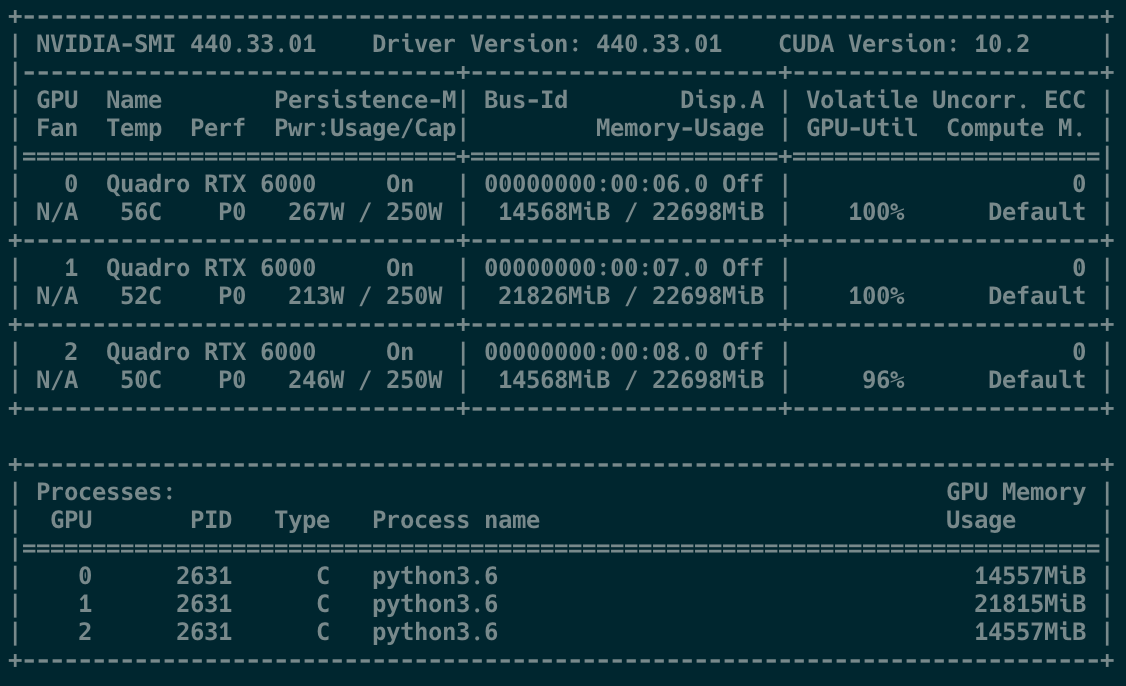
➡️ 메모리 불균형 문제가 발생!
Distributed Data Parallel
Distributed Data Parallel은 각각의 디바이스를 하나의 프로세스로 보고 각각의 프로세스에서 모델을 띄워서 사용하고, 역전파하는 과정에서만 내부적으로 그래디언트를 동기화하기 때문에 메모리 불균형을 일으키지 않는다.
- DataParallel은 Single Node, Multi Gpu 상황에서만 트레이닝 가능한 반면에 DDP는 Multi Node, Multi Gpu 트레이닝도 가능함.
하지만 더 큰 모델을 학습하기 위해서는 여전히 한계가 있다😂
(Data Parallel과 Distributed Data Parallel과 관련된 설명은 당근마켓 블로그에 설명이 잘 되어있다!)
DeepSpeed
DeepSpeed ZeRo(Zero Redundancy Optimizer)는 MS에서 만든 대규모 분산 딥러닝을 위한 새로운 메모리 최적화 기술로 적용시에 모델 및 데이터 병렬 처리에 필요한 리소스를 크게 감소시킬 수 있으며 학습할 수 있는 파라미터의 수를 크게 증가 가능하다. 이와 같은 내용은 이전 포스팅(효율적인 분산 학습을 위한 DeepSpeed ZeRO)에서 더 자세히 알 수 있다!
Installation
PyPI로 설치하기
pip install deepspeed
or
pip install transformers[deepspeed]- 여러 추가적인 옵션을 사용하기 위해서는
DS_BUILD_OPS=1 pip install deepspeed와 같이 환경 변수를 1로 설정하여 설치를 해야하는 경우도 있다. 현재 환경과 호환되는 옵션은ds_report로 확인할 수 있고 여러 옵션과 환경 변수에 관해서는 공식 홈페이지에서 볼 수 있다.
수동 설치하기
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.logTORCH_CUDA_ARCH_LIST : 현재 사용 중인 GPU에 따라 달라져야한다. 확인하는 방법은 아래와 같다.
# INPUT
CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
# OUTPUT
_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)- 위 와 같이 major=8, minor=6이 나온다면
TORCH_CUDA_ARCH_LIST="8.6"을 사용하고, 현재 환경에 여러 개의 다른 GPU가 있다면 위 명령어를 각각의 GPU에 대해 확인하여TORCH_CUDA_ARCH_LIST="6.1;8.6"과 같이 나열하여 설정이 가능하다.
Writing DeepSpeed Model
DeepSpeed Engine 초기화
- deepspeed.init_distributed()
- 기존에 Distributed Data Parallel을 사용할 때 초기화 하는 과정인
torch.distributed.init_process_group()와 같은 역할.

- 기존에 Distributed Data Parallel을 사용할 때 초기화 하는 과정인
- deepspeed.initialize()

-
Parameters
args :local_rank및deepspeed_config를 포함
model : torch.nn.module class 기반의 모델(transformers model 포함)
model_parameters : model.parameters()
-
Returns : tuple of
engine,optimizer,train_dataloader,lr_scheduler
-
-
deepspeed.add_config_arguments(parser)
parser = argparse.ArgumentParser(description='My training script.') parser.add_argument('--local_rank', type=int, default=-1, help='local rank passed from distributed launcher') # Include DeepSpeed configuration arguments parser = deepspeed.add_config_arguments(parser) cmd_args = parser.parse_args()
Training
-
deepspeed engine 초기화 후에 3가지 단계로 모델 학습이 가능
for step, batch in enumerate(data_loader): #1. forward() method loss = model_engine(batch) #2. runs backpropagation model_engine.backward(loss) #3. weight update model_engine.step()
-
모델 checkpoint 저장 및 불러오기
#load checkpoint _, client_sd = model_engine.load_checkpoint(args.load_dir, args.ckpt_id) step = client_sd['step'] #advance data loader to ckpt step dataloader_to_step(data_loader, step + 1) for step, batch in enumerate(data_loader): #forward() method loss = model_engine(batch) #runs backpropagation model_engine.backward(loss) #weight update model_engine.step() #save checkpoint if step % args.save_interval: client_sd['step'] = step ckpt_id = loss.item() model_engine.save_checkpoint(args.save_dir, ckpt_id, client_sd = client_sd)- ckpt_dir : 체크포인트를 저장할 경로
- ckpt_id : 경로 내에서 여러 체크포인트를 구분하기 위한 유니크한 식별자(optional)
DeepSpeed Configuration
- 아래의 사진과 같이 JSON 형식의 Config 파일을 통해서 설정 가능. (전체 기능은 공식 API 문서를 참고해주세요!)
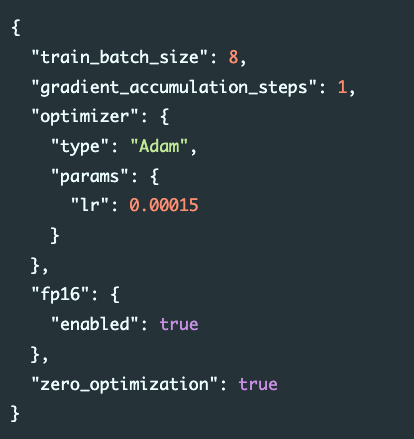
DeepSpeed로 학습 실행하기
deepspeed --num_gpus={사용할 GPU 개수} <python_file.py> <python_file args> --deepspeed_config <config_file.json>--num_gpus를 사용하지 않으면, 현재 환경의 모든 GPU를 사용한다.
주의할 점!
DeepSpeed는 CUDA_VISIBLE_DEVICES로 특정 GPU를 제어할 수 없다. 아래와 같이 --include로만 특정 GPU를 사용할 수 있다.
➡️ Single GPU를 사용할 때 활용
deepspeed —inlcude localhost:<GPU_NUM1>, <GPU_NUM2> <python_file.py> <python_file args> —deepspeed_config <config_file.json>추가적인 정보
마지막으로 DeepSpeed를 사용하면서 마주했던 이슈들을 기록해보았다.
gradient overflow with fp16 enabled
상황 및 이슈

T5 모델을 fp16 모드를 사용하여 학습할 당시에 학습 loss가 계속해서 NaN이고, loss scaling 과정에서 계속해서 OVERFLOW 발생
원인 및 해결 방법
-
bf16 모드로 사전 학습된 모델을 fp16 모드를 사용하여 학습을 하려고 할 때 발생하는 문제였다.
(TPU 환경에서 학습된 대부분의 모델과 Google에서 출시한 모델이 이런 문제가 발생한다. 예 : T5)➡️ fp32 또는 bf16을 사용하여 학습하도록 변경
(bf16은 지원되는 GPU에서만 사용이 가능하다. NVIDIA A100을 포함한 대부분의 NVIDIA 계열에선 사용이 가능)

안녕하세요. 혹시 deepspeed는 커맨드 라인에서 deepspeed + 실행문구로만 실행이 가능한가요? 아니면 코드상에서 해결이 가능한지 궁금합니다.