
프로젝트를 시작하기에 앞서서 사용할 수 있을 데이터셋과 한국어 Pre-trained Language Model에 대해 조사하고, 현재 기업에선 어떤 방식으로 악플/혐오 표현을 탐지하는지 리서치를 진행했다.
데이터셋
1. Korean hate speech dataset
Reference

✏️ 데이터셋 구성
- labeled : 9,381 문장
- train(7,896) / validation(471) / test(974)
- test 셋에 대한 성능은 kaggle에서 측정 가능
- unlabeled : 2,033,893 문장
✏️ 레이블 종류 : multi-class, multi-label 데이터
- social bias : gender, others, none
- hate speech : hate, offensive, none
✏️ kaggle
2. Korean UnSmile Dataset(Smilegate)
Reference
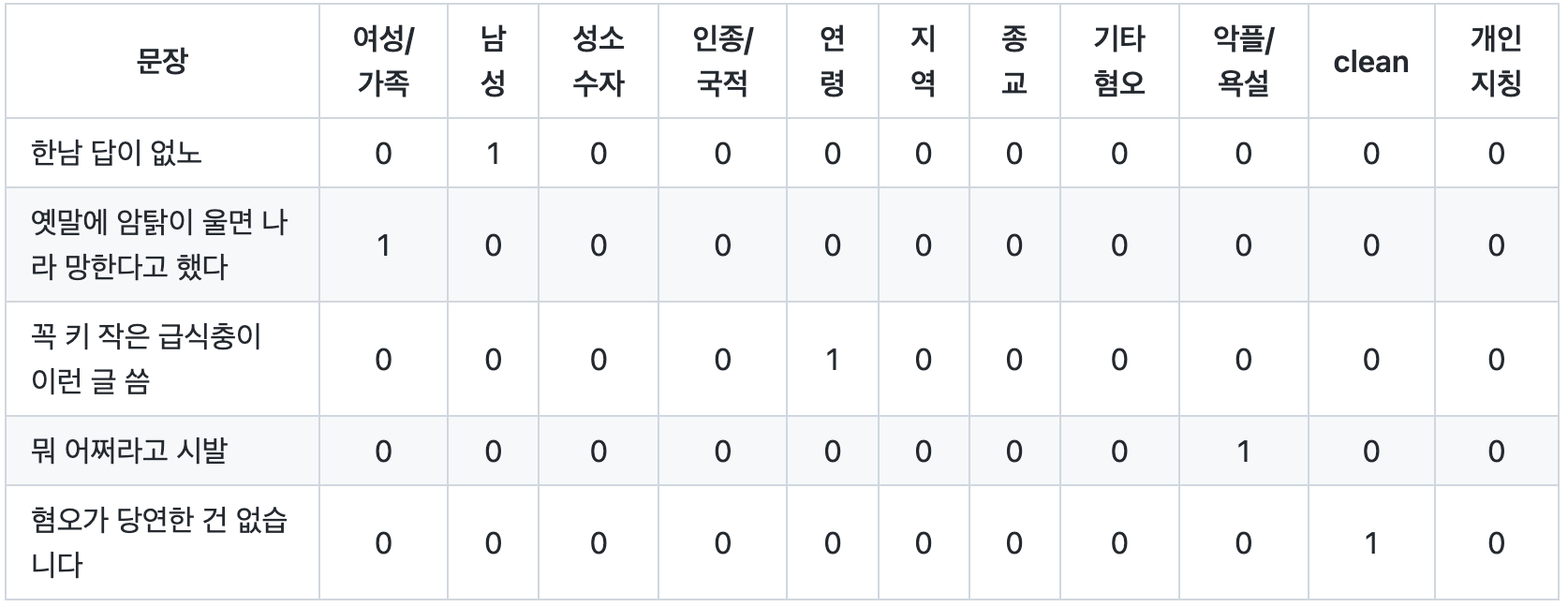
✏️ 데이터셋 구성
- labeled : 18,742 문장
- train(16,102) / validation(3,985)
✏️ 레이블 종류 : multi-label 데이터
- 혐오 표현 : 여성, 남성, 성소수자, 인종, 연령, 지역, 종교, 기타
- 악플/욕설
- clean
📃 보조 데이터셋 : HateScore
• 본 데이터셋의 크기는 약 1.1만 건으로, Korean UnSmile Dataset의 base model을 활용해 HITL(Human-in-the-Loop) 방식으로 태깅된 1.7천 건, 위키피디아에서 수집한 혐오 이슈 관련 중립 문장 2.2천 건, 규칙 기반으로 생성된 중립 문장 7.1천 건의 세 가지로 구성되며 중립 문장 오분류 방지를 주 목적으로 개발되었습니다.
https://github.com/sgunderscore/hatescore-korean-hate-speech
3. 기타 데이터
- https://github.com/ZIZUN/korean-malicious-comments-dataset
- 10,000개의 문장
- hate, none 두 가지의 레이블만을 활용
- Korean hate speech와 중복 문장 존재
- https://github.com/2runo/Curse-detection-data
- 5,825개의 문장
- 욕설의 유무만을 레이블로 활용
참고 : 비속어가 포함되어 있지만 악의가 없는 단순 강조의 의미일 경우에는 욕설로 분류하지 않음. (존맛, 개이득)
Korean PLM
1. BERT
| model | size | link |
|---|---|---|
| KoBERT(SKT) | base | https://github.com/SKTBrain/KoBERT |
| KorBERT(ETRI) | base | https://aiopen.etri.re.kr/service_dataset.php |
| HanBERT | base | https://github.com/monologg/HanBert-Transformers |
| KcBERT | base, large | https://github.com/Beomi/KcBERT |
| KR-BERT(SNU) | https://github.com/snunlp/KR-BERT | |
| Ko-Char-BERT | base | https://github.com/MrBananaHuman/KoreanCharacterBert |
| LMKor-BERT | base | https://github.com/kiyoungkim1/LMkor |
| DistilKoBERT(SKT 경량화) | https://github.com/monologg/DistilKoBERT | |
| KLUE-BERT | base | https://huggingface.co/klue/bert-base |
| KPFBERT | base | https://github.com/KPFBERT/kpfbert |
| brainsbert(kakaobrain) | base | https://huggingface.co/hyunwoongko/brainsbert-base |
| KalBert | base | https://github.com/MrBananaHuman/KalBert |
| LMKor-Albert | base | https://github.com/kiyoungkim1/LMkor |
| KLUE-RoBERTa | small, base, large | https://huggingface.co/klue |
| KoBigBird | base | https://github.com/monologg/KoBigBird |
2. ELECTRA
| model | size | link |
|---|---|---|
| TUNiB-Electra(TUNiB) | small, base | https://github.com/tunib-ai/tunib-electra |
| KoELECTRA | small++, base | https://github.com/monologg/KoELECTRA |
| KcELECTRA | small, base | https://github.com/Beomi/KcELECTRA |
| KoCharELECTRA | small, base | https://github.com/monologg/KoCharELECTRA |
| LMKor-ELECTRA | base | https://github.com/kiyoungkim1/LMkor |
3. GPT
| model | size | link |
|---|---|---|
| LMKor-KoGPT2 | base | https://github.com/kiyoungkim1/LMkor |
| KoGPT2(SKT) | base | https://github.com/SKT-AI/KoGPT2 |
| KoGPT-Trinity 1.2B(SKT) | 1.2B | https://huggingface.co/skt/ko-gpt-trinity-1.2B-v0.5 |
| KoGPT(kakaobrain) | 6B | https://github.com/kakaobrain/kogpt |
4. Encoder-Decoder(T5, BART)
T5
| model | size | link |
|---|---|---|
| KE-T5 | small, base, large | https://github.com/AIRC-KETI/ke-t5 |
| LMKor-T5 | small | https://github.com/kiyoungkim1/LMkor |
| KcT5(개발 중 추측) | base | https://huggingface.co/beomi/KcT5-dev |
| pko-t5 | base, large | https://github.com/paust-team/pko-t5 |
| KoT5(Wisenut) | base | https://github.com/wisenut-research/KoT5 |
| ET5(ETRI) | https://aiopen.etri.re.kr/service_dataset.php |
BART
| model | size | link |
|---|---|---|
| KoBART | base | https://github.com/SKT-AI/KoBART |
| Korean-BART | mini, small, base | https://cosmoquester.github.io/huggingface-bart-train/ |
혐오 표현 탐지 알고리즘
심심이
Reference
KoELECTRA를 활용한 챗봇 데이터의 혐오 표현 탐지
- Korean hate speech 데이터(9,381 문장) + 심심이 자체 데이터(351,432 문장)
- Korean hate speech 데이터의 validation set으로 모델 성능 체크
- 심심이 자체 데이터
- 크라우드소싱으로 모집한 10명의 패널이 '가르치기 데이터'를 직접 레이블링하여 구축
- 10명 중 기준(나쁜 말)에 해당한다고 평가한 패널의 비율을 '나쁜말 점수'로 사용
ex) 10명의 패널 중 4명이 나쁜 말에 해당한다고 평가 ➡️나쁜말 점수 = 0.4 - 구축한 데이터 중에서 약 5%를 랜덤으로 선택하여 활용(351,432 문장)
- classification 태스크 적용을 위해서 1/3, 2/3을 점수의 경계로 하여 각 문장에 대해 상, 중, 하 레이블링
- KoELECTRA(koelectra-base-v3-hate-speech 버전의 모델) 사용
심심이 Deep Bad Sentence Classifier
- Word가 아닌 Character 중심의 연구 진행
- 임베딩 단계에서 각각의 character를 unicode로 표현. 다시 말하면, 하나의 음절을 16개의 bit array로 표현했다는 뜻(0과 1로만 이루어짐)
- 모든 문장을 character 단위로 변환 후에
window size=20단위로 스캔
➡️ 모델의 입력은 16*20 = 320개의 0과 1로 표현됨
- 띄어쓰기에 따라서 욕설 여부가 달라질 수 있기 때문에 띄어쓰기를 포함하여 트레이닝
- 임베딩 벡터는 0과 1로만 이루어져 있기 때문에 기존과 같이 zero padding을 한다면 인풋에 0이 너무 많아서 모델 학습에 악영향을 미침 ➡️ Nine padding 적용
- 입력이 짧을 경우에는 center align 적용(가운데 정렬이 되도록 양쪽에 패딩 추가)
TUNiB
Reference
TUNiB Safety Check
-
학습 데이터 직접 구축
- Korean hate speech dataset의 unlabeled 데이터(약 16만 문장)
- 네이버 종교 뉴스(2,000 건)
- 디시인사이드 공익 갤러리(2,000 건)
- 일베사이트(2,000 건)
- 성소수자 관련 네이버 뉴스(2,000 건)
-
2명의 작업자가 개별 학습 데이터에 13가지 라벨 속성에 따라 0~4점을 부여
점수 설명 0점 특정 속성이 문장에 없음 1점 약하게 표현되어 있음 2점 보통 3점 정도가 강함 4점 정도가 매우 강함 -
비윤리적 속성을 13가지로 정의하여 데이터 라벨로 사용
- 욕설, 모욕, 폭력/위협, 외설, 범죄 조장과 혐오 8종(성별, 연령, 인종/출신지, 성적지향, 장애, 종교, 정치성향, 기타 혐오)
-
구축한 학습 데이터를 이용하여
TUNiB-Electra-ko-base튜닝- 문장이 입력되면 해당 발화 중에 가장 문제가 되는 단어/어구를 하이라이트하고, 13가지 속성에 얼만큼 해당하는지를 확률값으로 출력하도록 학습을 진행
- 13가지의 속성별 확률값에 따라서 한국어 음절 변형 방법을 다르게 적용하여 유해어/유해어구 사전 구축
- (음절 변형 방법의 예시) 바보 ➡️ ㅂ ㅏ보, ㅂr보
- 구축한 유해어 사전을 활용하여 모델을 다시 학습
넥슨 인텔리전스랩
Reference
- 딥러닝으로 욕설 탐지하기(NDC2018) [발표 자료 및 발표 영상]
- VDCNN [논문] [깃헙]
딥러닝으로 욕설 탐지하기
- 직접 크롤링한 데이터 활용
- VDCNN + Attention mechanism
- 오타에 대한 처리를 위해 자모 임베딩 사용
- Active learning 적용
- 모델을 트레이닝한 후에 새로 구축할 때, "모델이 가장 헷갈려하는 데이터"로 선택
➡️ 욕설일 확률이 50%에 가까운 데이터를 뽑자!
- 모델을 트레이닝한 후에 새로 구축할 때, "모델이 가장 헷갈려하는 데이터"로 선택
NAVER
Reference
Naver Cleanbot 2.0
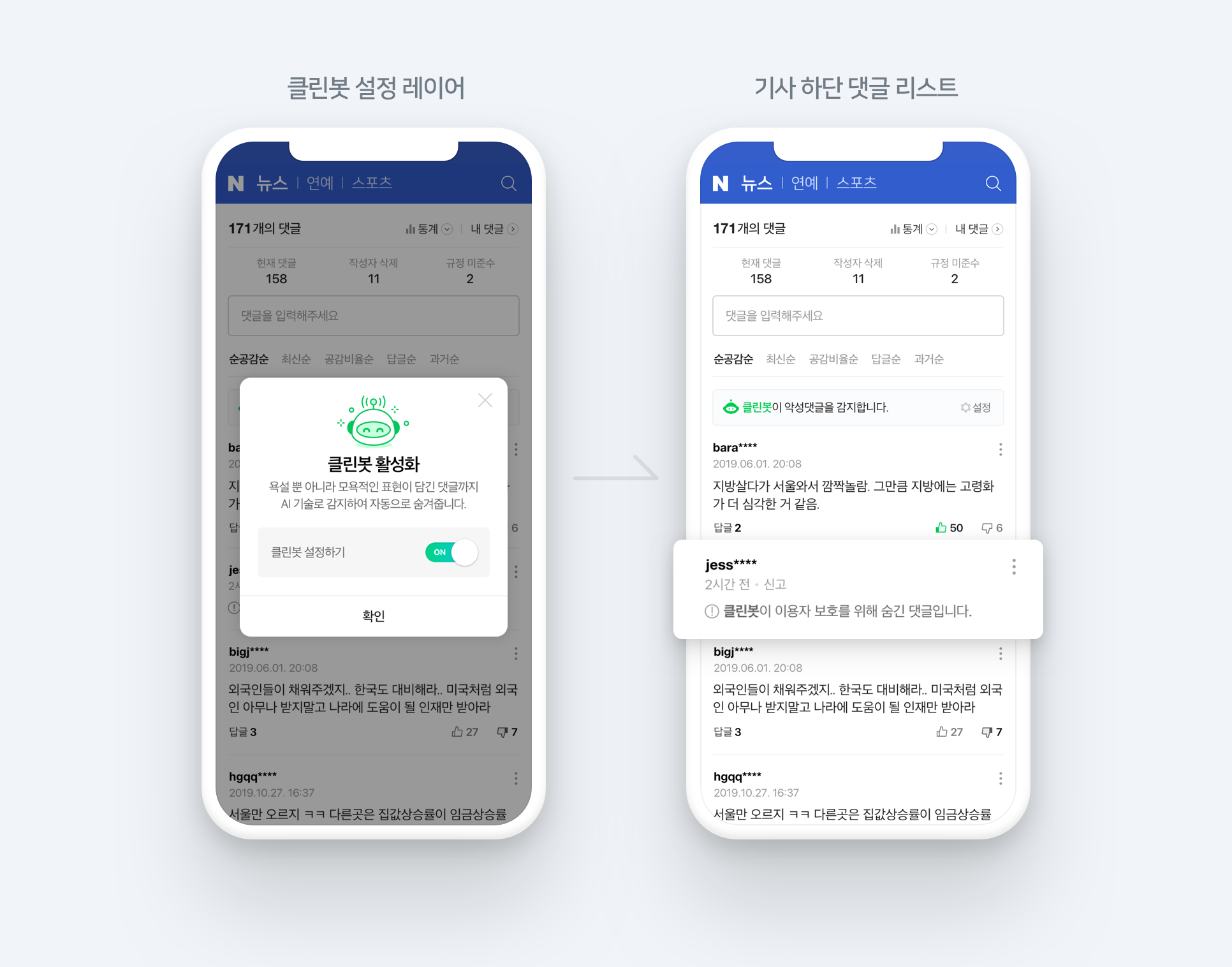
-
데이터 직접 구축
- 뉴스, 연예, 스포츠 섹션의 댓글 데이터를 익명화 샘플링(약 35만여 문장)
- 레이블
- 2 : 악플
- 1 : 애매함
- 0 : 악플이 아님
-
실제 서비스에 활용하기 위해서 가벼운 모델을 사용하는 것을 목표로 함
- 성능 측정 결과에서 RoBERTa의 정확률이 가장 높았지만, BERT보다도 정확률이 약간 낮아도 비교적 가벼운 CNN_LSTM(x2) 기반 모델을 선택. (성능 측정 결과는 발표 영상을 참고해주세요)
-
추가적인 성능 개선을 위해서 Persona Embedding(댓글 유사도 학습)을 적용 - 네이버 내부의 중복 댓글 탐지 모델의 학습 방식
- 작성자 동일성 여부에 따른 비선형 변환을 수행하여 새로운 유사도를 얻어내어 이를 정답 스코어로 간주하는 방식
- "동일한 사용자가 작성한 두개의 댓글은 다른 사용자가 작성한 댓글보다 의미적으로 유사할 것이다"라는 가설을 바탕으로 구현된 알고리즘
➡️ 두 댓글 사이의 코사인 유사도를 산출하고 두 개의 댓글의 작성자가 같다면 유사도 상향 조정, 다르다면 유사도 하향 조정
-
표현의 자유를 최대한 보장하기 위해서 의도적으로 악플의 기준을 조금 더 상향하여 서비스 진행 중

뤼튼 욕설 필터링 개발하신 분이신가보군요.