Korean Hate Speech Detection
1.[PLM을 이용한 한국어 혐오 표현 탐지] 1. 현황 파악

프로젝트를 시작하기에 앞서서 사용할 수 있을 데이터셋과 한국어 Pre-trained Language Model에 대해 조사하고, 현재 기업에선 어떤 방식으로 악플/혐오 표현을 탐지하는지 리서치를 진행했다.
2.[PLM을 이용한 한국어 혐오 표현 탐지] 2. 베이스라인 모델 선택하기

지난 시간에 리서치한 것을 바탕으로 혐오 표현 탐지에 사용할 수 있을만한 PLM을 몇 가지 뽑아서 각 모델 별 특징을 정리해보았다. 이후, 간단하게 각 모델 별 성능을 측정하여 베이스라인 모델을 선택해봤다.
3.[PLM을 이용한 한국어 혐오 표현 탐지] 3. 모델 구조 바꿔보기

지난 시간에 성능 향상을 위한 실험 방법 중 하나로 모델의 구조 변경을 선택했었다. 오늘은 classification head에 따른 성능 변화를 비교하여 새로운 모델을 선택해보았다. 실험에 사용한 코드는 추후에 깃헙에 추가할 예정이다.
4.[PLM을 이용한 한국어 혐오 표현 탐지] 4. 데이터 바꿔보기

지난 시간에 "해당 발언이 어떤 유형인가"보다는 "해당 발언이 혐오 표현인가 아닌가"를 판단하는 것이 더 중요한 문제이기 때문에 방향성을 바꾸기로 했다.
5.[PLM을 이용한 한국어 혐오 표현 탐지] 5. 레이블 불균형 해소

1. 이전 모델 평가 현재 모델 학습에 사용한 데이터는 레이블 불균형 문제가 존재한다(bad:clean = 7:3 정도의 비율). 이 경우에 현재 테스트 셋에 대한 성능은 높을지라도, 실제 환경에서 모델이 과도하게 bad로만 분류할 확률이 높기 때문에 추가적인 평가가
6.[PLM을 이용한 한국어 혐오 표현 탐지] 6. 데이터 증강

모델 성능 개선을 위한 다음 단계로는 이전에 2. 베이스라인 모델 선택하기에서 생각했었던 unlabeled data를 활용하는 방법을 선택하여 실험하기로 결정했다.
7.[PLM을 이용한 한국어 혐오 표현 탐지] 7. 증강 데이터 활용하기

Reference 한국어 상호참조해결을 위한 BERT 기반 데이터 증강 기법 [paper] MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification [paper] [github] 1. 서론 이전 시간에 max_epoch로 설정했...
8.[PLM을 이용한 한국어 혐오 표현 탐지] 8. 증강 데이터 활용하기2
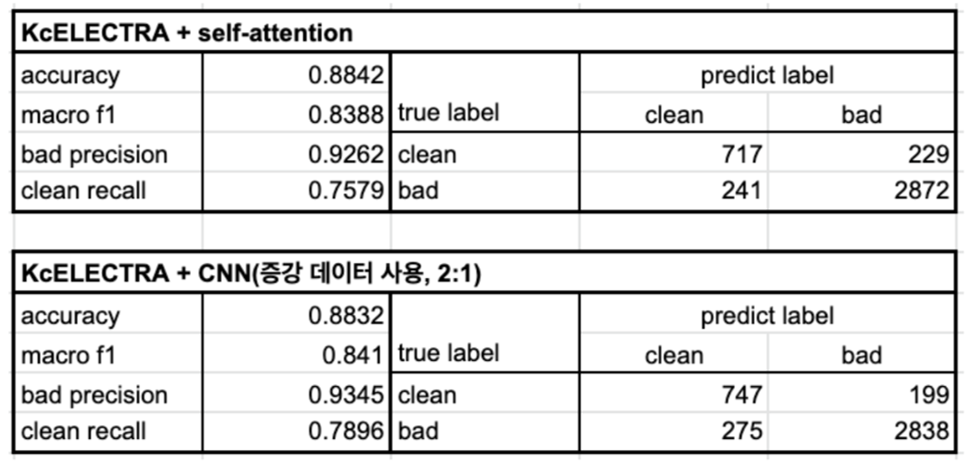
1. 서론 지난 포스팅 이후로 실험은 모두 끝내놨지만 조금의 휴식 기간을 보낸다고 늦어진 기록 혐오 표현 탐지 프로젝트에서 해보고자 했던 실험은 모두 끝내놔서 이번 포스팅 이후로 새로운 아이디어가 떠오를 때까지는 잠깐 홀드할 것 같다. 이번 시간에는 기존의 데이터 증강 방식을 통해서 오버 샘플링을 적용해보는 실험과 Unlabeled 데이터를 활용한 모...