
Reference
1. 서론
이전 시간에 max_epoch로 설정했던 30까지 모두 마쳤지만, 아직 수렴을 다 마치지 못 하고 계속해서 loss가 줄고 있는 모습을 보여서 추가적인 학습을 진행했다. 그 결과, 에포크 49에서 수렴을 했고 데이터 증강을 위한 모델 튜닝을 완료했다. 최종적으로 튜닝한 모델은 쉽게 다운로드하고 사용하기 위해서 Huggingface hub에 공유하고, 모델 학습 및 증강을 위한 코드는 깃헙에 올렸다🎉
이번 시간에는 튜닝을 완료한 모델을 이용하여 데이터 증강을 적용하고, 증강 데이터를 활용하여 학습한 모델의 성능을 비교해보았다.
2. 증강 데이터 추가(KcELECTRA)
후보 필터링 조건
- [MASK]에 대해서 모델이 생성한 top0 후보의 점수(softmax 기준)이 0.9 미만일 경우는 그대로 사용
- 점수가 0.9 미만일 때,
- 기호는 기호만 치환, 기호가 아닌 토큰은 기호가 아닌 토큰으로 치환
- 앞 혹은 뒤에 동일한 토큰이 있다면 선택하지 않음
이전 시간에 정의했던 후보 필터링 조건에서 softmax 점수를 이용한 조건을 추가했다. softmax 기준의 점수가 매우 높을 경우에는 원토큰과 같더라도 그대로 사용을 하게 되는데, 이는 확률이 너무 낮은 후보로 치환을 한다면 원문장과 의미적으로 많이 멀어질 수 있다고 생각해서 해당 기준을 추가했다.
✔️ 증강 데이터 비율에 따른 모델의 성능 비교
참고했었던 논문에 따르면 원 데이터에 대한 증강 데이터의 비율에 따라서 모델의 성능이 달라졌다고 한다. 이를 바탕으로 현재 설정한 베이스라인 모델(KcELECTRA-CNN)에 가장 적합한 증강 데이터의 비율을 정하기 위해 성능 비교를 진행했다.
참고 논문에서의 결과
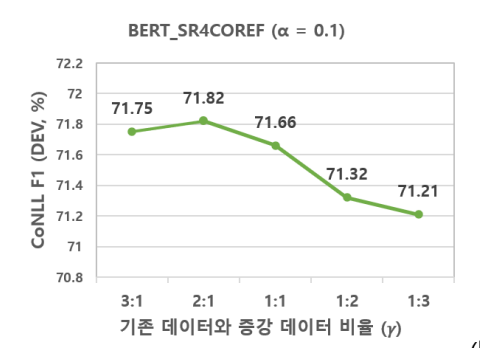
- 증강 데이터를 사용하지 않은 모델은 F1 score 기준 70.78이었고, 2:1 비율로 사용했을 때의 성능이 가장 높았다고 한다.
KcELECTRA + CNN
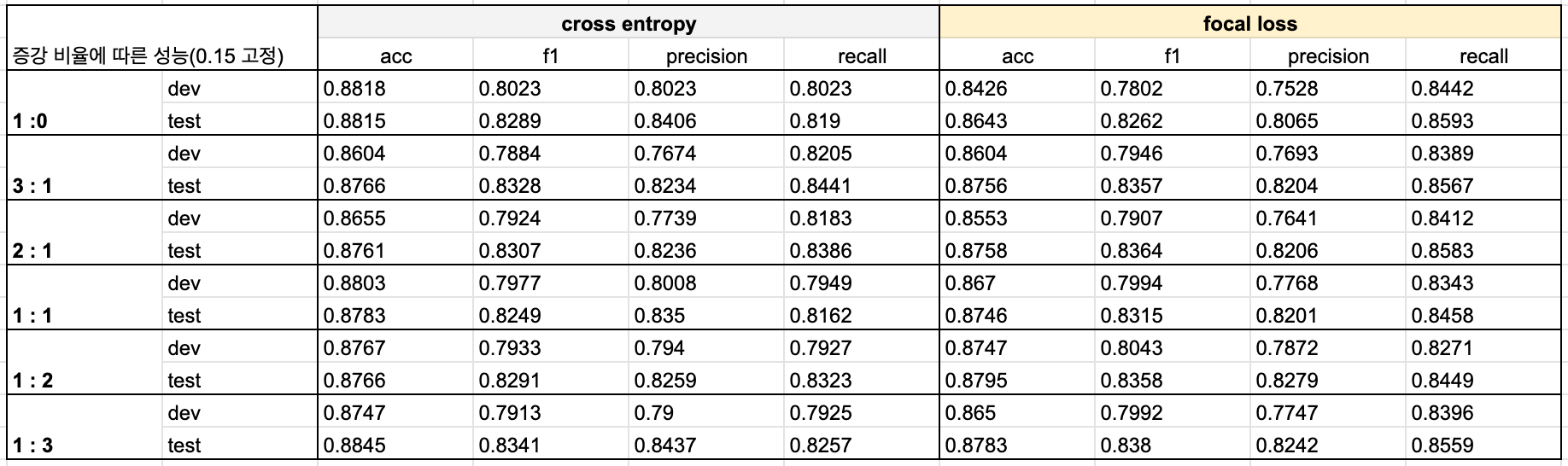
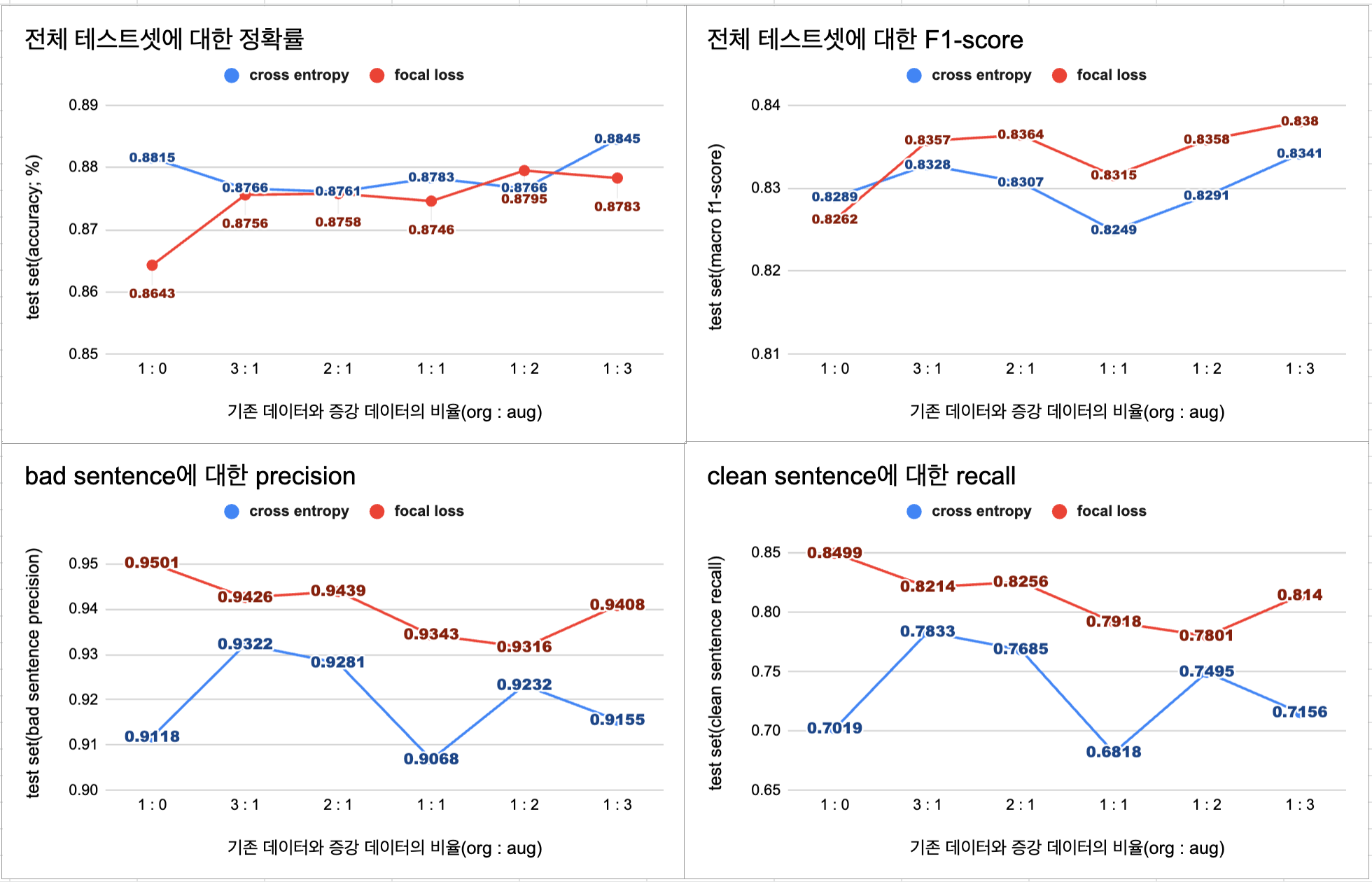
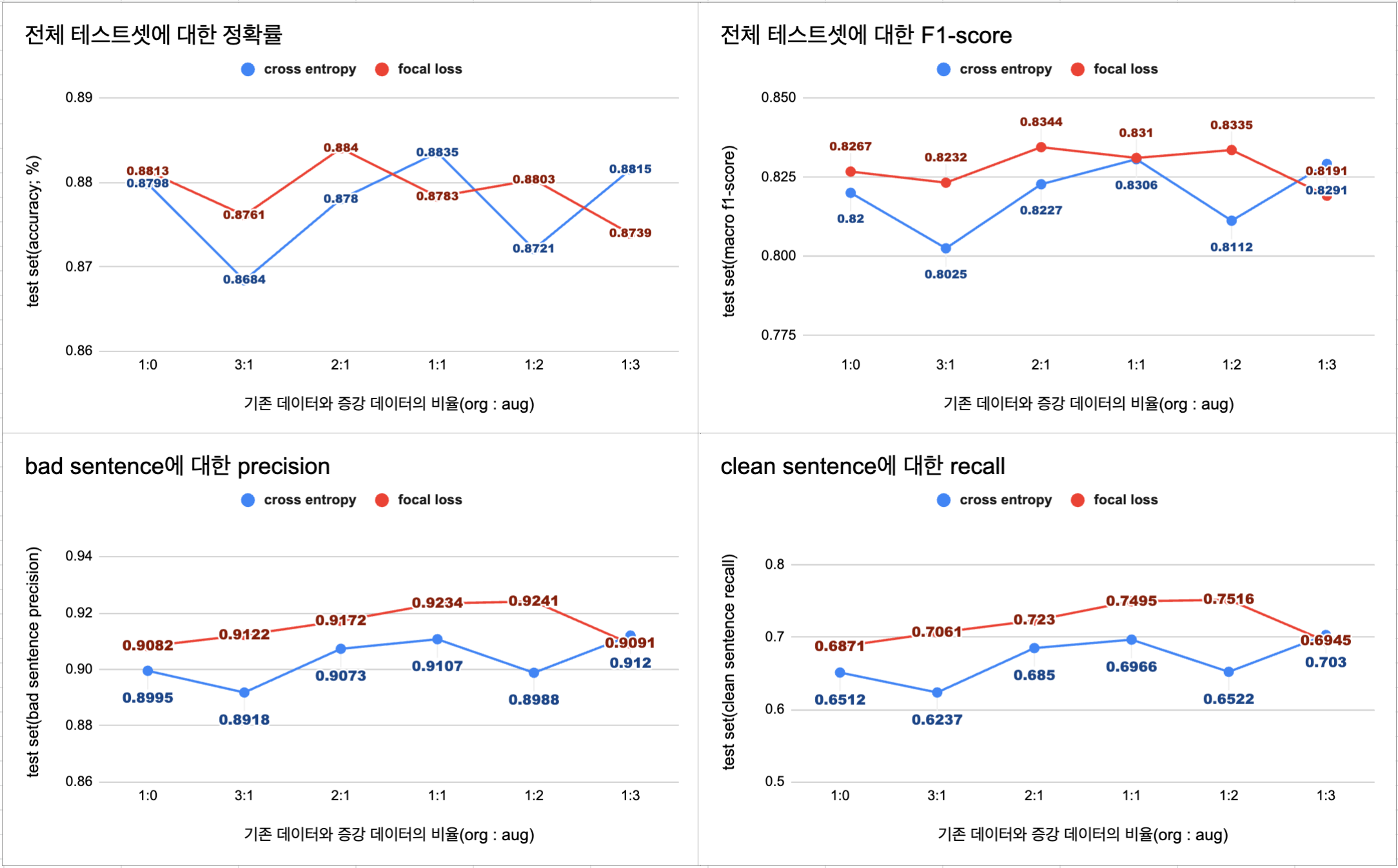
- 단순히 정확률과 F1-score를 기준으로 봤을 때는 원본 데이터 양의 3배의 증강 데이터를 추가한 1:3 모델이 가장 높은 성능을 보였다.
- 하지만 현재의 가정(bad 문장의 precision이 중요하다)에 따르면 원본 데이터셋의 1/2의 증강 데이터를 추가한 2:1 모델이 가장 적합하다고 판단된다.
✔️ 마스킹 비율에 따른 모델의 성능 비교
증강 데이터의 비율뿐만 아니라 데이터 증강을 할 때 마스킹 비율에 따라 생성되는 문장도 달라져서 모델의 성능에 영향을 준다. 마스킹 비율이 클수록 원 문장에서 달라지는 토큰의 개수가 많아지기 때문에 더 많은 패턴을 학습할 수 있는 장점도 있지만, 원문장과의 유사도가 떨어질 수도 있기 때문에 데이터의 퀄리티에 중요한 요소 중 하나이다. 이에 따라서 마스킹 비율에 따라 증강 데이터를 생성하고, 각 모델의 성능 비교를 진행했다.
참고 논문에서의 결과
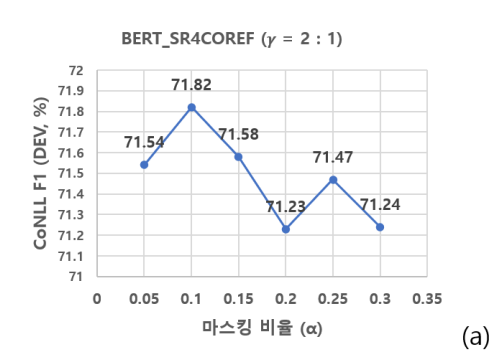
- 논문에서는 같은 양의 증강 데이터를 추가할 때, 마스킹 비율으로 설정했을 때의 모델 성능이 가장 높았다고 한다.
KcELECTRA + CNN
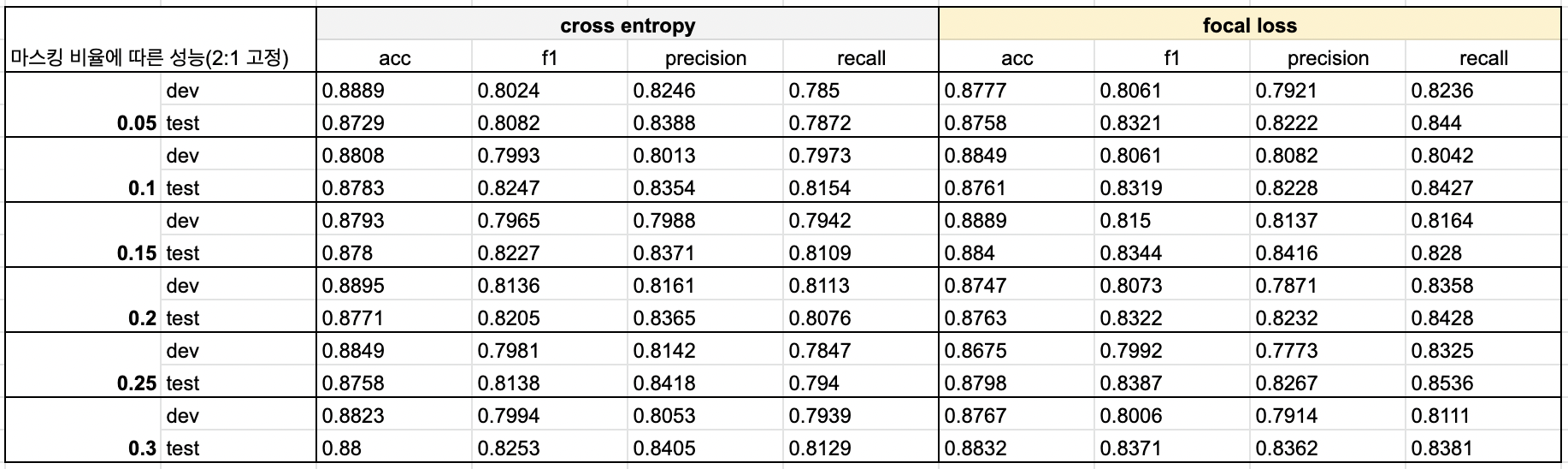
위 실험의 결과로 증강 데이터의 비율은 원본 데이터의 1/2으로 고정하여 실험을 진행했다.
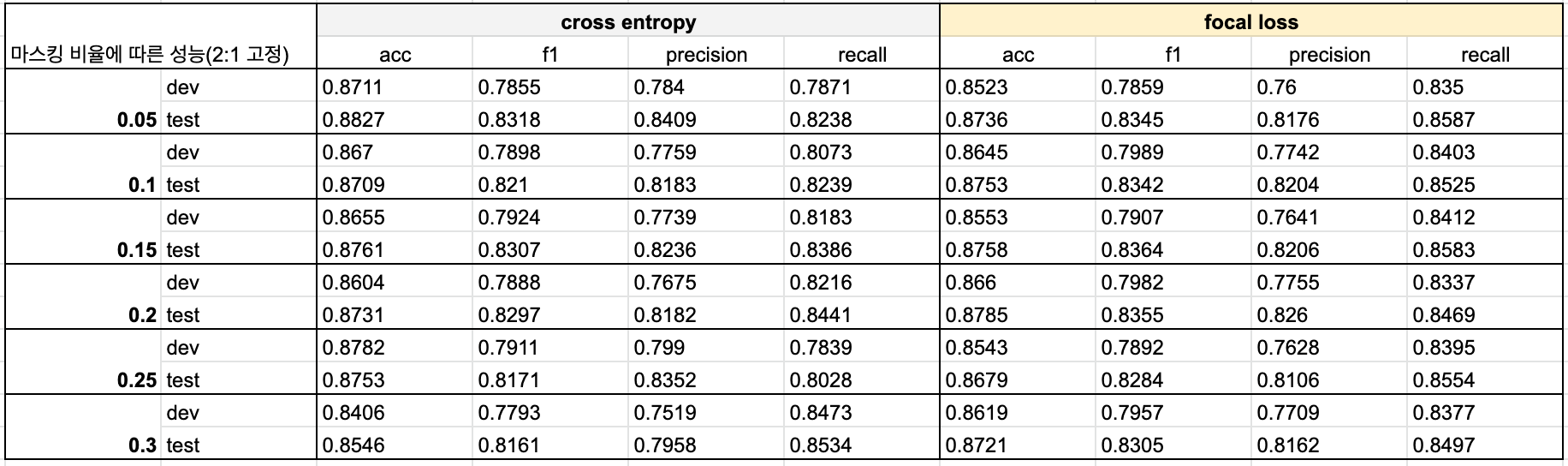
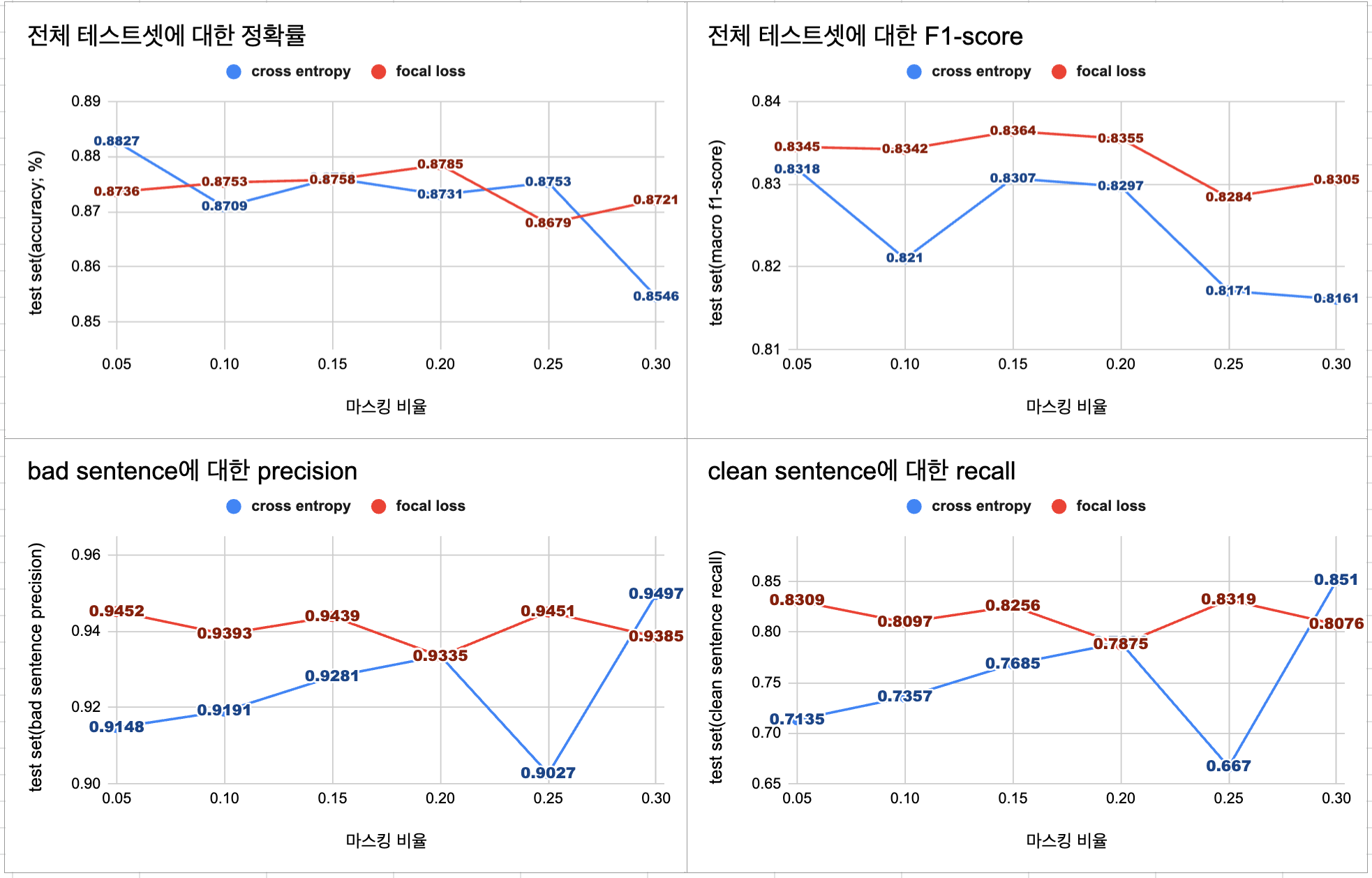
- 전체적인 성능을 모두 고려했을 때, 0.15의 마스킹 비율을 적용했을 때의 모델이 가장 적합하다고 판단된다.
- 기존에 세운 가설에 따르면 0.30의 마스킹 비율과 cross entropy를 적용한 모델이 가장 적절하긴 하지만, 이 모델의 경우에는 다른 케이스에 비해서 정확률, f1-score가 떨어져서 선택하지 않았다.
3. 증강 데이터 추가(MixText)
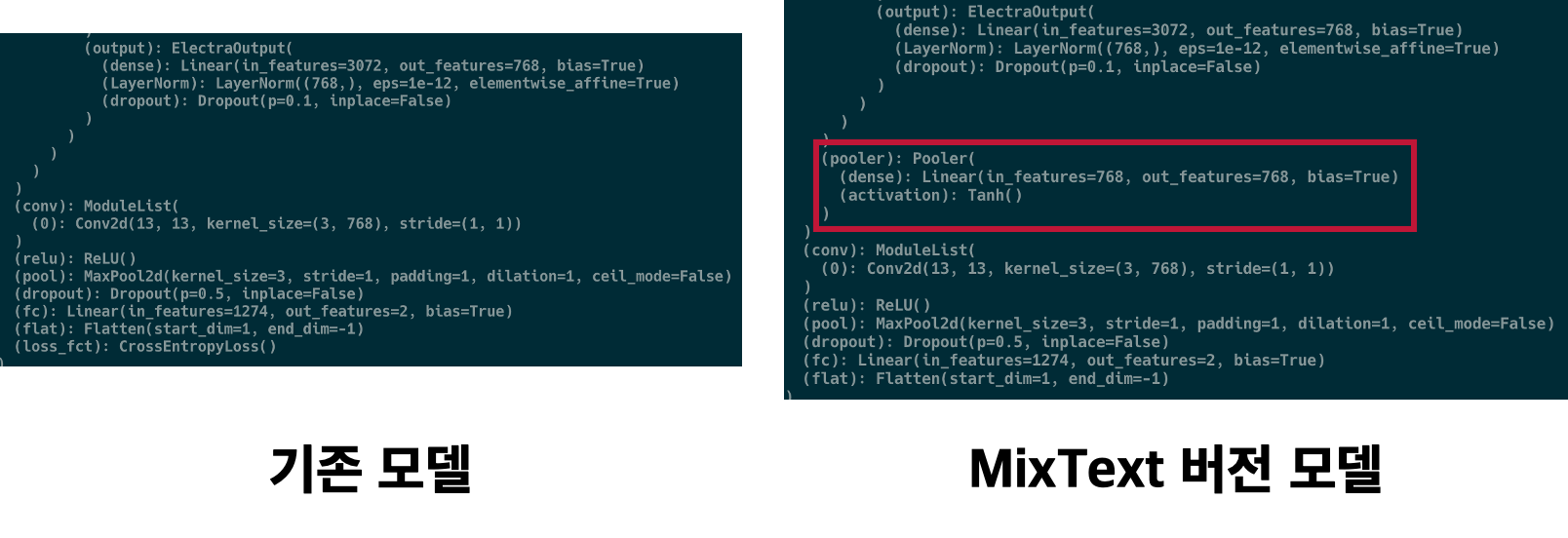
위 실험에서는 기존의 베이스라인 모델인 KcELECTRA-CNN 모델을 사용했지만, 기존 계획대로 동일한 환경에서 MixText로 모델을 변경하여 실험을 진행했다. MixText는 NLP에서의 semi-supervised 방법론이고, unlabeled 데이터를 활용하기 위해서는 labeled 데이터로 학습을 완료한 모델이 필요하다. 이번 실험에서는 실질적인 MixText를 적용하기 전에 labeled 데이터만을 사용한 모델을 이용한 성능 비교를 진행했다.
- MixText는 논문과 공식 코드를 참고하여 구현했으며, 기존 베이스라인 모델의 구조를 활용하기 위해서 KcELECTRA와 CNN으로 변경하였다. 결론적으로 labeled data만 사용할 때는 Electra 모델 다음에 pooling layer가 하나 추가됐다는 점만 다른 것이다.
✔️ 증강 데이터 비율에 따른 모델의 성능 비교
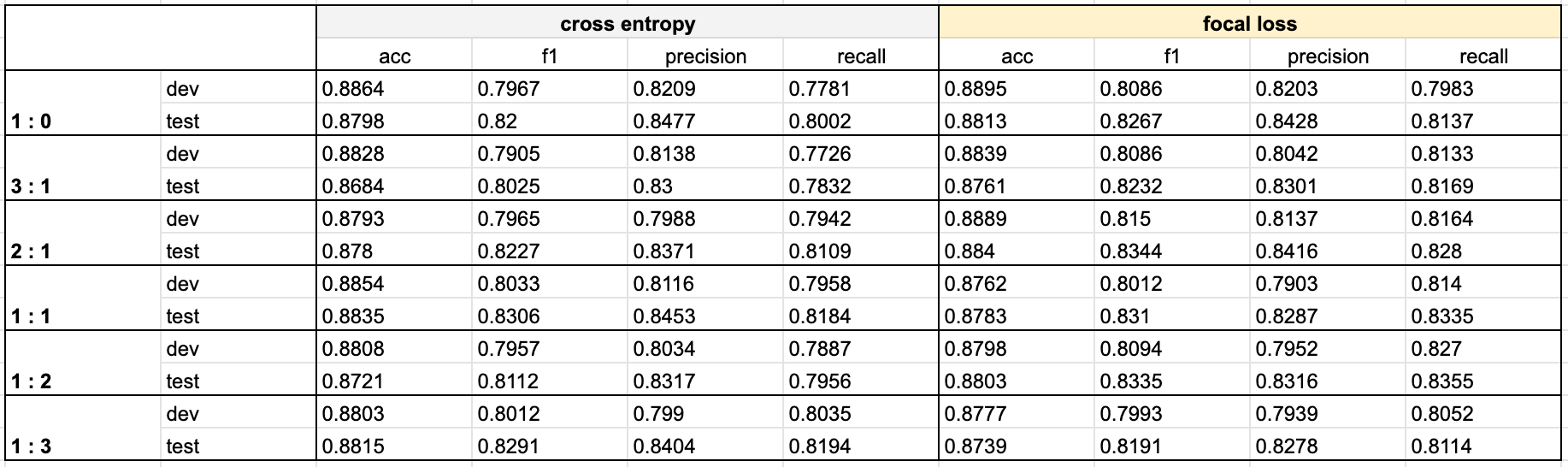
- 현 실험에서는 베이스라인을 이용한 실험에 따라서 마스킹 비율은 0.15로 고정하고 실험을 진행했다.
- 성능 측정 결과, 원본 데이터의 2배의 데이터를 추가한 1:2 모델이 가장 적합하다고 판단된다.
✔️ 마스킹 비율에 따른 모델의 성능 비교
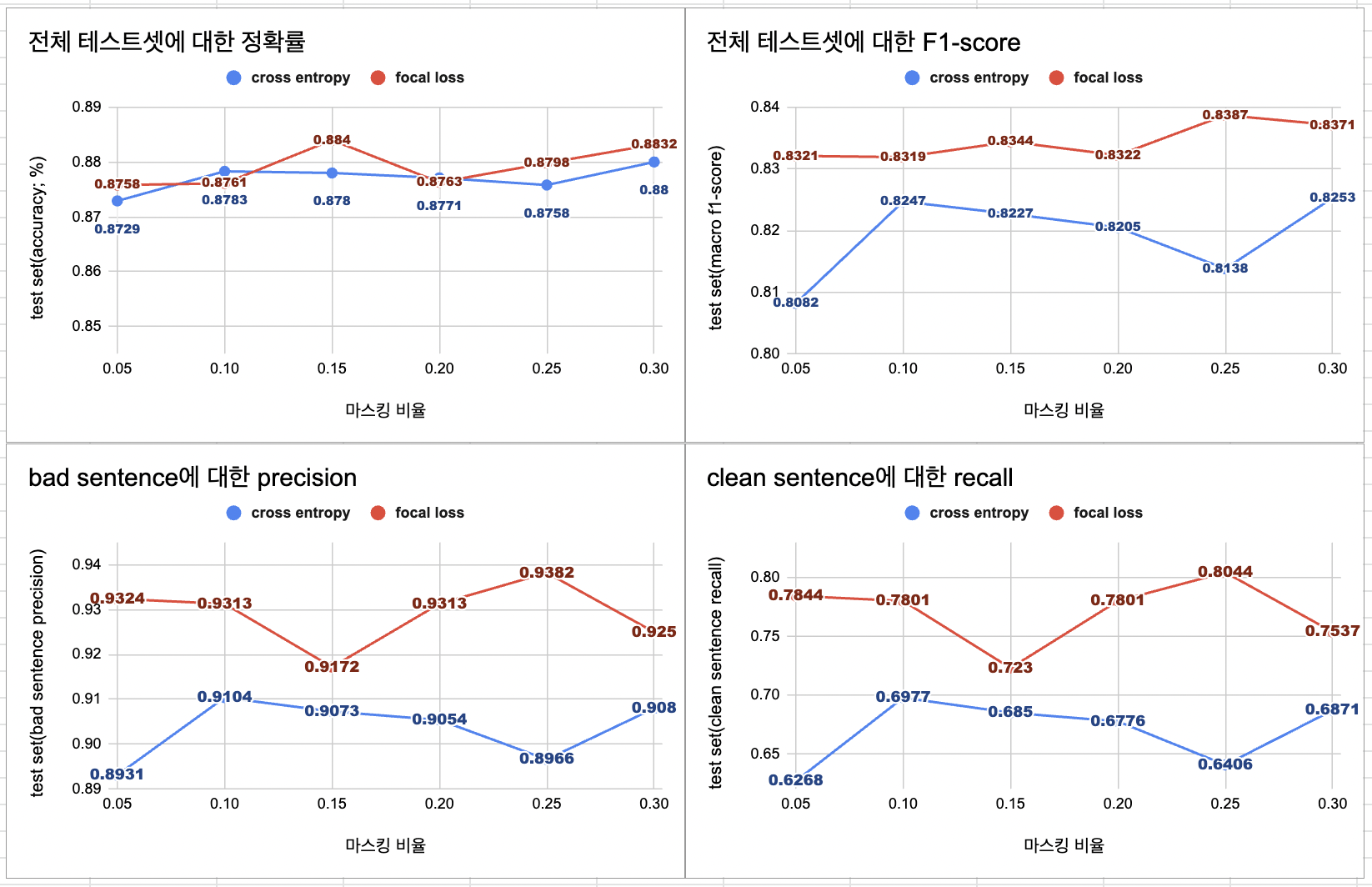
- 베이스라인을 이용한 실험에 따라서 증강 데이터의 비율은 원본 데이터의 1/2로 고정하여 실험을 진행했고, 마스킹 비율을 0.25로 했을 때의 모델이 가장 적합하다고 생각한다.
4. 마무리
- Masked Language Model을 이용하여 데이터 증강을 적용하고, 증강 데이터를 활용한 모델 성능 평가를 진행했다. 증강 데이터를 추가했을 때, 약간의 성능 향상이 있긴 했지만 전체적으로 오차 범위 내의 성능 차라서 크게 효과적이진 않았다고 생각한다.
- 효과가 크지 않았던 원인에 대해서 생각해봤을 때, 모델의 성능이 이미 높았던 상황이기에 증강 데이터 없이도 충분히 패턴을 학습할 수 있었던 것은 아닌가? 라는 생각을 했다.
- 이번 시간에는 labeled data에만 데이터 증강을 적용했던 것에서 더 나아가서 다음 시간에는 unlabeled data에도 데이터 증강을 적용하여 semi-supervised learning 방법론을 적용해보도록 한다.

넘 잘 공부하고 갑니다!