

지난 시간에 성능 향상을 위한 실험 방법 중 하나로 모델의 구조 변경을 선택했었다. 오늘은 classification head에 따른 성능 변화를 비교하여 새로운 모델을 선택해보았다. 실험에 사용한 코드는 추후에 깃헙에 추가할 예정이다.
Reference
https://velog.io/@howay96/Korean-Hate-Speech-Detection
https://aclanthology.org/2020.semeval-1.271.pdf
https://arxiv.org/pdf/1910.12574.pdf
후보 모델
- baseline (
dropout + linear layer) - reference (https://velog.io/@howay96/Korean-Hate-Speech-Detection)
- LSTM (
2 stack BiLSTM + dropout + linear layer) - CNN ver1(https://aclanthology.org/2020.semeval-1.271.pdf)
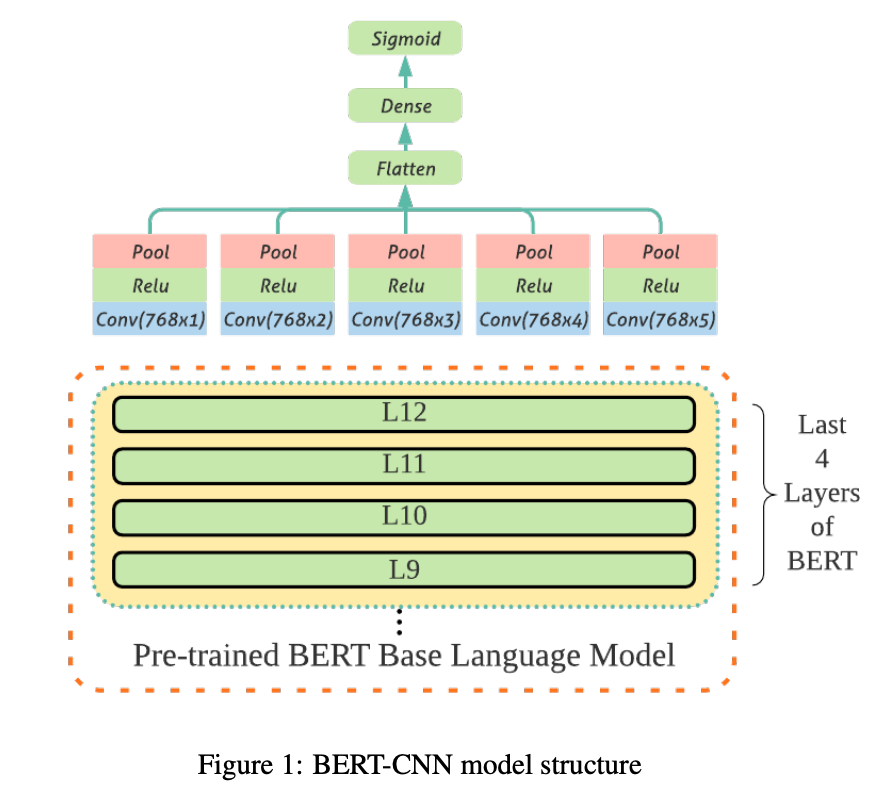
- CNN ver2(https://arxiv.org/pdf/1910.12574.pdf)
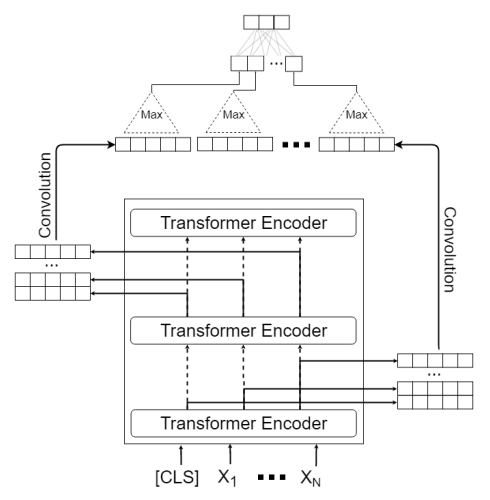
모델 별 하이퍼파라미터
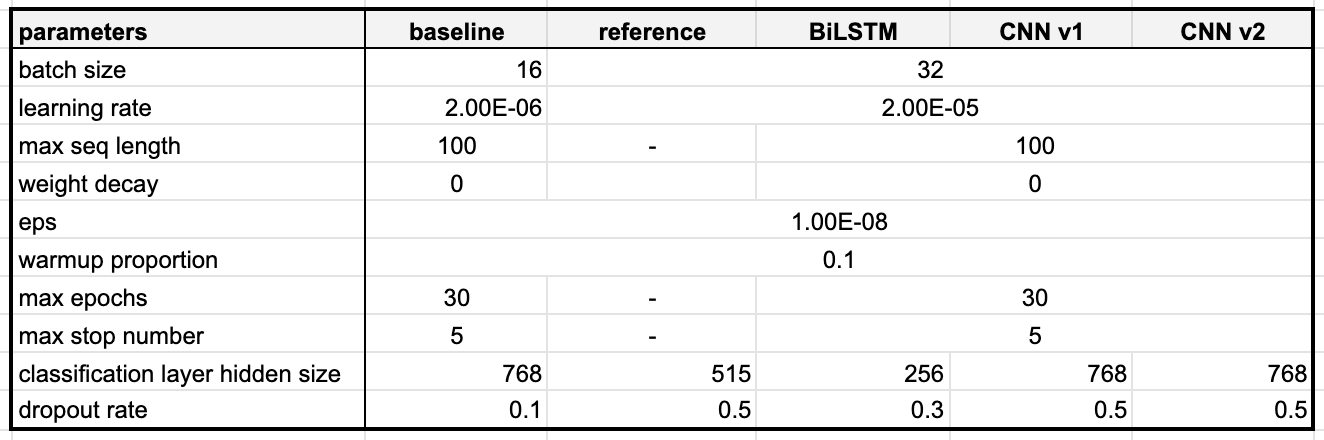
모델 별 성능
- reference를 제외한 모델 후보들은 직접 구현을 하여 모델 성능을 측정했으며, reference 모델의 성능은 해당 글 작성자분의 포스팅을 참고하였다.
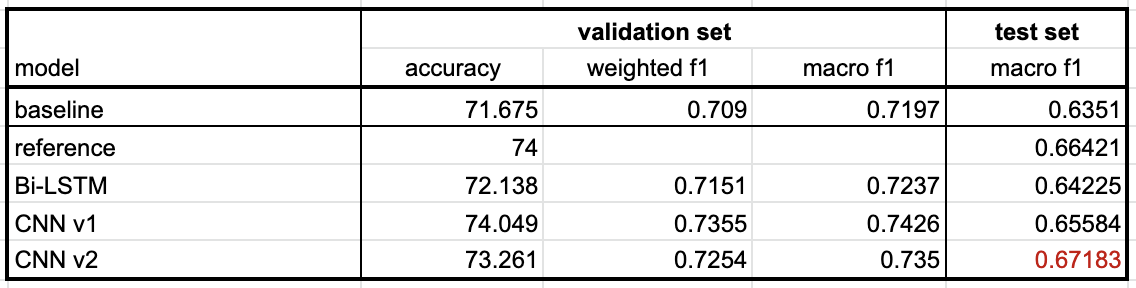
- 모델 성능 측정 결과, CNN ver2의 성능이 가장 높았고, kaggle competition 2위를 달성했다!🥳
결론
지난 시간에 성능 향상을 위한 방법으로 아래와 같은 3가지를 생각했었다.
1) 모델 구조 변경하기
2) 뉴스 기사 제목 활용하기
3) unlabeled data 활용하기그 중, 오늘은 첫 번째 아이디어를 실험하여 기존 0.6351이었던 f1 score를 0.67183까지 향상시킬 수 있었다! 모델의 성능 향상은 의미 있는 결과였지만, 혐오 표현 탐지 모델의 사용성을 생각했을 때, "해당 발언이 어떤 유형인가"보다는 "해당 발언이 혐오 표현인가 아닌가"를 판단하는 것이 더 중요한 문제이기 때문에 방향성을 조금 바꾸기로 했다.
기존에 사용했던 hate, offensive, none 레이블 대신에 binary classification 문제로 변경하여 bad, clean 레이블로 데이터셋을 재구성하여 학습하기로 결정했다. 여기서는 혐오 표현의 기준에 따라서 데이터셋 레이블링 기준이 달라지는데 이 부분에 대해서는 다음 시간에 자세히 결정하기로 한다😁

ML Engineer @Wrtn Technologies Inc.