
1. 이전 모델 평가
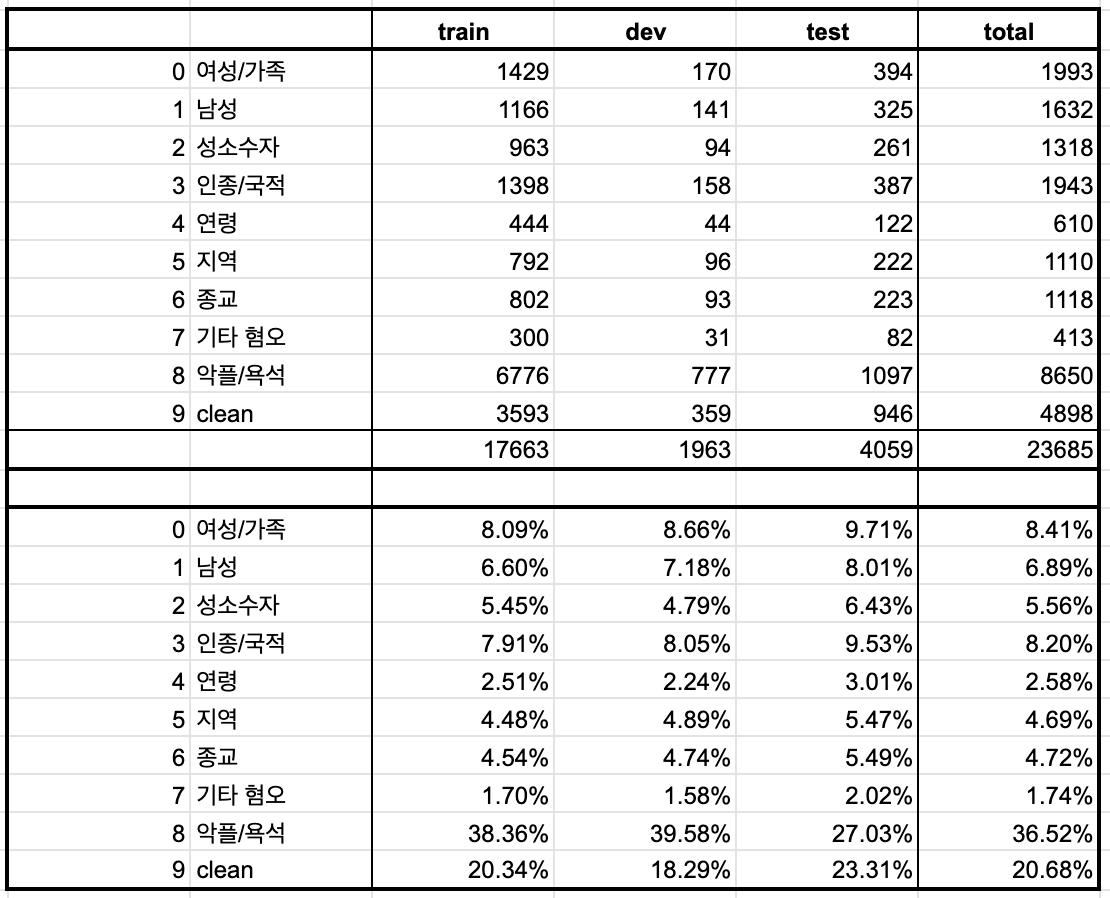
현재 모델 학습에 사용한 데이터는 레이블 불균형 문제가 존재한다(bad:clean = 7:3 정도의 비율). 이 경우에 현재 테스트 셋에 대한 성능은 높을지라도, 실제 환경에서 모델이 과도하게 bad로만 분류할 확률이 높기 때문에 추가적인 평가가 필요하다.
Naver Sentiment Movie Corpus
일반적인 문장(clean)에 대한 성능 평가를 위해서 Korean hate speech dataset과 가장 비슷한 유형이라고 생각되는 영화 감성 분석 데이터를 활용하였다. 이 때, clean을 잘 분류하는가에 대한 평가가 필요하기 때문에 긍정 평가 문장만으로 한정하여 사용했다.
- Naver Sentiment Movie Corpus(NSMC)의 테스트 데이터 중에서 긍정 평가 문장을 랜덤하게 1,000 문장 추출하여 성능 측정을 진행한 결과, 예상보다 높은 정확률을 보였다(약 95%).
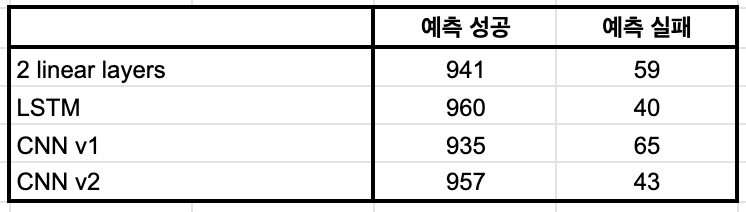
- 모델이 예측을 실패한 문장을 봤을 때, 영화에 대해서는 긍정적인 평가를 내린 게 맞지만 또 다른 대상에 대한 혐오 표현이 포함되어서 bad 문장으로 분류된 케이스가 많았다. 이는 목적에 따르면 정확하게 분류한 결과라고 볼 수 있다.
➡️ 긍정 평가라고 모두 clean 문장은 아니다!

Korean hate speech unlabed data
추가적인 평가를 위하여 Korean Hate Speech Dataset의 unlabeled data 일부를 랜덤으로 샘플링하여 직접 태깅한 후, 모델 성능 측정을 진행하였다.(직접 태깅을 했기 때문에 많은 양을 사용하지 못 하고 100개만 사용)
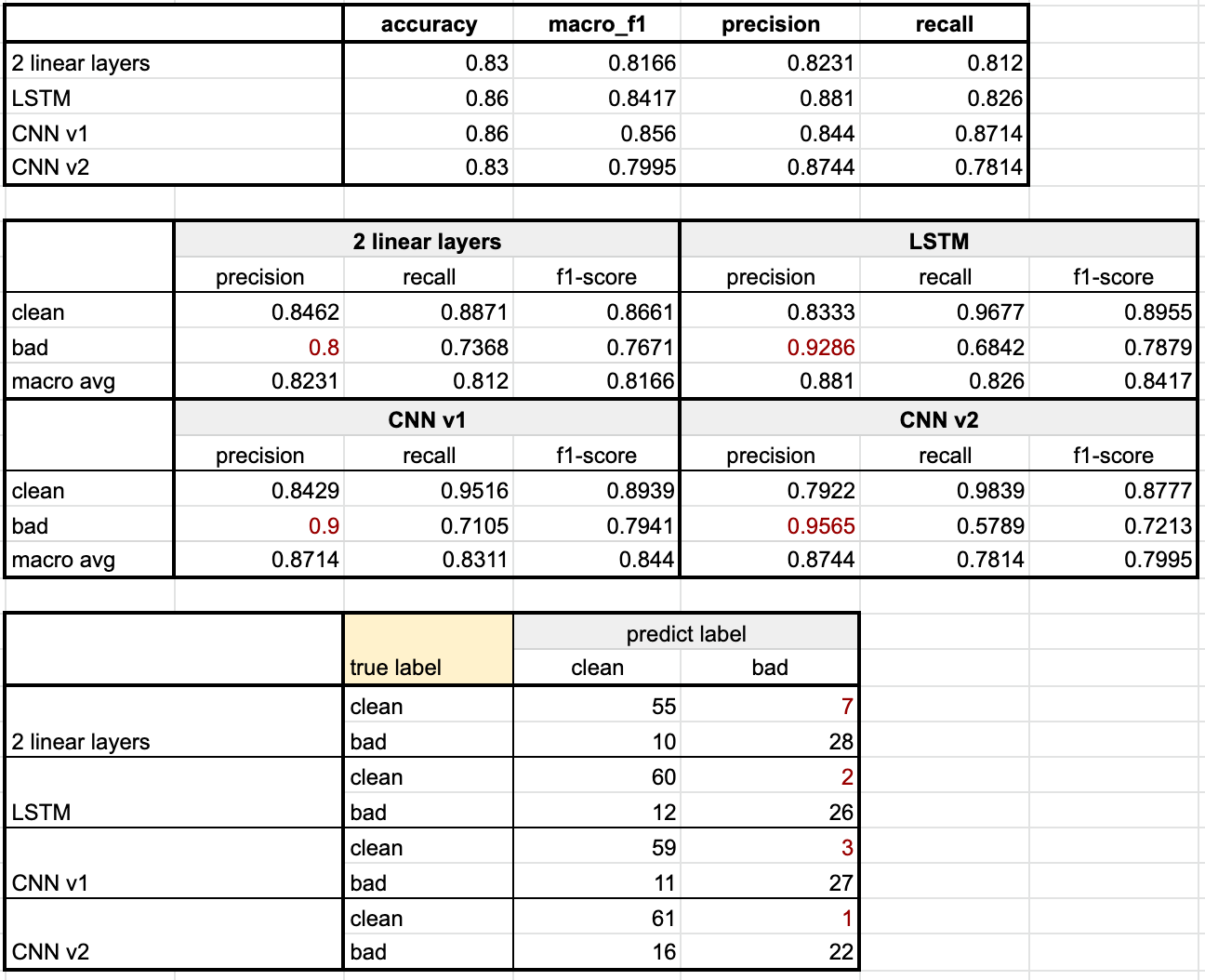
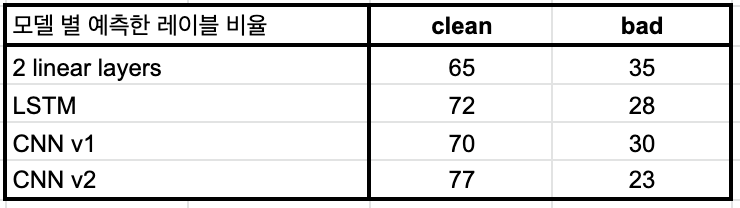
- 너무 적은 양의 데이터를 사용했기 떄문에 이 지표를 가지고 모델을 선택하는 것은 무리가 있지만, 불균형 데이터로 학습했음에도 예상보다 bad로 분류하는 비율(
Input = clean or bad/Output = bad) 자체가 높지 않았다. - 또한, 정상적인 문장이 입력으로 들어왔을 때 bad로 분류해서 틀리는 비율(
Input = clean/Output = bad)이 높지 않기 때문에 목적에 부합하는 방향으로 트레이닝 되었다고 볼 수 있다.
2. 레이블 불균형 해소
1의 결과로 현재의 모델이 레이블 불균형이 존재하는 데이터로 학습을 진행했음에도 inference 단계에서는 해당 문제가 두드러지지 않는다는 것을 파악하게 되었다. 그렇다면 레이블 불균형이 해소된 데이터를 사용하여 트레이닝을 진행한다면 모델의 전체적인 성능이 향상되는지를 확인하기위해 몇 가지 실험을 진행하였다. 실험은 4. 데이터 바꿔보기의 마지막에 레이블 불균형 문제를 보완하기 위한 아이디어 3가지를 순서대로 진행했다.
데이터셋 구성
현재의 데이터는 혐오 표현 여부에 따라서 binary classification을 적용하여 아래와 같이 레이블 불균형 문제가 존재한다.(4. 데이터 바꿔보기 이후로 아래와 같은 필터링을 진행하여 이전과 약간 다른 분포가 되었음)
- Unsmile dataset의 레이블이 아예 없는 케이스 제거
- Korean hate speech dataset 중에서 hate class가 none이지만 bias class가 none이 아닌 케이스 제거

✔️ clean 문장 추가를 통한 보완
현재 데이터는 clean 레이블의 비율이 hate 레이블에 비해 매우 낮은 것을 위 표에서 확인할 수 있었다. 이를 해소하기 위해서는 hate 레이블 문장을 제거하거나, clean 레이블 문장을 추가해야 한다. 충분한 양의 데이터가 있을 때는 더 많은 레이블의 샘플을 제외해도 모델 학습에 문제가 없지만, 현재와 같이 데이터의 양이 많지 않을 때는 해당 방법을 적용하기엔 무리가 있다. ➡️ clean 문장 추가
- 추가하는 문장은 기존 데이터와 비슷하게 비정제 데이터로 구성되는 것이 통일성 면에서 더 좋을 것이라고 판단했기 때문에 1번 실험에서 사용했던 Naver Sentiment Movie Corpus의 긍정 평가 문장을 사용하였다.
- 실험 1에서 영화 평가가 긍정적이라고 항상 clean 문장은 아니라는 것을 알아냈지만, 그 비율이 크지 않기 때문에 감안하고 그대로 사용했다.
- labeled data를 사용할 때, 각각의 레이블에 해당하는 샘플이 1:1일 때 가장 이상적이긴 하지만 원본 데이터의 clean 문장 수보다 많은 임의의 데이터(NSMC 문장)을 추가하면 원래 task의 목적성이 훼손될 위험이 있다고 생각해서 임의로 각각 3000개, 300개(train, dev)의 clean 문장을 추가하였다.

모델 별 성능

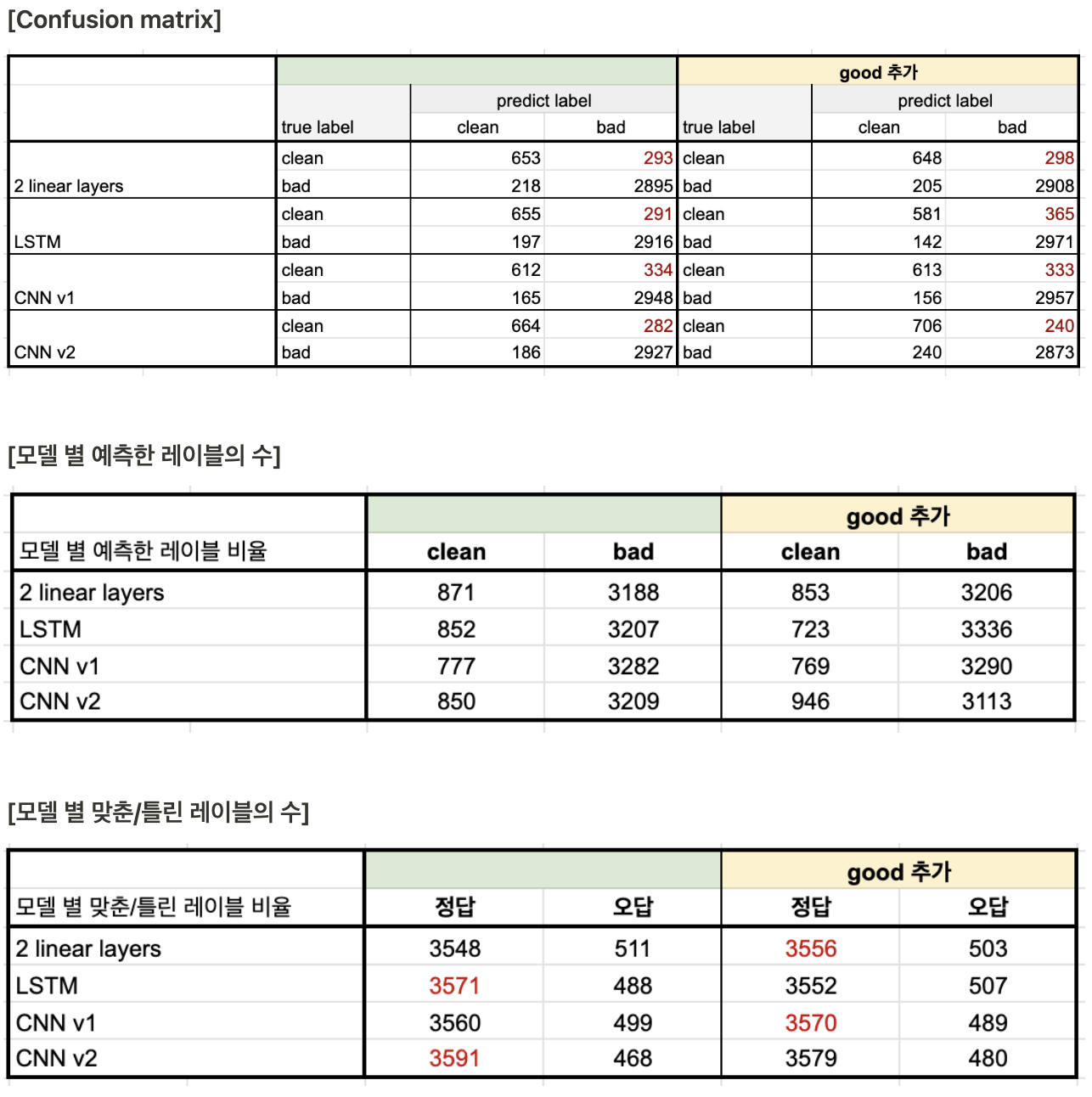
- 전체적인 성능은 문장을 추가하기 전과 후가 거의 비슷하다. 데이터를 추가하긴 했지만, 여전히 레이블 불균형 문제가 존재하기 때문에 전후의 성능 차가 거의 없다고 추측된다.
➡️ task 목적성의 훼손될 수 있긴 하지만 레이블을 1:1로 맞추어 트레이닝을 진행해보았다.
✔️ clean 문장 추가를 통한 보완2
위와 동일하지만 clean 문장과 bad 문장의 비율이 1:1이 될 수 있도록 NSMC 데이터를 추가하여 모델을 학습한 후에 전후의 성능 비교를 진행했다.
모델 별 성능
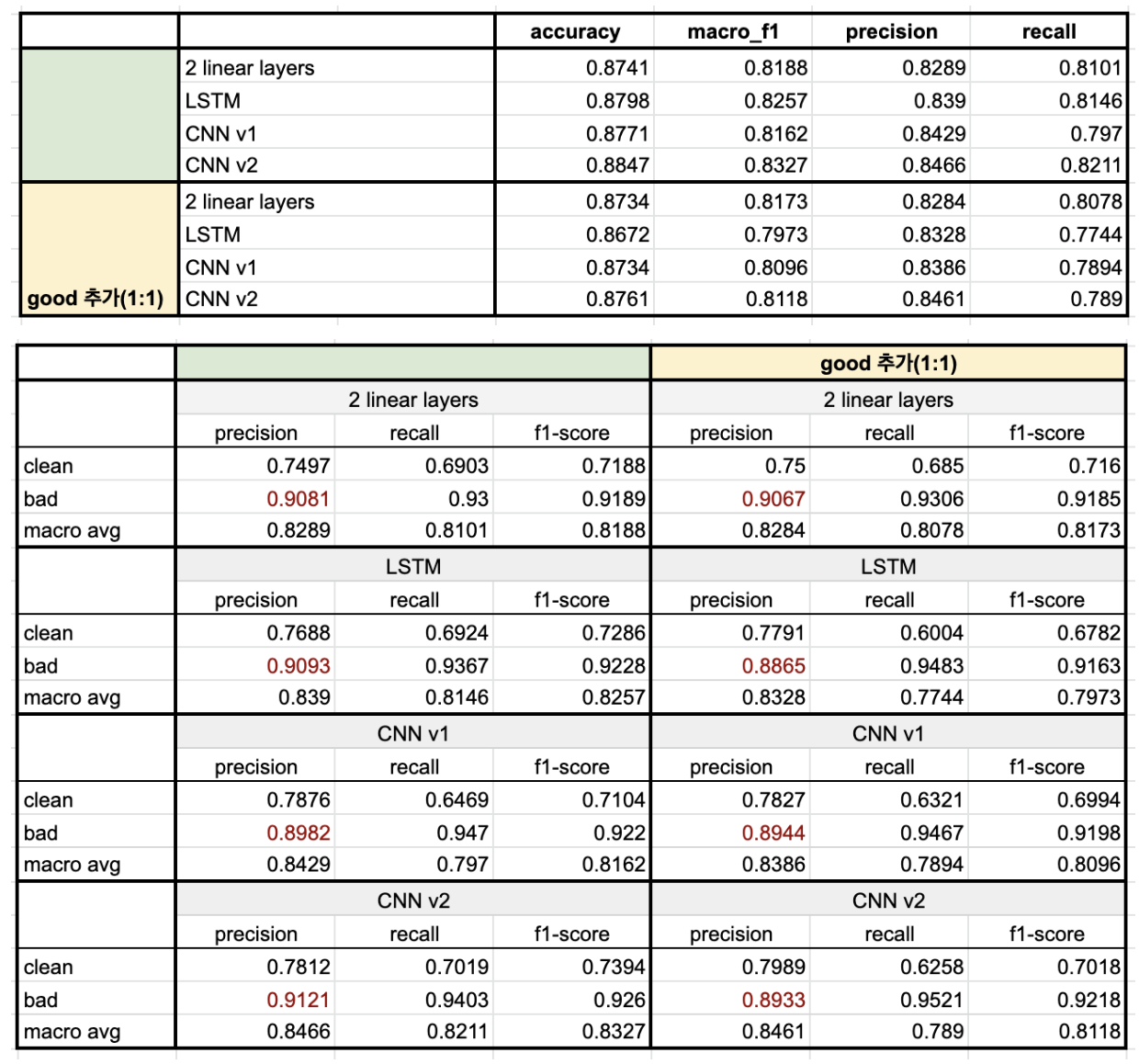
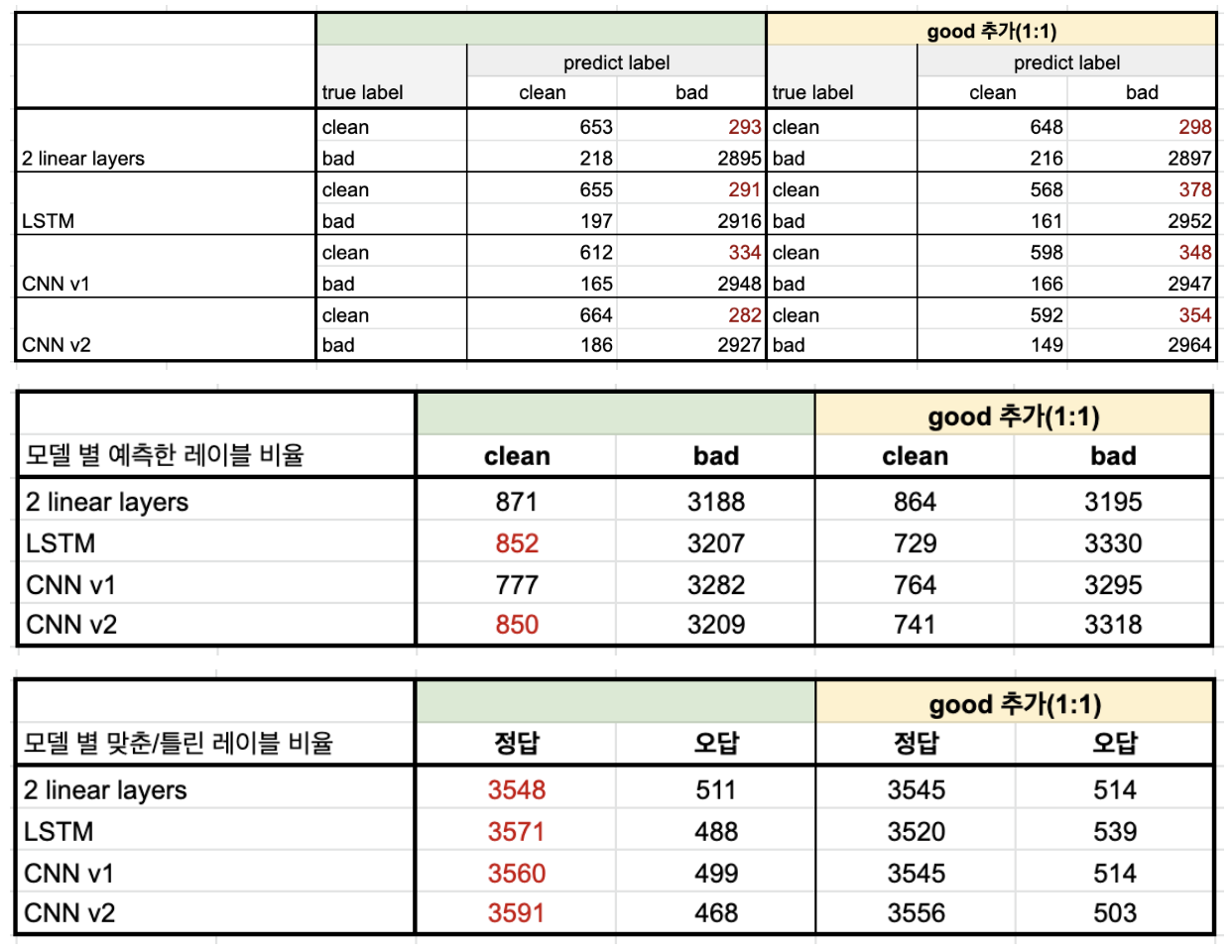
- 전체적인 정답 문장 수를 봤을 때는 기존 모델이 약간 더 많지만, 오차 범위 내라고 판단이 된다. 하지만 모델이 예측한 레이블의 수를 비교했을 때 LSTM, CNN v2는 오히려 clean 문장을 추가한 모델이 더 bad sentence로 많이 분류하는 경향을 보였다(bad에 대한 recall이 높음).
➡️ 좋은 퀄리티의 데이터(노이즈가 적은 데이터)를 추가하지 못 할 경우에는 오히려 불균형 데이터를 사용했을 때의 성능이 더 높을 수 있다는 것을 보여주는 결과.
✔️ 레이블 치환을 이용한 보완
이전에 Named Entity Recognition(NER)과 Grammatical Error Correction(GEC) 모델을 개발할 당시에 봤었던 논문을 참고하여 생각한 아이디어이다. 아래 논문들을 참고하여 전체 레이블을 모두 사용하여 학습한 후, 인퍼런스 단게에서 clean인지 아닌지에 따라서 다시 2개의 레이블로 치환하는 방식을 적용해보았다.
참고했던 논문
자원부족 환경에 적합한 BIT 개체명 표기법
Multi-Class Grammatical Error Detection for Correction: A Tale of Two Systems
레이블 분포
Unsmile dataset에는 하나의 문장에 대해서 여러 개의 레이블을 가지는 경우가 존재하지만, 이 실험에서는 여러 개의 레이블로 학습한 후에 다시 치환하는 것이 모델 성능 개선에 효과적인가를 확인하기 위해서 별도의 처리를 하지 않고 태깅되어 있는 레이블 중 하나를 랜덤으로 선택하였다. 쉽게 말하면 한 문장 당 하나의 레이블만을 가지도록 변환 후에 사용했다.
모델 별 성능
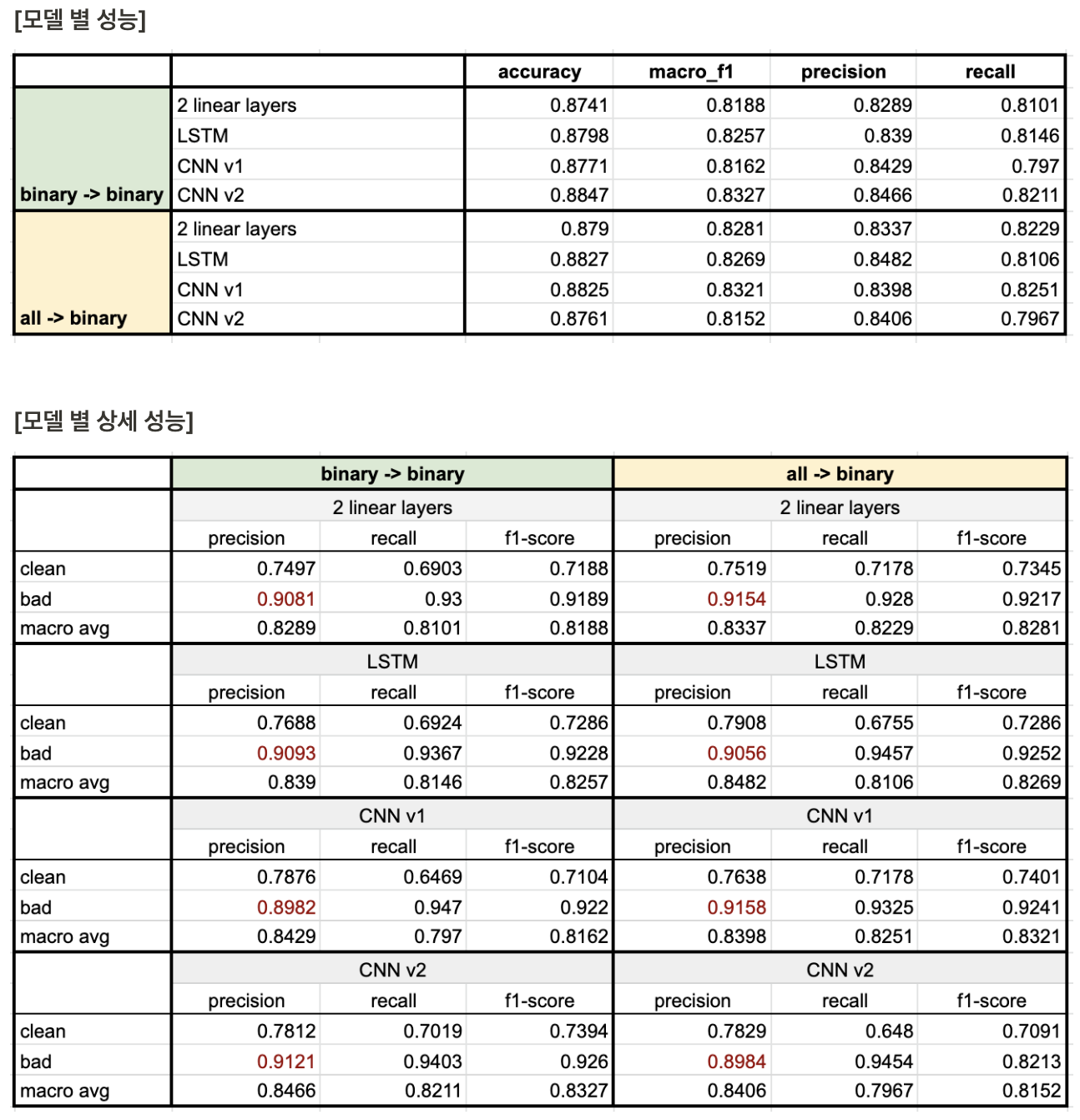
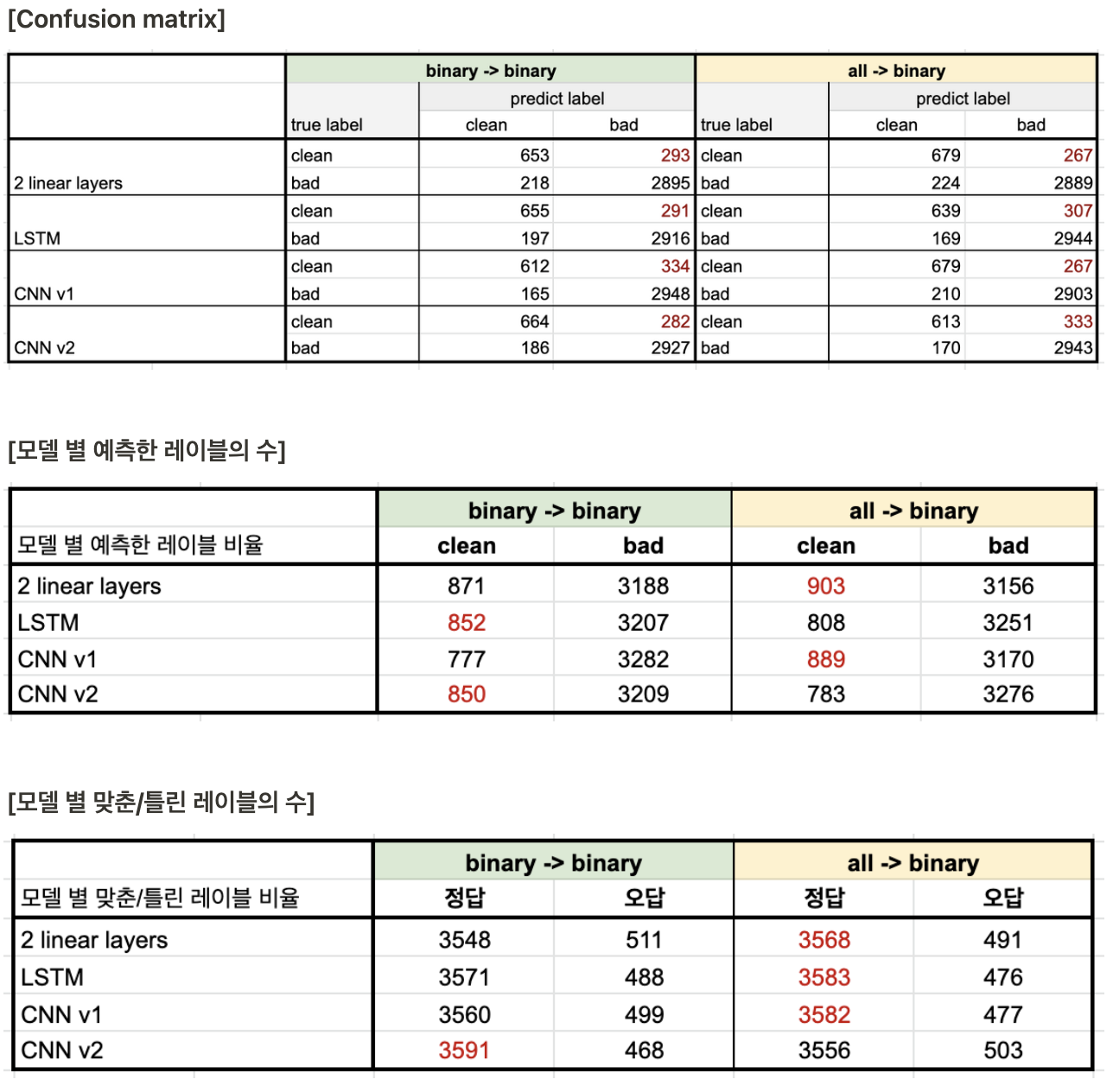
조건에 따라서 성능 향상을 보인 모델도 있고, 성능이 떨어진 모델도 존재한다. 하지만, 성능 등락 폭이 크지 않기 때문에 오차 범위 내라고 판단했다. 효과가 없었던 이유를 분석하기 하기 위해서 참고했던 논문들의 실험 환경을 고려하여 원인을 생각해보았다.
-
두 개의 논문은 모두 토큰 단위의 분류 문제이다. 토큰 단위의 분류에서의 성능 향상 방법이 문장 단위 분류 문제에 적합하지 않았을 수 있다.
-
두 개의 논문은 하나의 레이블을 여러 개의 레이블로 늘려서 학습한 후에 다시 치환했다는 점에서는 같지만 한 가지 다른 점이 존재했다. Multi-Class GED 논문은 전체 레이블 중 적은 부분을 차지하는 Incorrect(문법적 오류가 포함된 토큰)을 여러 개의 클래스로 나누었고, BIT 논문은 전체 레이블 중 대부분을 차지하는 O(Not NER)을 여러 개의 클래스로 나눴다는 점에서 달랐다.
- 전체 레이블 중에서 대부분을 차지하는 O를 여러 개의 클래스로 나눈 BIT 논문의 성능 평가 결과를 봤을 때, BERT 모델에 대해서는 오히러 성능이 하락했음을 확인할 수 있었다. ➡️ pre-training 단계에서 이미 대용량의 데이터를 학습한 PLM에는 적합하지 않은 방법일 수 있다는 생각이 들었다.

[출처 : 자원부족 환경에 적합한 BIT 개체명 표기법]
- 전체 레이블 중 적은 비율을 여러 클래스로 나눈 Multi-Class GED 논문은 실험에서는 더 많은 비율인 Incorrect를 여러 클래스로 나누었기 때문에 환경이 조금 다르다고 볼 수 있을 것 같다.
- 전체 레이블 중에서 대부분을 차지하는 O를 여러 개의 클래스로 나눈 BIT 논문의 성능 평가 결과를 봤을 때, BERT 모델에 대해서는 오히러 성능이 하락했음을 확인할 수 있었다. ➡️ pre-training 단계에서 이미 대용량의 데이터를 학습한 PLM에는 적합하지 않은 방법일 수 있다는 생각이 들었다.
✔️ loss function 변경을 통한 보완
레이블 불균형 데이터를 위한 Loss function 중 하나인 focal loss를 적용하여 모델을 학습하여 전후 성능 비교를 진행했다. focal loss에 대한 내용은 링크를 참고했다.
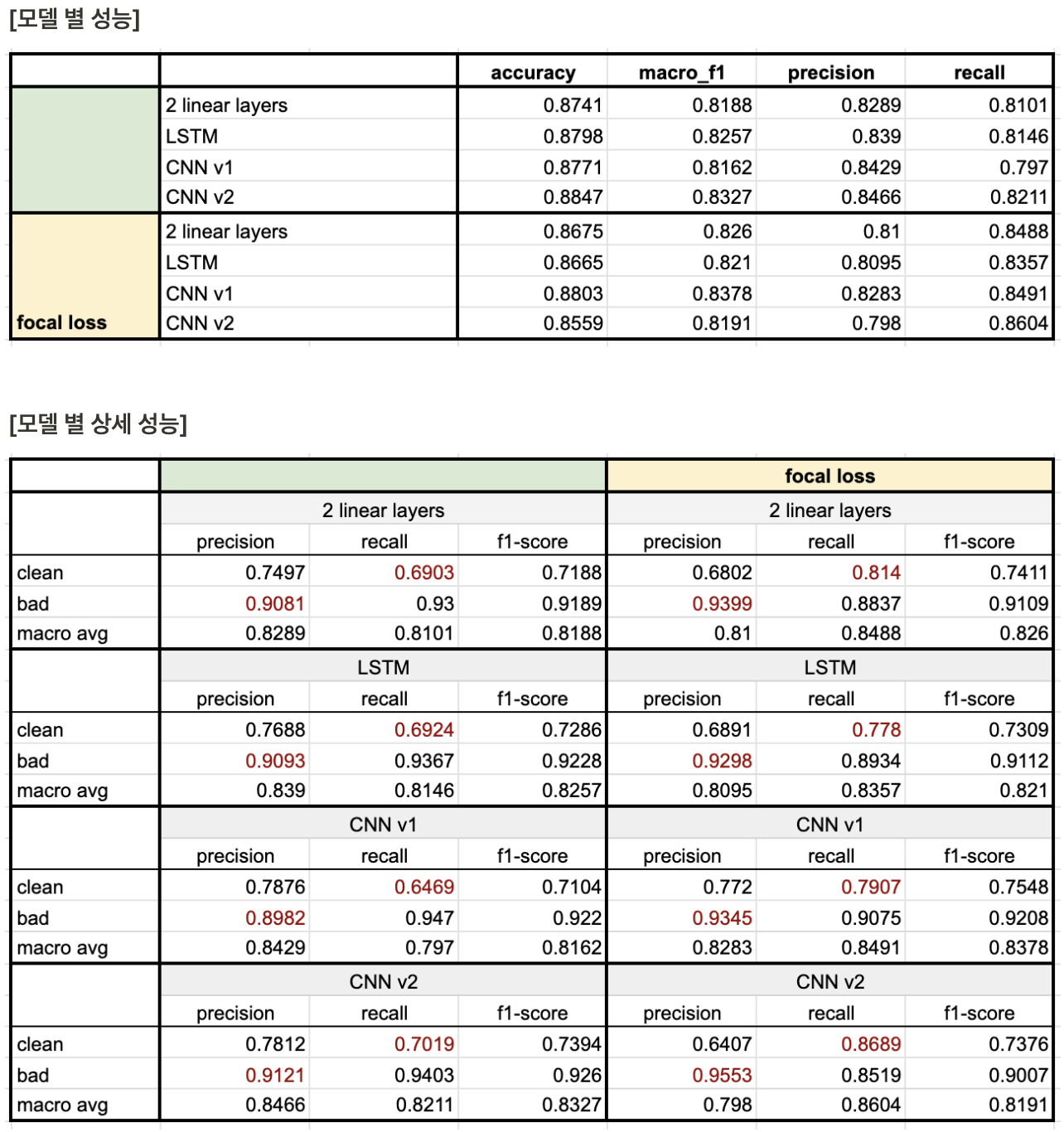
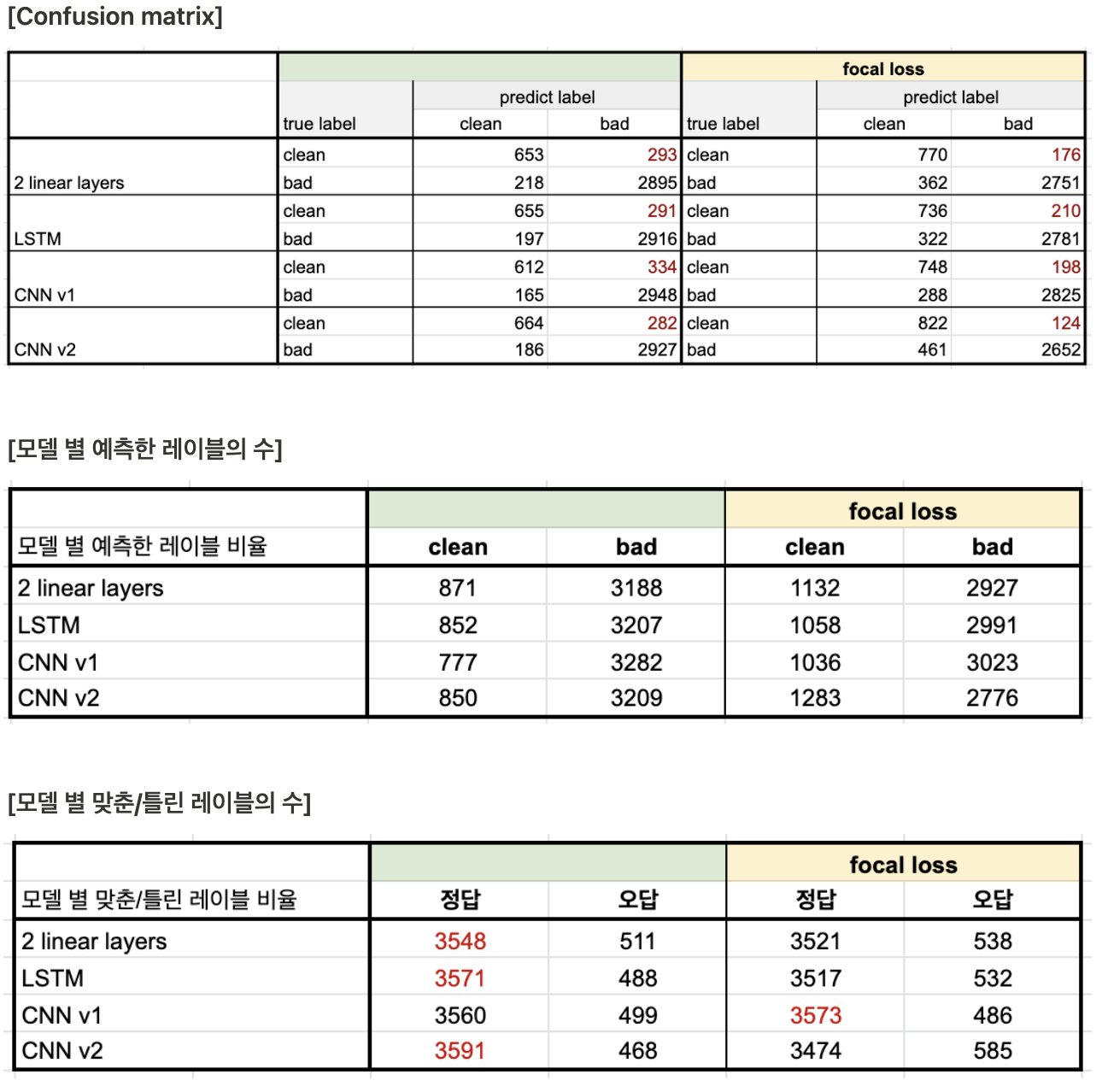
focal loss를 적용한 결과 전체적인 성능(accuracy, macro f1-score)은 하락했지만, bad sentence에 대한 precision과 clean sentence에 대한 recall이 증가하였다. 모델 별 예측한 레이블의 수를 봤을 때도 적용하기 전에 비해서 clean으로 분류한 문장의 수가 늘어난 것을 확인 가능하다.
- 현재 세운 기준에는 좀 더 적합한 방향으로 학습되는 것을 확인할 수 있다.
3. 결론 및 방향성
- 사용한 데이터에는 레이블 불균형이 존재했지만, 우려했던 것에 비해서 모델이 극단적으로 한 쪽(bad)으로 분류하는 모습을 보이진 않았다.
- 레이블 불균형 문제를 보완하기 위한 방법 중에서는 focal loss와 같이 loss function을 변경하는 것이 가장 효과적이었다. 이 방법을 사용했을 때는 전체적인 성능이 떨어지긴 하지만, 실험 전에 세운 가설(실제 환경)에는 좀 더 적합한 모습을 보였다.
➡️ 다만, 실제 사용을 위해서는 성능 개선이 필요할 것.
- 모델 성능 개선을 위한 다음 단계로는 이전에 2. 베이스라인 모델 선택하기에서 생각했었던 unlabeled data를 활용하는 방법을 선택하여 실험하기로 결정했다. 이를 적용하기 위해서는 이전에 리서치를 진행했던 Semi-supervised learning for Text classification의 MixText를 활용하고자 한다.
- MixText에서는 데이터 증강을 위해서 back-translation을 활용하는데 이를 그대로 hate speech detection에 적용하기엔 무리가 있다. (아래 그림 참고)
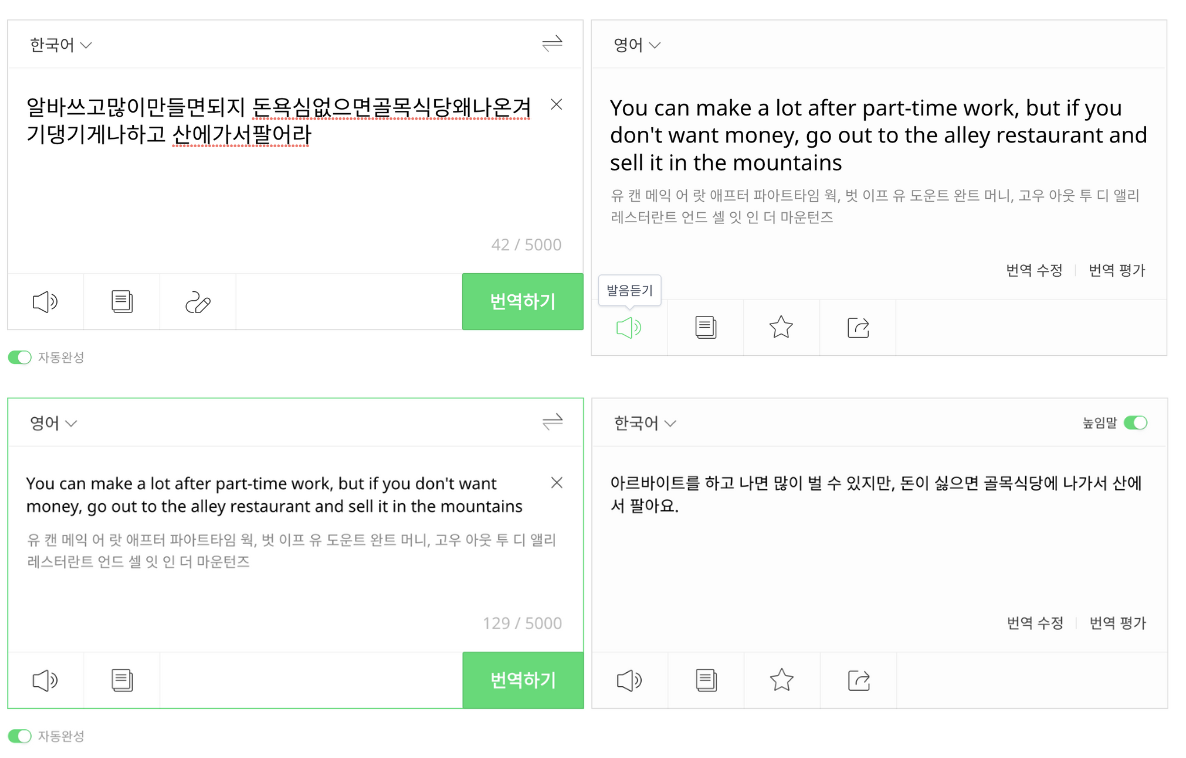
- 원본 문장의 뜻이 달라지고, 기존 입력과 다르게 정제된 형태로 변환되는 문제가 있음.
- MixText에서는 데이터 증강을 위해서 back-translation을 활용하는데 이를 그대로 hate speech detection에 적용하기엔 무리가 있다. (아래 그림 참고)

잘 읽고 갑니다