
💻NLP(Natural Language Processing) :
인공지능의 한 분야로 텍스트 데이터를 처리 및 해석하는 기술.
언어학 지식에 상관없이 텍스트를 이해하는 통계적 방법을 사용해 문제를 해결한다.
1.1 Supervised Learning
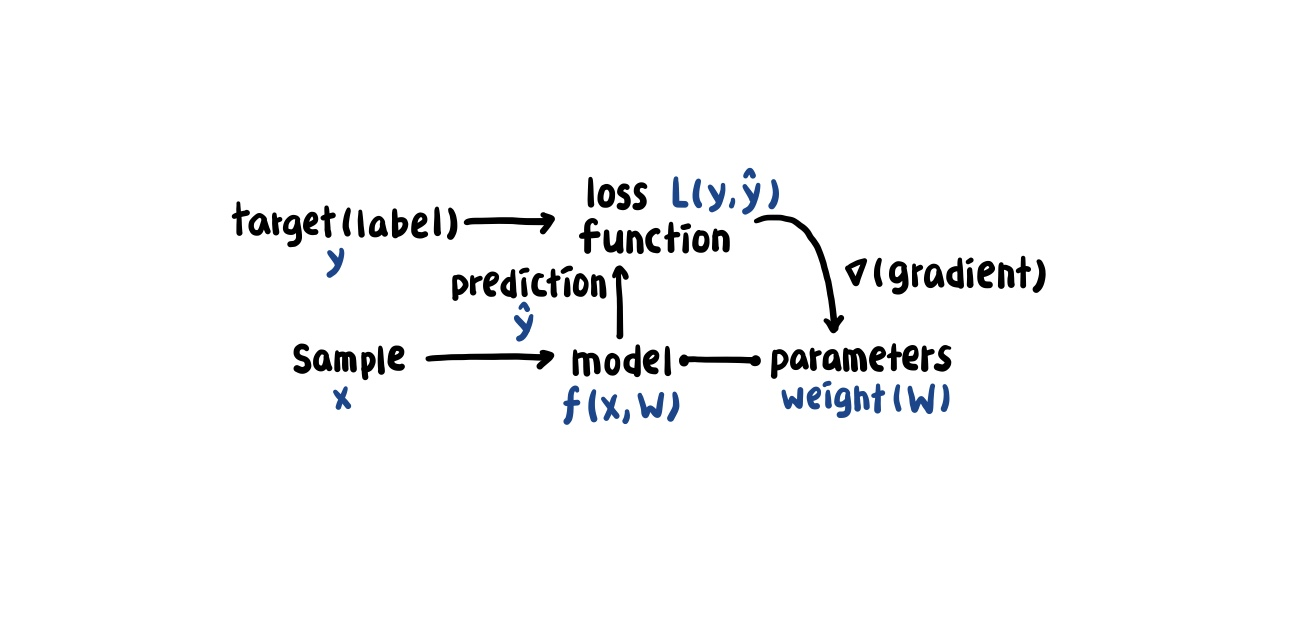
1.2 샘플과 타깃의 Encoding
encoding이란? 정보의 형태나 형식을 변환하는 처리, 데이터(sample&target)를 벡터나 텐서와 같은 수치형 데이터로 표현하는 것.
1.2.1 One-Hot representation
One-Hot Encoding : 표현하고 싶은 단어에 상응하는 원소는 1을 부여하고 나머지 원소들은 0을 부여하는 벡터 표현 방식. 이때, 벡터의 차원은 단어 집합의 크기이다.
Time flies like an arrow.
Fruit flies like an banana.문장을 token으로 나누고 구두점을 무시한 다음 모두 소문자로 바꾸어 단어 집합을 만든다.
{time, fruit, flies, like, a, an, arrow, banana}필요한 단어의 개수 8개 이므로 8차원 One-Hot vector로 각 단어를 표현할 수 있다.
| 단어 | 단어 idx | one-hot vector |
|---|---|---|
| time | 0 | [1, 0, 0, 0, 0, 0, 0, 0] |
| fruit | 1 | [0, 1, 0, 0, 0, 0, 0, 0] |
| flies | 2 | [0, 0, 1, 0, 0, 0, 0, 0] |
| like | 3 | [0, 0, 0, 1, 0, 0, 0, 0] |
| a | 4 | [0, 0, 0, 0, 1, 0, 0, 0] |
| an | 5 | [0, 0, 0, 0, 0, 1, 0, 0] |
| arrow | 6 | [0, 0, 0, 0, 0, 0, 1, 0] |
| banana | 7 | [0, 0, 0, 0, 0, 0, 0, 1] |
NOTE 두 문장에서 쓰이는 'flies'의 의미는 각각 다르지만, 같은 벡터로 표현된다.
1.2.2 TF representation
원소의 인덱스가 가리키는 단어가 문장(corpus)에 등장하는 횟수이다.
예를 들어, 'Fruit flies like time flies a fruit'의 TF 표현은 [1, 2, 2, 1, 1, 0, 0, 0] 이다.
1.2.3 TF-IDF representation
TF는 단어 등장 빈도 수에 비례하여 가중치 부여하는 반면에, IDF는 희귀한 단어에 높은 가중치를 부과하는 방식이다. 'a'/'an'과 같은 단어는 자주 등장하지만 중요 정보를 담고 있지 않지만 'tetrafluoroethlene'과 같은 희귀 단어가 문서의 특징을 잘 나타내는 경우에 적합한 표현이다.
= 를 포함한 문서의 개수, = 전체 문서 개수 ( = 이라면, 이 되어 단어 제외됨)
1.2.4 Target Encoding
Target variable(label)의 형태는 해결하고자 하는 NLP 문제에 따라 다르다. 기계 번역, 요약, 질의응답 문제에서 label도 text이기 때문에 encoding하여 벡터 형태를 가진다.
많은 NLP 문제는 categorical label 중에서 하나의 label 예측하는 것이다. Categorical label을 encoding 하기 위해 label 마다 고유한 인덱스를 부여하는 방법을 주로 사용한다.
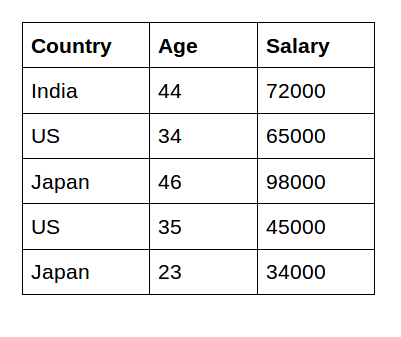
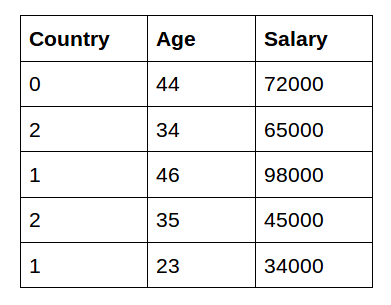
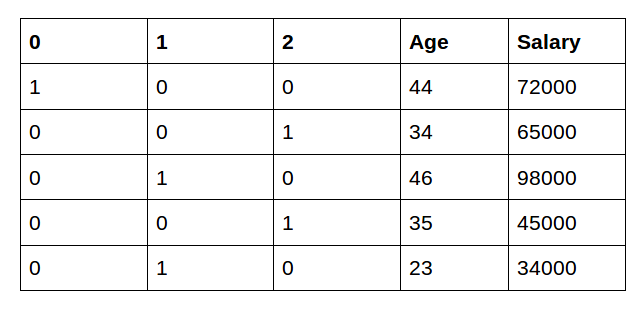
Label Encoding Categorical Encoding vs. One-Hot encoding
"country" label을 encoding 했을 때의 차이
1️⃣Categorical Encoding
2️⃣One-Hot Encoding
입력된 단어로 다음 단어를 예측하는 언어 모델링 문제의 경우에는 label의 규모가 한 언어의 전체 어휘가 된다. 이렇게 출력하려는 label의 수가 너무 많을 경우에는 다루기 힘들어진다는 단점이 있다.
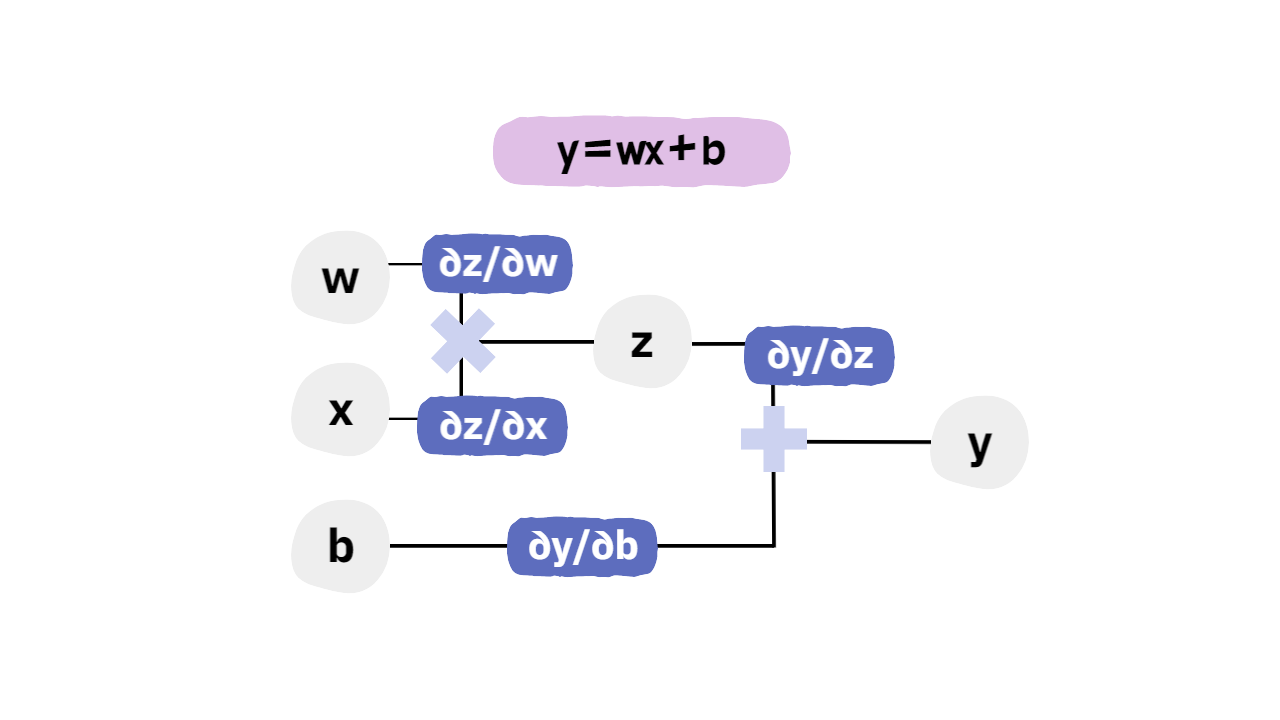
1.3 계산 그래프
1.4 Pytorch Basic
PyTorch
- A python based scientific cimputing package
- A replacement for Numpy to use the power fo GPUs
- A deep learning research platform
PyTorch 기본 구성
1) torch : 메인 네임스페이스로 고차원 연산을 위한 tensor 등의 다양한 수학 함수가 포함되어 있다. Numpy와 유사한 구조를 가진다.
2) torch.nn : Neural Net 구축을 위한 layer, architecture, activation function, loss fucntion 등이 저장되어 있다. Deep Learning 개발을 진행할 시에 항상 호출되는 package 이다.
3) torch.autograd : 자동 미분을 위한 함수들이 포함되어있다.
4) torch.optim : Stochastic Gradient Descent(SGD)를 중심으로 한 parameter optimization을 위한 algorithm이 구현되어 있다.
5) torch.utils.data : SGD의 반복 연산을 실행할 때 사용되는 mini-batch utility function이 있다.
6) torch.onnz : Open Neural Network Exchange(ONNX) 형식으로 neural net model을 exprot할 때 사용한다. (ONNX는 서로 다른 Deep Learning Framework 사이에서 modle 공유할 때 사용하는 format.)
Tensor Manipulation
1) Pytorch Tensor Shape Convention
- 2D tensor의 크기 |t| = (batch size, dimension)
- 3D tensor의 크기
1️⃣ Computer Vision: |t| = (batch size, width, height); width height 크기를 가진 img가 여러 장(batch size)으로 구성됨.
2️⃣ NLP: |t| = (batch size, length, dim) = (batch size, 문장의 길이, 단어 벡터의 차원)
ex) 4개의 문장으로 구성된 전체 training set
[[나는 샤브샤브 사랑해], [나는 하이디라오 사랑해],
[나는 샤브샤브 좋아해], [나는 하이디라오 좋아해]]컴퓨터 입력으로 사용하기 위해 단어별로 나누어줌.
4×3의 2D tensor.[['나는', '샤브샤브', '사랑해'], ['나는', '하이디라오', '사랑해'],
['나는', '샤브샤브', '좋아해'], ['나는', '하이디라오', '좋아해']]'나는' = [0.1, 0.1, 0.0]
'샤브샤브' = [0.2, 0.4, 0.8]
'하이디라오' = [0.4, 0.2, 0.2]
'사랑해' = [0.4, 0.8, 0.0]
'좋아해' = [0.5, 0.6, 0.7]위의 기준을 따라 training set 재구성,
4×3×3의 크기를 가지는 3D tensor[[[0.1, 0.1, 0.0], [0.2, 0.4, 0.8], [0.4, 0.8, 0.0]],
[[0.1, 0.1, 0.0], [0.4, 0.2, 0.2], [0.4, 0.8, 0.0]],
[[0.1, 0.1, 0.0], [0.2, 0.4, 0.8], [0.5, 0.6, 0.7]],
[[0.1, 0.1, 0.0], [0.4, 0.2, 0.2],0.5, 0.6, 0.7]]]
batch size = 2로 training set 2개로 나누기.
# 첫번째 batch (2×3×3)
[[[0.1, 0.1, 0.0], [0.2, 0.4, 0.8], [0.4, 0.8, 0.0]],
[[0.1, 0.1, 0.0], [0.4, 0.2, 0.2], [0.4, 0.8, 0.0]]]
# 두번째 batch (2×3×3)
[[[0.1, 0.1, 0.0], [0.2, 0.4, 0.8], [0.5, 0.6, 0.7]],
[[0.1, 0.1, 0.0], [0.4, 0.2, 0.2],0.5, 0.6, 0.7]]]
Tensor를 GPU에 할당하는 방법
x = torch.tensor([1., 1.], device = "cuda") x = torch.tensor([1., 1.]).cuda() x = torch.tensor([1., 1.]).to("cuda") x.device # 할당된 device 정보 (cuda:0)
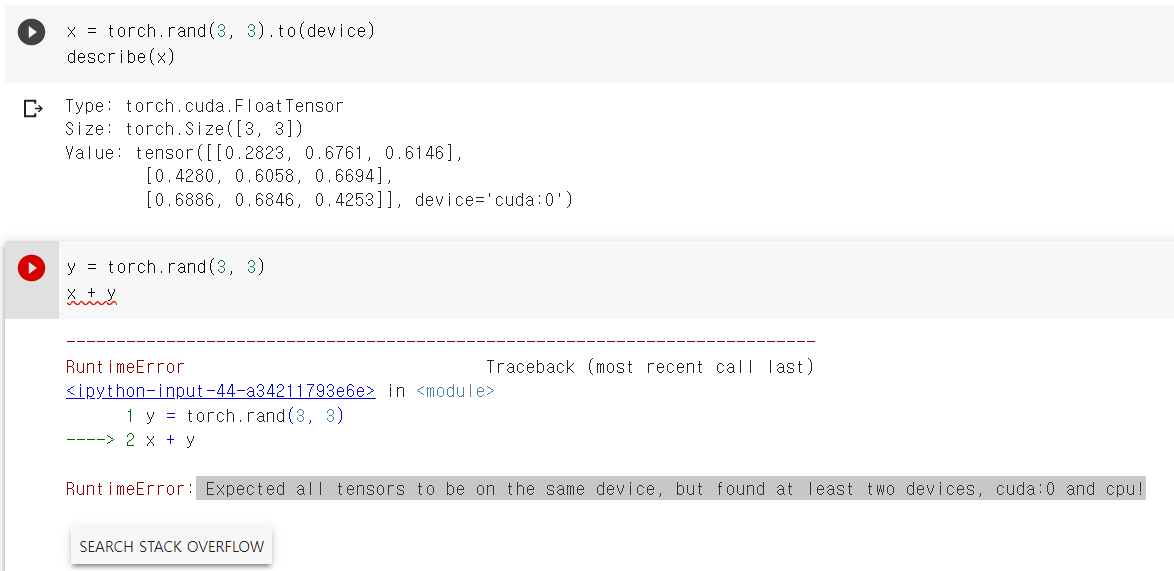 더하고자하는 두 객체가 같은 장치에 있어야 연산 가능함.
더하고자하는 두 객체가 같은 장치에 있어야 연산 가능함.
