
2.1 Corpus, Token, and Type
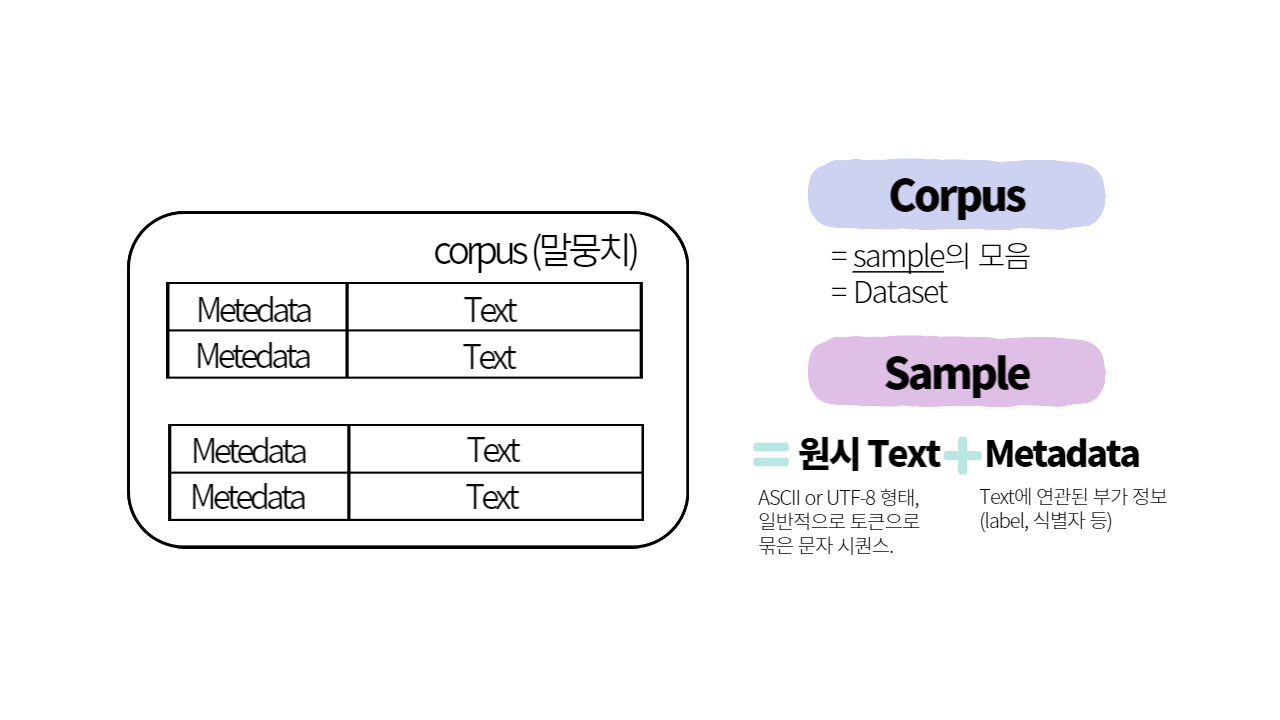
1) Corpus A collection of authentic text or audio organized into datasets
말뭉치라는 뜻으로 자연어 처리를 위해 언어의 표본을 추출한 집합이다. 확률/통계적 기법과 시계열적인 접근으로 전체를 파악한다. 언어의 빈도와 분포를 확인할 수 있는 자료이다. 복수형은 corpora 이다. <출처: 말뭉치, 위키백과>
2) Token 영어에서 token은 공백 문자나 구두점으로 구분되는 단어와 숫자를 의미한다. 토큰화(tokenization)은 텍스트를 토큰으로 나누는 과정을 말한다. 터키어와 같은 교착어는 공백 문자 및 구두점으로 토큰화하는 것이 어려워 보다 전문적인 기술이 필요하다.
3) Type corpus에 등장하는 고유한 token.
🦄metadata란? 데이터에 관한 구조화된 데이터로, 다른 데이터를 설명해 주는 데이터이다.
예를 들어, 영화 DVD에서 포장에 붙어있는 제목, 상영시간, 등급, 제작사, 감독, 줄거리 등에 관한 정보를 '메타데이터'라고 할 수 있다.
-
데이터를 표현하는 역할을 한다.
-
데이터를 빨리 찾을 수 있게 한다.
메타 데이터는 컴퓨터에서 정보의 인덱스(Index) 구실을 하여 다른 데이터를 빠른 속도로 찾을 수 있도록 한다.
<출처: 메타데이터, 두산백과와 메타데이터, HRD 용어사전>
2.2 N-gram
N-gram model 통계학 기반의 언어 모델 중 하나이다. 의 은 연속적인 개의 단어 나열을 하나의 token으로 간주한다는 의미를 가진다.
부분 단어(subword) 자체가 유용한 정보를 가지고 있을 때 을 사용할 수 있다.

2.3 표제어와 어간
1) lemmatization 표제어 추출 토큰을 표제어로 바꾸어 벡터 표현의 차원을 축소하는 것을 말한다.
lemma 표제어 : 단어의 기본형. 예) flow, flew, flies, flown, flowing의 표제어=fly
2) stemming 어간 추출 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해 내어 차원 축소하는 기법이다. 어간 추출 후의 결과에는 사전에 없는 단어들도 포함되어 있다.
2.4 문장과 문서 분류기
2.5 POS Tagging
POS(part-of-speech) Tagging : 품사 태깅. 각 단어에 품사를 붙이는 절차로 실용적인 작업 전에 해야하는 사전 단계이다.
2.6 Chuncking & Named Entity
1) Chuncking 문장을 명사구(NP)와 동사구(VP)로 구별하는 과정이다. shallow parsing이라고도 한다.
2) Named Entity 개체명. 개체명은 사람, 장소와 같은 고유묭사를 의미하는 문자열이다.
