
1. Feature Selection 개요
데이터의 특성(feature) 중에서 가장 중요하게 생각되는 변수를 선택하는 것
목표 : 모델 훈련에 있어 가장 유용한 특성을 선택하는 것
(모델의 정확도 향상을 위해 가장 좋은 성능을 보여줄 변수들의 부분집합을 찾아내는 과정)
Feature Selection의 이점
- 차원의 저주 해결
- 모델 성능 향상
- Overfitting 방지
- 계산 효율성 증가
- 데이터 분석에서 중요하지 않은 feature 제거
Feature Selection 종류
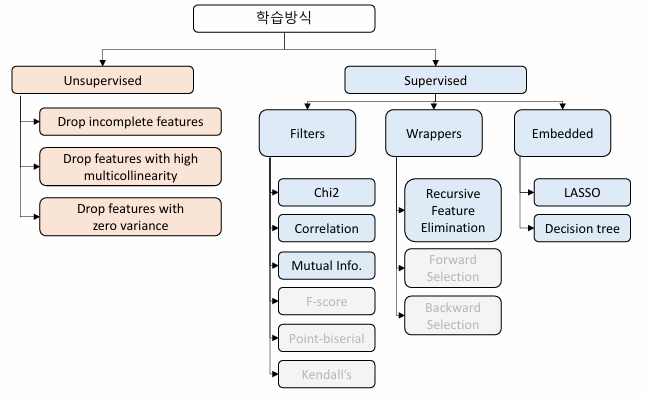
2. Filter Method
: 카이제곱검정(Chi-squared Test) / 상관계수(Correlation coefficient) / 상호정보량(Mutual Information)
dataset의 각 feature들의 통계적 특성을 이용하여 중요도를 평가, 선택하는 방법
대표적인 filter method
- 카이제곱검정(Chi-squared Test)
- 상관계수(Correlation coefficient)
- 상호정보량(Mutual Information)
Filter Method의 원리
: 기준값(label)과 변수들 간에 관계성을 분석하여, 관계가 깊은 변수로 간주하여 선택
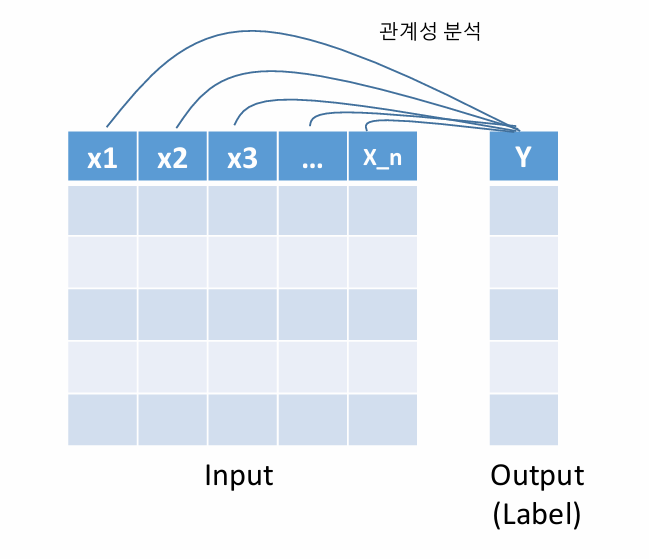
Filter Method 1: Chi-squared Test
임의의 특정 feature를 선택하고, 다른 feature간 독립성을 검정하여 feature의 중요도를 측정하는 방법
- 범주형 데이터에서 주로 사용
Chi-squared Test Process
1) 가설을 설정
2) 유의수준 결정
3) 기각 값 결정( 값 )
4) 관찰도수에 대한 기대도수 계산
5) 검정 통계량 계산
6) 귀무가설의 채택 또는 기각 여부 판정
Filter Method 2: Correlation coefficient
데이터 간 상관계수를 구한 후, 상관계수가 높을 경우 해당 변수를 선택하는 방법
상관계수 : 두 변수 사이에 관계 정도를 나타내는 수치 ( 사이 값 )
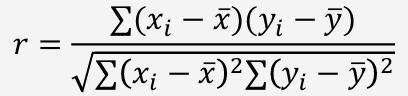
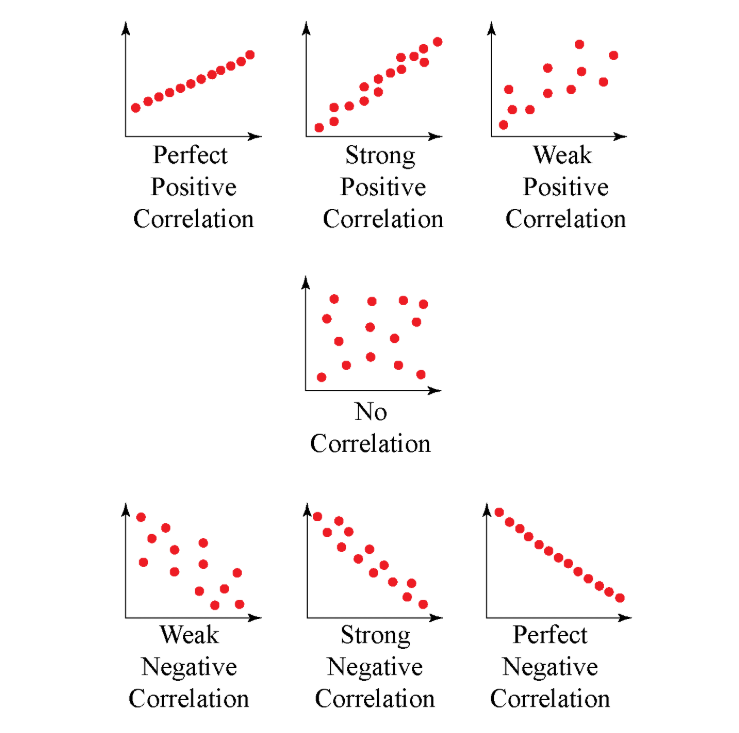
- +1에 가까울 수록 양의 상관관계
- -1에 가까울 수록 음의 상관관계
- 0에 가까울 수록 아무 관계 없음
장점
- 간단하고 직관적인 방법
- 변수 간 관계 파악 쉬움
- 계산 단순
단점
- 선형적 관계를 기반으로 하기에, 비선형적인 관계 분석 어려움
- 연관성을 보여줄 뿐, 인과관계 설명 x
- 누락된 데이터나 이상치에 민감하게 반응
Example. Correlation 계산 (중요)
주어진 두 변수 간 상관계수를 구하기

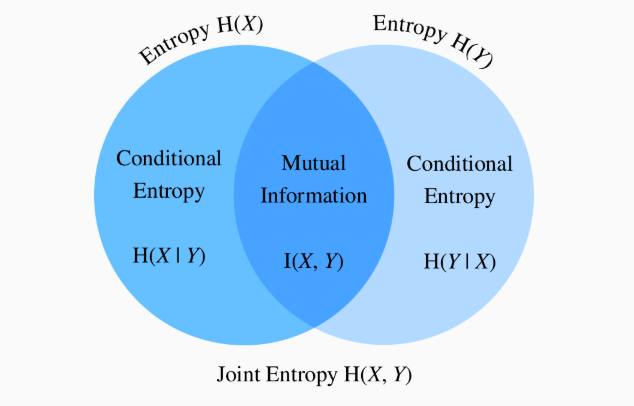
Filter Method 3: Mutual Information
두 확률 변수 간 의존성을 나타내는 척도
(의존성이 클 경우 해당 변수를 선택)
Mutual Information Process
1) 각 특성과 목표 변수 간의 상호 정보량 계산
2) 계산된 상호 정보량을 기준으로 정렬
3) 임계값을 기준으로 특성 선택
장점
- 다른 feature selection보다 정확함
- 비선형적 관계 변수도 분석 가능
- 비대칭성을 고려 가능(양방향, 단방향 구분 가능)
- 데이터가 희소한 경우에도 적용 가능
단점
- 계산 비용이 큼
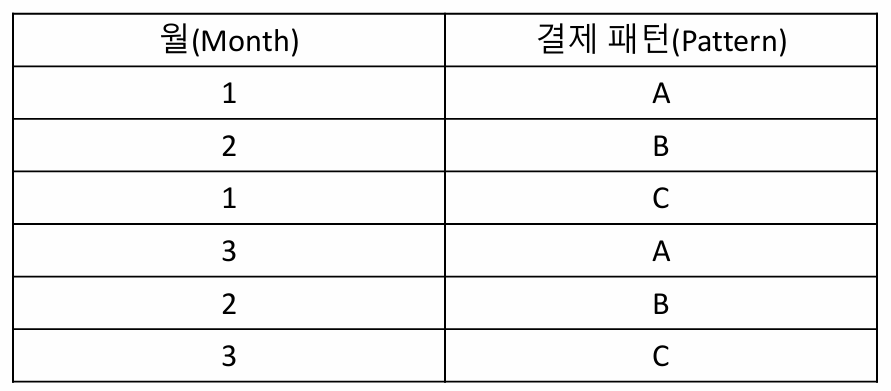
Example 1. Mutual Information
월별 결제 패턴이 주어졌을때, 주어진 두 변수의 상호 정보량 구하기
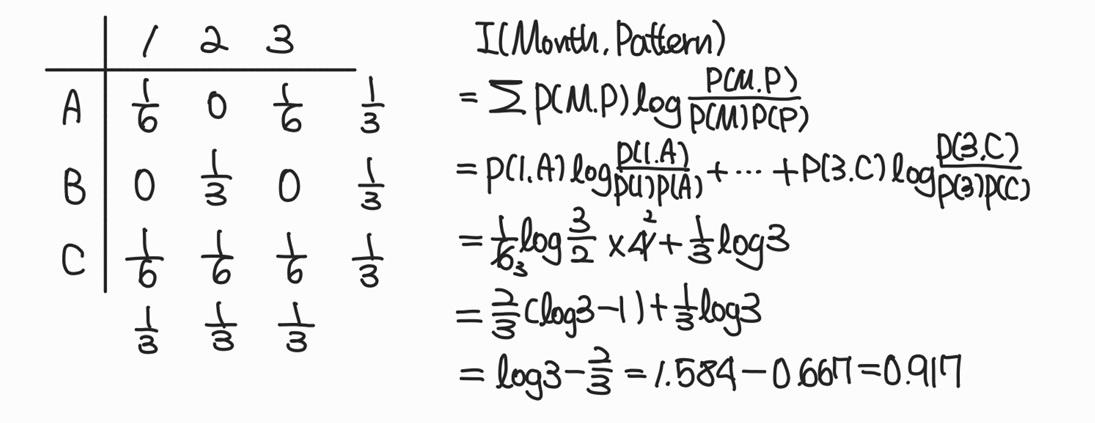
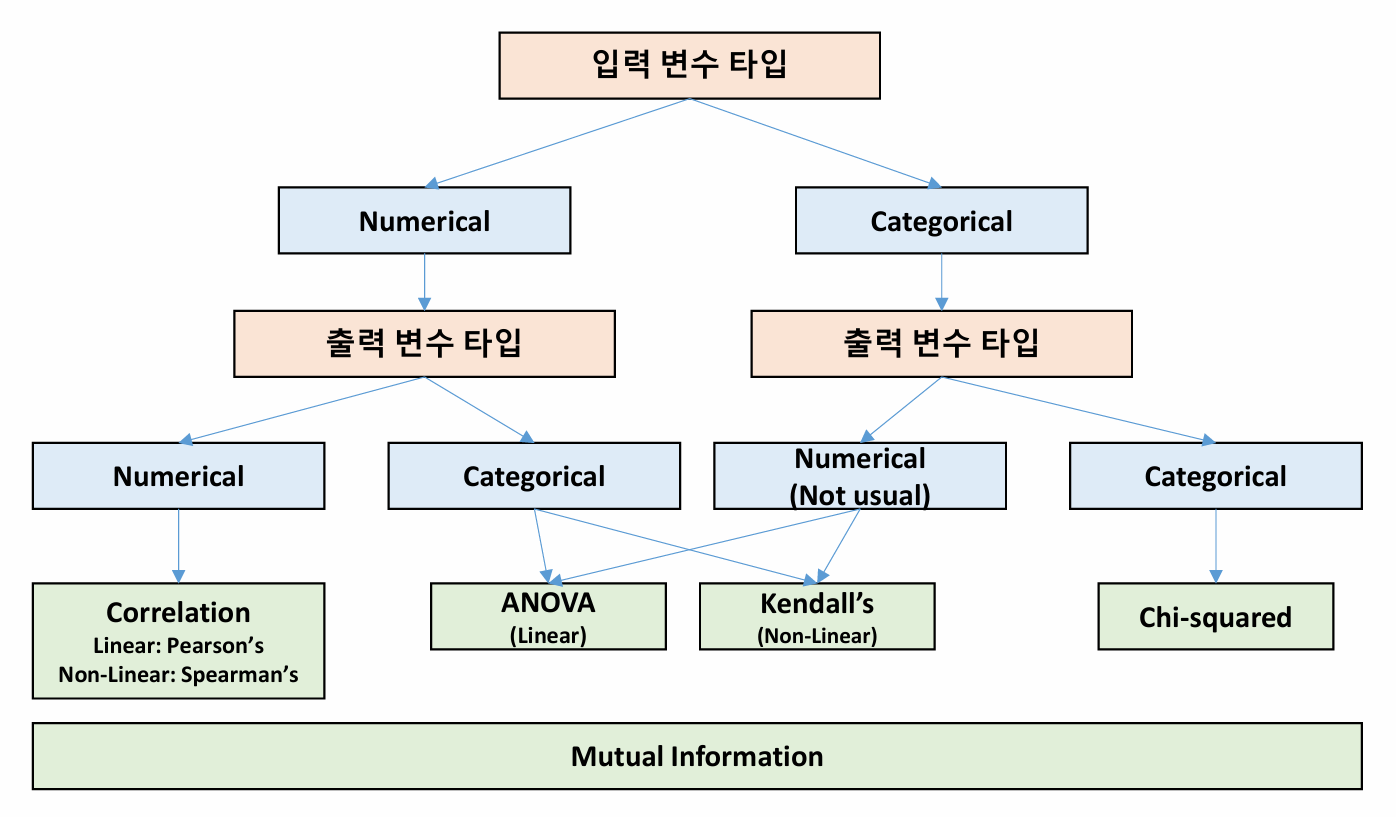
Filter Method
: Feature Selection 방법 선택
3. Wrapper Method
모델을 학습시키면서 변수를 선택하는 방법
특정 feature 조합에 대해 model을 학습시켜 성능을 평가한 후,
다음 라운드에서 추가하거나 제거한 뒤, 가장 최적의 feature를 선택
대표적인 Wrapper Method
:후진 소거법 (Recursive Feature Elimination, RFE)
(중요도가 낮은 feature를 하나씩 제거하는 방식)
Wrapper Method. RFE
모든변수를 모두 포함시킨 후 학습을 진행하고,
중요도가 낮은 변수를 하나씩 제거하는 방식
RFE Process
1) 모든 특성을 포함하는 모델 선택
2) 선택한 모델을 사용하여 feature의 중요도 계산
3) 중요도가 가장 낮은 feature 제거
4) feature 제거 후 남은 것으로 새로 학습
5) 1~4 과정 반복하여, 정해놓은 feature 개수 or 중요도에 따라 선택
장점
- 모델의 성능을 극대화하는 특성 집합 찾을 수 있음
- 특성의 중요도 파악 가능
단점
- 특성을 선택하는데 시간 오래 걸림
- 모델에 따라 결과가 달라질 수 있음
4. Correlation 실습
: Boston 주택 가격 data set으로 feature 선택
데이터 로드
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df=pd.read_csv(r'/content/boston.csv')
df.head()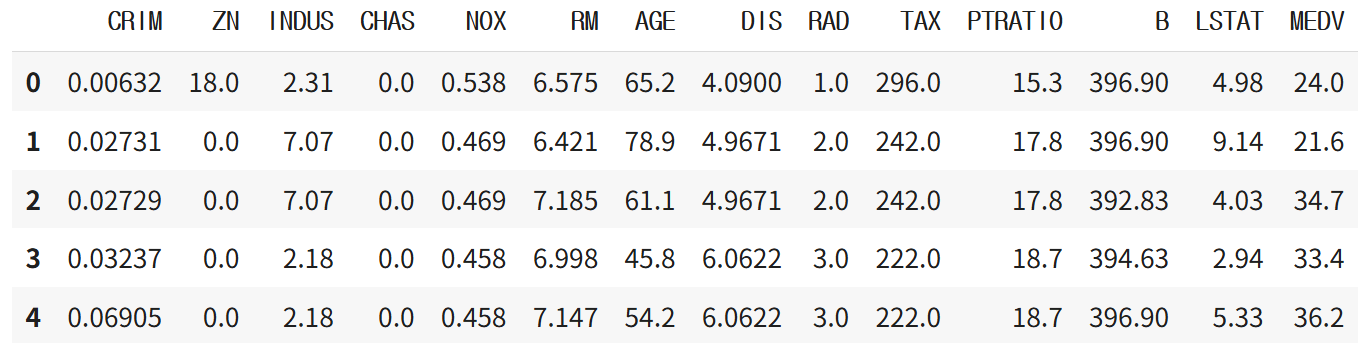
Correlation 분석
cor=df.corr()
plt.figure(figsize=(10,10))
sns.heatmap(cor,annot=True,cmap=plt.cm.Blues)
plt.show()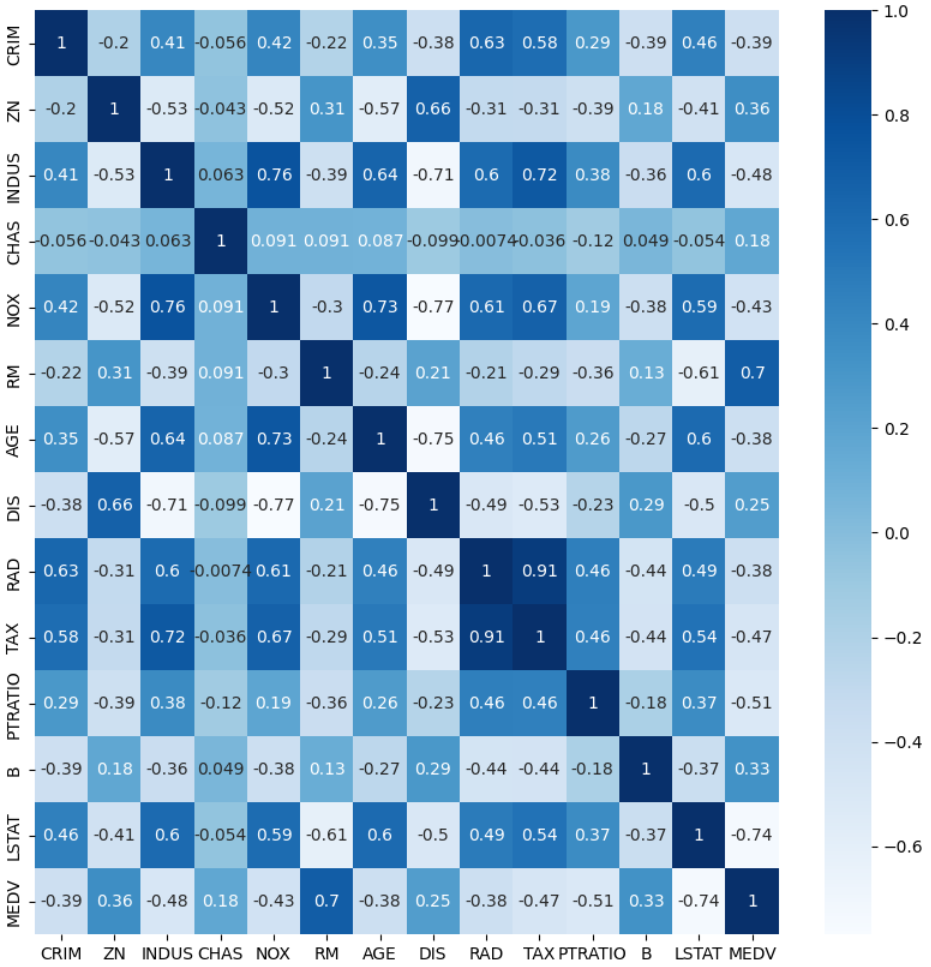
feature Selection
target이 되는 기준 변수를 선택한 후,
특정 상관계수를 넘어가는 feature들만 선택
cor_target=abs(cor['MEDV']) #기준 변수 선택
selected_cols=cor_target[cor_target>0.6] #임계값 설정
print(selected_cols)
boston_sel=df[selected_cols.index]
boston_sel.head()
5. Mutual Information 실습
: 유방암 data set으로 Top10 feature 선택
데이터 로드
from sklearn.datasets import load_breast_cancer
data=load_breast_cancer()
X=data.data
y=data.targetMutual Information 계산 및 feature Selection
from sklearn.feature_selection import mutual_info_classif, SelectKBest
#상호 정보량 계산
mi=mutual_info_classif(X,y)
#k개의 feature 선택
selector=SelectKBest(mutual_info_classif,k=10)
X_new=selector.fit_transform(X,y)
#상호 정보량이 가장 높은 Top 10 feature 출력
topk_indices=mi.argsort()[::-1][:10]
topk_features=data.feature_names[topk_indices]
print("Top 10 features based on mutual information:")
print(topk_features)
6. RFE 실습 1
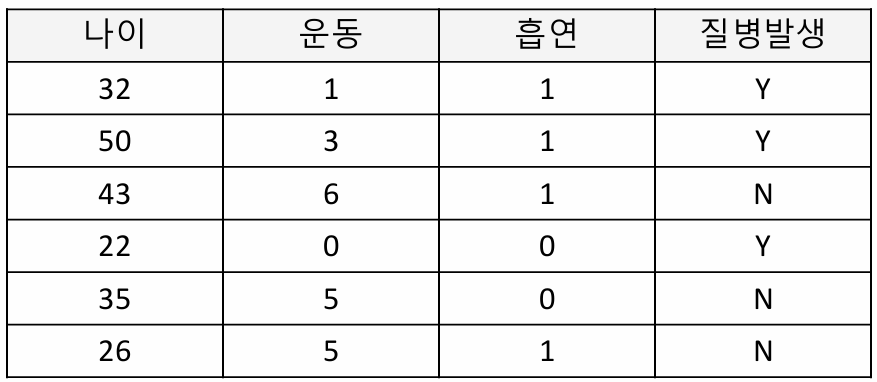
: model은 logistic regression / 성능지표는 Accuracy 기준
데이터 로드
model=LogisticRegression().fit(data[:,[1]], label)
print(f'예측값 : { model.predict(data[:, [1]])}')
print(f'실제값 : {label}')import numpy as np
from sklearn.linear_model import LogisticRegression
data = [[32, 1, 1],
[50, 3, 1],
[43, 6, 1],
[22, 0, 0],
[35, 5, 0],
[26, 5, 1]]
data = np.array(data)
label = [1,1,0,1,0,0]모델 정의 및 학습
model=LogisticRegression().fit(data,label)
model1=LogisticRegression().fit(data[:,[1,2]],label) #나이 feature 제거
model2=LogisticRegression().fit(data[:,[0,2]],label) #운동 feature 제거
model3=LogisticRegression().fit(data[:,[0,1]],label) #흡연 feature 제거중요 feature로만 학습한 모델 성능 확인
model=LogisticRegression().fit(data[:,[1]], label)
print(f'예측값 : { model.predict(data[:, [1]])}')
print(f'실제값 : {label}')
7. RFE 실습 2
: 유방암 data set에서 중요도를 기반으로 10개의 feature를 선택
데이터 로드
from sklearn.datasets import load_breast_cancer
data=load_breast_cancer()
X=data.data
y=data.target모델 정의 및 학습
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model=LogisticRegression()
rfe=RFE(model,n_features_to_select=10) #10개의 특성을 선택하는 과정
rfe.fit(X,y)
print(rfe.get_support())중요 feature 출력
selected_features=X[:,rfe.get_support()]
feature_names=data.feature_names[rfe.get_support()]
print(f'Selected features : {feature_names}')
