1. Ensemble Learning 개요
여러 개의 예측 모델을 조합하여, 강력하고 안정적인 예측 모델을 생성하는 기법
(각기 다른 모델을 사용하기도, 동일 모델을 사용하기도 함)
Ensemble Learning의 목적
: 편향과 분산을 줄이고 일반화 성능을 향상
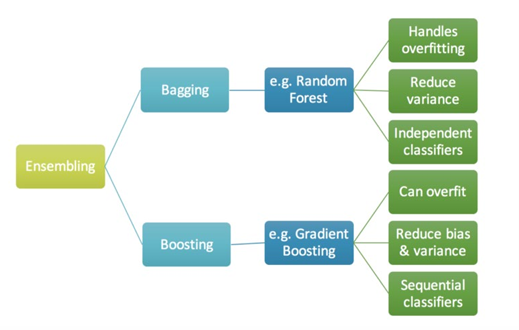
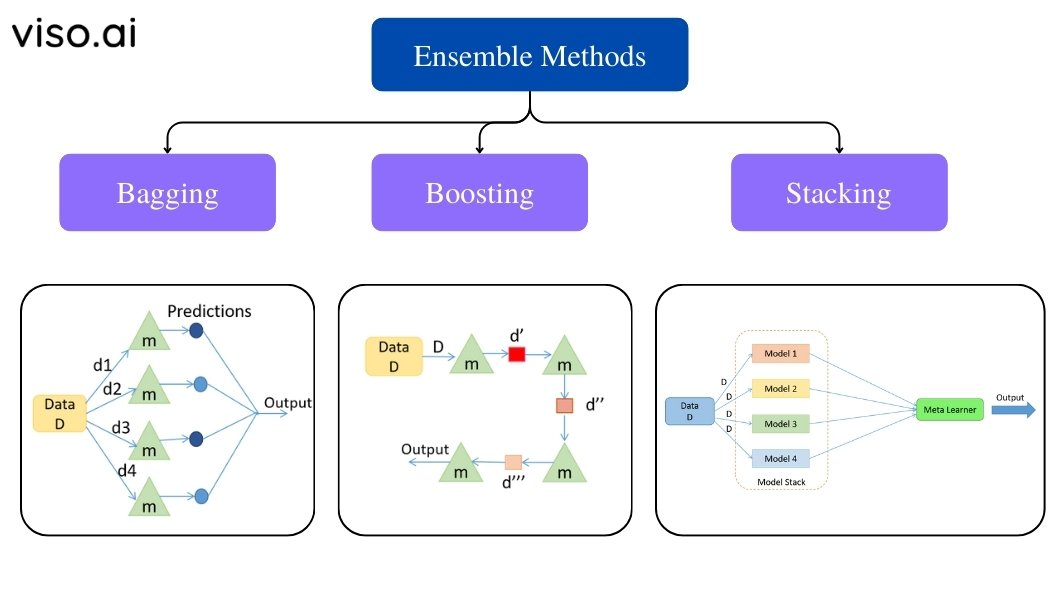
Ensemble Learning의 종류
- Voting
- Bagging
- Boosting
장점
- 예측 성능 향상 : 다양한 모델들의 예측 결과를 결합하기에, 편향과 분산을 줄이고 일반화 성능을 향상
- 안정성 : 오류나 노이즈에 덜 민감하여, 안정적인 결과 얻음
- 모델의 다양성 : 다양한 종류의 모델을 사용하거나, 동일한 알고리즘을 사용하더라도 다른 하이퍼 파라미터 설정 또는 다른 데이터로 학습
단점
- 높은 계산 비용 : 모델의 수가 많아질 수록 학습 시간, 메모리 사용량 증가
- 해석의 어려움 : 다양한 모델을 결합하기에, 개별 모델에 대한 해석 어려움
- 데이터 불균형 문제 : 일부 모델이 학습 데이터를 무작위로 샘플링 or 가중치를 부여하는 경우가 있어, 불균형 혹은 overfitting 문제 야기
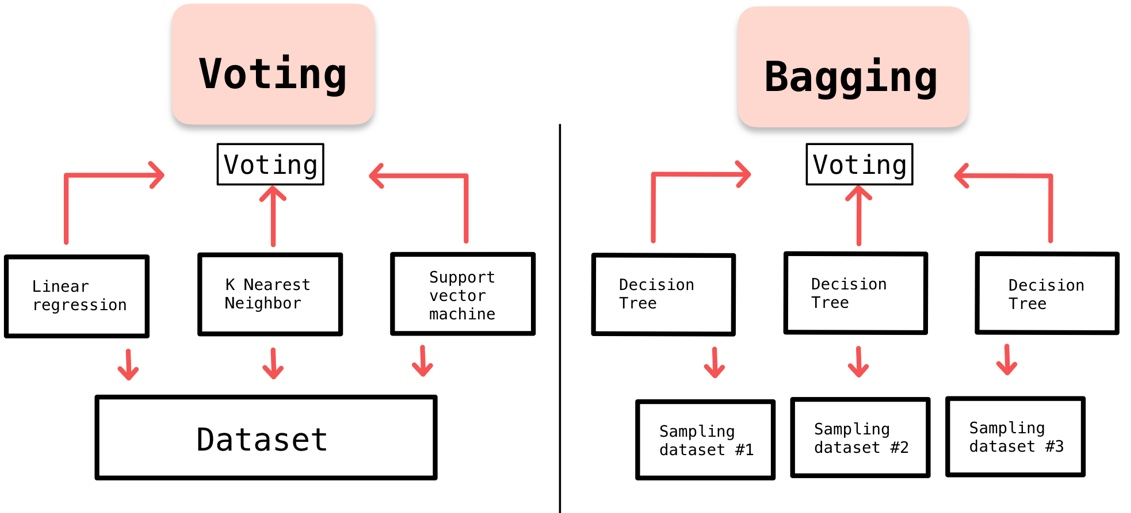
2. Voting
다양한 예측 모델들의 결과에 대해 투표하여 최종 예측을 수행하는 방법
- 예측 성능 향상 : 모델들 사이의 오류를 상쇄
- 일반화 성능 향상 : 다양한 모델들의 결합
- overfitting 방지
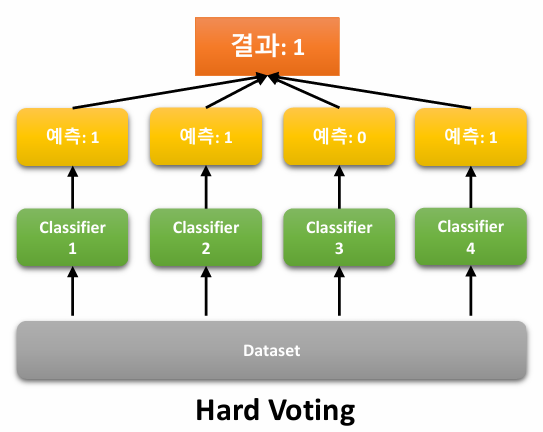
Hard Voting
각 model의 예측 결과 중 가장 많이 예측된 class를 최종 예측으로 선택하는 방식
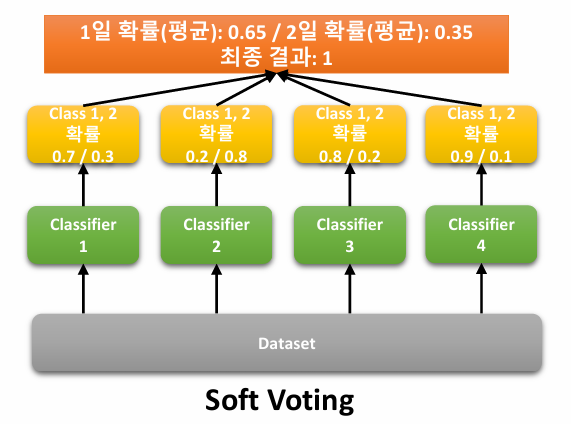
Soft Voting
각 model의 예측 결과에 대한 확률 값을 평균하여 최종 예측을 수행하는 방식
(일반적으로 hard voting보다 soft voting이 성능 더 좋음)
Voting 실습
라이브러리
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoredata set 불러오기
cancer=load_breast_cancer()
#데이터 나누기
X_train, X_test, y_train, y_test= train_test_split(cancer.data, cancer.target, test_size=0.2)모델 불러오기 및 학습
logistic_regression=LogisticRegression()
knn=KNeighborsClassifier(n_neighbors=8)
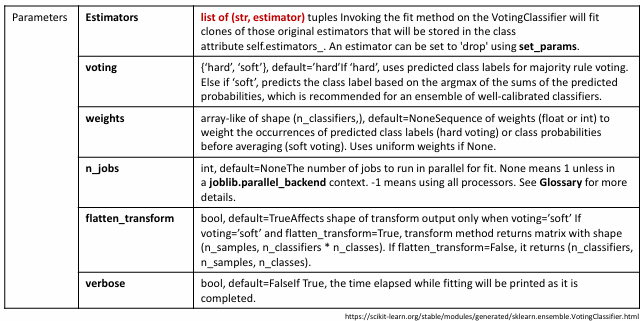
voting_model=VotingClassifier(estimators=[('LogisticRegression', logistic_regression), ('KNN', knn)], voting='soft')
voting_model.fit(X_train, y_train)
Voting model 성능 확인
pred=voting_model.predict(X_test)
print(f'Accuracy : {accuracy_score(y_test,pred)}')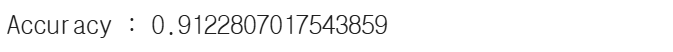
classifiers = [logistic_regression, knn]
for classifier in classifiers:
classifier.fit(X_train, y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print(f'{class_name} : {accuracy_score(y_test, pred)}')
3. Bagging
: Bootstrap Aggregating 중 하나인 Random Forest에 대해서만 다룸
Bootstrap을 이용하여 주어진 data set을 Resampling 하고, 여러 학습 모델을 훈련 시킨 뒤 결과를 voting 하는 방법
(기존 voting과 달리, 동일한 알고리즘으로 여러 분류기를 만든 후 voting)
- Random Sampling과 앙상블 방법을 통해 분산을 줄이고, 일반화 성능을 향상
장점
- 분산 감소 : 여러 개의 모델을 학습하고, 결합함으로서 모델의 분산 줄임
- overfitting 방지 : 다른 데이터 부분집합을 사용하기에, 과적합을 감소시키고 일반화 성능 향상
- 예측 성능 향상 : 다수의 모델을 결합하여 예측 결과를 조합
Random Forest
Bagging model 중 하나로, 여러 개의 Decision Tree를 생성하고
각 Tree의 예측 결과를 조합하여 최종 결과를 예측하는 방식
Random Forest Algorithm
Step1. Bootstrap Sampling : 원본 데이터에서 중복을 허용하여 임의로 샘플링
Step2. 랜덤 특성 선택 및 모델 학습 : 각 Decision Tree의 특성을 랜덤하게 하여 각 트리 모델 간 상관관계를 줄이고, 다양성을 높여 학습
Step3. 앙상블 예측 : 모든 Tree의 예측 결과를 조합하여 최종 결과 예측
장점
- 결정 트리의 쉽고, 직관적인 장점을 그대로 가짐
- 앙상블 알고리즘 중 비교적 빠름
- 다양한 분야에서 좋은 성능을 가짐
단점
- 하이퍼 파라미터가 많아서 튜닝을 위한 시간이 많이 소요됨
Random Forest 실습
Voting vs Bagging
4. Boosting
: AdaBoost / Gradient Boosting / XGBoost / LightGBM
약한 모델(Weak Model)을 여러 개 결합하여, 강한 모델(Strong Model)을 만드는 방법
(학습 데이터에서 잘못 예측된 샘플에 집중하여 반복적으로 학습)
- 각각의 약한 모델이 상호보완하도록 함
Boosting 알고리즘 종류
- AdaBoost
- Gradient Boosting
- XGBoost
- LightGBM
AdaBoost
오분류된 Sample에 집중하여 학습하는 방식
(한 개의 약한 모델은 성능이 낮지만, 여러 개의 약한 모델을 순차적으로 학습시키면서 잘못 분류된 샘플에 더 집중하도록)
- 이전 학습기의 오류를 보완
- 이를 통해 성능 개선, 예측력 향상
- 약한 학습기의 중요도를 기반으로 모델의 예측 설명력 제공 가능
- 분류 문제에 주로 사용
- data set의 불균형 문제를 다루는데 효과적
장점
- overfitting의 영향 덜 받음
- 구현이 쉬움
단점
- 이상치에 민감
- 해석의 어려움
- 계산 복잡성
- 하이퍼 파라메터 설정 필요
AdaBoost Algorithm

Step1. 초기화 : 모든 샘플에 동일한 가중치 할당
Step2. 약한 모델 학습
1) 약한 분류기 학습
2) 분류기 중요도 계산
3) 샘플 가중치 업데이트
4) 가중치 정규화
Step3. 데이터 Resampling 및 약한 모델 학습 : 순차적으로 약한 모델 학습
Step4. 최종 예측 : 모든 약한 학습기의 예측 결과를 결합
AdaBoost Example
Gradient Boost(GBM)
이전 학습기의 오차를 보완하여 모델을 강화하는 방식
- 이전 학습기의 예측 오차에 집중하여 학습
- 예측 성능이 높고, 다양한 유형의 데이터에 적용 가능
- 다양한 약한 학습기 사용 가능
장점
- 구현이 쉬움
- 높은 정확도
- 모델의 유연함
단점
- overfitting 문제
- 메모리 문제
Gradient Boost Algorithm

Step1. Create First Leaf (초기 모델 생성)
Step2. Calculate Pseudo Residual (잔차 계산)
Step3. 잔차를 예측하는 모델 학습
Step4. Update, Prediction
Gradient Boost Example
Learning rate
overfitting의 가능성이 크기에, 실제 값에 조금씩 가까워지는 방향으로 학습 필요
Gradient Boost 실습
XGBoost
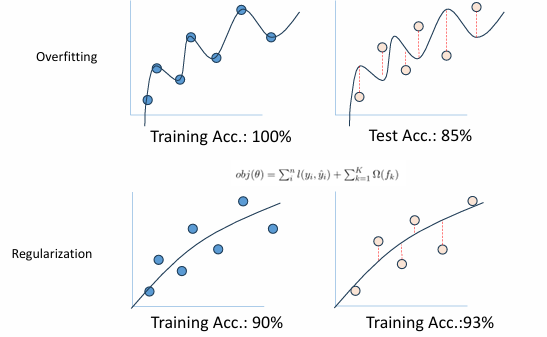
Extreme Gradient Boost의 약자로, 기존 GBM의 overfitting 문제를 해결하기 위한 기법이 추가된 방식
- 기본 학습기는 Decision Tree / Residual을 이용한 약점을 보완하는 방식으로 학습
- overfitting 방지를 위한 추가 parameter 존재
Regularization
: 모델의 복잡성을 제어하여, 과적합 방지
XGBoost Algorithm
Step1. 초기 모델 설정
Step2. 분기 기준 찾기 : 각 Root/Leaf에 대해 Similarity Score 계산
Step3. 분기 실행 : Gain 계산 및 가장 큰 값으로 분기
XGBoost Example
XGBoost 실습
Bagging vs Boosting