
1. Voting Classifier 실습
: VotingClassifier을 이용하여 iris data set 분석
다양한 모델 조합(선형+비선형)일 수록 일반화 성능이 높아짐
Hard Voting은 단순하지만 빠름
Soft Voting은 성능 좋을 수 있으나, 개별 모델이 확률 값을 지원할 때만 사용 가능
데이터 로드
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X,y=load_iris(return_X_y=True)
X_train, X_test, y_train, y_test=train_test_split(
X,y, test_size=0.3, random_state=42, shuffle=True)개별 분류기 정의
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
clf1=LogisticRegression()
clf2=DecisionTreeClassifier()
clf3=KNeighborsClassifier()VotingClassifier 정의 및 학습
from sklearn.ensemble import VotingClassifier
voting_clf=VotingClassifier(
estimators=[('lr',clf1),('dt',clf2),('knn',clf3)],
voting='hard'
)
voting_clf.fit(X_train,y_train)
y_pred=voting_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(f'VotingClassifier Accuracy : {accuracy_score(y_test,y_pred)}')
각 모델의 학습 결과 출력
from sklearn.ensemble import VotingClassifier
voting_clf=VotingClassifier(
estimators=[('lr',clf1),('dt',clf2),('knn',clf3)],
voting='hard'
)
voting_clf.fit(X_train,y_train)
y_pred=voting_clf.predict(X_test)
from sklearn.metrics import accuracy_score
print(f'VotingClassifier Accuracy : {accuracy_score(y_test,y_pred)}')
2. Random Forest 실습
: RandomForestClassifier을 이용하여 유방암 data set 분석
데이터 로드
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset=load_breast_cancer()
X=dataset.data
y=dataset.target
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3)모델 학습 및 예측
from sklearn.ensemble import RandomForestClassifier
rf=RandomForestClassifier()
rf.fit(X_train, y_train)
rf.score(X_test, y_test)
Feature 중요도 출력
importances_values=rf.feature_importances_
print(dataset.feature_names)
print(importances_values)
결과 시각화
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
ftr_importances=pd.Series(importances_values, index=dataset.feature_names)
ftr_top20=ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Top 20 Feature importances')
sns.barplot(x=ftr_top20, y=np.squeeze(ftr_top20.index.to_list()))
plt.show()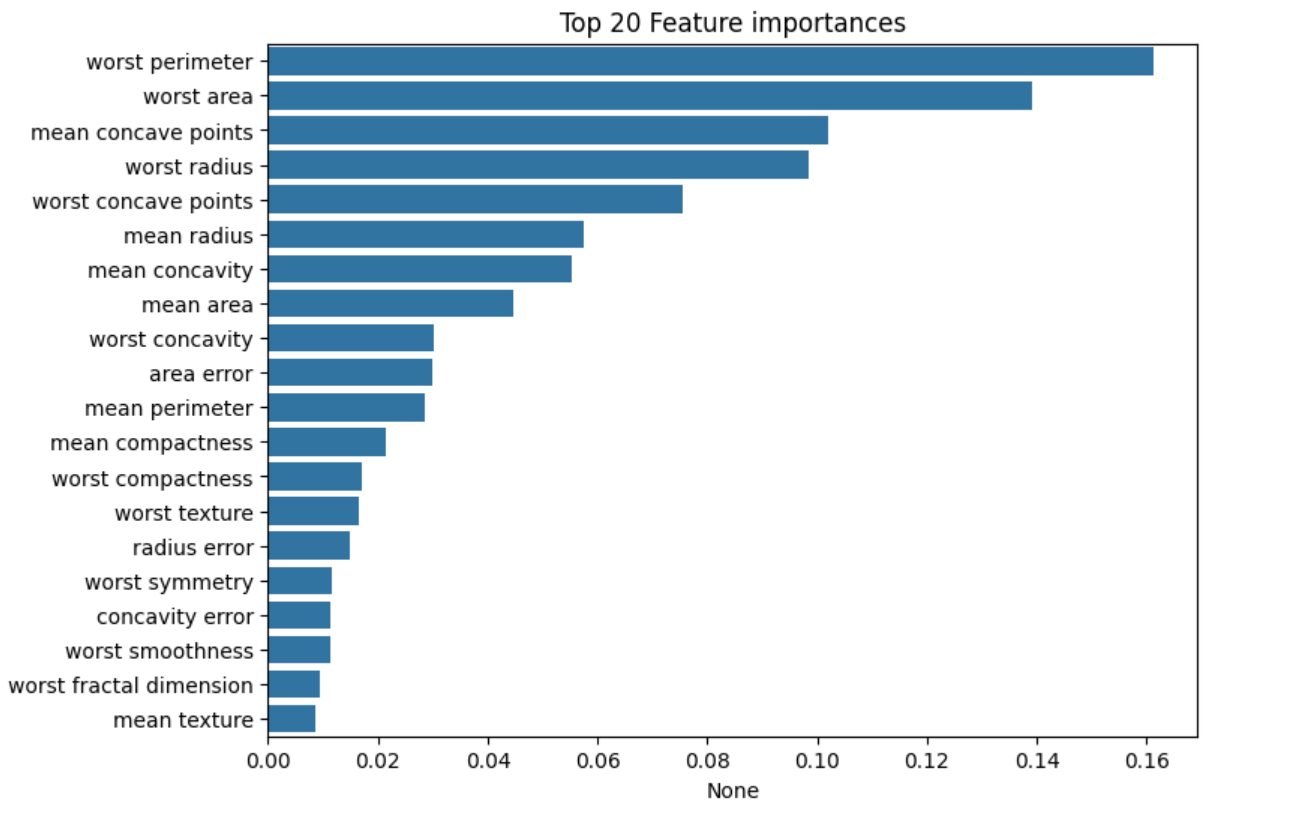
3. Gradient Boost 실습
: Gradient Boost를 이용하여 유방암 data set(5:5로 나누기)을 분석
데이터 로드
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
df=load_breast_cancer()
X=df.data
y=df.target
X_train, X_test, y_train, y_test=train_test_split(X,y, test_size=0.5, random_state=2)모델 학습 및 예측
clf=GradientBoostingClassifier(n_estimators=20, learning_rate=0.5, max_depth=8, random_state=2)
clf.fit(X_train, y_train)
print(f'정확도 : {np.mean(y_test == clf.predict(X_test))}')
결과 시각화
import matplotlib.pyplot as plt
import seaborn as sns
ftr_importances_values = clf.feature_importances_
ftr_importances=pd.Series(ftr_importances_values,
index=df.feature_names)
ftr_top20=ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Top 20 Feature Importances')
sns.barplot(x=ftr_top20, y=np.squeeze(ftr_top20.index.to_list()))
plt.show()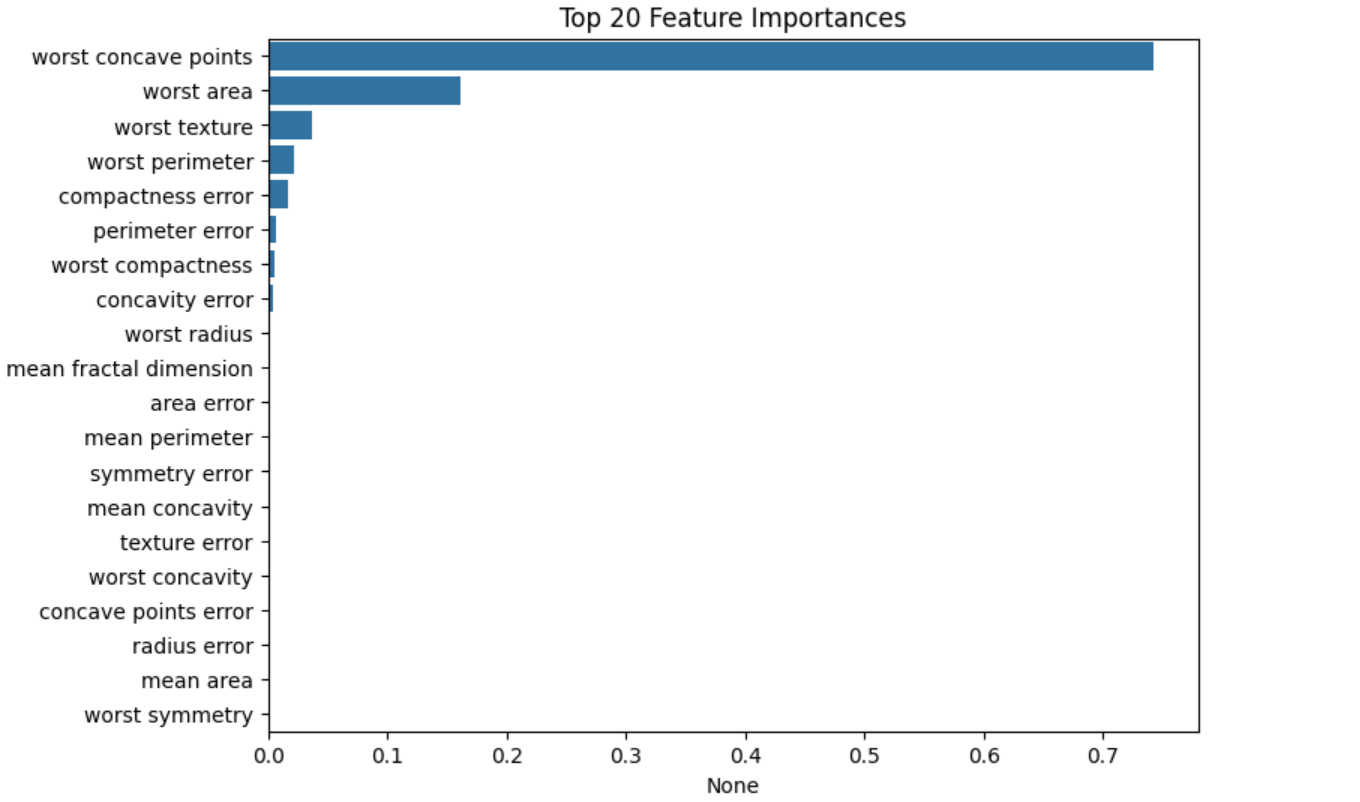
4. XGBoost 실습
: XGBoost를 이용하여 유방암 data set을 분석
데이터 로드
pip install xgboostfrom sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
from xgboost import XGBClassifier
df=load_breast_cancer()
X=df.data
y=df.target
X_train, X_test, y_train, y_test=train_test_split(X,y, test_size=0.2, random_state=42)모델 학습 및 평가
model=XGBClassifier()
model.fit(X_train, y_train)
pred=model.predict(X_test)
accuracy=accuracy_score(y_test, pred)
print(f'정확도 : {accuracy}')
결과 시각화
import matplotlib.pyplot as plt
import seaborn as sns
ftr_importances_values=model.feature_importances_
ftr_importances=pd.Series(ftr_importances_values,index=df.feature_names)
ftr_top20=ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Top 20 Feature Importances')
sns.barplot(x=ftr_top20,y=np.squeeze(ftr_top20.index.to_list()))
plt.show()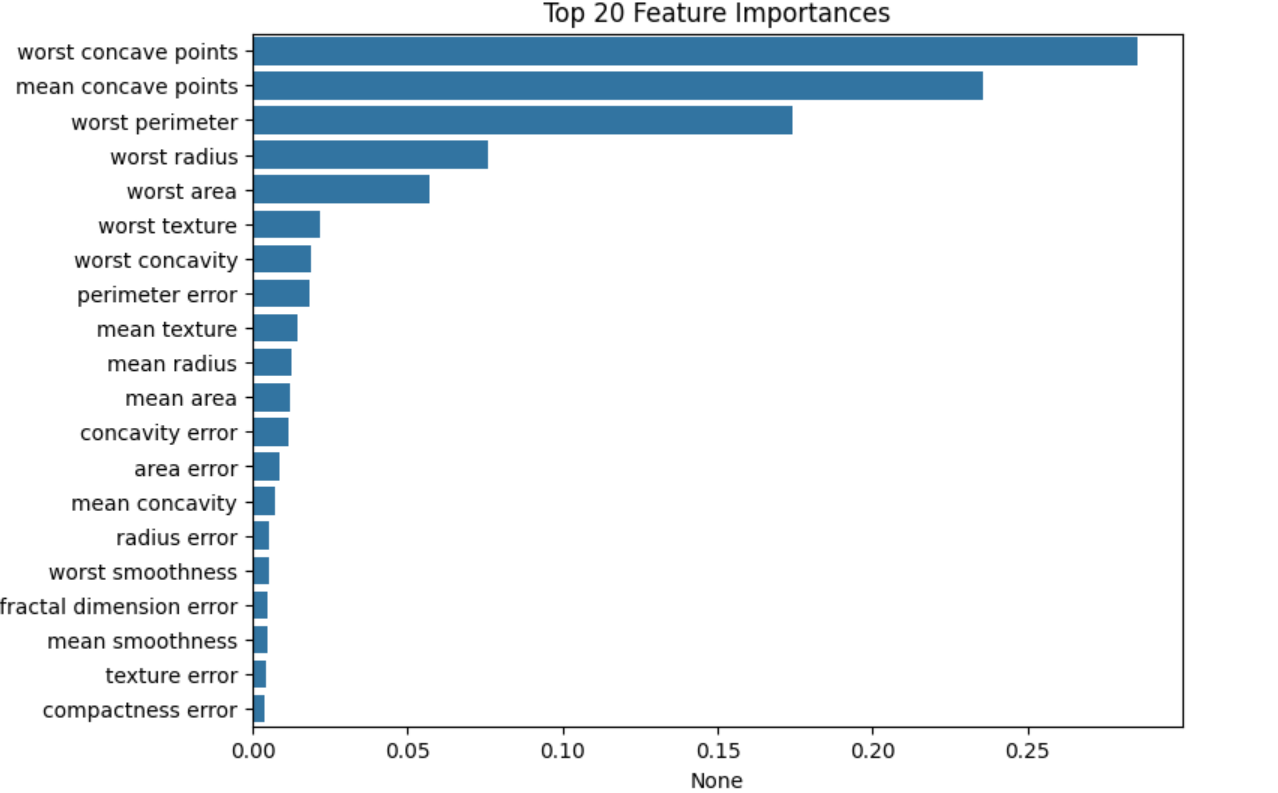
5. GridSearchCV
앞의 model들은 적절한 하이퍼 파라미터를 수동으로 찾는 것이 어려움
-> 자동으로 하이퍼 파라미터를 대입하면서 최적의 조합을 찾기
GridSearchCV
: 모델 성능을 높이기 위해 하이퍼 파라미터의 조합을 탐색하는 방법
교차 검증
모델의 성능을 더 정확하게 평가하기 위해, 훈련 데이터를 여러 개의 부분으로 나누어 여러 번 평가하는 방법
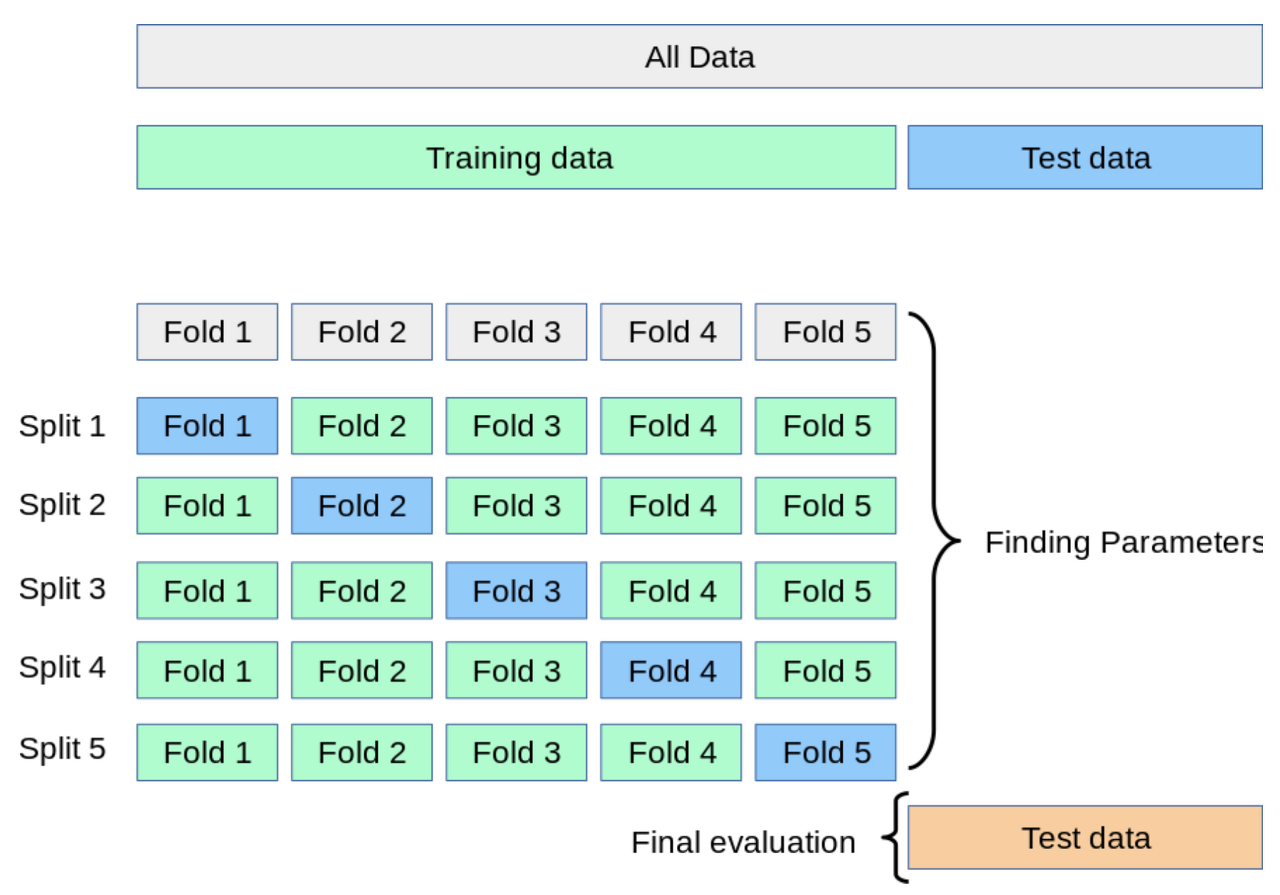
교차 검증의 필요성
- 과대평가 : test data가 운 좋게 쉬운 data일 수 있음
- 일반화 어려움 : 데이터가 작을 때, 훈련에 쓸 수 있는 data도 부족해짐
- 모델의 일반화 성능 측정 필요 : 다양한 데이터 조합으로 test 필요
동작 방식
- 전체 데이터를 K개의 fold로 나눔
- 하나의 fold를 검증용 데이터로 사용
- 나머지는 훈련용으로 사용
- K번 돌아가면서 성능평가 후 평균값을 최종 점수로 사용
6. GridSearchCV 실습
데이터 로드
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
df=load_breast_cancer()
X=df.data
y=df.target
X_train, X_test, y_train, y_test=train_test_split(X,y, test_size=0.2, random_state=42)하이퍼 파라미터 범위 설정
param_grid={
'n_estimators' : [50, 100],
'max_depth' : [3,5, None],
}GridSearchCV 실행
grid=GridSearchCV(RandomForestClassifier(), param_grid, cv=5, scoring='accuracy')
grid.fit(X_train, y_train)
print(f'최적 Parameters : {grid.best_params_}')
print(f'검증 정확도 : {grid.best_score_}')
print(f'테스트 정확도 : {grid.score(X_test, y_test)}')

안녕하세요 :)