[Paper Review] Convolutional Neural Networks for Sentence Classification
논문명: Convolutional Neural Networks for Sentence Classification
Introduction
- 딥러닝 모델은 컴퓨터 비전 / 음성 인식 등에서 탁월한 성능을 보임
- NLP에서는 Neural language model을 통해 언어를 word vector로 표현하여 분석하는 경우가 대부분임
- 이러한 dense representation에서 의미 면에서 가까운 단어들은 코사인 거리 (벡터 간의 각도 비교)나 유클리디안 거리 (벡터 간의 거리 비교) 또한 가깝게 나타남
- 본 논문은 한 개의 층만을 사용하는 simple CNN 모델에서 Mikolov가 Google news에서 비지도 신경망 학습(word2vec)을 통해 추출한 word vector (universal feature)를 활용하면 적은 양의 하이퍼 파라미터 튜닝으로도 다양한 task들에서 탁월한 자연어 분류 성능을 낼 수 있다고 주장함.
- Pre-trained vector는 universal하기 때문에 task-specific vector들에서도 채널 수를 늘림으로써 좋은 성능을 낼 수 있음
Model
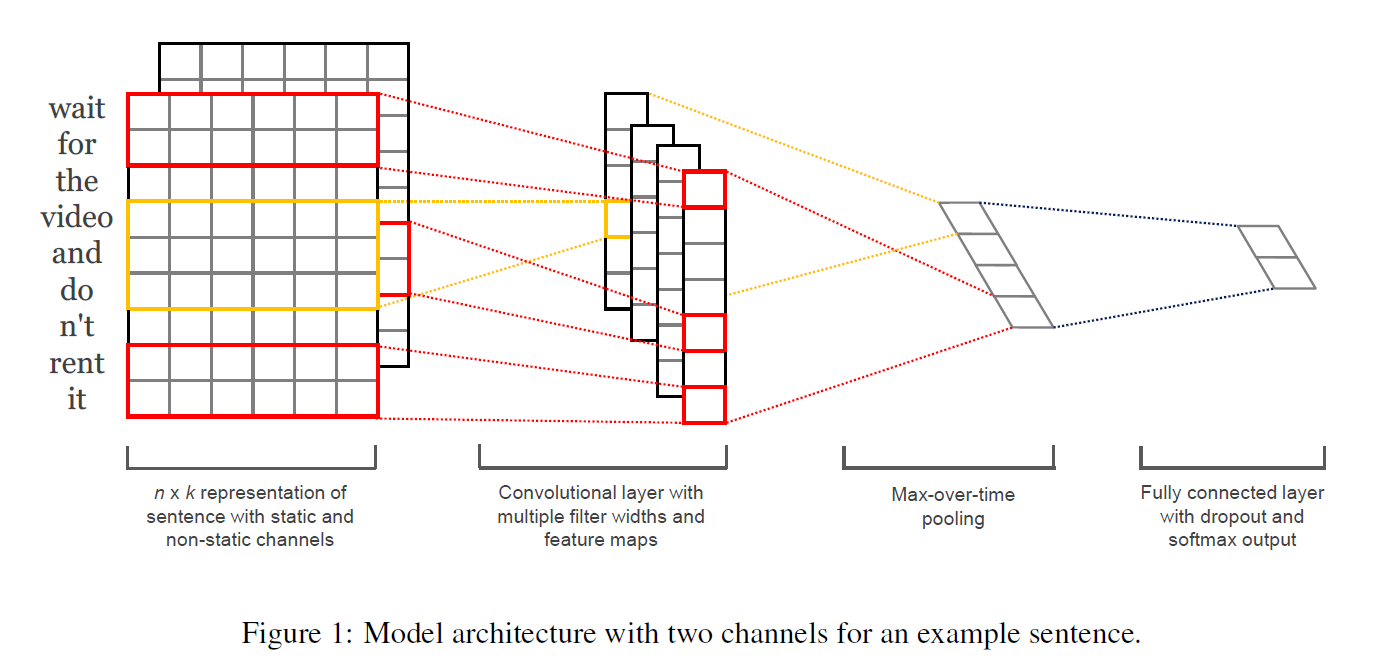
- k = word vector의 차원 수
- n = 문장의 길이 (필요할 경우 padding 처리)
- xi = k-dimensional word vector
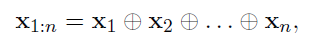
- 표시는 concatenation operator ⇒ word vector들을 concat하여 만든 문장에 convolution을 적용하는 것
- 필터 w은 h * k 벡터의 모양을 띄고 있으며, h개의 단어에 적용되어 새로운 feature를 뽑아냄
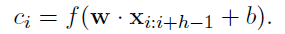
- 위 ci는 개별 feature의 도출 공식
- b는 편향, f는 비선형 함수 / x(i:i+h-1)는 w 필터가 적용되는 h개의 단어들을 의미함
- 1번째 단어부터 h번째 단어 / 2번째 단어부터 h+1번째 단어 / ….. / n-h+1번째 단어부터 n번째 단어까지 각각의 h의 길이를 가진 문장들에 filter가 적용되어 feature map을 생성하게 됨
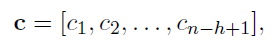
- 이렇게 생성된 feature map에서 max-over-time pooling을 통해 feature map의 특징을 가장 잘 나타내고 가치가 높은 최대 feature 값을 도출함.
⇒ 결과적으로 이렇게 도출된 하나의 feature는 하나의 filter를 대표하는 값이 됨.
-
해당 모델은 여러 개의 filter를 활용함. 이 필터들에서 추출한 feature들은 penultimate layer를 구성하고, 이를 fully connected softmax layer에 통과시켜 레이블에 대한 확률 분포를 만들어냄
-
이 논문에서는 두 개의 word vector 채널을 활용하여 실험을 수행함. (multichannel architecture)
- 1) static vector 채널
- 2) backpropagation를 통해 fine-tuned된 채널 (non-static vector)
- 각각의 필터들에 두 개의 채널을 동시에 통과시켜 결괏값을 2개 구하고, 이를 서로 더해서 feature를 구함
Regularization
- 정규화 작업 ⇒ dropout을 penultimate layer에 적용
- dropout ⇒ 마스킹 벡터 r (베르누이 확률분포에 따라 랜덤으로 0과 1을 요소로 갖는 벡터)를 penultimate layer에 곱하여, r의 0과 곱해진 penultimate layer의 feature들은 제거되도록 조정함
- Gradients 값은 역전파 과정에서 unmasked된 unit들에 의해서만 업데이트됨
- 추가로 l2 정규화의 경우, 경사 하강 단계에서 가중치가 s보다 커지면 가중치가 s값을 가지도록 조정한다.
Datasets and Experimental Setup
| MR | 리뷰 당 하나의 문장으로 된 영화 리뷰 |
|---|---|
| SST-1 | Stanford Sentiment Treebank (세분화된 label) |
| SST-2 | Stanford Sentiment Treebank (Binary label) |
| Subj | 주관성 데이터셋 |
| TREC | TREC 질문 데이터셋 |
| CR | 소비자 리뷰 데이터셋 |
| MPQA | 오피니언 긍정/부정 데이터셋 |
Hyperparameters and Training
- ReLU 함수 (입력값이 음수면 0, 양수면 그대로 출력)
- 100개의 feature map을 가진 3,4,5 크기의 filter
- dropout 비율 = 0.5
- l2 constrain = 3
- 미니 배치 크기 = 50
- 위 파라미터들은 SST-2의 개발 세트를 기반으로 한 파라미터 튜닝을 통해 도출하였으며, 이 과정에서 early stopping을 사용한 것 외에는 별도의 튜닝 작업을 하진 않음.
- 보편적인 개발 세트가 없는 데이터셋의 경우, 훈련 세트 중 무작위로 10%의 데이터를 추출하여 개발 세트로 사용함
- 학습 과정에는 SGD 기법 + 파라미터 업데이트는 Adadelta를 사용함
Pre-trained Word Vectors
- 구글 뉴스 데이터셋을 word2vec(CBOW)을 통해 사전 학습한 임베딩 벡터를 사용함
- 사전 학습 단어에 포함되지 않은 단어는 임의로 값을 초기화시켜 사용함
Model Variations
| CNN-rand | 모든 단어 벡터 값을 임의로 초기화한 뒤, 학습 과정에서 값을 조정한 baseline model |
|---|---|
| CNN-static | word2vec으로 사전 학습된 단어 벡터를 사용한 모델. 사전 학습이 안된 단어들을 포함한 모든 단어들은 고정되어 있으며, 다른 파라미터들만 학습된다. |
| CNN-non-static | 위 모델과 유사하지만, 각 task에서 벡터값이 업데이트된다. |
| CNN-multichannel | 이 모델에서는 임베딩 벡터들을 두 개의 channel로 나누고, 각각의 channel을 input으로 삼아 filter를 적용하는 방식으로 학습을 진행한다. 그러나 역전파 과정에서 하나는 static하게 값이 그대로이고, 다른 하나는 값이 계속 업데이트된다. 즉, static과 non-static의 방법론을 섞어서 사용한 것으로 볼 수 있다. |
4개의 모델의 차이점을 비교하기 위해 상기한 차이점들을 제외한 나머지 요소(CV-fold assignment, initionalization of unknown word vectors, initialization of CNN parameters)들은 모두 균일하게 유지함.
Results and Discussion
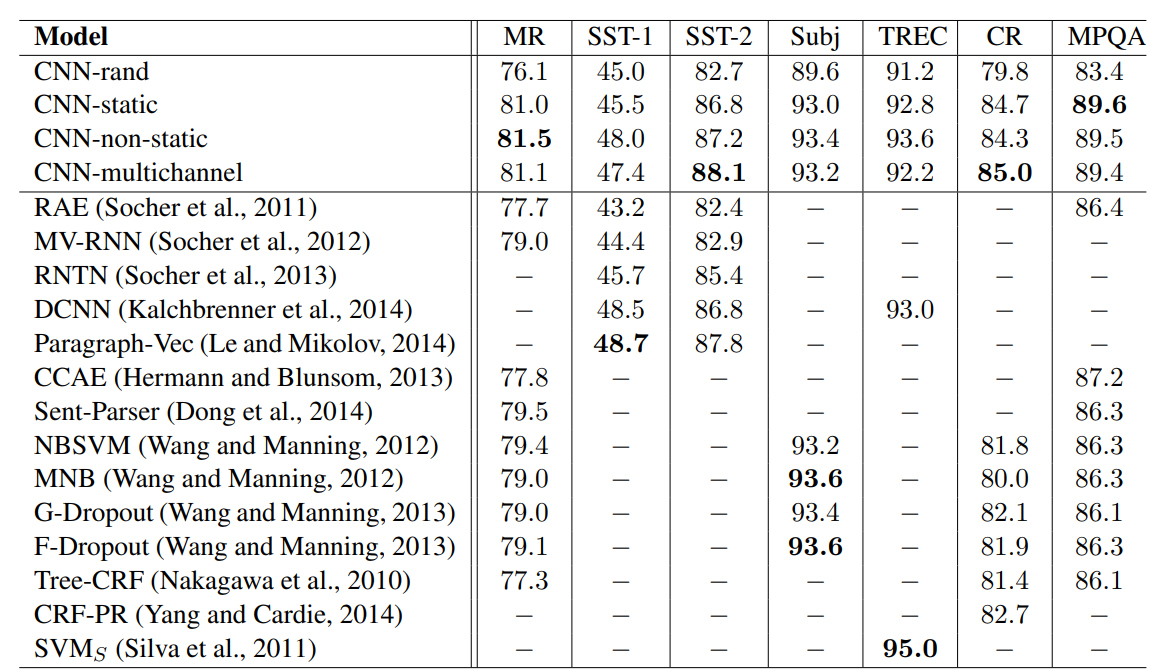
- baseline model (CNN-rand)는 성능이 그리 좋지 못함을 알 수 있음.
- 그러나 static vector만을 이용한 간단한 CNN 모델조차도 예측치를 크게 상회하는 훌륭한 성능을 보임
- 함의
- ‘universal’한 feature extractors는 다양한 데이터셋에서 활용될 수 있다.
- 학습 과정에서 임베딩 벡터를 fine-tuning하는 CNN-non-static 모델의 경우, 보다 좋은 성능을 낼 수 있다.
Multichannel vs. Single Channel Models
- multichannel 아키텍처가 과대적합을 방지하여 모델 성능을 높일 것으로 기대됨.
- 그러나, single channel 모델과 비교했을 때 큰 성능 차이를 보이지 않음. (mixed)
Static vs. Non-static representations
- single non-static 모델과 마찬가지로 multichannel 모델은 임베딩 벡터에 fine-tuning하는 과정을 거쳐 단어의 의미를 더 정확하게 만들 수 있음.
- 예를 들어, "good"와 "bad"는 word2vec에서는 일반적으로 유사한 단어로 여겨지지만, fine-tuned된 모델에서는 이와 다른 결과를 보여줌. ("good"은 감정 표현의 측면에서 "nice"보다 "great"와 더 가깝게 표현됨.)
- 사전에 등장하지 않아 무작위로 초기화된 단어들도 fine-tuning을 통해 의미 있는 표현을 학습하게 .
Further Observations
- Kalchbrenner 등(2014)의 유사 아키텍처를 사용한 CNN은 본 연구의 모델과 비교했을 때 더 적은 filter width와 feature map을 사용했기 때문에 성능이 비교적 안 좋게 나온 것으로 예상됨.
- Dropout은 간단하고 효과적인 정규화 도구로, 일관된 성능 향상을 보여줌.
- Word2Vec에 없는 단어를 무작위로 초기화할 때, 적절한 분산을 유지하도록 차원마다 U[−a, a]에서 샘플링하여 성능을 개선할 수 있었음. 만일 pre-trained vectors의 분산을 완벽히 재현할 수 있다면 더 많은 성능 개선을 이룰 수 있을 것으로 기대됨.
- Collobert 등(2011)의 연구에서는 Wikipedia에서 훈련한 단어 벡터와 비교했을 때 Word2Vec이 우수한 성능을 보였으며, 이 같은 결과가 Mikolov 등(2013)의 아키텍처나 Google News 데이터셋과 관련이 있는지는 알려지지 않았음.
- Adadelta(Zeiler, 2012)는 Adagrad(Duchi 등, 2011)와 유사한 결과를 보이지만 더 적은 epoch를 필요로 함.
Conclusion
- 하이퍼 파라미터 튜닝을 거의 거치지 않은 간단한 layer 1개짜리 CNN 모델로도 NLP task에서 훌륭한 성능을 낼 수 있음.
- 단어 벡터의 비지도 사전 학습을 잘 이용하면 NLP에 필요한 딥러닝 과정에서 여러 모로 활용해볼 수 있을 것.

개발자 지망생