github link: https://github.com/Shawn1993/cnn-text-classification-pytorch
본 코드는 CNN 모델을 활용한 text classification의 방법론을 제시한 지난 논문의 내용을 직접 pytorch로 구현한 코드이다. 이 글에서는 해당 코드에 대해 모듈 별로 어떤 기능을 하고 있는지, 또 전반적인 코드가 논문의 주요 포인트들을 어떻게 구현하고 있는지에 대해 집중적으로 탐구해볼 예정이다.
| 파일명 | 설명 |
|---|---|
| mydatasets | 모델 학습 및 테스트에 필요한 데이터셋 구축 |
| model | CNN 모델 구현 |
| train | 학습 및 예측 과정 구현 |
| main | 메인 코드 |
mydatasets
import re
import os
import random
import tarfile
import urllib
from torchtext import data사용된 주요 라이브러리들이다. 텍스트 데이터 처리를 위한 torchtext.data와 데이터 전처리를 위한 re 등을 import하고 있다.
TarDataset(data.Dataset)
class TarDataset(data.Dataset):data.Dataset 클래스는 데이터셋을 다루는 데 필요한 메소드와 속성을 이미 갖고 있기 때문에 이를 상속하는 하위 클래스에서는 __init__ 메서드를 정의하지 않아도 사용할 수 있다. 즉, 해당 클래스에서는 클래스 메서드인 download_or_unzip을 호출하여 데이터를 준비하고, 그 후에는 data.Dataset 클래스의 기능을 활용하여 데이터를 다루면 된다.
download_or_unzip
@classmethod
def download_or_unzip(cls, root):
path = os.path.join(root, cls.dirname)
if not os.path.isdir(path):
tpath = os.path.join(root, cls.filename)
if not os.path.isfile(tpath):
print('downloading')
urllib.request.urlretrieve(cls.url, tpath)
with tarfile.open(tpath, 'r') as tfile:
print('extracting')
tfile.extractall(root)
return os.path.join(path, '')download_or_unzip 메서드는 클래스 메서드이기 때문에 TarDataset의 인스턴스를 생성하지 않아도 접근이 가능하다. 이 메서드는 필요한 Tar 파일을 현재 위치에 다운받는 역할을 한다.
- path = os.path.join(root, cls.dirname)을 통해 데이터 다운받을 디렉토리 지정
- 만약 root 디렉토리 내에 데이터셋 디렉토리가 존재하지 않으면 파일 경로로 tpath를 지정한 뒤, url을 통해 다운로드
- 마지막으로 파일 생성 위치인 path를 반환
MR(TarDataset)
class MR(TarDataset):영화리뷰 데이터셋인 MR의 다운로드, 전처리, 훈련/테스트 세트 분할 등에 쓰이는 클래스이다. TarDataset 클래스를 상속받았기에 data.Dataset과 TarDataset의 메서드 및 속성들을 사용할 수 있다.
url = 'https://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz'
filename = 'rt-polaritydata.tar.gz'
dirname = 'rt-polaritydata'각각의 속성에 MR 데이터셋 설치를 위한 값들을 배정해준다. 이때, 가져오는 MR 데이터셋은 영화 리뷰에 대한 감성 분석을 바탕으로 긍정 혹은 부정 레이블이 매겨져 있는 상태이다.
__init__
def __init__(self, text_field, label_field, path=None, examples=None, **kwargs):text_field와 label_field는 data 모듈에서 지원하는 Field 형식의 객체이다. 또한 path, examples 인자에는 기본값으로 None이 주어져 있는데, 이는 데이터셋을 처음 다운로드받을 준비를 할 때 경로나 Example 객체 집합 등을 초기화해야 하기 때문이다.
torchtext.legacy.data.Field는 NLP에 사용되는 클래스이며, 텍스트 전처리 및 토큰화, 단어 집합 구축 (정수와의 mapping) 등에 주로 쓰이는 데이터 형식이다.
clean_str
def clean_str(string):
string = re.sub(r"[^A-Za-z0-9(),!?\'\`]", " ", string)
string = re.sub(r"\'s", " \'s", string)
string = re.sub(r"\'ve", " \'ve", string)
string = re.sub(r"n\'t", " n\'t", string)
string = re.sub(r"\'re", " \'re", string)
string = re.sub(r"\'d", " \'d", string)
string = re.sub(r"\'ll", " \'ll", string)
string = re.sub(r",", " , ", string)
string = re.sub(r"!", " ! ", string)
string = re.sub(r"\(", " \( ", string)
string = re.sub(r"\)", " \) ", string)
string = re.sub(r"\?", " \? ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip()텍스트 정제를 위한 정규식의 경우, 원 논문 저자가 github에 코드를 올려두었다. 해당 코드는 그 코드를 차용한 것이다.
text_field.tokenize = lambda x: clean_str(x).split()
fields = [('text', text_field), ('label', label_field)] text_field의 속성인 tokenize를 참조하여 lambda x: clean_str(x).split()이라는 토큰화 함수를 지정해주고 있다. 이는 텍스트 전처리와 토큰화를 한번에 수행할 수 있는 함수이다. 또한 field 객체들을 저장하는 리스트인 fields에 text_field와 label_field를 각각 튜플로 저장한다.
if examples is None:
path = self.dirname if path is None else path #'rt-polaritydata'
examples = []
with open(os.path.join(path, 'rt-polarity.neg'), errors='ignore') as f:
examples += [
data.Example.fromlist([line, 'negative'], fields) for line in f]
with open(os.path.join(path, 'rt-polarity.pos'), errors='ignore') as f:
examples += [
data.Example.fromlist([line, 'positive'], fields) for line in f]
super(MR, self).__init__(examples, fields, **kwargs) 만약 examples가 없으면 양극성 데이터가 들어 있는 디렉토리 이름을 path로 지정해준 뒤, examples라는 리스트에 data.Example 객체들을 추가해준다. 이때 examples에는 총 2가지 종류(긍정, 부정)의 리스트가 저장된다.
이후 완성된 examples와 fields를 상속 클래스인 TarDataset의 인자로 전달해준다.
splits
@classmethod
def splits(cls, text_field, label_field, dev_ratio=.1, shuffle=True, root='.', **kwargs):
path = cls.download_or_unzip(root)
examples = cls(text_field, label_field, path=path, **kwargs).examples
if shuffle: random.shuffle(examples)
dev_index = -1 * int(dev_ratio*len(examples))
return (cls(text_field, label_field, examples=examples[:dev_index]),
cls(text_field, label_field, examples=examples[dev_index:]))실제로 데이터셋을 다운 받아서 훈련 세트와 테스트 세트로 분할하는 클래스 메서드이다.
dev_ratio은 분할 비율, shuffle은 데이터셋을 무작위로 섞을 지의 여부를 나타내는 파라미터이다.
splits 자체가 클래스 메서드이기 때문에 따로 인스턴스를 생성하지 않고, cls 객체를 통해 클래스의 기능들에 접근하는 양상을 확인할 수 있다. 결과값으로는 dev_ratio를 바탕으로 생성한 dev_index를 기준으로 나누어진 훈련 세트와 테스트 세트가 각각 반환된다.
Model
import torch
import torch.nn as nn
import torch.nn.functional as F본 모듈에서는 신경망 모델을 정의하고 학습하기 위한 라이브러리인 torch.nn을 사용한다.
CNN_Text(nn.Module)
class CNN_Text(nn.Module):CNN 모델을 구현하기 위한 클래스로, 모델 훈련에 필요한 각종 기능들을 제공하는 torch.nn.Module 클래스를 상속받아 사용할 수 있도록 했다.
torch.nn.Module: 딥러닝 모델의 모든 구성 요소들을 추상화하고, 모델 학습 및 훈련에 필요한 기능을 제공하는 클래스이다. 모델 학습 시 자동으로 역전파 과정을 처리해주기 때문에 사용자는 forward 과정만 구현하면 된다는 장점이 있다.
__init__
def __init__(self, args):
super(CNN_Text, self).__init__()
self.args = args
V = args.embed_num # (len(text_field.vocab))
D = args.embed_dim # (default=128)
C = args.class_num # len(label_field.vocab) - 1
Ci = 1
Co = args.kernel_num # default=100
Ks = args.kernel_sizes # default='3,4,5'클래스 호출 시 args라는 인자를 받는데, 이는 argparse 모듈에서 지원하는 명령행 인자와 관련되어있다. 이후 main.py 파트에서 더 자세히 다루겠지만, 간단히 설명하자면 사용자가 입력한 argument들을 parsing하고, 그 결과를 프로그램 내에서 활용할 수 있도록 저장해둔 객체로 이해해볼 수 있다.
이때, args에 저장한 사용자 입력값을 토대로 하여 CNN layer와 관련된 여러 속성들을 정의하고 있다.
| 속성명 | 의미 |
|---|---|
| V | 임베딩할 단어 개수 |
| D | 임베딩할 벡터 차원 |
| C | 최종 출력 텐서 크기 (클래스의 개수) |
| Ci | 입력 채널 개수 |
| Co | 커널 종류 하나당 출력 채널의 개수 |
| Ks | 커널 크기를 담은 리스트 |
이를 기반으로 하여 nn.Module을 활용한 CNN 모델의 구성요소가 만들어지게 된다.
self.embed = nn.Embedding(V, D)
self.convs = nn.ModuleList([nn.Conv2d(Ci, Co, (K, D)) for K in Ks])
self.dropout = nn.Dropout(args.dropout)
self.fc1 = nn.Linear(len(Ks) * Co, C)
if self.args.static:
self.embed.weight.requires_grad = False- nn.Embedding을 통해 V * D 임베딩 룩업 테이블을 만든다.
- nn.ModuleList는 nn.Module 객체들을 input으로 받는 리스트이다. 해당 모듈 리스트에 nn.Conv2d를 통해 정의된 2차원 레이어들을 저장한다.
nn.Conv2d(in_channels, out_channels, kernel_size)
- args에 저장된 dropout rate를 참조하여 dropout 비율을 정한다.
- nn.Linear는 Fully Connected Layer를 만드는 데 사용되었다. 입력 텐서 크기로 len(Ks) * Co (filter에서 추출한 feature들이 구성하는 penultimate layer의 크기), 출력 텐서 크기로 C (클래스 개수)를 받아 최종 분류 결과를 도출하는 역할을 한다.
- 만일 args가 static vector로 설정되어 있다면 gradient update 설정을 False로 설정한다. 즉, fine-tuning 과정을 생략하는 것이라 볼 수 있다.
forward
pytorch가 제공하는 모듈들은 역전파 기능을 자체적으로 제공하고 있기 때문에 따로 이를 구현할 필요는 없다. 다만, 모델 학습에 사용되는 순전파의 경우는 사용자가 직접 정의를 해야 하기 때문에 해당 함수를 정의한 것으로 보인다.
def forward(self, x):
x = self.embed(x) # (N, W, D)
x = x.unsqueeze(1) # (N, Ci, W, D)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs] # [(N, Co, W), ...]*len(Ks)
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] # [(N, Co), ...]*len(Ks)
x = torch.cat(x, 1)
x = self.dropout(x) # (N, len(Ks)*Co)
logit = self.fc1(x) # (N, C)
return logit| 변수명 | 의미 |
|---|---|
| N | 배치 크기 |
| W | 단어 시퀀스 길이 (단어 개수) |
-
우선 입력으로 텍스트 데이터인 x를 받은 뒤, 임베딩 룩업 테이블에 통과시켜 밀집 벡터 (dense representation)의 형태로 바꿔준다. 이때, x는 3차원 텐서의 형태를 가진다.
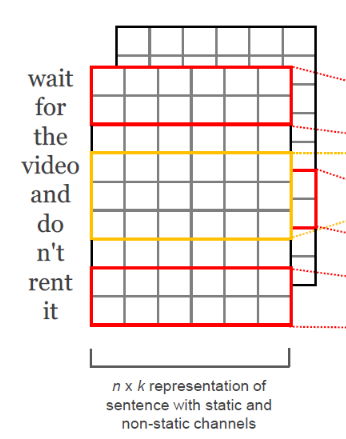
-
unsqueeze 함수를 통해 dim=1 자리에 size가 1 (입력 채널 개수)인 빈 공간을 채워주면서 벡터 차원을 확장시킨다.
squeeze 함수는 크기가 1인 차원을 제거해주는 반면, unsqueeze 함수는 원하는 차원에 크기가 1인 차원을 삽입해주는 역할을 한다. ==> 이유?
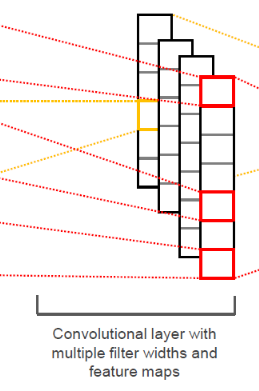
- nn.functional에서 제공하는 relu 활성화 함수 기능을 이용하여 x를 self.convs에 저장되어 있던 2D 레이어들을 통과시킨 값을 ReLU 함수의 input으로 넣어준다. 이후 도출된 feature들을 하나의 리스트 (feature map)로 만들어 x에 저장한다.
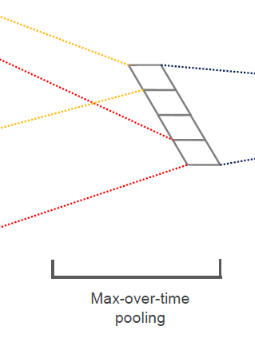
- 마찬가지로 nn.function에서 제공하는 max_pool1d 함수를 통해 max-over-time pooling 과정을 시행한다. feature map에 있는 각 feature들을 input값으로 주고, pooling 과정에서 생기는 중간 차원을 squeeze로 제거하여 최종 출력값을 얻는다. 이후 torch.cat 함수를 통해 len(Ks) (커널 종류 개수) 개의 최대 feature 값들을 하나의 벡터에 저장한다.
- 이렇게 만들어진 penultimate layer를 self.fc1에 통과시켜 label에 대한 확률 분포를 생성하고, 이를 반환한다.
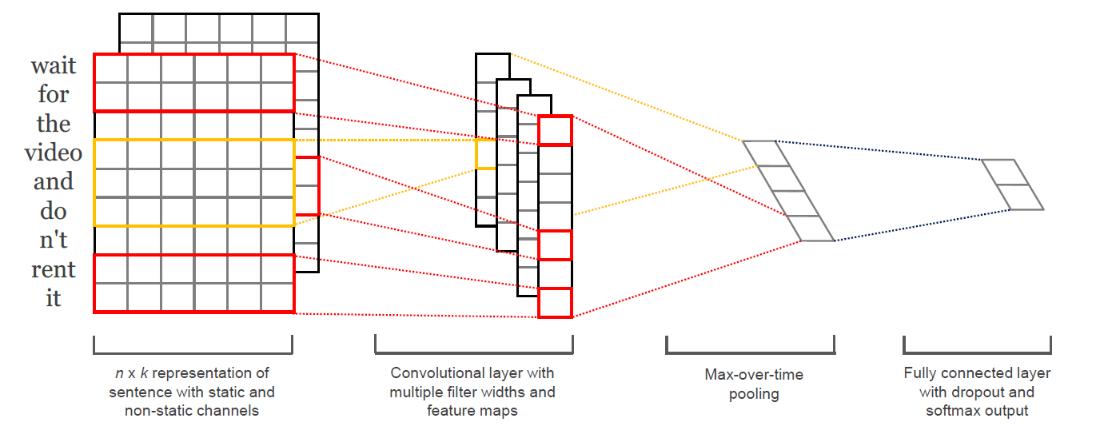
즉, model.py는 논문에서 제시한 위 CNN 모델 아키텍처의 흐름을 충실히 구현하고 있다고 볼 수 있다. 참고로, nn.Module을 상속한 클래스에서는 굳이 forward 메서드를 호출하지 않아도 입력값으로 feature들을 주면 자동으로 순전파 과정을 수행해준다.
train
import os
import sys
import torch
import torch.autograd as autograd
import torch.nn.functional as F본 모듈에서는 모델 학습에 필요한 라이브러리들을 위주로 import하였다.
Torch.nn.autograd는 역전파 과정을 통해 구해진 gradient를 자동으로 텐서의 속성으로 저장하여 참조할 수 있도록 하는 함수이다. 이때, 텐서의 옵션이 requires_grad=True로 지정되어 있어야 한다.
Torch.nn.functionals는 딥러닝 학습 과정에서 필요한 손실함수, optimizer, 활성화 함수 등의 기능을 지원하는 함수이다.
train
def train(train_iter, dev_iter, model, args):
if args.cuda:
model.cuda()train 함수는 train / dev_iter라는 batch 리스트와 함께 nn.Module로 구현된 딥러닝 모델과 args를 인자로 받는다.
또한 만약 args의 cuda 속성이 True라면 모델의 모든 파라미터들을 GPU에 로딩하여 사용하도록 설정하고 있다.
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)모델의 파라미터를 nn.Module.parameters를 통해 Adam optimizer에 전달하고 있다. 이때 학습률의 경우, args에 저장된 학습률을 참조하여 설정한다.
steps = 0
best_acc = 0
last_step = 0
for epoch in range(1, args.epochs+1):
for batch in train_iter:
model.train()
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index align
if args.cuda:
feature, target = feature.cuda(), target.cuda()우선 steps, best_acc, last_step이라는 변수를 생성한 뒤, args에 저장된 epoch 수에 따라 학습을 시작한다. train_iter에 들어 있는 batch마다 학습을 진행하는데, 여기서 model.train()은 모델이 학습에 적합한 모드로 변경하는 함수이다.
변경 이후 feature와 target 데이터를 지정해준 뒤, feature는 텐서를 전치(transpose)시켜 batch size가 가장 앞 차원에 오도록 조정하고, target은 각 레이블 값에서 1을 빼줌으로서 index를 바르게 정렬한다.
또한 GPU 사용이 가능할 때 해당 데이터들을 GPU로 이동하여 계산한다.
optimizer.zero_grad()
logit = model(feature)
loss = F.cross_entropy(logit, target)
loss.backward()
optimizer.step()pytorch는 역전파 과정에서 gradient 계산을 위해 동적 계산 그래프 방식을 채택하고 있기 때문에 파라미터 업데이트 때마다 gradient를 0으로 재설정해주지 않으면 gradient 값들이 누적되어 잘못된 값이 도출된다. 때문에 zero_grad() 함수를 통해 역전파를 끝마칠 때마다 gradient를 0으로 만들어줘야 한다.
model에 feature값을 넣어주면 label에 대해 예측한 확률 분포가 나온다. 이후 cross_entropy 손실 함수를 통해 loss 값을 계산하고, 역전파 과정을 거친다. 이 과정에서 도출된 새로운 파라미터 값들을 optimizer.step() 함수를 통해 업데이트해준다.
steps += 1
if steps % args.log_interval == 0:
corrects = (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
accuracy = 100.0 * corrects/batch.batch_size
sys.stdout.write(
'\rBatch[{}] - loss: {:.6f} acc: {:.4f}%({}/{})'.format(steps,
loss.item(),
accuracy.item(),
corrects.item(),
batch.batch_size))
만약 log_interval (학습 상태 기록 주기)가 되었다면 맞은 개수와 정확도를 구하여 다음 형식에 맞게 결과값을 출력한다.
Batch[300] - loss: 0.592910 acc: 68.3333%(41/60)
if steps % args.test_interval == 0:
dev_acc = eval(dev_iter, model, args)
if dev_acc > best_acc:
best_acc = dev_acc
last_step = steps
if args.save_best:
save(model, args.save_dir, 'best', steps)
else:
if steps - last_step >= args.early_stop:
print('early stop by {} steps.'.format(args.early_stop))
elif steps % args.save_interval == 0:
save(model, args.save_dir, 'snapshot', steps)마찬가지로 test_interval (모델 평가 주기)가 되면 아래에서 등장할 eval() 함수를 통해 best_acc와 last_step을 업데이트한다. 그리고 해당 모델이 최고의 모델이라고 평가될 경우, args에 저장된 save_dir에 현재 모델에 관한 정보들을 .pt 확장자 형식의 파일로 저장한다. 또한 꼭 test_interval이 아니더라도 save_interval (모델 저장 주기)가 되면 동일한 방식으로 모델의 snapshot을 .pt 형식으로 저장한다. 저장 방식의 경우, 아래 save() 함수를 통해 정의되고 있다.
eval
def eval(data_iter, model, args):
model.eval()
corrects, avg_loss = 0, 0
for batch in data_iter:
feature, target = batch.text, batch.label
feature.t_(), target.sub_(1) # batch first, index align
if args.cuda:
feature, target = feature.cuda(), target.cuda() logit = model(feature)
loss = F.cross_entropy(logit, target, size_average=False)모델을 평가하는 함수이다. 우선 model.eval()을 통해 모델을 평가에 적합한 모드로 변환해준다. 그 후 corrects와 avg_loss 변수를 지정해준 뒤, train에서 사용한 방법과 동일하게 label의 예측 확률 분포와 loss 값을 구한다. 이때, size_average 인자가 False로 설정되어 있는데, 이는 각 미니 배치에 있는 손실값을 모두 더하는 것을 의미한다.
avg_loss += loss.item()
corrects += (torch.max(logit, 1)
[1].view(target.size()).data == target.data).sum()
각 배치마다 loss 값과 corrects 값을 더하는 과정을 반복한다.
size = len(data_iter.dataset)
avg_loss /= size
accuracy = 100.0 * corrects/size
print('\nEvaluation - loss: {:.6f} acc: {:.4f}%({}/{}) \n'.format(avg_loss,
accuracy,
corrects,
size))
return accuracyiteration이 종료되면 평균 loss 값과 accuracy를 구해 다음과 같은 형식으로 출력하고, 도출된 accuracy를 반환한다.
Evaluation - loss: 0.613835 acc: 65.4784%(698/1066)
predict
predict 함수는 text를 입력값으로 받아 실제 예측값을 반환하기 위한 목적으로 작성된 함수이다.
def predict(text, model, text_field, label_field, cuda_flag):
assert isinstance(text, str)
model.eval()
# text = text_field.tokenize(text)
text = text_field.preprocess(text)
우선 assert문을 사용하여 text가 string이 아니면 Error를 띄우도록 한다. 그리고 모델을 평가용으로 전환한 뒤, Field 객체에 적용되는 함수인 preprocess를 통해 텍스트 전처리를 수행한다.
text = [[text_field.vocab.stoi[x] for x in text]]
x = torch.tensor(text)
x = autograd.Variable(x)
if cuda_flag:
x = x.cuda()
print(x)
output = model(x)
_, predicted = torch.max(output, 1)
return label_field.vocab.itos[predicted.item()+1]그 다음 대목이 중요하다. text_field에는 미리 build_vocab 함수를 통해 만든 단어 집합이 존재한다. 이 단어 집합은 정수 인코딩 과정을 거쳤기 때문에 단어 하나당 정수 하나가 매칭된 형태로 구성되어 있다. text_field.vocab.stoi의 인덱스 값에 x를 넣어 인덱싱을 해주면 해당 단어와 매칭되는 정수가 반환된다. 즉, 이를 통해 텍스트 데이터를 정수 집합으로 바꾸어주는 것이다.
이를 텐서화한 뒤, autograd.Variable() 함수에 입력값으로 집어 넣으면 자동으로 gradient 업데이트가 가능한 학습용 텐서로 바뀌게 된다. 만일 cuda_flag가 True이면 데이터를 GPU로 옮겨주고 예측 작업을 시작한다.
이후 output에서 가장 확률값이 높은 레이블의 인덱스를 predicted에 저장해주고, vocab.itos를 통해 예측값에 해당하는 예측 단어를 반환한다.
save
save 함수는 학습 진행 중에 pytorch 모델을 파일로 저장하기 위한 함수이다.
def save(model, save_dir, save_prefix, steps):
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
save_prefix = os.path.join(save_dir, save_prefix)
save_path = '{}_steps_{}.pt'.format(save_prefix, steps)
torch.save(model.state_dict(), save_path)간단히 설명하자면 model과 저장 위치, save_prefix (best of snapshot), 스텝 수를 인자로 받은 뒤, model의 정보를 담고 있는 파일인 .pt (파이토치 모델 파일)을 저장해준다. 이때, model.state_dict() 함수는 학습 가능한 파라미터가 담겨 있는 딕셔너리 형태의 데이터로, 저장 용량을 훨씬 더 적게 소모하면서 모델 파일을 저장 가능하다는 이점이 있다.
main
본 프로그램의 메인 실행 코드이다.
import os
import argparse
import datetime
import torch
import torchtext.data as data
import torchtext.datasets as datasets
import model
import train
import mydatasets
argparse 라이브러리는 명령줄 인터페이스를 파싱하고 명령행 인수를 처리하기 위한 라이브러리이다. parser 객체에 여러 명령행 인수를 저장함으로써 내용을 언제든지 참조할 수 있도록 한다는 특징이 있다.
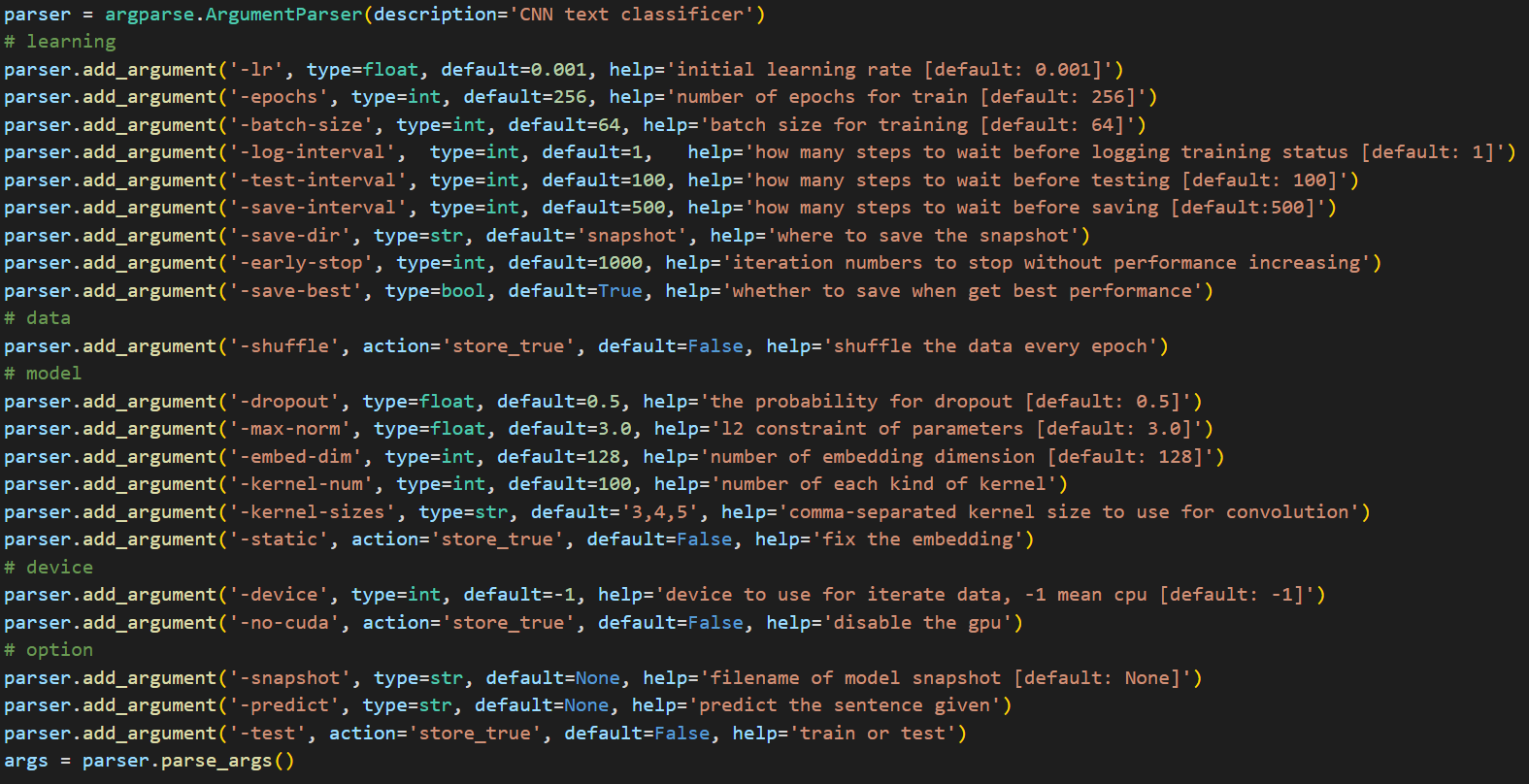
본 코드에서는 크게 학습, 데이터 처리, 모델링, 기기, 기타 옵션과 관련하여 argument들을 작성한 뒤, 이를 args 객체에 저장하였다. 추가로, 굳이 따로 변수를 지정해두지 않고 argparse 라이브러리를 사용하는 이유는 argparse가 코드의 가독성을 높이고 유지보수를 용이하게 해주기 때문이다.
sst
SST 데이터셋을 다운받고 훈련/테스트/검증 세트로 분할하는 역할의 함수이다.
def sst(text_field, label_field, **kargs):
train_data, dev_data, test_data = datasets.SST.splits(text_field, label_field, fine_grained=True)
#text_field와 label_field에 저장된 train/dev/test data 반환
text_field.build_vocab(train_data, dev_data, test_data) #
label_field.build_vocab(train_data, dev_data, test_data)
train_iter, dev_iter, test_iter = data.BucketIterator.splits(
(train_data, dev_data, test_data),
batch_sizes=(args.batch_size,
len(dev_data),
len(test_data)),
**kargs)
return train_iter, dev_iter, test_iter Field 객체들을 인자로 받는데, 이는 다운 받은 SST 데이터셋을 저장하는 용도로 사용된다. pytorch에서는 자체적으로 SST 데이터셋을 제공하고 있기 때문에 datasets의 메서드를 활용해 데이터를 다운받는 모습을 볼 수 있으며, fine_grained 옵션을 True로 설정함으로써 더 세분화된 감정 분화 레이블을 다운 받도록 했다는 점을 알 수 있다.
이후 build_vocab 함수를 통해 정수와 매칭된 단어 집합을 생성하고, BucketIterator 클래스를 이용하여 각 데이터들을 미니 배치로 나누어준다. 이때, batch_sizes에 len(dev_data)와 len(test_data)가 들어가 있는 이유는 배치 크기를 검증/테스트 데이터 크기와 동일하게 함으로써 해당 과정을 한번만 수행해도 되게 하기 위함이다.
미니 배치로의 분할까지 끝나면 생성된 train_iter, dev_iter, test_iter 객체를 반환한다.
mr
sst와 거의 같은 역할을 하는 함수로, mr 데이터셋을 다운받고 훈련/테스트/검증 세트로 분할하는 역할을 수행한다.
def mr(text_field, label_field, **kargs):
train_data, dev_data = mydatasets.MR.splits(text_field, label_field)
text_field.build_vocab(train_data, dev_data)
label_field.build_vocab(train_data, dev_data)
train_iter, dev_iter = data.Iterator.splits(
(train_data, dev_data),
batch_sizes=(args.batch_size, len(dev_data)),
**kargs)
return train_iter, dev_iter세부 내용은 sst 함수와 거의 유사하나, 한 가지 다른 점은 data.datasets 내에서 MR 데이터셋을 지원하지 않기 때문에 앞서 mydatasets 모듈에서 정의한 MR.splits 함수를 쓴다는 특징이 있다.
main part
print("\nLoading data...")
text_field = data.Field(lower=True)
label_field = data.Field(sequential=False) #no tokenization applied
train_iter, dev_iter = mr(text_field, label_field, device=-1, repeat=False)
# train_iter, dev_iter, test_iter = sst(text_field, label_field, device=-1, repeat=False)우선 자연어 처리의 기반이 되는 Field 객체인 text_field와 label_field를 생성해준다. text_field의 경우, lower=True로 해줌으로써 입력되는 데이터를 소문자로 바꿔주고 있고, label_field는 sequential을 False로 하여 tokenization이 적용되지 않는 데이터임을 나타내고 있다.
이후 데이터를 생성하는데, 주석을 어디에 다느냐에 따라 데이터의 종류를 결정할 수 있다.
args.embed_num = len(text_field.vocab)
args.class_num = len(label_field.vocab) - 1
args.cuda = (not args.no_cuda) and torch.cuda.is_available(); del args.no_cuda
args.kernel_sizes = [int(k) for k in args.kernel_sizes.split(',')]
args.save_dir = os.path.join(args.save_dir, datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
print("\nParameters:")
for attr, value in sorted(args.__dict__.items()):
print("\t{}={}".format(attr.upper(), value))args의 속성들을 새롭게 정의하는 파트이다.
- 임베딩할 단어 개수 (args.embed_num)은 text_field 내 단어 수
- 클래스 개수 (args.class_num)은 label_field 내 단어 수에 1을 뺀 값
- 사용자가 no_cuda를 설정하면 GPU를 사용하지 않고, 설정하지 않으면 GPU를 활성화
- 커널의 종류별 크기 집합은 기존의 string 형태였던 args.kernel_sizes를 리스트로 변환한 값
- 파일의 저장 위치 설정
속성 정의가 완료되면 args에 저장된 모든 내용을 출력한다.
cnn = model.CNN_Text(args)
if args.snapshot is not None:
print('\nLoading model from {}...'.format(args.snapshot))
cnn.load_state_dict(torch.load(args.snapshot))
if args.cuda:
torch.cuda.set_device(args.device)
cnn = cnn.cuda()앞서 model 모듈에서 정의한 CNN_Text 함수에 args를 인자로 전달해줌으로써 CNN 모델을 생성한다. 그리고 만일 args.snapshot에 값이 존재한다면 이를 불러와서 CNN 모델에 적용시키는데, default 값이 None이기 때문에 따로 설정하지 않으면 적용되지 않는 옵션이다.
또한 GPU 사용이 가능하면 모델을 GPU로 옮겨서 연산하도록 한다.
if args.predict is not None:
label = train.predict(args.predict, cnn, text_field, label_field, args.cuda)
print('\n[Text] {}\n[Label] {}\n'.format(args.predict, label))
elif args.test:
try:
train.eval(test_iter, cnn, args)
except Exception as e:
print("\nSorry. The test dataset doesn't exist.\n")
else:
print()
try:
train.train(train_iter, dev_iter, cnn, args)
except KeyboardInterrupt:
print('\n' + '-' * 89)
print('Exiting from training early')이후 args에 저장된 predict, test, train 값에 따라 학습 및 평가 등을 수행한다. args.predict와 args.test의 값이 각각 None과 False이기 때문에 따로 이를 수정하지 않는 이상 모델은 학습 과정을 수행하게 된다.
Conclusion
본 코드 리뷰를 진행하면서 논문에서 설명하는 내용이 pytorch를 통해 어떻게 구현되는지 여실히 확인할 수 있었다.
- 논문에서 제시한 모델 아키텍처를 어떻게 model.py에 구현하였는지
- 논문에서 제시하는 하이퍼 파라미터들을 어떻게 코드에 활용하였는지
- 워드 임베딩 과정이 어떻게 수행되는지
기실 이전에 pytorch 라이브러리에 대해 탐구하고 분석해본 경험이 없어서 코드를 이해하는 데 다소 시간이 오래 걸렸지만, 그만큼 얻어가는 게 많았던 것 같다. 또한 코드를 분석하는 건 누구나 할 수 있지만 중요한 건 이러한 코드를 내가 직접 구상하고 짤 수 있는 능력이기 때문에 이를 함양하기 위해 앞으로도 꾸준히 공부를 이어나갈 것이다.
