[Paper Review] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Transformer in Vision Tasks
Self-Attention 매커니즘을 활용한 Transformer 아키텍처는 그 계산 효율성과 확장성 덕분에 다양한 NLP task들에 사용되었다. 이는 주로 큰 텍스트 코퍼스에서 사전 학습을 진행한 뒤, 세부 task-specific 데이터셋에 대하여 fine-tuning을 수행하는 방식으로 활용되었는데, 대표적인 모델로는 BERT를 들 수 있다.
그러나 Vision Task에서는 여전히 ResNet을 비롯한 CNN 아키텍처 기반 모델들이 주를 이루고 있었다. 하지만 이 논문의 등장으로 인해 Vision Task에서도 Transformer가 점차 활발하게 사용되기 시작하였고, 현재는 SOTA 모델 대부분의 주류를 차지하게 되었다.
Introduction
NLP에서 transformer 아키텍처가 큰 성공을 거두자, 비전 분야에서도 self-attention 매커니즘을 활용하여 이미지 분류 성능을 높이고자 하는 시도들이 여러 번 시행되었다. 그러나 이러한 시도들은 비전 분야에 특화된 specialized attention pattern을 사용하였기 때문에 하드웨어 성능 문제와 맞물려 대규모 이미지 분류 task에서는 ResNet 모델만큼 좋은 성능을 내지 못하였다.
이에 착안하여, 본 논문에서는 기존 transformer 모델에 최소한의 수정만을 적용한 채 vision task에 직접적으로 접목시키는 시도를 하였다. 바로 이미지를 패치 (patch) 단위로 나누어 선형 임베딩한 뒤, 시퀀스 형태로 transformer에 전달하는 방식이다. 이러한 이미지 패치는 NLP에서 word token과 같은 형태로 취급되기 때문에 NLP에서 sentence sequence를 처리하는 방식과 동일하게 처리될 수 있다는 장점이 존재한다.
위와 같은 방식으로 이미지를 처리한 결과, ImageNet과 같은 mid-sized 데이터셋에서는 기존의 CNN 기반 아키텍처에 비해 낮은 성능을 얻었지만, 그보다 규모가 큰 데이터셋에 대해서는 눈에 띄는 성능 향상 결과를 도출할 수 있었다. 이는 중간 규모 데이터셋으로 학습을 진행할 때는 transformer가 CNN에 비해 translation equivariance, locality와 같은 inductive bias (귀납 편향)이 부족하기 때문에 적은 데이터만으로 일반화 성능을 끌어올리기 쉽지 않기 때문이다. 반면 대규모 데이터셋에서는 스케일링의 영향력이 귀납 편향의 영향력을 상회할 수 있기에, 더 좋은 성능을 낼 수 있는 것이다.
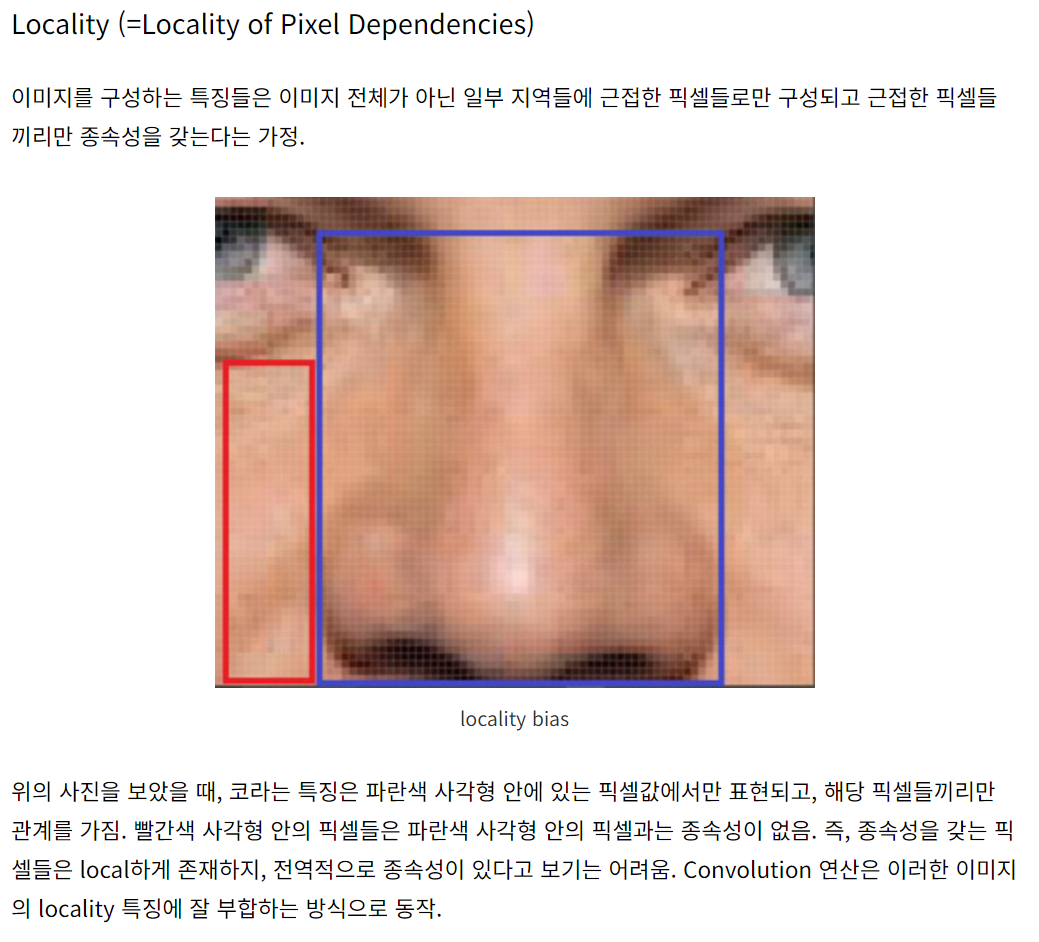
Translation equivariance: 모델이 입력 이미지에서 특징(feature)이 위치한 장소와 무관하게 그 특징을 동일하게 인식할 수 있는 성질. 예컨대, 고양이 이미지에서는 고양이와 관련된 특징이 특징이 이미지 좌측이나 우측에 있든 동일하게 인식할 수 있어야 함.
Locality: 특징이 주변 지역 픽셀의 정보에만 의존한다는 성질. 즉, 이미지의 특정 지역은 그 주변 영역과만 강한 상관관계를 가지고 멀리 있는 픽셀과는 약한 상관관계를 가짐.
실제로 ViT는 대부분의 이미지 인식 벤치마크에서 기존의 SOTA 성능을 능가하는 모습을 보였다.
Method
Model Overview
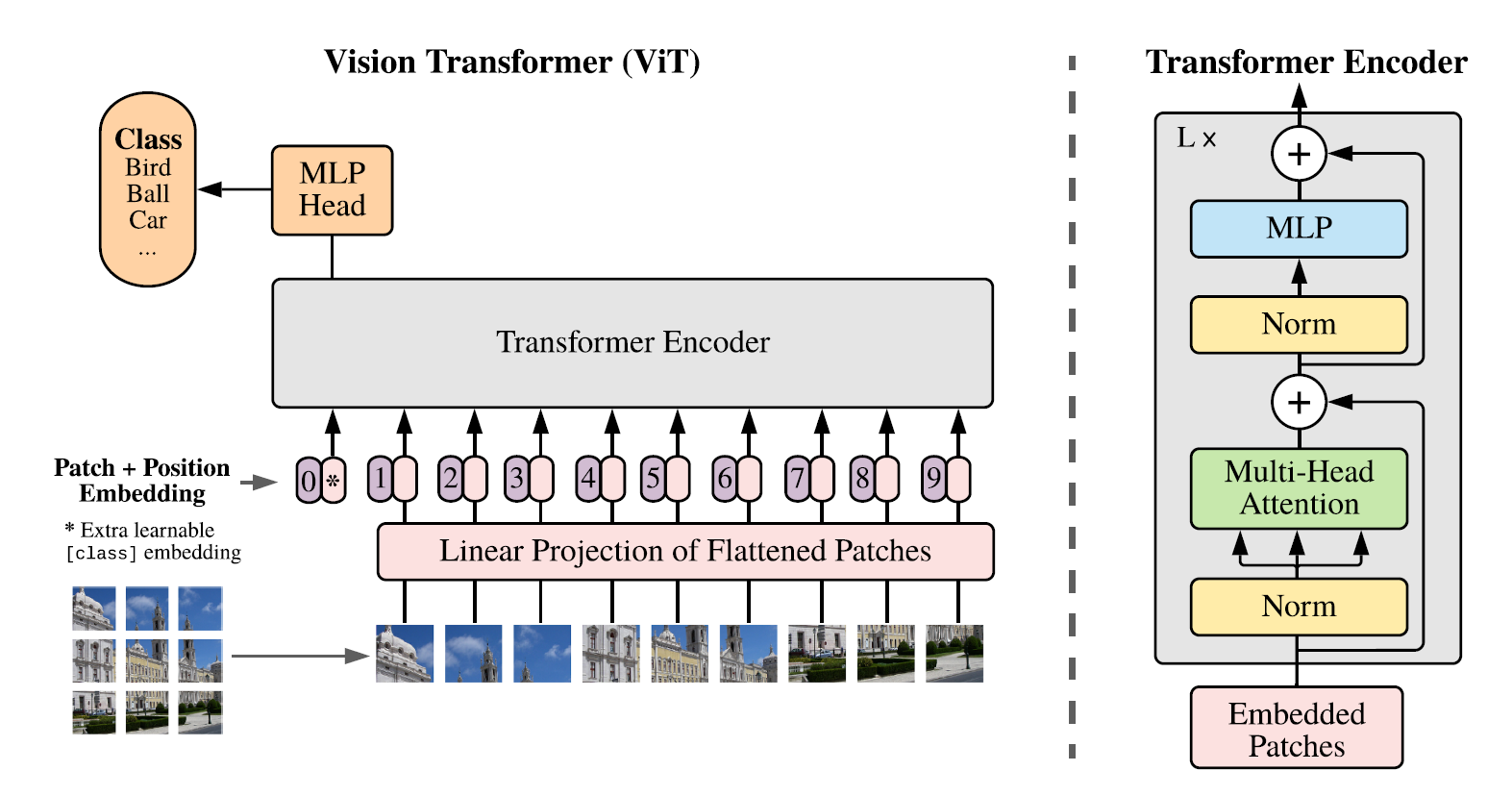
모델의 구조를 살펴보면, 고정된 크기의 패치들로 나누어진 이미지가 선형 임베딩되어 transformer encoder에 전달된다. 이때, 각 패치의 position 임베딩이 함께 전달되어 위치 정보를 표시하는 역할을 한다. 이후, 분류 작업을 수행하기 위해 학습 가능한 토큰인 'CLS token'을 시퀀스 앞에 삽입한 뒤, 기존 transformer 아키텍처(BERT 등)와 동일한 방식으로 분류 작업을 진행한다.
구체적으로 ViT는 2D 형태의 이미지를 시퀀스 형태로 변환하기 위해 다음과 같은 reshaping 과정을 거친다.
변환 전
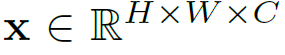
변환 후
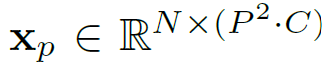
여기서 (H, W)는 원본 이미지의 해상도, (P, P)는 이미지 패치의 해상도, C는 채널 개수를 의미한다. 따라서 원본 이미지 크기인 HW를 패치의 크기인 P^2로 나눈 값인 N은 패치의 총 개수가 된다. 즉, 위와 같은 변환 과정을 통해 모델에 입력 데이터를 전달하기에 앞서 데이터를 flatten해주는 것이다.
위치 임베딩의 경우, 2차원이 아닌 1차원 위치 임베딩을 사용한다.
1차원 위치 임베딩을 사용하는 이유
(1) 2차원 위치 임베딩을 사용했을 때 성능 향상이 크지 않음.
(2) 2차원 위치 임베딩은 x, y 좌표를 모두 인코딩해야 하므로 계산 복잡도와 메모리 요구량이 증가함.
(3) 1차원 위치 임베딩을 사용하면 이미지를 1차원 시퀀스로 평탄화하는 접근 방식과 일관성이 있어 모델 설계가 간단해짐.
(4) Transformer 아키텍처는 self-attention 매커니즘을 통해 위치 정보를 상대적으로 잘 학습할 수 있기에 단순한 1차원 위치 임베딩으로도 충분한 성능을 낼 수 있음.
ViT Encoder
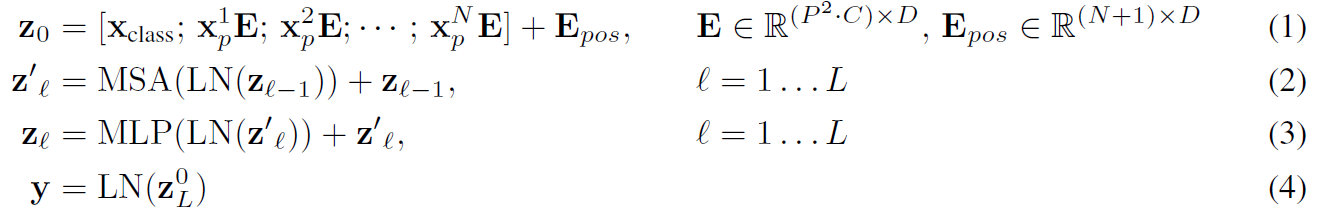
ViT는 기존 Transformer의 encoder와 거의 동일한 형태의 encoder를 사용하지만, 세부 구성이 조금씩 다르다. 우선 Norm Layer가 Multi-Head Attention이나 MLP 레이어의 앞에 배치되어 있다. MLP에서 활성화 함수로 2개의 GELU layer를 사용하여 학습의 안정성을 높이고 있다.
GELU (Gaussian Error Linear Unit): ReLU의 smoothed version으로, 매끄러운 형태를 가져 학습을 안정적으로 수행할 수 있다.
이를 수식으로 나타내면 다음과 같다.
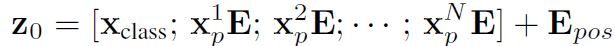
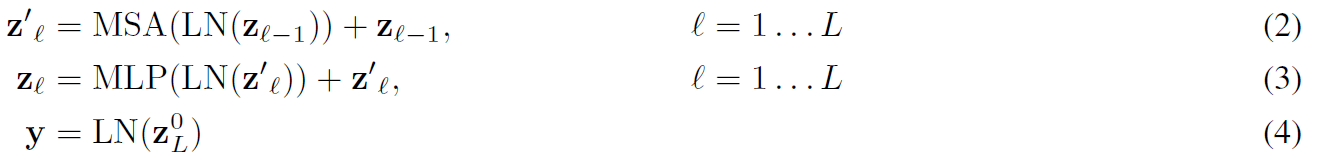
입력 시퀀스 (Embedded Patches)는 CLS 토큰 뒤에 각각의 패치 임베딩이 연결된 형태로 되어 있다. 그리고 기존 transformer와 동일하게 ViT는 self-attention 매커니즘을 차용하고 있으므로, 패치의 임베딩 토큰에 위치 정보가 존재하지 않는다. 이를 위해 위치 인코딩 정보를 따로 더하여 패치의 1차원 위치 정보를 표시한다.
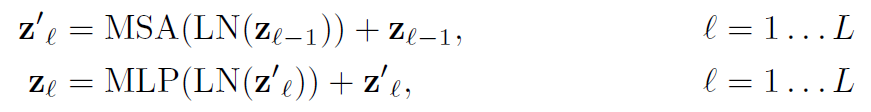
이후, MSA (Multiheaded Self Attention) layer와 MLP (Multi Layered Perceptro) layer에 각각 LayerNorm을 거친 시퀀스를 통과시키는데, 이때 기울기 소실 문제를 없애기 위해 각각의 출력값에 Residual Connection을 해준다.
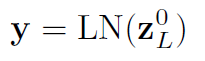
그리고 마지막으로 CLS 토큰의 최종 출력인 z0L을 LayerNorm layer에 넣어줌으로써 최종 예측 결과를 산출하게 된다.
inductive bias
CNN과 달리, ViT 내 self-attention layer들은 전역적(Global)인 특징을 갖고 있다. 하지만 그로 인해 ViT는 image-specific한 'Inductive bias' (locality, translation equivariance, two-dimensional neighborhood structure)를 CNN에 비해 더 적게 갖고 있다는 특징이 있다. 즉, 이미지 데이터가 갖는 bias를 제대로 반영하지 못하는 것이다. 이 때문에 학습 데이터셋의 크기가 작을 경우 ViT는 CNN 기반 아키텍처에 비해 분류 성능이 더 낮게 나타난다.
<참고자료> 출처: https://daebaq27.tistory.com/108

Hybrid Architecture
Raw하게 이미지 패치를 나누어 쓰는 것 대신, CNN의 Feature Map의 시퀀스를 사용하는 것이 대안으로 활용될 수 있다. CNN의 Feature는 공간적 크기가 1x1이 될 수 있기 때문에 이를 flatten하여 transformer 차원에 투영시키면 간단하게 입력 시퀀스를 구할 수 있다.
Fine-Tuning & Higher Resolution
Fine-tuning 과정에서 pre-training 과정보다 더 높은 해상도를 사용할 경우, 성능이 향상된다고 한다. 패치 크기가 동일하다는 가정 하에서 해상도를 더 높게 설정하면 시퀀스의 길이가 증가하고, 이는 fine-tuning 데이터를 더욱 효율적으로 활용할 수 있게 해주기 때문이다. 또한 fine-tuning 시에는 사전 학습된 위치 임베딩이 더 이상 필요가 없기 때문에, 입력 이미지 크기 내 패치 위치에 맞게 2차원 interpolation (보간) 기법을 활용하여 위치 임베딩 값을 채워준다.
Experiment
Dataset
(1) Pre-Training
- ILSVRC-2012 ImageNet
- ImageNet-21k
- JFT-18k
(2) Fine-Tuning
- ImageNet
- ImageNet-ReaL
- CIFAR-10/100
- Oxford-IIT Pets
- VTAB (Natural, Specialized, Structured)
Models
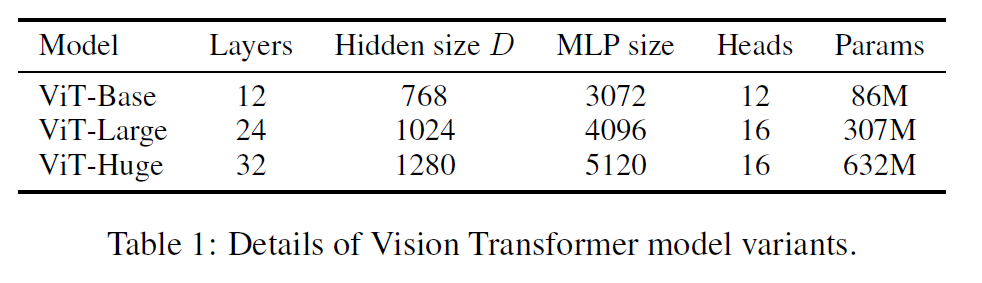
참고로 Base와 Large의 아키텍처는 BERT의 구조를 차용한 것이다. Baseline 모델의 경우는 ResNet을 사용했으나, Batch Normalization layer를 Group Normalization로 바꾸고 Standardized Convolution 기법을 사용했다는 점이 차이점이다.
모델 표기의 경우, ViT-(1)/(2)라는 이름으로 표기되고 있는데, 여기서 (1)은 모델 크기를 나타내고 (2)는 패치 크기를 나타낸다. (ex: ViT-L/16)
Training & Fine-tuning
아래는 훈련 및 파인튜닝 과정에서의 하이퍼파라미터들이다.
| Pre-training | Fine-tuning | |
|---|---|---|
| optimizer | Adam | SGD with momentum |
| batch size | 4096 | 512 |
| image size | 224 | 384 |
Metrics
Fine-tuning 정확도와 Few-shot 정확도를 사용하고 있다. Fine-tuning 정확도의 경우, fine-tuning 과정을 모두 거친 뒤 모델의 완전한 벤치마크 성능을 평가하기 위해 사용된다. 반면 Few-shot 정확도는 학습 데이터의 일부만을 사용해 빠르게 모델 성능을 평가할 때 주로 사용된다.
Comparision to the SOTA
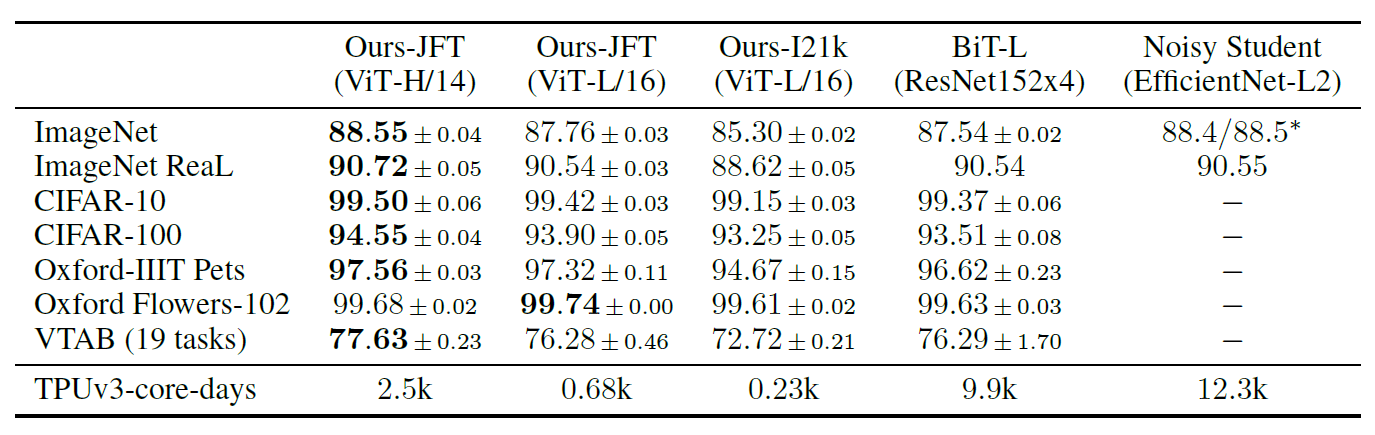
실험 결과, 대부분의 데이터셋에서 기존의 SOTA 모델인 CNN 기반 ResNet을 상회하는 성능을 도출하고 있음을 알 수 있다.
뿐만 아니라 TPUv3-core-days 지표에 따르면, ViT는 SOTA 모델보다 훨씬 더 적은 계산 시간을 소요하고 있음을 알 수 있다.
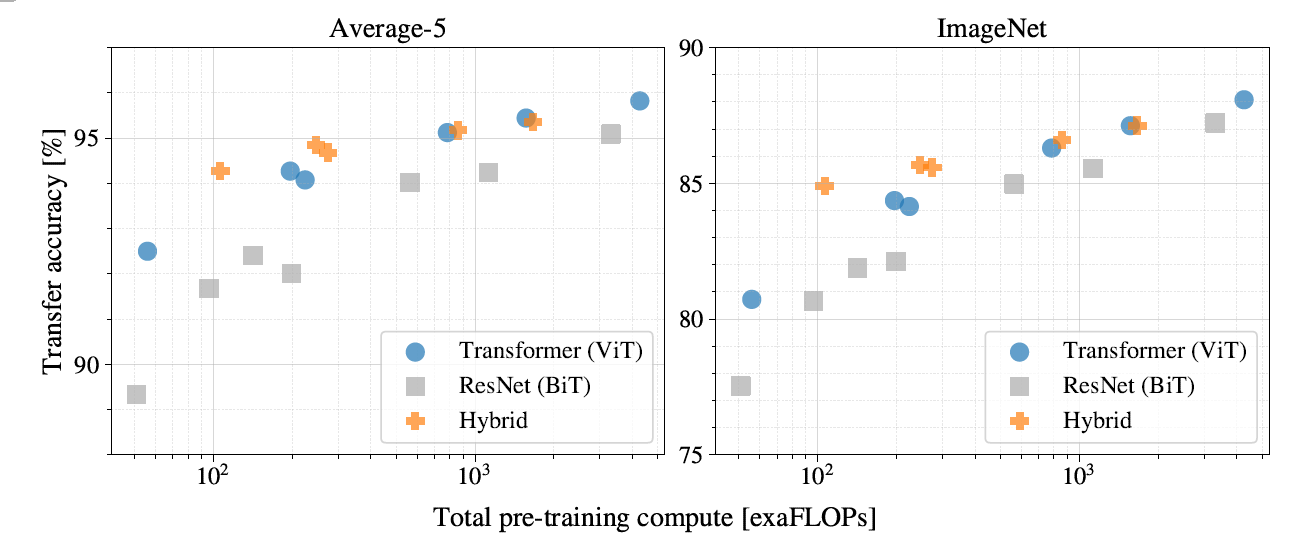
더 나아가 VTAB 데이터셋 내의 task-specific한 데이터들에 대해서도 전반적으로 굉장히 훌륭한 성능을 보이고 있음을 알 수 있다.
다만 학습 데이터셋의 크기가 비교적 작은 ImageNet의 경우, BiT (ResNet)의 성능이 더 높게 나타나고 있음을 확인할 수 있는데, 이는 앞서 언급한 inductive bias의 영향으로 추측된다. 하지만 데이터셋의 크기를 키우면 키울수록 transformer 특유의 scalability에 의해 ViT의 성능이 월등히 높게 나타나게 된다.
또한 모델의 크기가 비슷할 경우, BiT에 비해 ViT가 더 좋은 성능을 내고 있을 뿐만 아니라 연산량도 더 적게 소요됨을 확인할 수 있다. 즉, ViT는 ResNet 계열과 달리, 모델이 비대해짐에도 불구하고 성능 포화 (Saturate)없이 지속적으로 성능이 증가하는 양상을 보이고 있기 때문에 스케일 증가에 따른 성능 향상의 가능성이 아직까지 무궁무진하게 남아있는 상태라고 볼 수 있다.
Conclusion
ViT는 이미지 인식 문제에 Transformer 모델을 직접 적용한 새로운 접근법이다. 기존 연구들과는 달리, ViT는 패치 추출 단계를 제외하고는 image-specific한 inductive bias를 모델 아키텍처에 도입하지 않는다. 대신 이미지를 패치 시퀀스로 해석하고, 자연어 처리에서 사용되는 표준 transformer 인코더로 처리한다.
이 간단하지만 확장성 있는 전략은 대규모 데이터셋으로 사전학습될 때 놀라울 정도로 잘 작동한다. ViT는 많은 이미지 분류 데이터셋에서 SOTA 수준의 성능을 내거나 능가하며, 사전학습 비용 또한 비교적 저렴하다.
이러한 초기 결과는 고무적이나, 여전히 많은 과제가 남아있다.
-
객체 검출, 세그멘테이션 등 다른 컴퓨터 비전 태스크에 ViT를 적용하는 것
-
자가 지도 사전학습 방법 탐색 (현재 자가 지도 사전학습은 대규모 지도 사전학습에 비해 성능 격차가 크다)
-
ViT의 추가 확장을 통한 성능 향상
전체적으로 ViT는 inductive bias 대신 대규모 데이터와 사전학습을 활용하여, 이미지 인식 문제에서 transformer 아키텍처를 성공적으로 적용한 사례이다. 향후 다양한 과제 해결과 모델 확장을 통해 더욱 발전할 것으로 기대된다.
