Introduction
GPT-3의 출시 이전까지의 언어 모델들은 대규모 텍스트 데이터를 바탕으로 pre-training을 진행한 뒤, 세부 task에 대해 fine-tuning 과정을 거쳐 성능을 대폭 끌어올리는 방식으로 구성되었다. 그러나 이러한 방법론은 세부 task들에 대한 fine-tuning 데이터셋이 항상 구비되어 있어야 한다는 점에서 분명한 한계점을 갖는다. 한계점에 대해 보다 구체적으로 정리해보면 다음과 같은 요인들이 있을 수 있다.
1. label 데이터셋의 필요성
일반적으로 인간은 사전 지식을 갖추고 나면 이와 관련된 어떠한 새로운 문제가 나오더라도 기존에 가지고 있던 사전 지식을 활용하여 문제를 해결할 수 있다. 반면 LLM은 pre-training을 진행했더라도 특정 문제를 출려면, 특정 문제를 다시 학습해야 한다. 게다가 이 학습 과정에는 label이 필수적으로 요구되기 때문에 데이터셋을 구축하는데 많은 비용이 든다는 단점이 있다.
2. Fine-tuning 과정에 의한 일반화 기능 상실
LLM 모델은 fine-tuning을 통해 새로운 데이터를 학습하게 될 경우, pre-training 과정에서 학습한 언어 능력을 소실하게 된다. 이는 학습 과정에서 기존 가중치가 조정되면서 일반화 능력이 사라지게 되기 때문이다. 즉, 사람으로 치면 특정 분야의 전문가가 되었지만 그 댓가로 일상적인 대화 능력을 상실하게 되는 것으로 볼 수 있다.
3. 언어 학습 과정에서 드러나는 인간과의 차이
인간은 언어를 학습함에 있어 딥러닝 모델과 달리 label된 데이터를 필요로 하지 않는다. 자연어로 된 간단한 지시나 몇 가지 예시 문장만 갖고도 task에 대한 적응을 완벽히 수행할 수 있다. 딥러닝의 최종 목표는 인간의 인지 기능을 완벽히 재현하는 것이기에 이러한 점에서 분명한 한계를 갖는다.
이에 GPT-3의 개발진은 다음과 같은 해결책을 제시하였다.
1. In-context Learning
in-context learning은 사전 학습된 모델을 바탕으로 새로운 task를 수행할 때 몇 가지 예시들을 함께 제공해주는 방식이다. 즉 예시로 주어진 문장들에서 context를 파악하고, 이를 통해 task의 목적 및 수행 방식을 추론하고 학습하는 방식이라 볼 수 있다.
2. Model Capacity의 대량 증가
이는 곧 모델 사이즈를 대폭 키우는 것과 같은 뜻이다. 모델 사이즈가 증가하게 되면 더 많은 파라미터를 갖게 되고, 이에 따라 더 많은 연산을 수행할 수 있는 능력을 갖추게 된다. 즉 모델의 추론력이 큰 폭으로 상승하게 된다. 해당 논문에서 소개한 GPT-3의 경우, 무려 1,750억개 가량의 파라미터를 사용하였다.
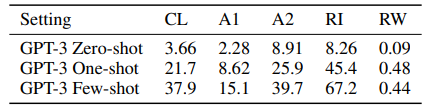
In-context learning을 활용하는 모델은 제공받는 예시의 수에 따라 크게 zero-shot, one-shot, few-shot으로 나눌 수 있다. zero-shot은 0개의 예시 (task에 대한 적응 X), one-shot은 하나의 예시, few-shot은 여러 개의 예시를 제공받는다.
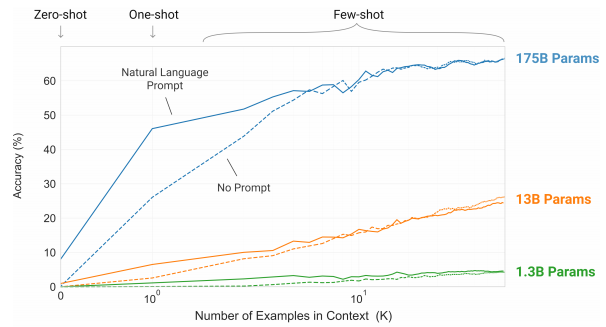
위 그림에서 알 수 있듯이, 모델의 성능은 예시의 개수와 비례하는 경향을 보인다. 이때, 예시 개수 증가에 따른 모델 성능 향상은 수확체감하므로, 예시의 수를 무조건 늘리는 것만이 능사가 아니라는 사실을 알 수 있다. 또한 모델의 성능은 파라미터의 수, 즉 model capacity가 올라갈 수록 큰 폭으로 상승한다. 이를 통해 shot의 수, 파라미터 개수가 모델 성능과 높은 상관관계를 갖는다는 사실을 알 수 있다.
이때 한 가지 유의해야 할 부분은 성능 측정 과정에서 gradient 업데이트나 fine-tuning은 일절 진행되지 않았다는 점이다. 다시 말해 shot의 개수가 성능에 미치는 영향을 순수하게 나타낸 것이며, 위의 과정이 추가될 경우 정확도가 더욱 상승하게 될 것임을 예측해볼 수 있다.
GPT-3가 놀라운 점은 이렇게 높은 수준의 정확도를 fine-tuning 데이터셋 없이도 달성할 수 있다는 점이다. 단 몇 가지의 예시만으로도 사람에 가까운 task 적응력을 보여준다는 점에서 NLP 모델의 범용성을 크게 확장시켰다고 볼 수 있다.
Approach
GPT-3를 평가한 방법은 다음 4가지로 압축하여 설명할 수 있다.
(1) Fine-Tuning
(2) Few-Shot
(3) One-Shot
(4) Zero-shot
즉, 기존의 LLM에서 활용되는 Fine-tuning 방식과 비교하여 in-context learning 방식이 얼마만큼의 정확도를 갖는지 측정하고자 했음을 알 수 있다.
모델 아키텍처
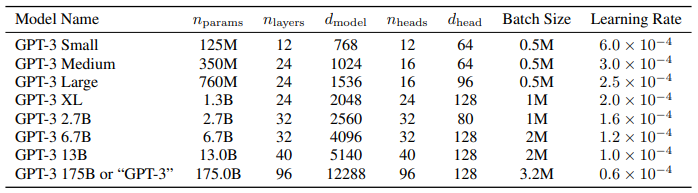
- 아키텍처 자체는 GPT-2와 같지만 파라미터 수를 극단적으로 늘려 model capacity를 증가시켰음을 알 수 있다. 가장 큰 모델의 경우, 1,750억개의 파라미터와 96층의 레이어, 12,288차원의 히든 차원, 96개의 attention head를 사용하였다.
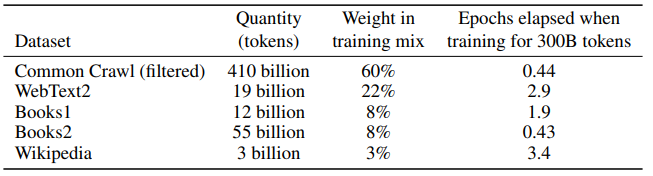
훈련 데이터셋
Results
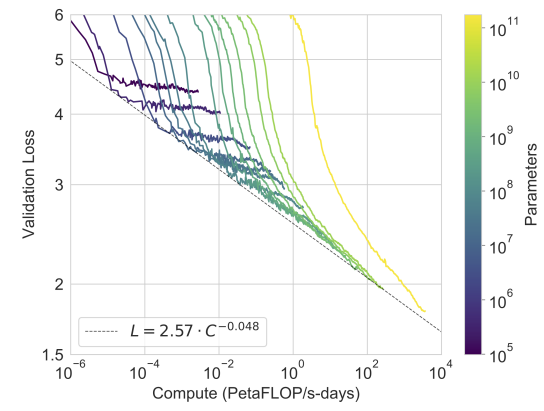
in-context learning 방식에 대한 평가에 앞서, 모델 파라미터 수가 성능에 미치는 영향을 측정한 결과는 다음과 같다. 색이 진한 그래프일 수록 (모델 파라미터 수가 많을 수록) 학습 과정에서 cross-entropy loss 값이 더 작게 나타나는 것을 확인할 수 있다. 이는 큰 모델 크기가 다양한 NLP task들에서의 성능 향상을 가져올 수 있음을 암시한다.
Language Modeling 및 관련 task에서의 성능
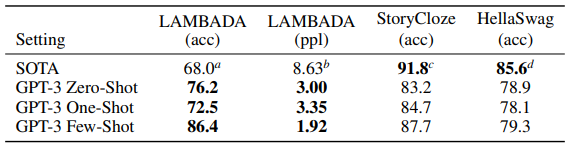
LAMBADA: 문장 완성하기 / 언어의 장기 의존성을 모델링하는 task
HellaSwag: 짧은 글이나 지시사항을 끝맺기에 가장 알맞은 문장을 고르는 task
StoryCloze: 다섯 문장의 긴 글을 끝맺기에 가장 적절한 문장을 고르는 task
최근 사이즈만 키운 언어 모델은 LAMBADA와 같이 난이도가 높은 벤치마크 데이터셋에 대해서는 미미한 성능 향상만을 가져왔고, '하드웨어와 데이터 크기만 늘리는 것이 길이 아니다'는 논쟁을 불러일으켰다. 그러나 GPT-3은 기존 대비 8% 이상의 성능 향상을 얻으며 Zero-shot setting에서 76%의 정확도를 달성했고, Few-shot에서는 86.4%의 정확도를 달성하였다.
그러나 HellaSwag와 StoryCloze의 경우, BERT 기반의 기존 SOTA 모델의 성능을 뛰어넘지는 못했음을 알 수 있다.
Closed Book Question Answering
GPT-3이 폭넓은 사실 기반의 지식에 대한 질문에 답변할 수 있는지 측정하기 위해 open-domain QA 형태의 태스크에 대한 closed-book 테스트를 진행하였다.
TriviaQA : Few-shot& Zero-shot 성능으로 T5-11B 모델의 fine-tuning 기반의 접근법 성능을 뛰어넘었다.
WebQuestions : 14.4% / 25.3% / 41.5% (0S/1S/FS) -> few shot으로 갔을 때 zero shot에 비해 성능 향상 폭이 컸다.
Natural Questions : 14.6% / 23.0% / 29.9% -> NQ는 위키피디아에 대해 fine-grained 지식을 요구하는 태스크로, GPT-3의 폭넓은 사전학습 분포에 대한 학습 능력을 측정하기에 적당하지 않았다고 분석하였다.
번역
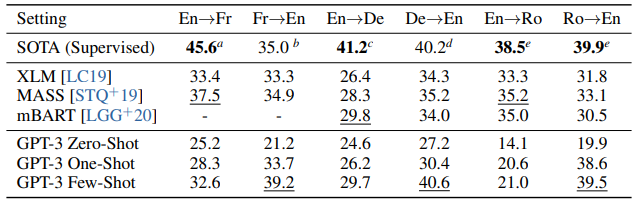
위 그림은 모델별 다양한 언어에 대한 번역 성능을 비교한 표이다. GPT-3는 Fine Tuning을 진행한 SOTA 모델에는 못미치는 성능을 보였다. 하지만 Few Shot 성능을 비교해보면 몇몇 언어에서는 SOTA 성능을 능가하는 모습도 보이고 있다.
이는 곧 GPT-3가 다양한 언어의 구조와 문맥을 잘 이해하고 있음을 의미하며, fine tuning 없이도 실시간 통역, 분서 번역, 다국어 지원 서비스 등 다양한 어플리케이션에 적용할 수 있는 수준임을 알 수 있다.
Winograd-style task
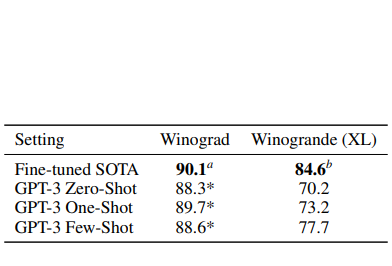
GPT-3의 성능은 Fine Tuning을 진행한 SOTA 모델에 조금 못미치는 모습을 볼 수 있으나, Fine Tuning 없이 사전 학습만으로 진행한 성능임에도 불구하고 SOTA 성능에 거의 근접한 모습을 보여주고 있다.
Common Sense Reasoning
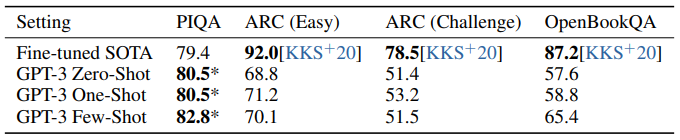
물리학이 어떻게 작동하는지 묻는 PhysicalQA(PIQA)에서는 few / zero shot 세팅에서 이미 SOTA를 넘겼지만, 분석 결과 데이터 오염 문제가 있을 수 있다고 조사하였다.
3-9학년 과학 시험 수준의 4지선다형 문제인 ARC에서는 easy와 challenge 모두 SOTA에 미치지 못하는 성적. OpenBookQA에서는 few-shot이 zero-shot setting 대비 크게 성능 향상이 있어 in-context learning을 해낸 것으로 보이나, 역시 SOTA에는 미치지 못하는 성적이었다.
기계 독해
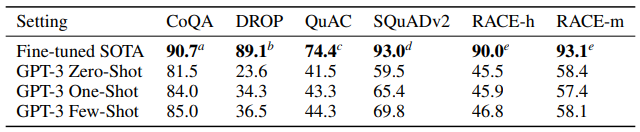
SuperGLUE
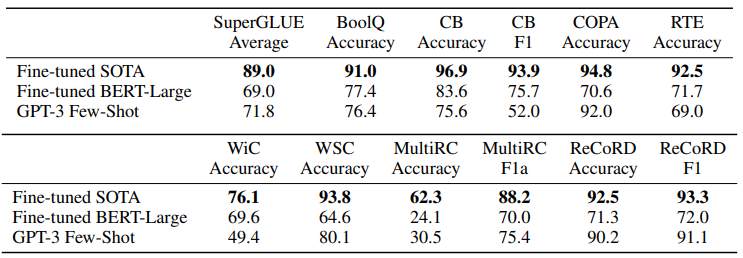
NLI (Natural Language Inference)
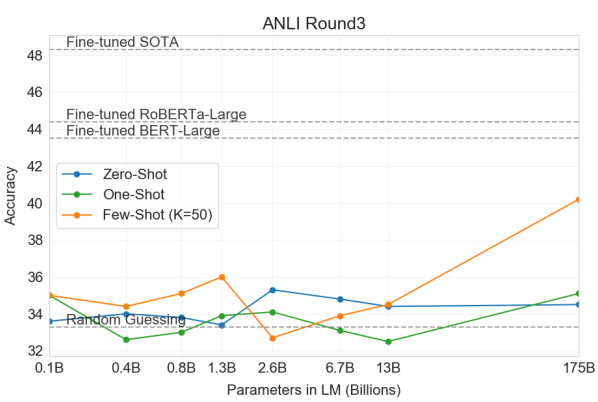
Synthetic & Qualitive Tasks
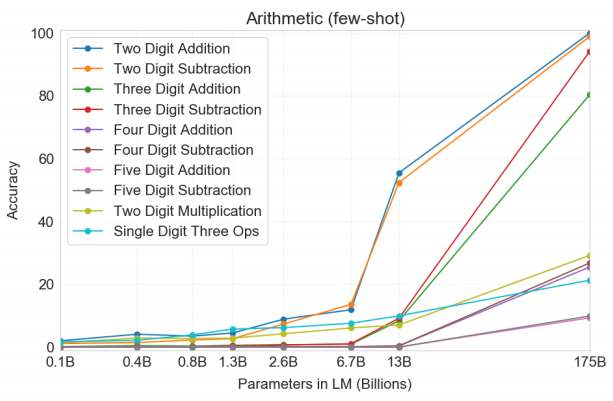

few-shot 세팅에서 두 자릿수 덧셈과 뺄셈 영역에 있어서는 175B 모델의 경우 완벽에 가까운 성능을 보였다. 하지만 4 자릿수 이상의 계산에서는 성능이 매우 떨어졌고, 복합 연산에 대해서는 21.3%밖에 되지 않는 정확도를 보여, 복잡한 계산에 대해서는 강건성이 떨어지는 것으로 나타났다.
이처럼 GPT-3은 대부분의 task들에서 SOTA를 능가하는 성능을 보여 few-shot learning의 유용성을 입증하는데 성공하였다.
Measuring and Preventing Memorization of Benchmarks
GPT-3를 학습한 사전학습 데이터는 인터넷에서 얻은 다량의 데이터이기 때문에, 벤치마크 테스트 셋에 있는 예제를 이미 참조했을 가능성이 있다. 이렇게 net scale 데이터를 사용함에 따라 발생할 수 있는 테스트 셋 오염 현상을 발견하는 것은 SOTA를 달성하는 것 이외에 중요한 연구 분야이다.
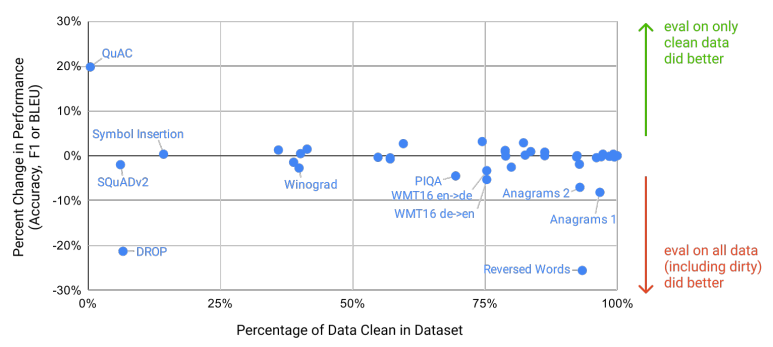
그러나 데이터 양이 너무나 방대하기 때문에 GPT-3의 175B 모델조차 훈련 데이터셋을 오버피팅하지 못하였다. 따라서 연구자들은 net scale의 사전학습 데이터를 사용함에 따라 테스트셋 오염 현상이 발생하나, 그 결과가 크지는 않을 것이라 예상했다.
사전학습 과정에 테스트 셋이 유출된 것의 영향을 평가하기 위해, 각각의 벤치마크에 대해 사전학습 데이터와 13-gram으로 오버랩되는 데이터를 삭제하는 "클린"버전의 테스트 셋을 만들어 보수적으로 모델을 평가하였다. 이후 GPT-3을 이러한 깨끗한 버전의 데이터에 대해 평가해보았을 때, 유출된 데이터에 대해 모델이 더 잘했다라는 특별한 증거는 없었다. 테스트셋 중 오염된 데이터의 비율이 높은 태스크에 대해서도 조사해 보았으나, 그것이 성능에 미치는 영향은 거의 0에 가까웠다.
Limitations
- 성능
GPT-3의 목표는 지금까지의 언어 모델들과는 달리, 그저 성능이 조금 더 좋은 언어 모델을 제작하자는 것이 아닌 ChatGPT와 같이 사람과 대화가 가능한 응용 어플리케이션을 제작하는 것이 목표이다. 그런데 몇 가지 task들에 대해서는 SOTA 모델보다 낮은 성능을 보이고 있고, 문장 생성 시에 오류가 발생할 수 있다는 점에서 분명한 한계를 갖는다고 볼 수 있다.
- 모델 구조/알고리즘적 한계
GPT 시리즈는 BERT 등과는 달리 Autoregressive 방식으로 학습하고 동작한다. 그러나 양방향적인 (bidirectional) 구조나 denoising 훈련 목적함수 등은 고려하지 않았는데, GPT-3가 잘 처리하지 못하는 task들에서 특히 위 구조를 차용한 모델들이 좋은 성능을 내는 것을 확인할 수 있었다. 즉, 보다 더 다양한 구조를 차용할 필요성이 있어 보인다.
- 본질적 한계
큰 규모의 사전학습 모델은 동영상이나 실제 물리 세상에서의 상호작용 등에서는 적용된 바가 없다. 따라서 세상에 대한 방대한 양의 context가 부족할 수 있다. 또한 현재의 목적함수는 모든 토큰에 대해 동일한 가중치를 적용하고 있고, 어떤 토큰을 예측하는 것이 더 중요한지를 반영하지 않는다. 해당 가중치 적용 방식에 대해 더 생각해볼 필요가 있다.
- 훈련 과정의 효율성
GPT-3가 실생활에 적용될 수 있으려면 굉장히 많은 양의 데이터를 봐야 한다. 따라서 사전학습 시 하나의 샘플이 모델에게 주는 정보에 대한 효율성을 높여야 한다.
- few-shot 세팅 효과의 불확실성
few-shot learning이 정말로 추론 시에 새로운 태스크를 새롭게 배우는 것인지, 아니면 훈련하는 동안 배운 태스크 중 하나를 인지해 수행해내는 것인지는 모호하다.
- 비용
GPT-3 스케일의 모델을 학습하는 것은 몹시 비싸고, 추론조차도 수행하기 쉽지 않다. 현재로써는 실용성 부분에서 점수가 낮은 모델이다.
Broader Impacts
GPT-3는 언어 모델의 발전을 통해 자동완성, 문법 교정, 게임 내 레이션 생성, 검색 엔진 성능 향상 및 질의응답과 같은 다양한 어플리케이션 개발에 기여하였다. 그러나 이러한 모델은 범죄 등에 악용될 가능성, 편향성, 학습에 필요한 에너지 소모 문제 등 다양한 문제를 야기할 수 있다.
때문에 GPT-3와 같은 언어 모델은 혁신적인 발전을 가져왔지만, 이러한 발전이 사회에 미치는 영향과 함께 잠재적인 위험에 대한 지속적인 연구와 조치가 필요할 것이다.
