C# 언어 자료형의 특징
C# 언어는 기본적으로 모든 데이터가 클래스 또는 객체로 인식이 된다.
즉, C / C++에서 다루었던 int, float와 같은 기본적인 자료형도 C#에서는 클래스로 표현이 된다.
C# 언어의 자료형 데이터는 데이터 타입에 따라 값 타입과 참조 타입, 형식에 따라 기본 데이터 형식, 복합 데이터 형식으로 구분된다.
값 형식 데이터 타입
- 값 형식 데이터 타입은 스택 메모리에 할당된다. 이는 시스템에 의해 메모리가 관리되는 것을 의미한다.
값 형식의 종류
- byte / sbyte
- int, uint, long
- float(정밀도 : 7), double (정밀도 : 15), decimal (정밀도 : 29 / 연산 느림 / 메모리 : 16Byte)
- char
- enum
- struct
- Nullable -> 값 형식이지만 null 확인이 가능한 형식
참조 형식 데이터 타입
- 실제적인 값을 스택 메모리에 할당하는 값 형식과 다르게 힙 메모리에 할당되며, 해당 메모리에 대한 참조 값을 스택에 할당하는 변수에 보관한다. 즉, 참조 형식의 데이터 타입은 가비지 컬렉션이 관리한다는 뜻이다.
참조 형식의 종류
- 참조형식은 null 대입이 가능하다. -> 오류(쓰레기값)을 방지하기 위함.
- Object
- String
- Class
- Delegate
C# 언어 변수 특징
C# 언어의 모든 클래스는 Object 클래스를 직, 간접적으로 상속하는 것이 원칙이다.
즉, 모든 클래스를 상속하기 때문에 Object 타입의 변수로 모든 데이터를 보관하는 것이 가능하다.
이 Object 타입을 다른 데이터 형식의 값으로 제어하는 것을 박싱과 언박싱이라고 한다.
- 박싱은 데이터를 보관하는 것
- 언박싱은 데이터를 읽어들이는 것
Object 타입의 변수는 기본적으로 참조 타입이며, 해당 변수에 참조 타입의 값을 보관할 때는 퍼포먼스 저하를 일으키지 않지만, 값 형식의 데이터를 보관할 떄는 이 박싱과 언박싱이 실행되기 때문에 퍼포먼스의 저하가 발생하게 된다.
값과 참조의 차이점
기본적으로 C#의 Object 타입은 모든 데이터를 가르키는 것이 가능하지만, 참조 타입에 해당되기 때문에 해당하는 타입의 변수의 값 타입 데이터를 할당하는 경우 박싱과 언박싱이 발생한다.
값 타입의 자료형은 스택에 할당되어 시스템에 의해 메모리가 관리되며, 값을 할당할 때는 복사가 발생한다.
즉, 값 자체가 복사된다는 뜻이다
참조 타입의 자료형은 힙에 할당되기 때문에 가비지 컬렉션에 의해 메모리가 관리되며, 값을 할당할 때, 참조 값을 복사한다
즉, 메모리 주소를 뜻한다
단, C# 언어의 문자열은 기본적으로 변경이 불가능하기 때문에 기본 문자열을 편집한 새로운 문자열을 얻기 위해서는 새로운 메모리 공간에 문자열을 생성하야 한다.
이는 C#에서는 한 번 할당돼 만들어진 문자열은 더 이상 편집이 불가능하다는 뜻이다
C / C++ 에서는 포인터를 활용해 접근해 원하는 문자열을 수정할 수 있지만, C#에서는 불가능하다.
Nullable 참조 타입 ?
C# 언어는 참조 타입 데이터의 유효하지 않은 여부를 null을 사용해 구분할 수 있다.
그러나 값 타입의 데이터는 null을 사용할 수 없다.
그래서 NUllable이라는 자료형 타입이 생겼으며, 해당 자료형은 값 타입에 null을 사용할 수 있도록 해주며, 값 타입의 데이터에만 사용할 수 있다.
일반적으로 값 타입 데이터에 null을 사용하면 아래와 같이 오류가 발생한다.


그러나 Nullable을 사용하면 null을 사용할 수 있다.
Nullable의 선언 방법은 다음과 같다
- 데이터 타입?
- Nullable<데이터타입>
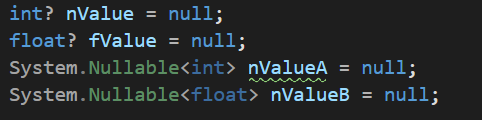
이렇게 사용하면 값 타입의 데이터에도 null을 넣을 수 있다.
