문제 상황
UT 피드백 중 무한스크롤 로딩시간이 길다는 유저의 피드백이 있었습니다. 어떻게 보면 백엔드 개발자에게 가장 치명적인 피드백이 아닐까 합니다..
초기에 검색 쿼리를 작성 했을 때는 분명 실행 속도도 100ms 내외로 완료되어 이상이 없다고 느꼈지만 게시물이 50개도 안 됐을 때 부터 속도가 느려져서 무한스크롤에 불편함을 느낀 다는 것은 말이 안 된다고 생각했습니다.
그래서 jmeter로 검색 api 속도 테스트를 진행해보기로 했습니다.
사실 jmeter는 부하테스트 용도로 많이 사용하지만 아쉽게도 이번 '너나들이' 프로젝트 기간 동안 부하테스트를 진행할 여유가 되지 않아 속도 테스트 용도로 활용해봤습니다.
(추후 부하테스트 실시 후 에러율 수정도 포스팅 해보겠습니다!)
Jmeter 테스트 환경 세팅
-
기존 50여개의 게시물이 있는 운영용 데이터베이스를 직접 테스트 하기에는 데이터 손상에 대한 우려가 있음
-> 새로운 데이터베이스를 만들어서 연결하고 더미 데이터를 생성 -
더미데이터는 기존 데이터의 6배 분량인 게시물 300개로 진행(한 키워드로 전부 검색 가능한 300개의 데이터)
-
100명의 유저가 1초안에 접속하여 검색 api를 각각 3번 호출하는 환경으로 세팅

최초에 짰던 검색 api를 우분투 서버에서 테스트 진행해보겠습니다.
api를 잠깐 설명드리면 /plans/keyword/{keyword}/{pageNumber} 로 키워드와 페이지 넘버가 동적으로 바뀌는 흐름입니다.

테스트 결과

총 샘플이 300 case가 나왔고 평균 검색 속도는 20284ms가 나왔습니다. 물론 데이터 300개 중에 '강릉'이라는 키워드를 가진 데이터가 300개(전부) 였지만 약 20초가 걸렸다는 것은 서비스 제공이 어려운 수준입니다.
이럴 땐 SQL이 어떻게 찍혔나 보는게 은근히 힌트가 될 수 있습니다.(경험상..)
충격적인 결과가 나왔습니다
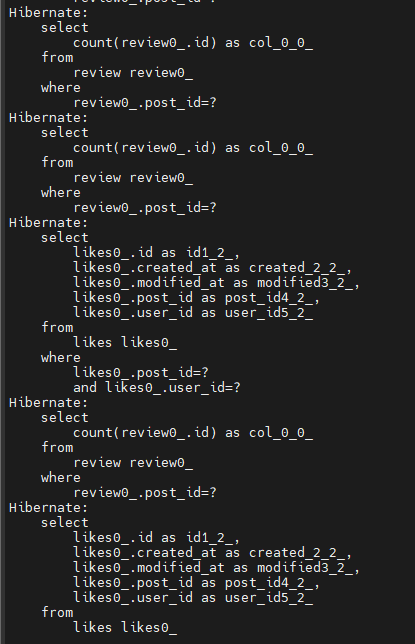
SQL이 찍힌 것을 확인해보니 댓글 수를 count하는 SQL문과 북마크 여부를 확인하기 위한 SQL문이 각각 300번 찍힌 것을 확인했습니다. 분명 페이지 요청은 1페이지, 즉 8개의 게시물만 요청했는데 300개를 풀스캔한 것입니다.
(참고로 말씀드리면 댓글수 count와, 북마크 여부는 post 엔티티 내부에 있는 칼럼 정보가 아니라서 각각 review 엔티티, like 엔티티와 연관하여 추출한 정보들입니다. 그래서 for문을 돌렸을 때 list 사이즈 대로 300번 sql문이 찍힌 것 같습니다. )
근데 분명 포스트맨으로 테스트해보고, 프론트 개발자와 협업하여 테스트해봤을 때 모두 8개씩 의도한대로 게시물이 나오긴 했었습니다.. 코드를 다시 봐야겠습니다.
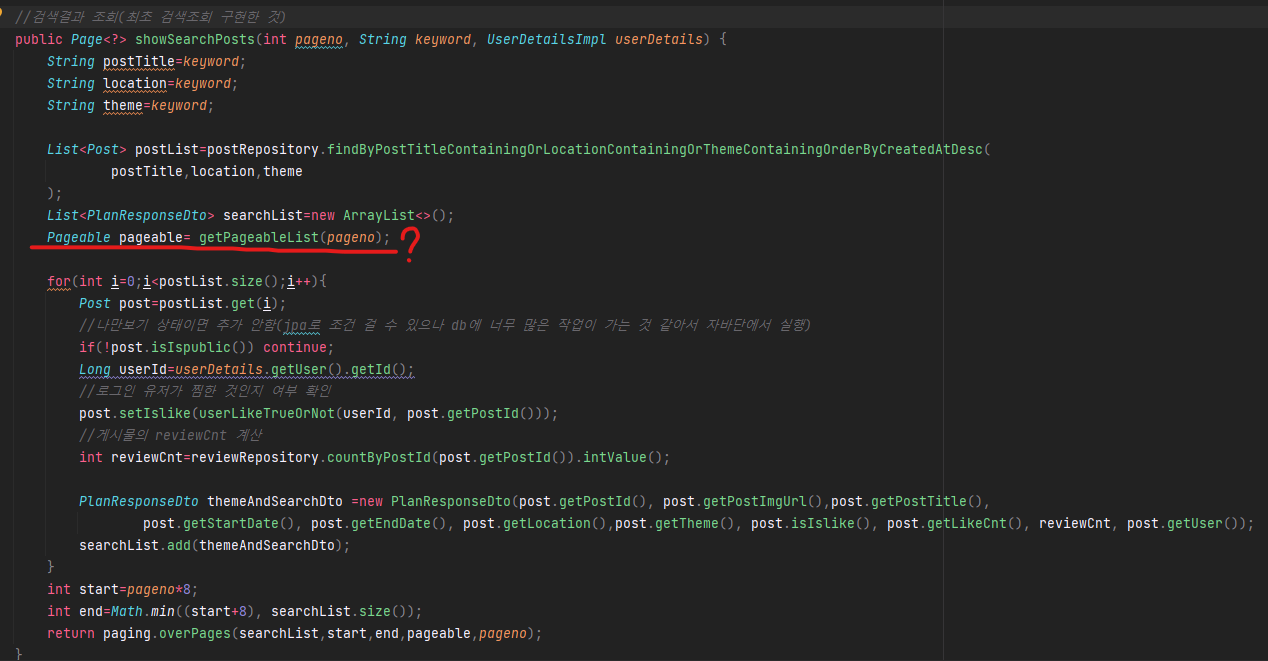
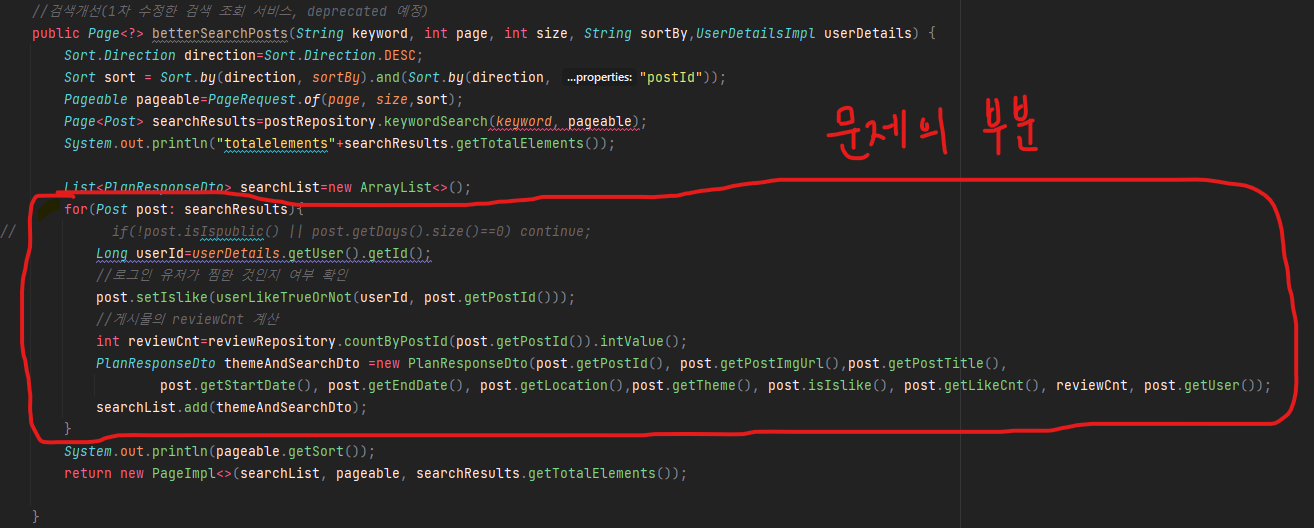
문제를 찾았습니다.
JPQL로 구현한 findBy~CreatedAtDesc() 검색 메소드를 List<>로 받는 거에서 페이징 처리가 잘 되지 않고 있다는 생각이 들었습니다.
페이징 처리의 원리가, 원하는 정보 리스트를 쭉 나열하고 그 리스트를 원하는 size로 잘라서 내보내는게 페이징의 원리라고 생각했습니다. 이러한 이유로, 위와 같이 List로 정보를 쭉 나열하고 Pageable 인터페이스를 적용하여 페이징 처리를 했던 것이었습니다.
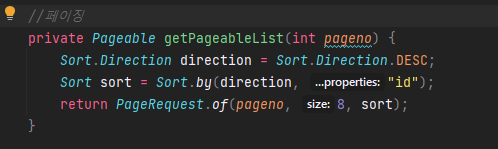
(위의 사진은 Pageable을 따로 구현한 메소드. 참고만 해주세요, 뒤에서는 저렇게 안 할 겁니다)
그래서 페이지 처리를 데이터를 불러오는 처음 부분에서 부터 8개만 불러오도록 수정할려고 합니다.
해결
이때 고민 했던 것이 바로 JPQL을 @Query 어노테이션을 이용해 페이징 할 것이냐, 새로운 기술인 Querydsl을 활용하여 페이징을 할 것이냐 였습니다.
두 기술 다 구현할 수는 있겠지만, 저는 JPQL은 단지 객체를 활용한 스트링 이라는 점에서 마음이 걸렸습니다. 즉, Querydsl 처럼 sql문을 객체지향적으로 메소드화 한 것이 아닌 그냥 sql문 처럼 문자열로 쭉 작성한 것입니다.
이는 큰 차이가 있는데, JPQL로 복잡한 쿼리를 짜게될 시 sql 문을 매우 잘 알아야 한다는 러닝커브도 존재하겠지만 무엇보다 컴파일 시 에러를 뿜지 않고 런타임에러를 발생시킨다는 점이 치명적인 요소입니다. sql문을 짜다가 오타하나로 에러가 나는 상황이어도 프로그램을 실행해서 사용하는 도중에 에러가 발견되는 것입니다.
반면 Querydsl은 spring data JPA처럼 sql문을 메소드로 만들어 놓은 것을 갖다 쓰기만 하면 되는 기술이어서, 자동완성의 혜택도 누릴 수 있었고 무엇보다 자바 언어로 돼 있어서 컴파일 시 에러를 감지할 수 있다는 점이 큰 이점으로 다가왔습니다.
결론 : Querydsl로 페이징 처리 할 것임!
Querydsl의 기본적인 의존성 주입과 세팅, 그리고 다루는 법에 대한 설명은 제외하겠습니다.(제가 문제를 어떻게 고민했고 어떻게 해결했는지를 남겨보는 글이기에.. ㅎㅎ)
-
custom 인터페이스 작성
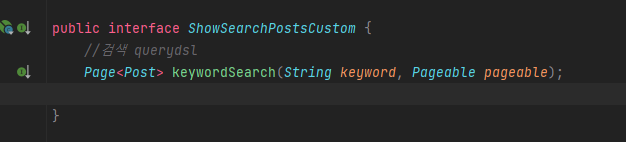
-
customImpl 클래스 작성(custom 인터페이스 구체적으로 구현)
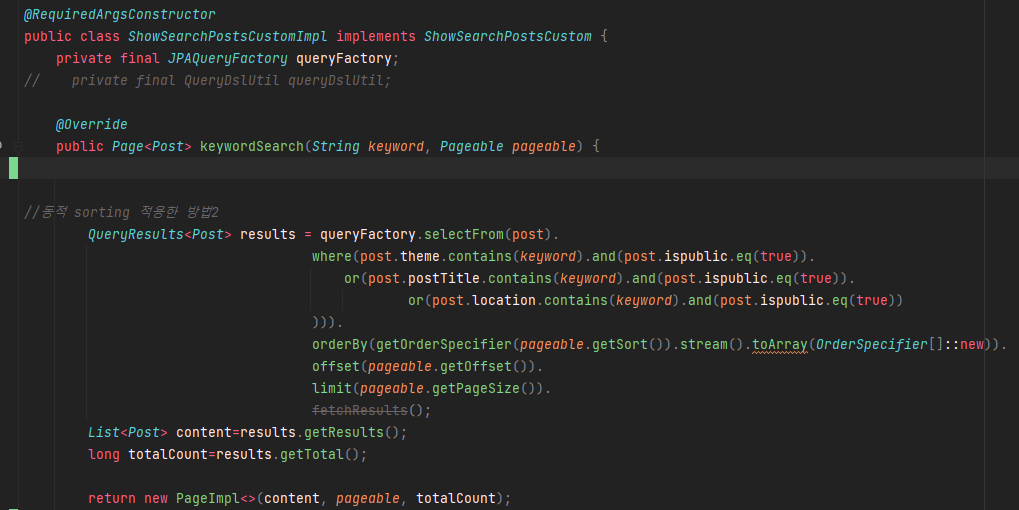
이 부분에서 offset(페이지 내 첫 게시물 인덱스, page x size)과 limit(한 페이지 사이즈)을 지정하여 애초에 스캔할 때 부터 정해진 사이즈(8개)만 스캔하도록 합니다!
orderBy 부분은 저번 포스팅에서 '동적 sorting'으로 다뤘으니 지금은 넘어가겠습니다. -
postRepository가 상속
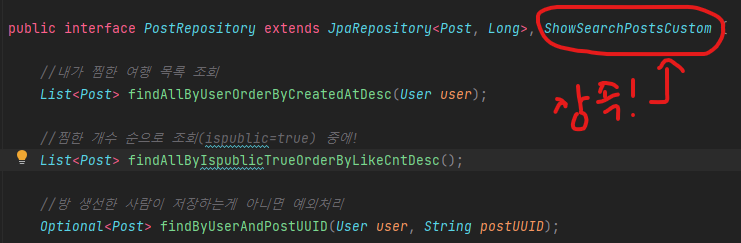
이와 같이 Querydsl을 구현하고 최초 했던 조건과 같은 조건으로 jmeter 테스트를 돌려봤습니다.
(100명의 유저가 1초안에 접속하여 검색 3번씩 실시)
테스트 결과
우선 sql 문이 찍힌 것부터 확인해보면,
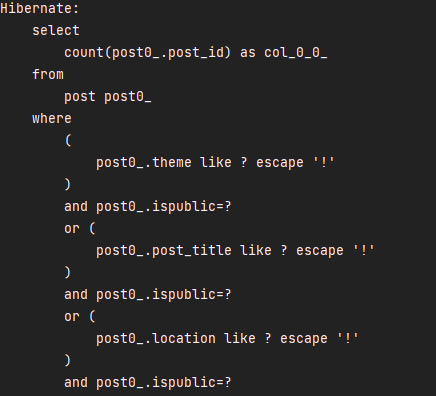
querydsl에서 페이징 처리 때 필요한 totalCount를 얻기 위해 results.getTotal()로 인해 count 쿼리 한번 호출
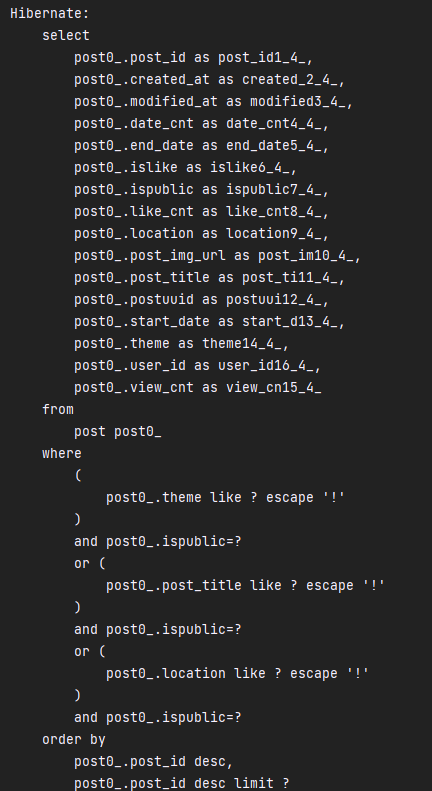
실질적으로 개발자가 작성한 querydsl이 sql 형식으로 한번 호출되는 부분.
limit이 들어가서 페이징 처리가 이뤄졌다는 것을 알 수 있습니다.
속도 개선(20284ms -> 571ms)

결과적으로 페이징 처리가 성공적으로 이루어졌고, 20초가 걸리던 검색이 0.5초로 단축된 것을 알 수 있습니다.
해결 2
페이징 처리만으로 571ms로 줄긴했지만 뭔가 Querydsl의 장점을 제대로 못 살린 느낌입니다.
현재 가장 큰 문제는 페이징 처리해서 나온 8개의 리스트에서 댓글 count와 북마크여부를 파악하기 위해 매번 8번의 추가적인 쿼리가 호출 되는 점 입니다.
그리고 그걸 원하는 출력 형태의 DTO 형식으로 맞춰주기 위해 매번 생성자를 사용하고 다시 페이징 처리 하는 것이 지저분하고 효율적으로 보이진 않습니다.
이 부분은 원하는 출력 형태의 DTO를 service단에서 다시 짜맞추는게 아니라 querydsl 레벨에서 Projections.constructor를 사용해 DTO형태로 내보내는 방식으로 해결했습니다. 이를 구현하기 위해 기본 SQL문법인 leftjoin을 잘 알아야 했습니다.
사설이지만,
Querydsl에 처음으로 도전할 땐 SQL 기본문법의 중요성에 대해 크게 걱정하지 않았습니다.
그러나 지금과 같은 문제를 해결하기 위해 leftjoin, inner join과 같은 기본문법을 공부하다 보니 정말 기본부터 알아야 응용이 쉽겠다라는 것을 다시 한 번 느꼈습니다..
다시 본론으로 돌아와서!
LeftJoin
leftJoin은 간단히 말하면 합집합의 개념으로, select~ from~ where 로 추려진 데이터 리스트(left)에 추가적인 테이블을 조건(on) 비교하여 해당되는 부분을 반영(join)하는 것 입니다.
여기서 leftJoin이 '합집합'의 개념이라는 것은 다른 테이블 정보가 join 되었을 때 조건에 맞지 않아 join이 안 되는 부분들까지도 포함해서 모두 정보가 나간다는 것입니다.
InnerJoin
만약 다른 테이블과 조건을 비교했을 때 해당되는 부분만 교집합으로 내보내고 싶다면 innerJoin을 활용하면 됩니다!!
수정된 Querydsl 코드
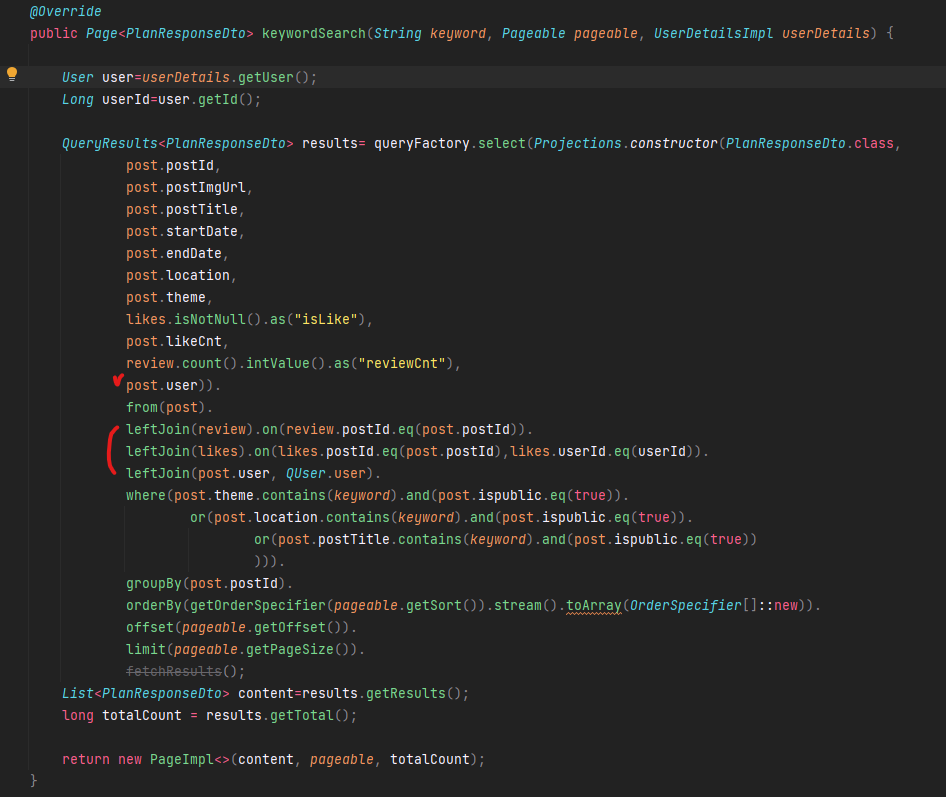
위와 같이 반환타입을 DTO로 정하고, Projections.constructor 를 활용해 dto 요소를 전부 적어줍니다. 이때 post에 멤버변수 없어서 따로 연산을 해주었던 댓글 수와 북마크 여부를 'likes.isNotNull()' 과 'review.count()'로 구현했습니다.
이를 위해 service단에서 조건으로 주던 것을 leftJoin으로 표현해야 했습니다. 그 결과 service 단의 코드도 다음과 같이 훨씬 깔끔하게 변모했습니다.
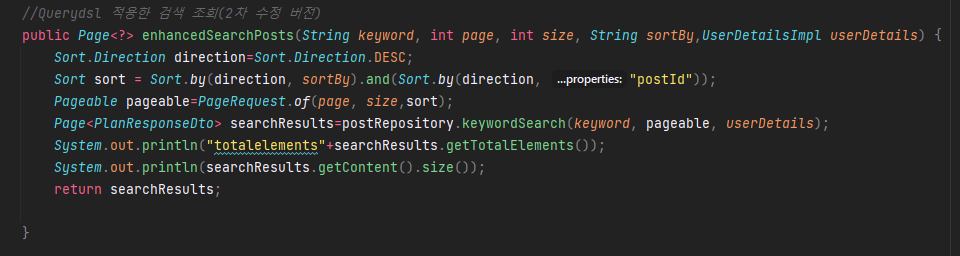
그렇다면 이 수정된 코드를 실행시키면 어떻게 쿼리가 찍히고 속도는 어떻게 변할까요?
쿼리 호출 횟수
딱 3번 호출됐습니다.
- JWT 유저 정보 인증 때문에 항상 실행되는 user 정보 조회 쿼리
- pageable 처리를 위해 totalCount 정보를 갖고오는 count 쿼리
- 앞서 설명한 leftJoin이 들어간 쿼리
2번 관련 이미지(카운트)
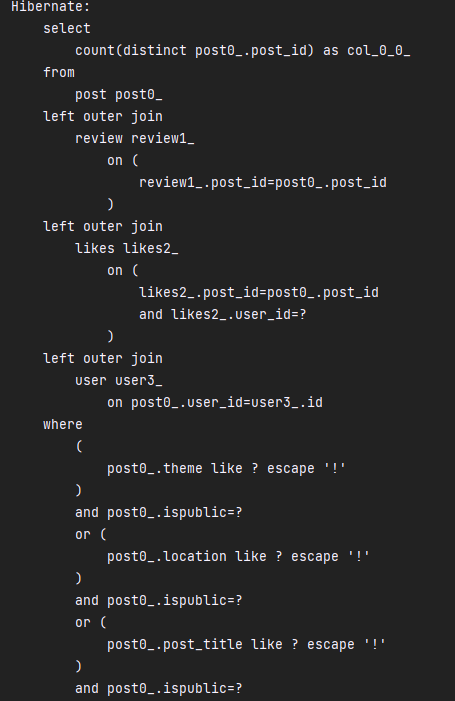
3번 관련 이미지 1/2장
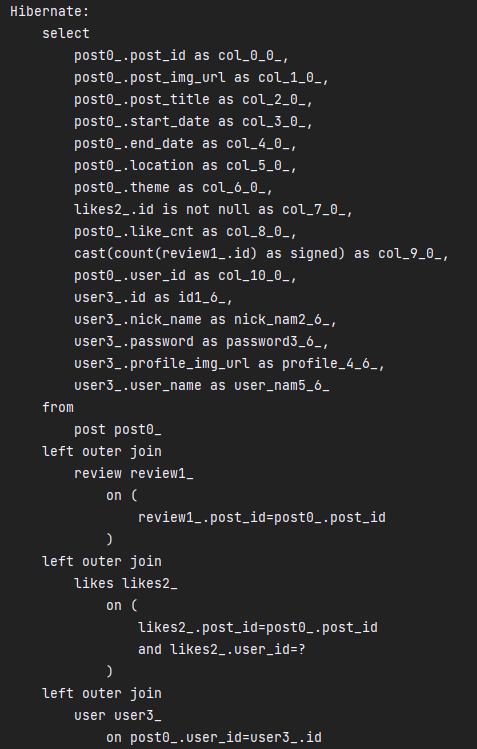
3번 관련 이미지 2/2장(1/2와 이어짐)
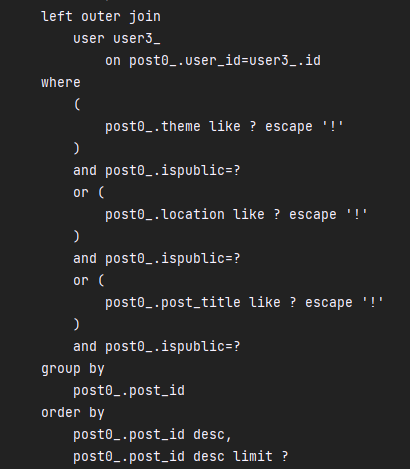
이렇게 쿼리 호출 횟수가 눈에 띄게 줄어든 것만 해도 가슴이 시원하지만 진짜 중요한 것은 성능 개선이죠.
앞선 테스트와 마찬가지의 조건으로 테스트를 진행했습니다.
(100명의 유저가 1초안에 접속하여 3번의 검색api를 호출)
테스트 결과
속도 개선(20284ms -> 571ms -> 380ms)

처음처럼 드라마틱한 개선 결과는 아니지만, 쿼리 호출횟수의 감소로 약 200ms 정도가 더욱 줄어든 것을 확인할 수 있습니다.
결론
이번 프로젝트에서 가장 재밌게 공부하고 시간을 투자했던 부분이 아닌가 합니다.
아는 만큼 보인다 라는 말이 있듯이 공부한 만큼 성능을 개선해서 좋은 프로그램을 만들 수 있다는 것을 또 한번 느꼈습니다.
물론 잘못 알고있는 부분도 있을 수 있고, Querydsl에 관하여 더욱 깊이 알아야 할 필요도 있지만, 고민과 공부를 통해 또 한번 문제를 해결하고 발전할 수 있어서 좋은 경험이었습니다!
지적과 가르침은 언제나 환영입니다! 댓글로 남겨주세요!
(SQL은 기본부터 꼭 한번 다시 공부해야겠습니다.. ㅎㅎㅎ)
.jpg)
너무 잘 읽고 갑ㄴ디ㅏ