Abstract
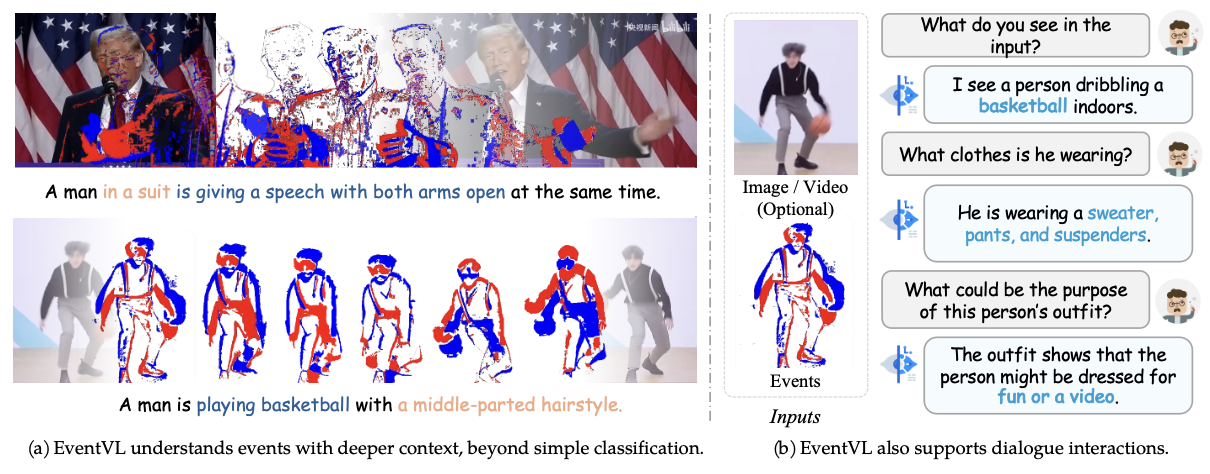
최근 Event Camera가 기존의 Camera의 단점을 보완하는 새로운 데이터로 떠오르고 있습니다. 하지만 Event 데이터를 이해하는 MLLM 모델이 존재하지 않았습니다. 이에 해당 논문에서 Event 데이터를 이해할 수 있는 MLLM 모듈인 EventVL을 제안합니다.
본 논문에서는 기존 데이터셋의 Caoption이 단순하게 설정되어 이미지(Event)의 의미론적 정보를 추출하는데 한계가 있다고 판단하여 이미지(Event)에서 의미를 추출할 수 있는 새로운 데이터셋을 구축하였습니다. 추가로 이벤트 데이터의 의미적 정보까지 추출 할 수 있는 Event Spatiotemporal Representation 을 제안하였습니다. 그리고 Event 데이터와 프레임 이미지를 정렬하기 위한 Dynamic Semantic Alignment 모듈을 제안하였습니다.
의의
Event 데이터를 이해할 수 있는 MLLM을 제안하였다. 추가로 대량의 데이터셋을 구축하여 밴치마크 데이터셋을 제공하였다.
한계점
학습에 사용된 Domain에 대해서만 높은 성능을 보여주고, 그 외의 Domain에서는 Few shot 성능이 미미하였습니다.
Data Engineering
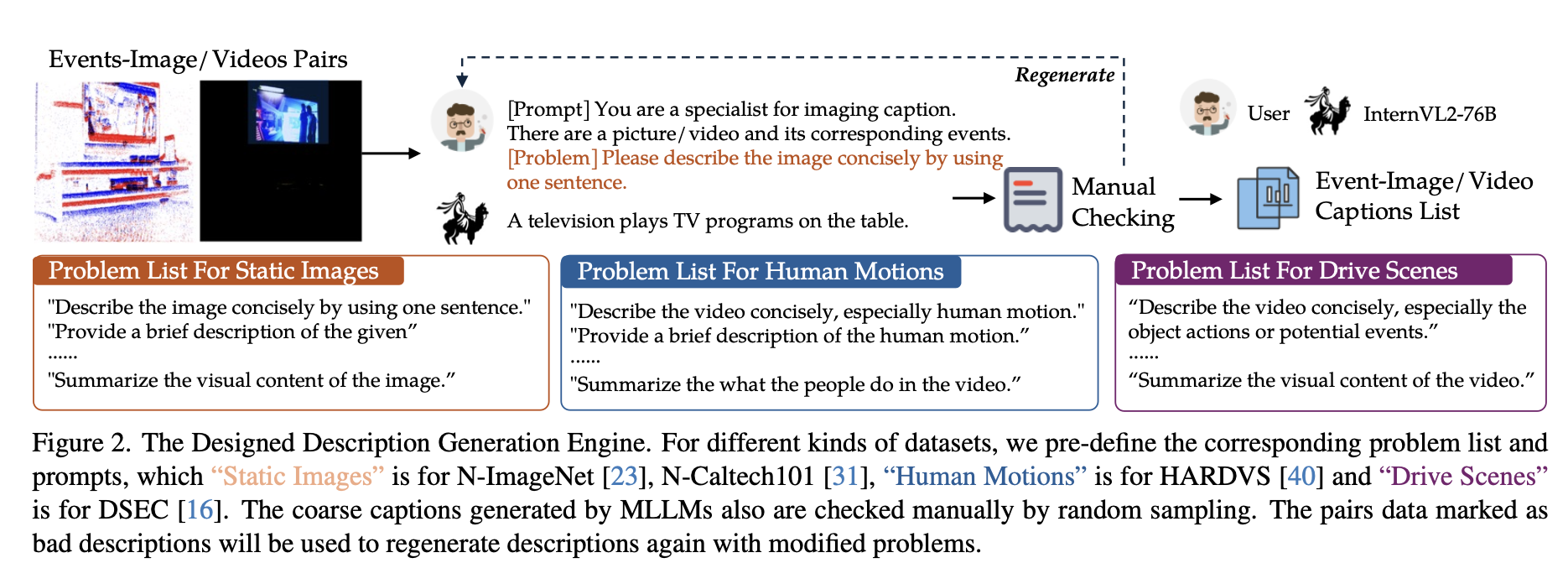
데이터를 생성하기 위해서 N-ImageNet, N-Caltech101, HARDVS, DSEC 데이터를 가져왔습니다. 그리고 사전에 질문 리스트들을 생성하였고, 랜덤으로 질문을 가져와서 ( 이미지 ( 비디오 ) , 질문 ) 을 하나의 쌍으로 만들었습니다ㅣ. 그리고 이렇게 만들어진 쌍을 open source에서 높은 성능을 낸다고 알려진 InternVL2-76 모델에 넣어서 Caption을 생성하도록 하였습니다. HARDVS, DSEC와 같은 비디오 데이터의 경우 특정 길이 만큼의 프레임을 하나의 프레임으로 묶어서 입력으로 활용하였습 니다.
그리고 데이터 품질 검사를 위해서 각각의 데이터들을 기존의 카테고리 ( ex) 리트리버, 펭귄 ) 으로 묶어서 그와 관련된 data smaple을 추출하고 검사를 진행하였습니다. 만일 caption이 잘못 된 데이터가 속해있다면, 해당 클래스의 caption을 전부 다시 생성하도록 하여 데이터의 품질을 향상시켰다고 합니다.
Methodology
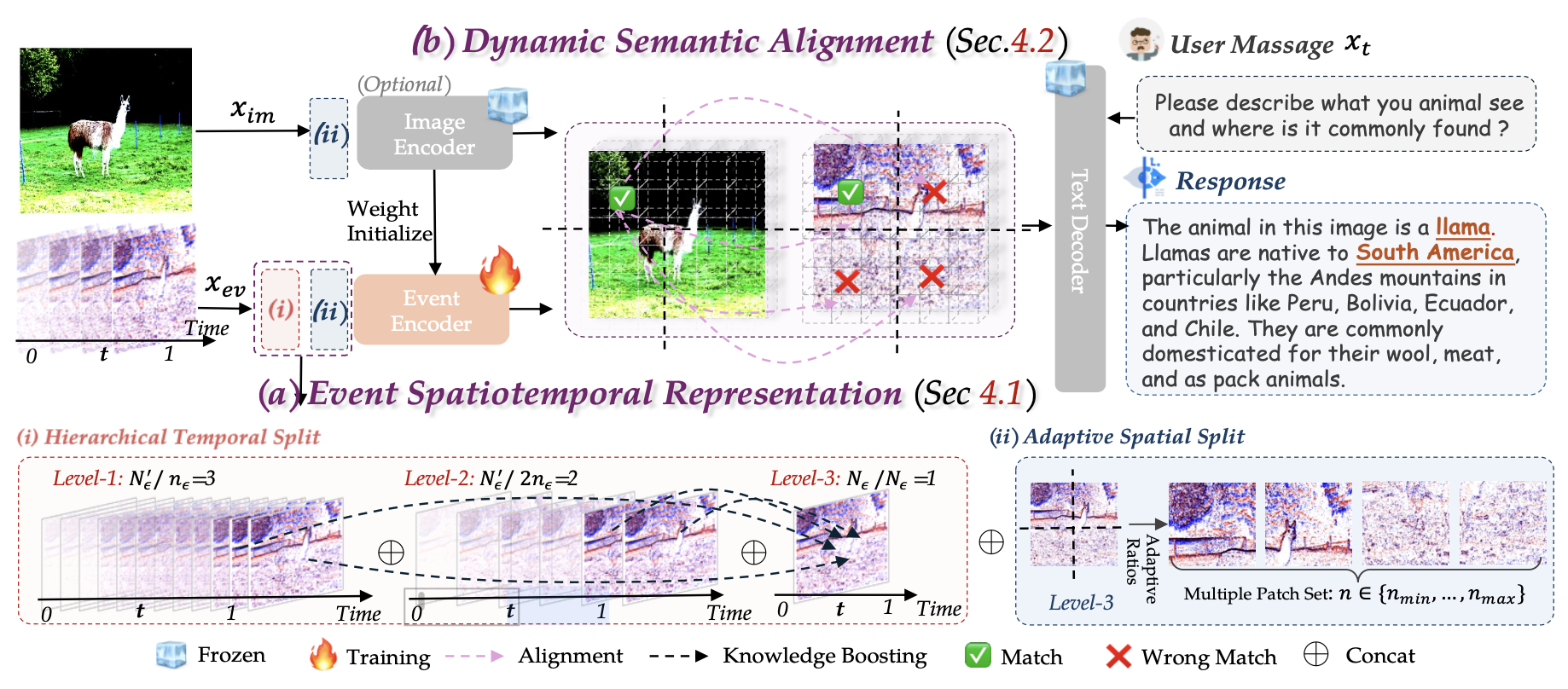
EventVL의 경우 크게 2가지 모듈을 제안합니다. (1)Event Spatiotemporal Representation (2) Dynamic Semantic Alignment
ESR의 경우 Event 데이터에서 의미론적 내용까지 추출하기 위한 표현방법을 제안하고 DSA의 경우 Event데이터와 Frame 이미지를 정렬시키는 방법을 제안합니다.
Event Spatiotemporal Represntation
ESR의 경우 2가진 단계로 구성됩니다
(1) Hierarchical Temporal Split
(2) Adaptive Spatial Split
Hierarchical Temporal Split
Event 데이터의 시간적 정보를 얻기 위해서 Event데이터를 시간 차원에서 계층적으로 그룹을 생성합니다. 총 3개의 그룹으로 구분하며 (1) 짧은 시간 간격 (2) 1번 그룹의 2배 간격 (3) 전체 프레임 길이 로 구분합니다. 즉 짧은 시간, 중간 시간, 긴 시간으로 구분된다고 합니다. 그리고 각각의 Event 데이터는 프레임 이미지 표현 형태로 변경되게 됩니다.
논문에서는 자세히 제공되고 있지 않지만 프레임 이미지 표현이라고 하면 2차원 히스토그램으로 +/- 극성을 구분해서 2차원 표현 후 마지막 차원을 단순히 0값으로 채워서 3차원 텐서로 표현하는것으로 생각됩니다
그래서 예를들어 10초의 Event 데이터가 있고, (1)은 1초당 (2)는 2초당, (3)은 10초당 프레임으로 그룹화를 진행한다면 (1) 10개, (2) 5개, (3) 1개 총 16개의 프레임이 생성되게 됩니다. 그리고 이렇게 생성된 프레임은 다음 단계인 Adaptive Spatial Split의 입력으로 사용됩니다.
Adaptive Spatial Split
해당 모듈에서는 이미지(Event) 데이터의 공간적 정보를 활용하기 위해서 이미지(Event)를 N개의 패치로 구분합니다. 이떄 단순히 240 240 크기로 리사이즈를 하게 된다면 기존의 데이터였던 N-ImageNet의(480 640 ) 데이터가 왜곡되어서 차량이 찌그러지는 문제가 발생할 수 있습니다. 그래서 사전에 정의해둔 비율중에서 (1:6 ~ 6:1까지 다양하게 구성됨 ) 원본 이미지와 가장 비율이 비슷한 비율로 그리드를 나눠줍니다. 그리고 이렇게 나눠진 그리드를 리사이즈 해서 최종적으로 224 224 크기를 만들어줍니다. 이렇게 하게되면 모든 이미지를 한번에 224 224로 변경하는 방법보다 왜곡을 줄일 수 있습니다. 예를들어서 16 : 9 크기의 비율을 갖는 이미지를 224 : 224, 즉 1 : 1로 하는것 보다, 16 : 9와 가장 비슷한 비율인 5 : 3 비율을 1 : 1로 만드는것이 더 왜곡이 적기 때문입니다.
이렇게 해서 최종적으로 Event Spatiotemporal Represntation 에서는 3개의 group, 그리고 원본이미지인 3번 group을 그리드로 나눈 N개의 패치들을 생성하고, 모두 Encoder에 들어가서 Self-Attention이 되게 됩니다. 이를 통해서 모든 데이터들이 시간적, 공간적 정보를 담는 정보로 변경되게 됩니다.
아키텍처에서 보면 Event 이미지의 경우 2개의 단계를 모두 거치게 되고, 이미지 데이터의 경우 2번 단계만 거친 후 각각의 Encoder에 들어가게 됩니다.
Dyanmic Semantic Alignment
해당 모듈의 경우 이벤트 데이터와 이미지 데이터를 정렬시키기 위한 모듈입니다. 그래서 패치, 짧은 시간 단위를 쓰는게 아니라 위에서 모든 정보들이 담겨진 3번째 group과 이미지 데이터를 직접적으로 정렬시킵니다. 이때 event데이터에서는 feature map, 패치들이 존재하고 Image 데이터 또한 동일하게 Encoder를 지나서 N개의 패치와 feature map이 생성됩니다.
이렇게 각각 매칭이 되는 데이터들을 cosine sim을 사용하여 loss를 계산하게 됩니다. 즉 단순히 cosine sim을 적용해서 event 데이터에 이미지 데이터의 색상, 질감 정보를 갖도록 유도할 수 있게 됩니다.
Framework Optimization
이후 최종적으로 Loss는 아래와 같은 손실을 사용하게 됩니다.
의 경우 다음과 같이 이벤트 데이터와 질문이 들어왔을때 -log loss를 의미합니다.
그리고 event데이터에는 색상과 질감에 대한 표현이 부족하기 때문에 보조 손실로써
다음고 같이 이미지 데이터를 사용하게 됩니다.
그리고 이렇게 2개의 instruction loss와 (이미지-이벤트) cosine sim loss를 더해서 최종적인 loss가 되게 됩니다.
Experiments

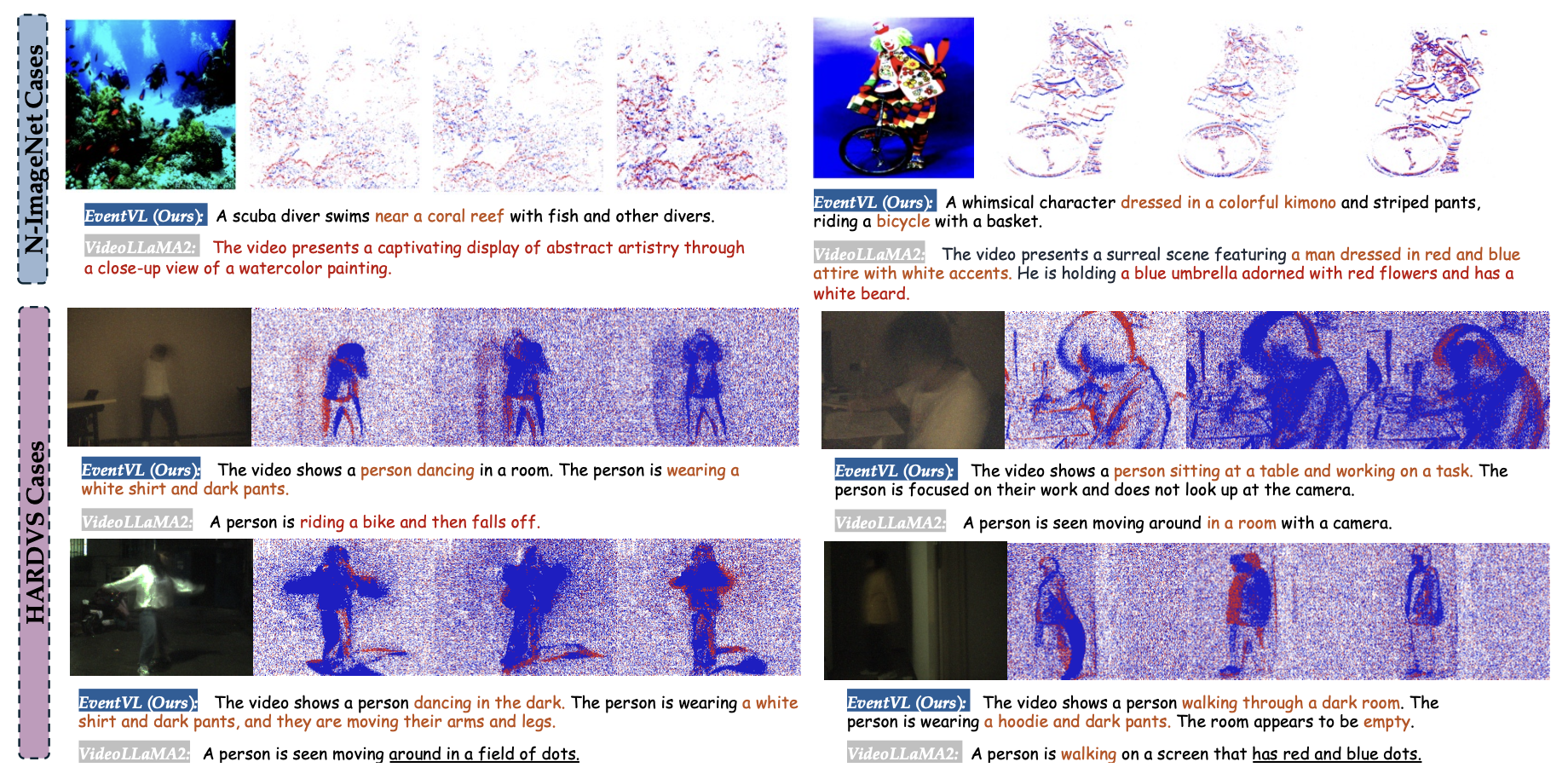
다음 표와 같이 기존의 MLLM은 이벤트 데이터를 이해하지 못하엿지만 EventVL의 경우 이벤트 데이터에 대해서 가장 높은 성능을 보여주었습니다.
Conclusion
해당 논문의 경우 Event 데이터를 이애할 수 있는 MLLM 모델을 제안하여 Event 데이터에 대한 추론이 가능해졌습니다. 추가로 이를 학습할 수 있는 데이터셋을 제공하여 새로운 밴치마크 데이터셋을 제공하였습니다. 파라미터가 적어 효율적이지만, 적은 파라미터로 인해 학습한 데이터에 대해서만 높은 성능을 보이며, Few shot의 경우 한게가 드러났습니다.
