NeRF의 경우 연속적인 장면을 5개의 자표로 표현합니다. ( x,y,z) 우리가 보고싶어하면 3D 상의 특정 좌표를 의미합니다. ( ) 에서 의 경우 Z 축에서 얼마나 기울어졌는지, 그리고 의 경우 (x,y) 평면에서 얼마나 기울어졌는지를 의미합니다.
그리고 해당 논문에서는 X = (x,y,z), d = ( )로 표현합니다. 해당 논문에서 제안하는 NeRF 모델의 경우 이렇게 3개의 좌표와 2개의 값을 입력으로 받아서 c, 를 출력으로 합니다. 여기서 C의 경우 해당 좌표의 색상을 의미하며 의 경우 밀도를 의미합니다.
NeRF의 경우 3D 장면을 구름처럼 보게됩니다. 그래서 각 카메라에서 광선을 쏘고, 해당 광선이 물체를 투과하여 그 속의 정보까지 파악할 수 있음을 가정하고 이해해야합니다. 그래서 밀도가 높은 곳은 특정 물체가 존재함을 의미하며 밀도가 낮은 곳은 빈공간을 의미하게 됩니다.
그리고 의 경우 단순히 (x,y,z) 좌표 값만 활용하게 됩니다. 이는 어디에서 보든지 항상 동일한 밀도를 가지고 있어야 하기 때문입니다. 하지만 C의 경우 어느 방향에서 보는지에 따라서 표면의 성질이나 햇빛 등에 의해서 달라질 수 있습니다. 그래서 C ( emitted color ) 의 경우 (x,y,z)와 ( ) 을 모두 사용한다고 합니다.
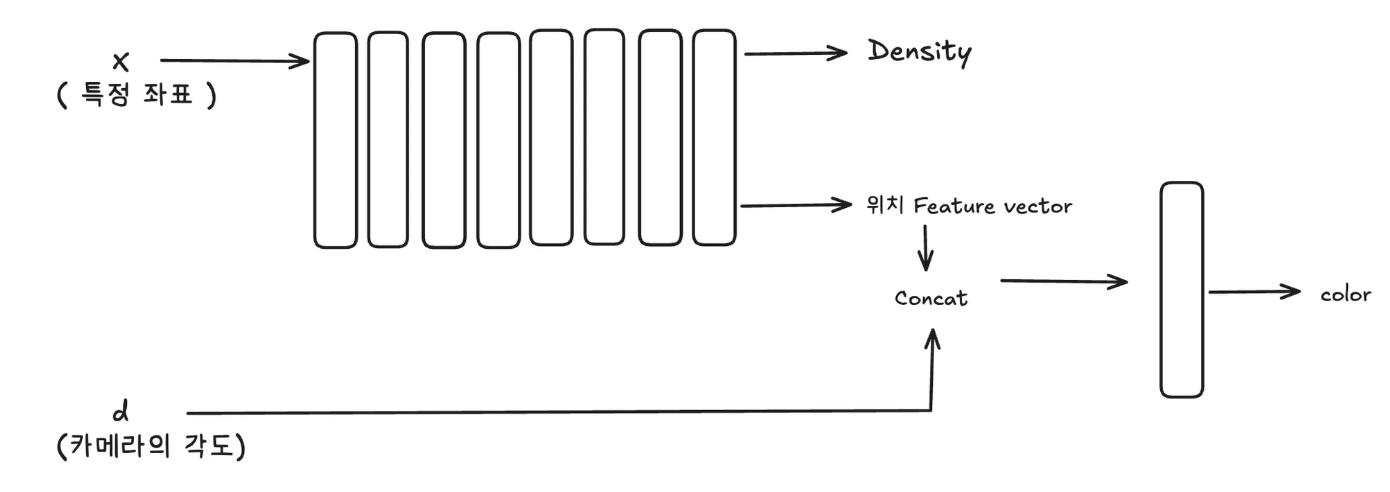
NeRF 논문에서 제안하는 최종 모델은 위와 같이 표현할 수 있습니다.
처음에는 3개의 좌표만 8개의 FC Layer에 들어가게 됩니다. 이를 통해서 밀도와 위치를 임베딩한 Feature Vector를 얻게 됩니다. 이렇게 얻어진 Feature Vector는 카메라 각도인 d ( 와 결합되어 다시 한번 1개의 FC Layer를 통과하여 최종 색상을 예측하게 됩니다.
NeRF는 무엇을 학습하는가?
NeRF의 경우 신경망 가중치에 3D 좌표에 대한 색상과 밀도에 대한 정보를 저장하는 방법이라고 생각합니다. 즉, 특정 (x,y,z)에 대한 밀도와 색상을 예측하도록 학습 시키는게 NeRF 기술입니다.
그래서 학습시에 각 이미지에서 특정 (x,y,z)를 샘플링 합니다. 그리고 해당 좌표가 속할 수 있는 광선을 고르게 됩니다. ( 해당 좌표를 볼 수 있는 카메라의 각도 )
NeRF에서 (x,y,z)의 좌표는 무한한가?
NeRF 에서 (x,y,z)는 유한하기 때문에 특정 상자안에 갇힌 3D를 복원하는것과 비슷합니다.
만일 카메라가 엄청 멀리서 찍은 사진과 가까에서 찍은 사진이 존재한다면 NeRF에서는 샘플링을 뛰엄 뛰엄 진행하여 우선적으로 중요한 (x,y,z) 영역을 찾아내고, 해당 영역을 한게로 지정한 후 해당 영역에 대해서만 집중적으로 학습한다고 합니다.
학습 과정은 ?
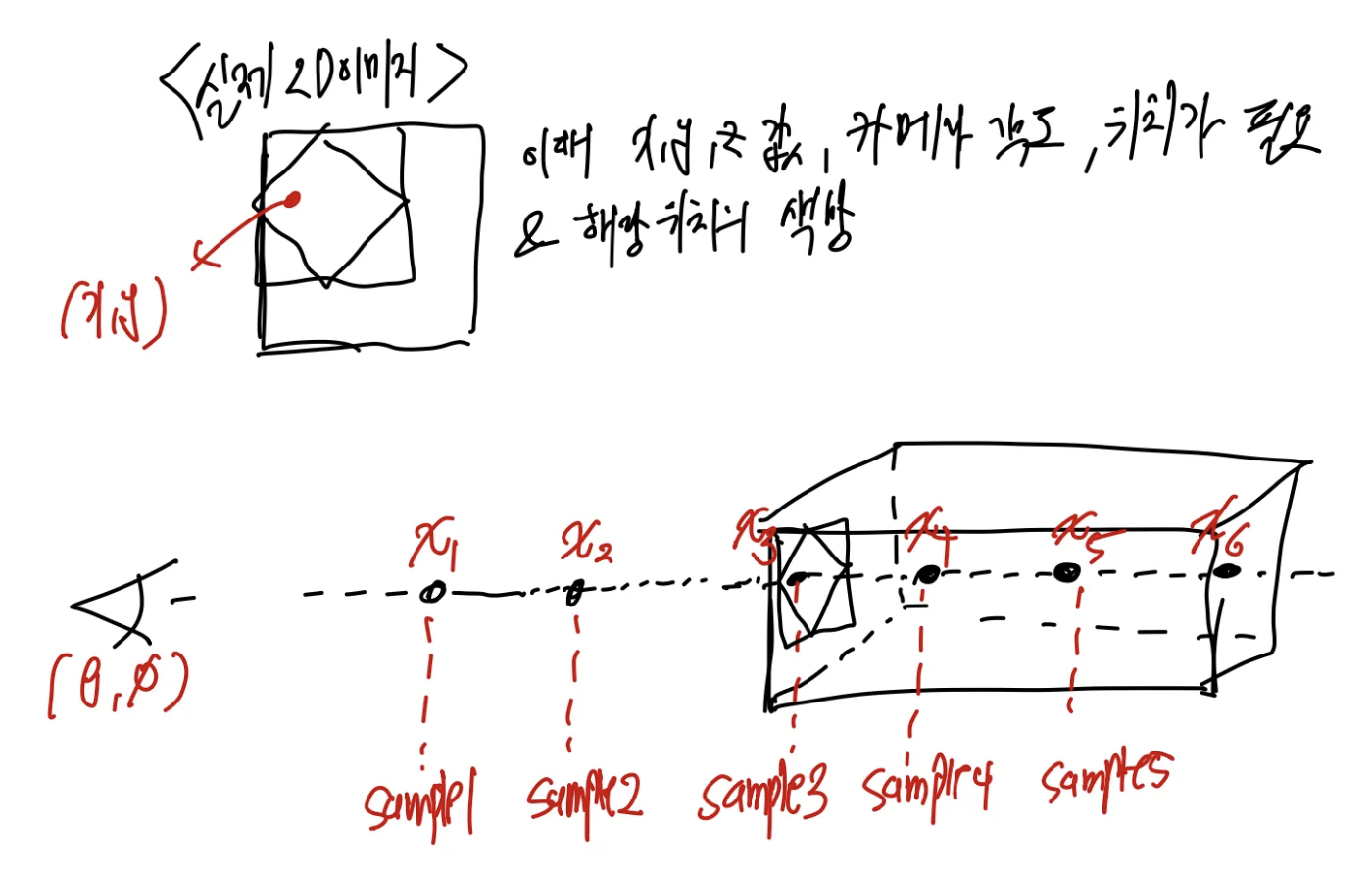
다음과 같이 N개의 2D 이미지 중에서 M개 ( N > M ) 개를 무작위로 선택합니다. 그리고 선택된 이미지에서도 무작위로 픽셀좌표 (x,y)를 추출합니다. 이떄 해당 이미지를 찍은 카메라의 ( 3D 좌표, 해당 픽셀의 색상, 카메라 각도 ) 를 추출하게 됩니다. 이렇게 M개의 정보가 추출되면 3D에서 광선을 쏠 수 있는 벡터를 구할 수 있게 됩니다. 그렇면 아래 그림처럼 해당 광선에서 K개를 샘플링하게 됩니다. 이렇게 샘플링된 좌표와 카메라의 각도는 NeRF 모델의 입력이 되게 됩니다. 그리고 모델의 각각의 좌표에 대해서 밀도와 색상을 예측하게 되고, 예측된 밀도와 색상은 랜더링 수식에 의해서 최종적으로 하나 색상을 출력하게 됩니다. ( 밀도를 출력하는 이유는 랜덩링 수식에서 색상을 결정할때 단순히 가중치의 역할을 수행하기 위함입니다. 그래서 NeRF는 결국 “색상”만 에측하게 되면 자연스럽게 밀도까지 학습하게 되는 방법을 활용하는것이 신기하였습니다 )
볼륨 랜더링 수식
[ i 번째 샘플의 투명도를 의미 ]
의 경우 MLP의 예측 밀도, 의 경우 i+1과의 거리 ( 샘플링 간격 ) 을 의미합니다.
[ 투과율 ]
1번 부터 지금까지의 투명도 * 간격들응ㄹ 모두 더해서 투과율을 게산합니다. 투과율의 경우 뒤로갈수록, 그리고 투명도가 낮을 수록 점점 0에 가까워집니다. T = 0 인경우 불투명해서 더이상 투과할 빛이 없게 됩니다.
위와 같은 공식을 통해서 최종적으로 (x,y,z)에서 어떤 색상을 갖는지 출력하게 됩니다.
+) 추가적으로 성능 향상을 위해서 positional encoding 과 계층적 샘플링을 적용하였다고 합니다.
최종 정리
NeRF의 경우 하나의 물체에 대해서 여러 각도에서 찍은 2D 이미지를 통해서 3D 이미지로 복원하는 기술을 의미합니다. 이때 객체 자체를 밀도가 있는 어떤 구름처럼 생각하여 밀도를 통해서 최종 색상을 결정하는 학습 방법을 가지고 있습니다.

