Abstract
본 논문에서는 HRFormer라는 모델을 제안합니다. ViT 모델들처럼 이미지를 저해상도로 만들고, 높은 게산 비용을 요구하는 방법과는 대조적이라고 주장합니다.
HRFormer는 HRNet의 다중 스케일 병렬적 처리 방법과 local-window self attention 을 활용하여 메모리와 연산 효율을 개선한다고 주장합니다. 추가로 FFN 내부에 Convolution 연산을 도입하여 서로 연결되지 않는 윈도우 간의 정보 교환이 가능하도록 설계하였다고 합니다. 이를 통해서 인간 자세 추정과 시맨틱 세분화 분야에서 적은 파라미터로 높은 성능을 달성했다고 주장합니다.
Introduction
최근 ViT 모델이 ImageNet에서 높은 성능을 달성하였고, 이에 지식증류, 깊은 아키텍처 등등 다양한 분야에서 ViT를 사용하고자 많은 연구들이 진행되었습니다. 그리고 객체 탐지, 세분화 등 다양한 분야에서도 높은 성능을 달성할 수 있음을 증명하였습니다. 본 논문에서는 그 중 자세 추정과 세분화에 집중을 하고 있다고 합니다.
ViT는 이미지를 그리드로 세분화 하여 각 그리드의 특징을 추출하는 방식으로 작동하기에 이미지 전체적인 공간정보를 잃는다고 주장합니다. 그리고 추가로 단일 이미지만 사용하게 되면 스케일 변화에 대응하지 못한다고 합니다. 이에 본 논문에서는 공간정보를 잃지 않으면서도 다중 스케일의 정보를 활용하는 HRFormer를 제안한다고 합니다.
HRFormer는 HRNet에서 최택된 멀티 해상도 병렬 설계를 따르는 방식으로 구축된다고 합니다. 그리고 초기 이미지 특징 추출에는 convolution 방법이 보다 높은 성능을 달성한다는 실험 결과를 토대로 stem과 stage1은 모두 convolution 을 사용한다고 합니다. 그리고 다중 스케일을 병렬로 처리하여 고해상도 이미지의 표현을 보강해주는 역할을 하며 각 스케일을 융합하는 attnetion을 통해서 서로 다른 스케일의 특징맵을 잘 융합한다고 합니다.
그리고 각 해상도에서 연산량을 줄이기 위해서 local window self atention 매커니즘을 도입하여 메모리를 줄였다고 합니다. 각 표현맵을 겹치지 않는 작은 이미지 윈도우들로 나누고, 각 윈도우를 개별적으로 self attention을 하고, 이 들의 정보를 섞기 위해서 FFN 내부에 CONV를 추가하여 사용하였다고 합니다.
이러한 모델은 다양한 밴치마크 데이터셋에서 적은 파라미터로 높은 성능을 보여주었다고 주장합니다.
정리 :
HRNet과 유사하지만 아래와 같은 부분이 다른것 같다
(1) fusion 방식이 단순 합이 아닌 attention을 활용
(2) 초기 부분을 제외하고 HRFormer는 모두 transformer 기반이다
(3) conv + Transformer를 섞어서 사용한다
그리고 고해상도 이미지는 그대로 유지하고, 저해상도 이미지로 부터 얻은 고차원의 특징은 단순히 고해상도 특징을 보조한다는 점이 비슷한 컨셉을 가지고 있는 듯 하다.
High-Resolution Transformer
Multi-resolution parallel transformer
HRFormer의 경우 HRNet의 병렬 처리 방법을 그대로 사용합니다. Stem과 초기 단게에서는 Transformer 블럭보다 convolution 블럭의 효과가 좋다고 하여 처기에는 HRnNet과 동일한 구조를 가지며, 이후의 블럭에 대해 특징을 추출하는 경우 Convolutional 블럭이 아닌 Tranformer 블럭을 사용합니다. 그리고 서로 다른 스케일의 정보를 융합하는 경우에는 convolutional 모듈을 통해서 융합한다고 합니다.
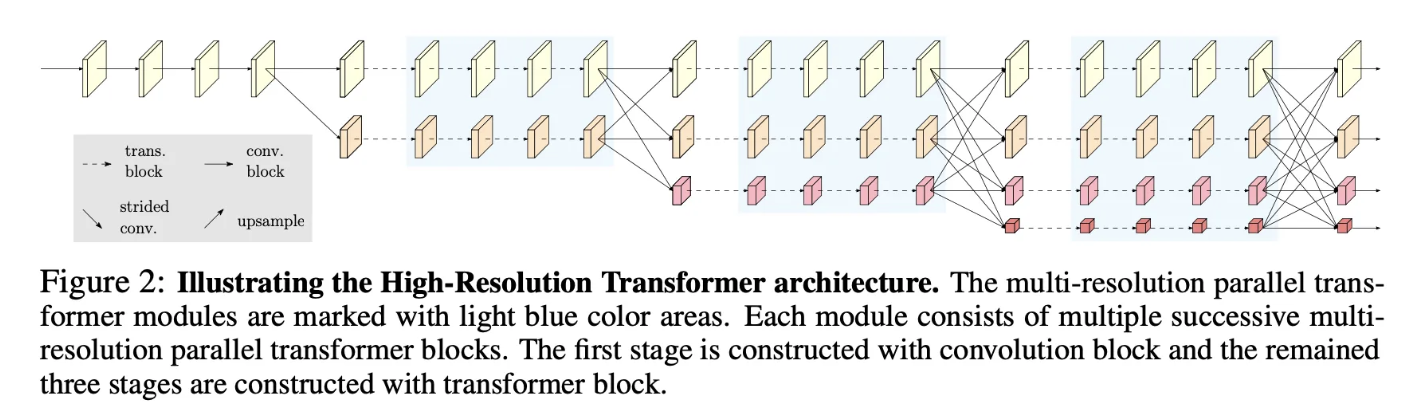
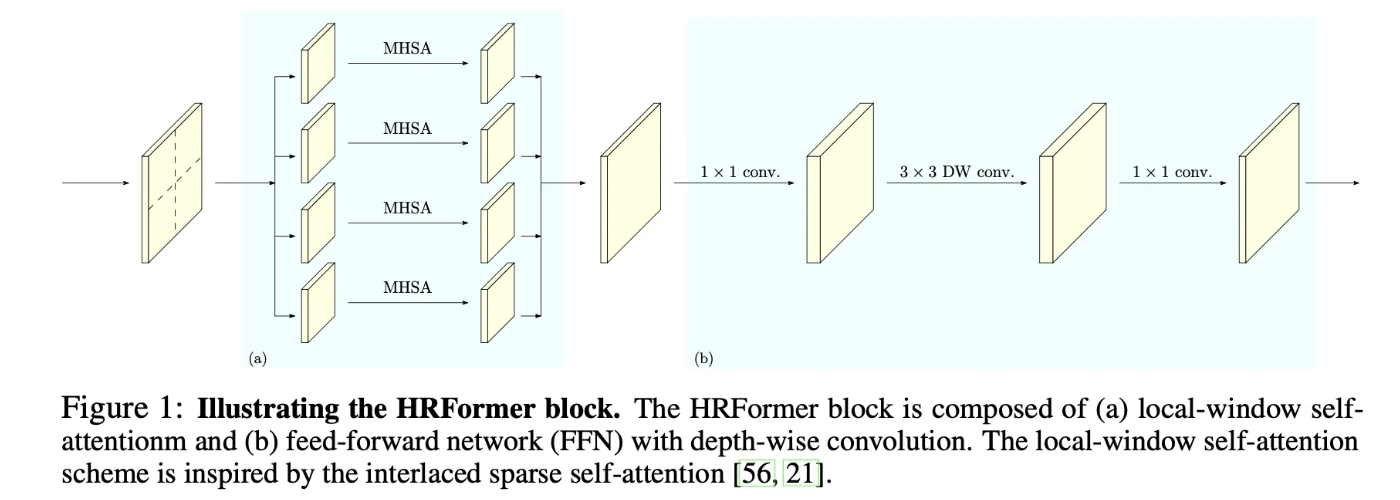
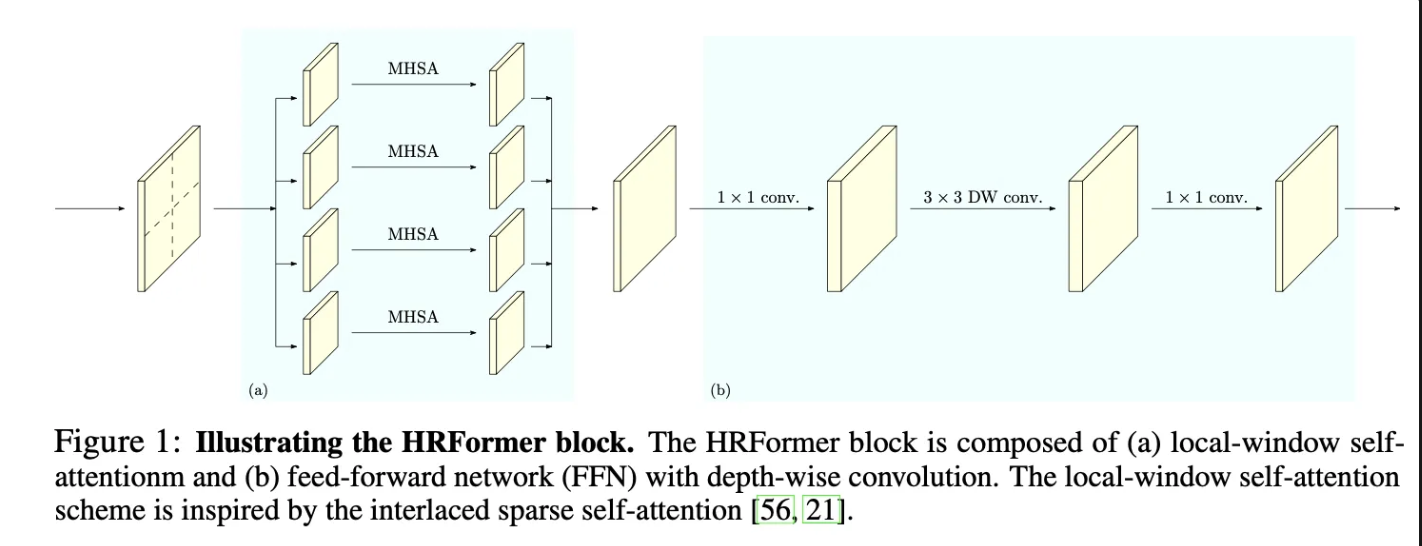
전반적인 구조는 Figure2를 따르고, 자세한 각 블럭의 동작 방식은 Figure1을 따른다고 합니다.
Local-window self-attention
본 논문에서는 연산의 효율성을 위해서 겹치지 않도록 feature map을 나누어 작은 패치로 나누게 됩니다. 그리고 각 패치는 독립적으로 Multi Head self attention을 진행하게 됩니다. 이를 식으로 표현하면 아래와 같이 표현할 수 있습니다.

다음과 같이 각각 겹치지 않는 윈도루를 만들고, 각각에 대해서 병렬적으로 self attention을 취하고 이를 concat하게 됩니다.
FFN with depth-wise convolution
그리고 이후 FFN을 거치게 되는데, 이때 겹치지 않게 패치를 나눴기 때문에 공간적으로 독립성이 존재합니다. 그래서 이를 보존하기 위해서 Depth wise conv와 1 * 1 conv를 동시에 사용함으로써 메모리 효율을 증가시키면서도 채널별 독집적으로 공간정보를 학습할 수 있도록 유도합니다.
Representation head desing
HRFormer는 Figure2처럼 총 4개의 서로 다른 해상도를 갖도록 구성됩니다. 그리고 각 Task마다 최종적으로 서로 다른 구조를 통해서 결과를 얻습니다. Classification의 경우 bottleneck → GAP를 사용하여 결과를 도출하고, Pose estimation의 경우 고해상도 이미지에 대해 1 * 1 conv를 취하고 Heatmap을 얻어 이를 통해서 좌표를 예측하게 됩니다. 그리고 Segmentation의 경우 모든 해상도를 고해상도로 upsampling하여 합쳐서 사용한다고 합니다.
이를 통해서 간단한 구조임에도 불구하고 각 테스크에 대해 높은 성능을 달성 할 수 있었다고 합니다.
정리
HRFormer는 ViT의 성능을 활용하기 위해서 HRNet 모델에 ViT를 적용한 모델입니다. 당시에도 여전히 ViT를 쓰더라도 이미지의 해상도를 줄인다는 문제가 발생 ( 고해상도 이미지의 공간적 정보를 손실한다 ) . 이에 초반에는 bottleNeck을 사용하는 HRNet과 동일하지만 2stage부터는 bottleNeck 대신 local self attention 기반 HRFormer block을 사용함으로써 이미지 정보를 보다 잘 추출할 수 있도록 수정하였습니다. 그리고 local self attention 의 문제점을 보완하기 위해서 FFN에 3 * 3 Depth wise conv를 추가하는 아이디어를 제안하였습니다. 이를 통해서 여러 테스크에서 간단한 모델로 부터 높은 성능을 달성할 수 있었습니다.
내생각
HRNet의 아이디어를 그대로 사용하면서 초기에는 conv, 후반에는 ViT를 쓰는 구조가 좋은 것 같다. 그리고 knowledge distillation 처럼 뭔가 conv와 vit를 변경하는 시점도 문제의 난이도, 모델의 크기, 심지어 각 해상도 마다 vit, conv중 더 적합한 방법이 다를수도 있다고 생각한다. 나중에 기회가 된다면 conv층과 vit 층 구분 방법과 해상도별 conv,vit 를 구분해서 성능향상이 될수 있는지 실험해보고 싶다.

대 승 민