[ 논문 리뷰 ] PPT : token-Pruned Pose Transformer for monocular and multi-view human pose estimation
논문리뷰
Abstract
최근 ViT의 발전으로 이미지 패치를 토큰으로 간주함으로써 트랜스포머는 전체 이미지 혹은 다른 뷰의 이미지들 간의 걸친 전역 의존성을 모델링할 수 있게 되었습니다. 그러나 전역 어텐션의 경우 연산량이 많아 고해상도 이미지에 적용하기에는 아직 무리가 있습니다. 그래서 본 논문에서는 2D 인간 포즈 추정을 위해 Token-Pruned Pose Trnaformer, PPT를 제안합니다. PPT는 대략적인 인간의 위치를 마스크로 설정하고, 해당 마스크의 영역에 대해서만 self-attention을 수행하며 연산량을 줄일 수 있습니다 . 또한 다중 뷰 인간 포즈 추정에도 확장하여 ‘huamn area fusion’기술을 사용하여 효과적으로 여러 뷰의 정보를 융합하였습니다.
Introduction
ViT 모델의 성능을 발휘 하면서 메모리 효율성을 위해서 사람의 위치를 추정후, 해당 위치에 대해서만 attention을 진행하는 PPT를 제안하였습니다.
최근 자세 추정 분야에서 CNN 모델이 지배적으로 사용되어왔습니다. 하지만 단일 카메라를 활용한 CNN 모델들은 관절이 가려지거나, 왜곡 된 경우 제대로 학습을 할 수 없다는 문제가 있었습니다. 그래서 최근에는 다중 뷰를 활용한 연구들이 진행되었습니다. 하지만 다중 뷰를 사용하더라도 CNN 기반의 모델의 경우 수용영역이 Kerenl size로 한정되어 있기에 전체적인 장거리 의존성을 파악하는데 제한이 있다고 주장합니다.
최근 ViT와 같은 Transformer 기반의 모델들은 전역 의존성을 손쉽게 모델링 할 수 있습니다. 자세 추정 분야에서도 여러 연구에서 Transformer 기반의 전역 의존성을 강조하는 모델들이 제안되어왔습니다.

다중 뷰 자세 추정은 TransFusion이 현재 뷰와 기준 뷰 양쪽의 정보를 Transformer로 융합합니다. 이러한 연구들은 주로 1D 토큰 시퀀스로 펼친 후 아주 긴 시퀀스를 입력으로 사용하였기에, 고해상도 이미지에 적용하기에는 다소 어려웠습니다. 하지만 실험적으로 확인 결과, 관절에 대한 attention map은 매우 희소하며, 몸통이나 관절 영역에만 집중된 다는 것을 확인할 수 있었습니다. (FIg2가 이를 증명하는 시각 자료이다 )
이는 사람 관절 간 제약이 주로 인접하고 대칭이기 떄문이라고 주장합니다. 이는 결곽 이미지의 모든 위치에 대해 attention을 수행하는 것은 모델을 복잡하게만 만든다는 것을 시사한다고 주장합니다.
그래서 본 논문에서는 자세 추정에서 사용하는 전역 어텐션을 대체하는, 효율적인 방법인 Token-pruning pose transformer를 제안합니다. 구체적으로 어텐션 맵을 활용하여 사람 신체 토큰을 골라내고, 이에 해당 하지 않는 토큰들은 모두 제거합니다 ( 배경 제거 ). 이러한 과정을 통해서 유용하지 않은 토큰을 제거함으로 써 모델을 경량화 할 수 있습니다. 추가적으로 PPT 모델은 추가 annotation 없이도 대략적인 사람 마스크를 스스로 예측해 낼 수 있다고 합니다.
추가적으로 본 논문에는 PPT 모델을 다중 뷰 환경으로 확장한다고 합니다. Human Area Fusion이라는 새로운 융합 전략을 제안한다고 합니다. 이러한 벙법은 사람 전경 픽셀만 대응 후보로 고려한다고 합니다.
(1) 각 뷰 마다 PPT를 이용해 사람 신체 토큰을 찾는다
(2) 선택된 토큰 끼리만 트랜스포머를 사용해 ㅈ다중 뷰 융합을 실행한다.
이러한 과저을 통해서 효율적으로 2D 포즈 추정을 가능하도록 했습니다. 그리고 추가적으로 여러 뷰의 사람 영역 정보만을 효율적으로 융합하는 다중 뷰 포즈 추정 방법을 제안하였습니다. 이를 통해 다양한 밴치마크 데이터셋에서 우수한 성능을 달성할 수 있었다고 합니다.
Relative Work
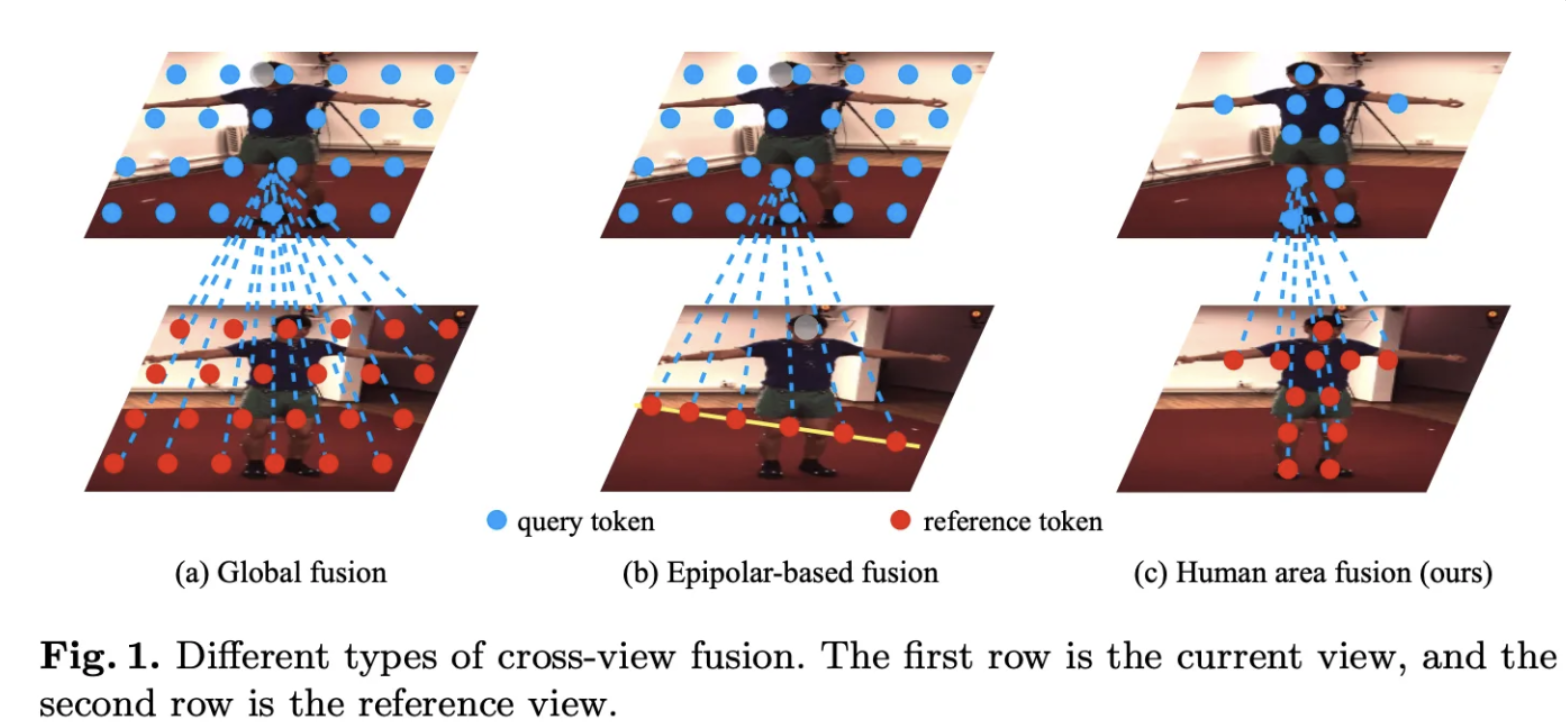
자세 추정에 있어서 CNN 모델이 주를 이루다, Transpose, TokenPose의 방법들이 제안되었지만, 경량화와 관련된 연구는 활발히 진행되지 않았다. 이후 가림현상을 해결하고자 다중 뷰를 활용한 모델이 연구되었으며 다중 뷰에는 크게 Epipolar based fusion 방식과 Global Fusion 방식이 등장하였습니다.
단안 2D Pose Estimation
↓
+------------------------------+
| Transformer 기반 도입 |
| (TransPose, TokenPose) |
+------------------------------+
↓
경량화된 2D Pose Estimation
(EfficientPose, Lite-HRNet)
↓
다중 뷰 2D→3D Pose Estimation
↓
┌─────────────────────────────┐
│ (1) Epipolar-based Fusion │
│ – 2D → 1D 대응, 경량 │
│ │
│ (2) Global Fusion │
│ – 전역 어텐션, 고연산 │
└─────────────────────────────┘
ViT 기반의 모델들은 지금 까지 다양한 분야에서 성능을 끌어올렸지만, Transformer 기반의 attention은 고해상도 이미지에 사용하는 경우 연산량이 많다는 단점이 존재하였습니다. 그래서 양자화, 프루닝, 지식증류와 같은 다양한 기법들이 ViT의 연산 효율성을 증가시킬 수 있다는 다양한 연구들이 나왔습니다. 그리고 CNN기반의 특성을 도입하거나 다양한 방법으로 토큰의 수를 줄이는 방법 또한 등장하였지만, 이러한 방법들은 클래스 분류 문제에 특화된 연구들이였습니다. → ViT 효율성을 높히는 연구들이 분류 문제에만 국한되어있다고 지적하고 있습니다.
Monocular 2D Pose Estimation : 최근 CNN에서도 2D 이미지에서 자세 추정 관련 연구들이 진행되었고, 심지어 ViT 기반의 모델들도 많이 연구가 되고 있습니다. 그리고 Transformer의 도입으로 크게 Transpose ( Transformer 을 이용하여 관절 간 의존성을 학습 )와 TokenPose(추가적인 ‘관절 토큰’을 투입해 제약 관계와 외형 정보를 함께 모델링 )의 방법들이 제안되었습니다.
Efficient 2D Pose Estimation : 실시간 추정을 목표로 하는 경량화 연구 또한 진행되었습니다. 특히 EfficientPose와 Lite-HRNet과 같은 모델이 연구되었지만, 모두 CNN 기반이였기에, 아직 Transformer 기반의 경량화 모델이 나오지 않았었습니다.
Multi-view Pose Estimation : 각 뷰 별로 2D 관절을 예측하고, 각 관절들을 삼각측량법을 활용하여 3D 위치로 변환하는 방법입니다. 최근 연구들은 2D 자세 추정 모델에 다중 뷰 신호를 융합하는 방법들을 제안하였다고 합니다. 이는 크게 2가지 전략으로 연구되었다고 합니다.
(1) Epipolar-based fusion : 한 뷰의 픽셀에 대응하는 에피폴라 선 상의 픽셀들만 융합 ( 관절들이 에피폴라 선 상에 존재한다는 가정하에, 2D 이미지를 1D로 매핑 시켜 메모리 연산량을 줄 일 수 있다 )
(2) Global Fusion : 한 뷰의 픽셀과 다른 뷰의 모든 위치를 융합. ( 한 뷰의 각 픽셀이 각 다른 뷰의 모든 위치와 전역적으로 attention 되게 됩니다. 각 뷰들의 전역적인 관계 해석에 용이하지만 메모리 사용량이 높다)
Methodology
Token-pruned Pose Transformer
Overview

PPT 모델을 간단하게 살펴보면 다음과 같이 나타낼 수 있습니다. 우선 이미지가 들어오면 해당 이미지를 CNN의 입력으로 넣어 특정 Feature map을 얻습니다. 그리고 이렇게 얻얻진 Feature map을 총 개의 패치로 나눠줍니다. 그리고 선형 변환을 통해서 각각의 패치를 D차원으로 선형변환 시켜 Transformer의 입력으로 넣을 준비를 합니다. 그리고 추가로 Position Embedding을 더해주게 됩니다. 이후, 관절에 대한 추가 토큰을 추가해주게 됩니다. J개의 관절 토큰은 단순히 학습 가능한 토큰을 넣어줌으로써 해당 토큰이 알아서 각 관절의 특징을 학습하도록 해줍니다. 그래서 최정적으로는 아래와 같이 개의 입력을 준비하게 됩니다.
그리고 PPT의 경우 L개의 Transformer 레이어를 가지고 있습니다. 여기서 Human Token Identification module은 K개의 사람이 있을 법한 토큰을 추출하게 됩니다. 그래서 HTI을 거치게 되면 로 표현할 수 있으며 HTI를 거치게 되면 개의 토큰만 남아 있게 됩니다. 그리고 특정 층마다 이러한 HTI를 진행되에 지속적으로 사람이 있을법한 토큰만 남기고, 나머지 토큰들은 제거 하게 됩니다. 이를 통해서 메모리 효율을 증가시킬 수 있습니다. 그래서 최종적으로 개의 토큰만 딱 남게 됩니다. 그리고 Transformer의 최종 결과에 대해서 J개의 관절 토큰만 선형 변환을 통해서 차원으로 만들어서 히트맵을 얻게 됩니다.
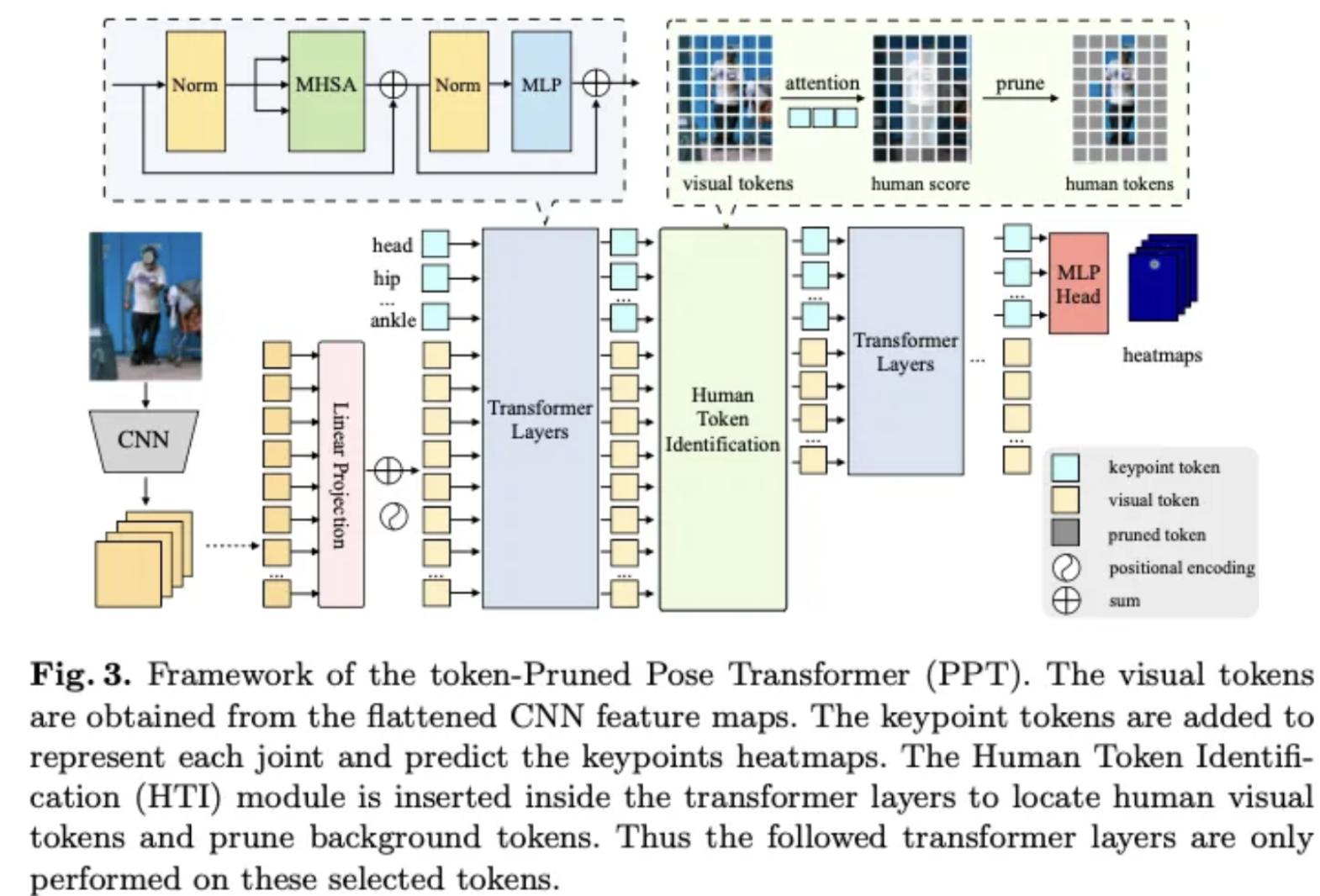
FIg3 이 최종적인 PPT 모델의 구조입니다. 결국 Transpose와 TokenPose를 동시에 사용함과 동시에, Human Token Identification을 도입하여, 지속적으로 토큰의 수를 줄여서 메모리 사용량을 줄인것이 특징이라고 생각됩니다.
Transformer Encoder Layer
Transformer Ecnoder Layer의 경우 그냥 기본적인 Transformer encoder의 구조를 갖습니다.
간단하게 Layer Norm → MHSA → Skip-connection → Layer Norm → MLP → Skip-connection 을 따릅니다.
Human Token Indentification (HTI )
사람이 있을 법한 토큰을 살리고, 나머지 부분에 대해서는 제거하는 레이어 입니다. Attnetion 계산을 통해서
다음과 같은 식을 유추할 수 있는데, 각 관절들과 이미지의 토큰들을 Attention하게 되면, 각 관절에 대한 확률 값을 얻을 수 있게 됩니다.
그리고 이렇게 얻어진 확률 값은 결국 해당 이미지 토큰과 관절의 유사도를 부여주게 됩니다. 그래서 아래와 같이 모든 관절들에 대해서 각 토큰들의 값들을 구해주게 됩니다.
이는 결국 해당 이미지 토큰에 관절이 포함되어 있을 확률을 의미하게 되며, a값을 기준으로 상위 K 의 토큰만 살리게 되면 결국 사람이 없는 토큰을 지우게 되는 것입니다.
Multi-view Pose Estimation with PPT
Human Area Fusion
본 논문에서 제안하는 Human Area Fusion의 경우 FIg1에서 설정한것 과 같이작동합니다. 이전의 Global Fusion은 모든 이미지 픽셀에 대해서 Attention을 실행하여 높은 연산량을 가지고 있는 한편, Human area fusion인 경우 사람이 있을법한 위치의 픽셀들과의 attention을 통해서 보다 메모리 효율적으로 서로 다른 뷰의 관절 끼리의 연관성을 파악할 수 있습니다.
Multi-view PPT
다중 뷰 자세 추정을 하기 위해서 기존의 세그멘테이션 모델을 활용하게 된다면 사람의 픽셀을 보다 정규하게 잡아줄 수 있습니다. 하지만 사전 데이터가 필요하며 모델의 크기도 크다는 단점이 있습니다. 이러한 단점을 극복하기 위해서 사람 위치를 대강 추측할 수 있는 PPT 모델을 사용해서 Multi-view pose estimation을 제안합니다.
우선 각각의 이미지를 PPT 모델에 통과 시켜 N개의 사람 추정 토큰과 관절 토큰을 얻습니다. 그리고 모든 뷰에서 나온 토큰들을 이어 붙인후, Transformer Encoder로 전달하여 전역 Attention을 진행하게 됩니다. 이떄, 3D 공간 정보를 모델이 인식 할 수 있도록 3D 위치 인코딩을 모든 선택된 시각 토큰에 추가합니다. 이를 통해서 서로 다른 뷰에서 나온 관절 토큰들 끼리 어텐션이 진행되고, 최종적으로 관졀 히트맵을 얻을 수 있게 됩니다.
Experiments on monocular image
인코드 레이어 수 L = 12
임베딩 차원 D = 192,
Attention Head = 8
비주얼 토큰 = 256
keep ratio r= 0.7 ( 3회 ) → 3회 프루닝 후 최종적으로 256 * = 88개의 토큰만 남게 된다.
HTI의 위치 : (4,7,10) 혹은 (2,4,5) 레이어 직전에 사용
r = 0.7은 실험적으로 결정되었다고 합니다. r의 값이 줄어들 수록 메모리는 줄지만, 사람을 추정하는 정확도 또한 소폭 감소하여 모든 모델에서는 0.7을 기본값으로 설정하였다고 합니다. 추가로 메모리 효율을 증가시키면서 동시에 여러 밴치마크에서 높은 성능을 달성하였다고 합니다.

HTI 적용시 이미지를 시각화 해본 결과 다음과 같이 사람의 픽셀을 제외한 나머지 배경 부분을 제거하는 것을 확인해볼 수 있습니다.

또한 다중 뷰 자세 추정 데이터셋에 대해서도 적은 메모리로 최상위 성능을 보여주었다고 합니다.
Conclusion
PPT 모델은 Transformer를 자세 추정에 도입하면서 적은 메모리로 높은 성능을 달성하였음을 보여줍니다. 추가로 Multi View PPT를 제안하여 다양한 뷰의 이미지를 융합하여 다양한 밴치마크데이터셋에서 높은 성능을 보여주었습니다.
나의 생각
Transformer 기반의 모델을 경량화 하는 방법으로 써 사람이 있을 법한 위치를 관절과의 attention score를 통해서 얻는 과정이 인상깊었습니다. 추가로 사람이 있는 픽셀이 만일 사라진 경우에 대해서도 고려하였지만, 이는 실험적으로 r= 0.7을 사용하면 안정적으로 결과를 도출할 수 있다는 실험 결과 또한 있어 좋았습니다.
이를 자연스럽게 자율주행에 적용하기 위해서는 도로가 있을 법한 위치를 추정하고, 도로위에 존재하는 다양한 객체들에 대해서 만일 사람인 경우 더욱 주위하도록 설정하는 방법으로 적용 가능 할것 같습니다. 이는 결국 차량내 다양한 카메라로 얻는 정보를 기반으로 3D 정보를 얻고, 이를 통해 하나의 결과를 도출하게 된다면 실시간 추론 및 높은 정확도를갖는 도로위 사람 인식 모델로 발전할 수도 있다고 생각합니다.
