✏️ Anomaly Detection이란?
👉 Normal(정상) sample과 Abnormal(비정상, 이상치, 특이치) sample을 구별해내는 문제
📂 비정상 sample 정의에 따른 분류
👉 비정상 sample을 정의하는 방식에 따라 크게 Novelty Detection과 Outlier Detection으로 구분
👉 Novelty Detection과 Outlier Detection 두 용어의 기준이 명확하지 않아 혼재되어 사용되기도 함
📌 용어 설명
🔦 Novelty
👉 기존의 주류 데이터와 달리 새로운 특성을 가진 데이터🔦 Outlier
👉 기존의 주류 데이터에서 벗어난 특성을 가진 데이터
📗 Novelty Detection
👉 이전과는 다른 새로운 형태의 데이터를 찾아내는 방법
👉 지금까지 등장하지 않았지만 충분히 등장할 수 있는 sample을 감지
👉 새로운 데이터가 기존의 학습된 데이터 분포에 적합한 값인지 아닌지를 판단해내는 방법
🧩 예) 기존의 망고는 노란색이 주류이나 새로운 파란색의 망고가 검출되는 경우
📙 Outlier Detection
👉 기존의 데이터 분포 내에 포함되지 않는 데이터를 찾아내는 방법
👉 지금까지 등장하지 않았고 앞으로도 등장할 가능성이 없는, 데이터에 오염이 발생했을 가능성이 있는 sample을 감지
🧩 예) 기존의 망고는 길이가 15cm 내외이나 50cm의 망고가 검출되는 것
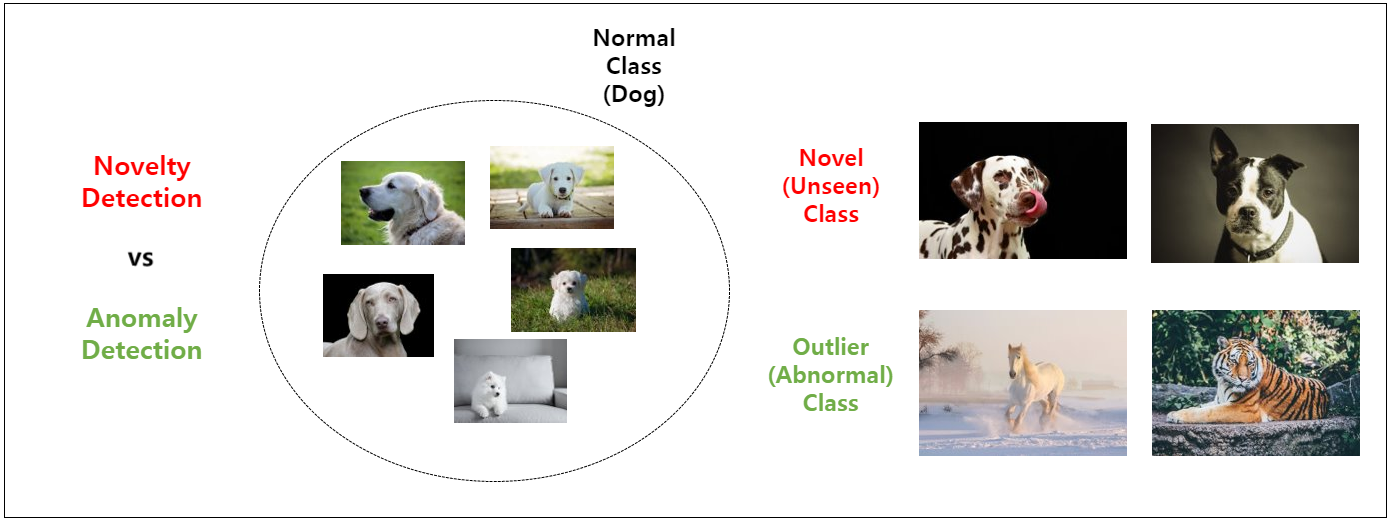
📍 예시
- 위 예시는 강아지가 Normal Sample로 정의된 자료
- 기존의 강아지 데이터에 없던 새로운 형태의 강아지 데이터가 등장하는 경우 새로운 형태의 강아지 데이터가 Novelty Sample이며 이를 찾아내는 방법이 Novelty Detection
- 강아지가 아닌 말, 호랑이와 같이 강아지와 전혀 관련없는 데이터가 등장하는 경우 호랑이, 말 데이터가 Outlier Sample 혹은 Abnormal Sample이며 이를 찾아내는 방법이 Outlier Detection
🙏 Reference
https://hoya012.github.io/blog/anomaly-detection-overview-1/
