📢 개요
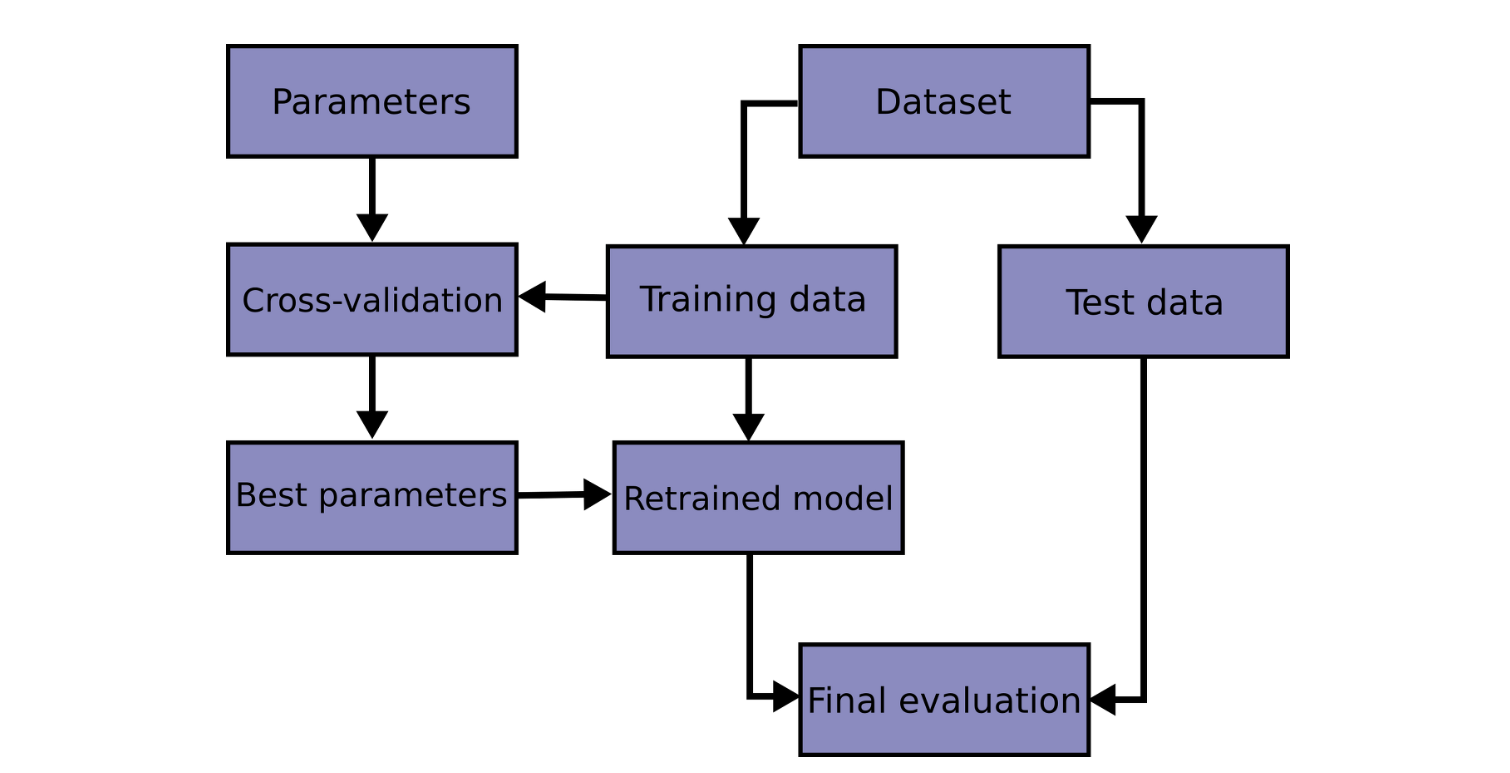
✏️ 교차검증(Cross Validation, CV)이란?
👉 모델 학습 시 학습 데이터 세트와 테스트 데이터 세트를 교차 변경하는 방법론
👉 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트를 통해 학습과 검증을 수행하는 방법
👉 Train set을 Train set + Validation set으로 분리한 뒤, Validation set을 이용해 검증 수행
📌 교차검증 기법을 사용하는 이유?
- 전체 데이터를 train set과 test set으로 분리하여, train set으로 모델을 학습 시킨 후 test set으로 모델의 성능을 평가하는 것이 일반적인 방법
Hold-Out Validation- 그러나 위 방법은 한 가지 문제점이 존재하는데, 고정된 test set을 통해 모델의 성능을 평가하고 수정하는 과정을 반복할 경우 모델이 해당 test set에만 잘 동작하게 되는, 즉 과적합(Overfitting) 되는 문제가 발생
- 이 경우, 다른 실제 데이터로 예측 수행 시 결과가 좋지 못함
- 위와 같이 데이터를 구성할 경우, train set으로 학습만 진행하는 것이 아니라 validation set을 통해 성능을 검증하고, 그 결과를 통해 모델을 수정(HyperParameter Tuning)하여 학습시킬 수 있음
- 그러나 위 방법 역시 모델이 고정된 validation set에 과적합(Overfitting) 되는 문제가 발생
- 이 경우, test set을 통한 최종 평가 결과가 좋지 못한 경우가 발생할 수도 있음
여러번의 검증을 통해 일반화된 모델을 만들 수 있도록 교차검증(Cross Validation) 기법을 적용하여 이를 해결!


📚 종류
1. K-Fold Cross Validation

👉 전체 학습 데이터 세트를 k개의 fold로 나누어 fold 1개를 검증 데이터로, 나머지 (k-1)개 fold를 학습 데이터로 분할 하는 과정을 반복하여 학습 및 검증 데이터를 교차 변경하는 기법
👉 가장 일반적이고 많이 사용되며 강력한 교차 검증 방법 중 하나
👉 모든 데이터를 학습 및 검증에 활용하기에 좀 더 일반화된 모델을 만들 수 있음
👉 HyperParameter k는 주로 5, 10fold 많이 사용하나, 최적의 k값을 찾기 위한 실험적 검증 과정이 필요함
🔎 절차
1) 전체 데이터 세트를 train set과 test set으로 분리
2) train set을 train set + validation set으로 사용하기 위해 k개의 fold로 분리
3) 첫 번째 fold를 validation set로 사용하고 나머지 fold들을 train set로 사용하여 학습 및 검증 수행
순차적으로 다음 fold를 validation set으로 사용하여 3번 과정을 k번 반복
4) 총 k개의 모델 성능 평가 결과가 도출되며, k개의 결과값의 평균을 최종 결과(모델의 성능)로 활용
2. Stratified K-Fold Cross Validation
👉 각각의 fold들이 최대한 같은 비율로 클래스를 포함하도록 하는 K-fold CV 기법
👉 원본 데이터의 레이블 분포를 먼저 고려한 뒤, 학습 데이터와 검증 데이터 세트가 가지는 레이블 분포가 유사하도록 세트를 구성
👉 일반적으로 클래스가 있는 분류문제에서는 Stratified K-Fold CV를 사용하고, 회귀문제에서는 K-Fold CV 사용
❗ Stratified K-Fold CV는 원본 데이터 세트의 레이블 분포를 학습 및 검증 데이터 세트에 제대로 분배하지 못하는 K-Fold CV의 문제를 해결해줌!
📌 함수 종류
✅ cross_val_score() : 평가지표로 계산된 검증 스코어에 대한 정보를 확인 가능
cross_val_score(estimator, X, y, scoring(검증평가지표), cv(교차검증 fold 수))✅ cross_validate() : 여러 개의 평가지표를 사용하여 검증 가능
cross_validate(estimator, X, y, scoring(검증평가지표), cv(교차검증 fold 수 or splitter 객체), n_jobs(CPU 코어 수), return_train_score(훈련 데이터 세트 점수 반환여부))💻 코드 예제
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# raw data 불러오기
wine = pd.read_csv('https://bit.ly/wine_csv_data')
# Dataframe -> array 변환
data = wine[['alcohol','sugar','pH']].to_numpy()
target = wine['class'].to_numpy()
# 학습 및 테스트 데이터 세트 분리
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size = 0.2, random_state=42)
dt = DecisionTreeClassifier(random_state=42)
# 교차검증 cross_val_score()
from sklearn.model_selection import cross_val_score
scores_1 = cross_val_score(dt, train_input, train_target, cv=5)
# 교차검증 cross_validate()
from sklearn.model_selection import cross_validate
scores_2 = cross_validate(dt, train_input, train_target, cv=5, )
print(scores_1)
print(scores_2)
print(np.mean(scores_1))
print(np.mean(scores_2['test_score']))# result
[0.86923077 0.84615385 0.87680462 0.84889317 0.83541867]
{'fit_time': array([0.01616669, 0.02228951, 0.01625681, 0.01645517, 0.01666021]),
'score_time': array([0. , 0.00103521, 0.00210857, 0. , 0. ]),
'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
0.855300214703487
0.8553002147034873. Leave-p-Out Cross Validation(LpOCV)

👉 전체 데이터 n개 중에서 p개의 샘플을 선택하여 모델 검증에 사용하는 기법
👉 각각의 학습 및 검증 iteration 결과값의 평균을 최종 결과(모델의 성능)로 활용
4. Leave-One-Out Cross Validation(LOOCV)

👉 오직 하나의 검증 데이터만 남기고 나머지 데이터로 학습을 수행하는 기법
👉 LpOCV에서 p=1인 경우에 해당하며 K-fold에서 K=N인 경우에 해당하는 기법
👉 일반적인 경우에는 사용하지 않으나, 데이터의 개수가 적은 경우에 효과적인 기법
5. Repeated Random Subsampling Validation

👉 각 iteration 마다 임의로 검증 데이터 세트를 추출하여 학습 및 검증을 수행하는 기법
👉 임의로 추출되는 것이기에 검증 데이터 세트가 중복될 수도 있으며, 한 번도 선택되지 않은 데이터가 존재할 수 있음
🙏 Reference
https://blog.naver.com/PostView.nhn?blogId=winddori2002&logNo=221850530979
https://medium.com/mlearning-ai/cross-validation-clearly-explained-in-5-graphs-9b83067bc696
