📢 개요
이번 포스트에서는 하이퍼파라미터가 무엇인지 그리고 이를 튜닝하는 다양한 기법들에 대해 정리하고자 한다.
📦 Parameter vs HyperParameter
📌 파라미터(Parameter)
👉 모델 내부에 존재하는 변수
👉 학습 알고리즘을 통해 데이터를 학습하여 자동적으로 결정되는 변수
👉 모델의 성능을 결정하는 핵심요소
🧩 EX) 편향(bias), 가중치(weight), SVM에서의 서포트벡터, Regression에서의 R-square 등
📌 하이퍼파라미터(HyperParameter)
👉 알고리즘 사용자가 경험에 의해 직접 설정해주는 변수로, 학습 과정에서 자동으로 변경되는 값이 아님
👉 모델의 학습 방식을 결정하며, 학습 시작 전 미리 값을 결정해주어야 함
👉 데이터 분석 결과로 얻어지는 값이 아니므로 정해진 최적의 값은 없음
👉 모델 학습 시, 알고리즘이 샘플에 대하여 보다 일반화된 성능을 보일 수 있도록, 이를 조정해주는 과정이 필요
🧩 EX) Neural Network에서의 learning rate, epoch, KNN에서의 k, Decision Tree에서의 max_depth 등
✏️하이퍼파라미터 튜닝(HyperParameter Tuning)?
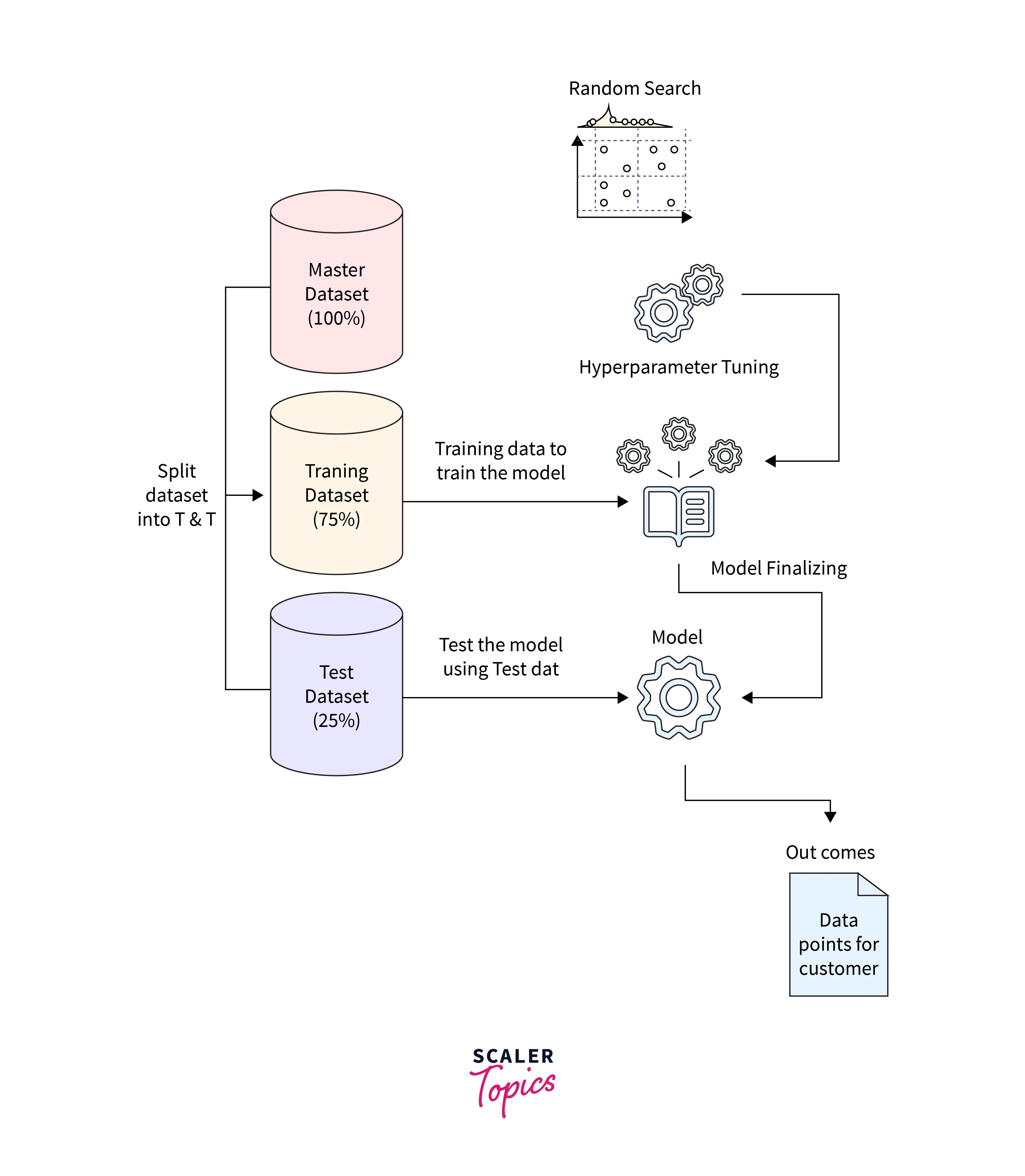
👉 모델의 학습 방식을 최적화하여 모델의 성능 및 일반화 능력을 향상시키는 방법
👉 하이퍼파라미터는 알고리즘 사용자가 경험에 의존하여 직접 설정해주는 값이지, 데이터 분석의 결과 값이 아니므로 절대적인 최적값은 존재하지 않음
👉 하이퍼파라미터는 사용하는 학습 알고리즘과 데이터에 따라 달라지므로 여러 값들을 대입해보면서 모델에 적합한 최적값을 찾아가는 과정이 필요
❗ 주의점
- 하이퍼파리미터 튜닝 시, 테스트 데이터 세트를 절대 사용해서는 안됨
- Test set는 모델의 최종 성능 평가를 위해 사용되어야 하므로, 모델의 학습 과정에서는 절대 사용되어서는 안됨
Validation set를 이용하여 하이퍼파라미터 검증 실시!
🔎 튜닝 기법
1. 메뉴얼 탐색(Manual Search)
👉 사용자가 경험에 의존하여 직접 하이퍼파라미터의 값과 조합을 선정 및 평가를 통해 비교하여 최적의 조합을 찾아내는 휴리스틱 기법
👉 사용자가 경험적으로 좋은 성능을 보였던 알고있는 값과 조합을 사용
👉 매우 단순하고 쉬운 기법이나, 그만큼 성능을 올릴 수 있는 최적의 파라미터 값과 조합을 찾기 여러우며, 자동화된 알고리즘이 아니므로 탐색에 많은 시간이 소요된다는 단점 존재
2. 그리드 탐색(Grid Search)
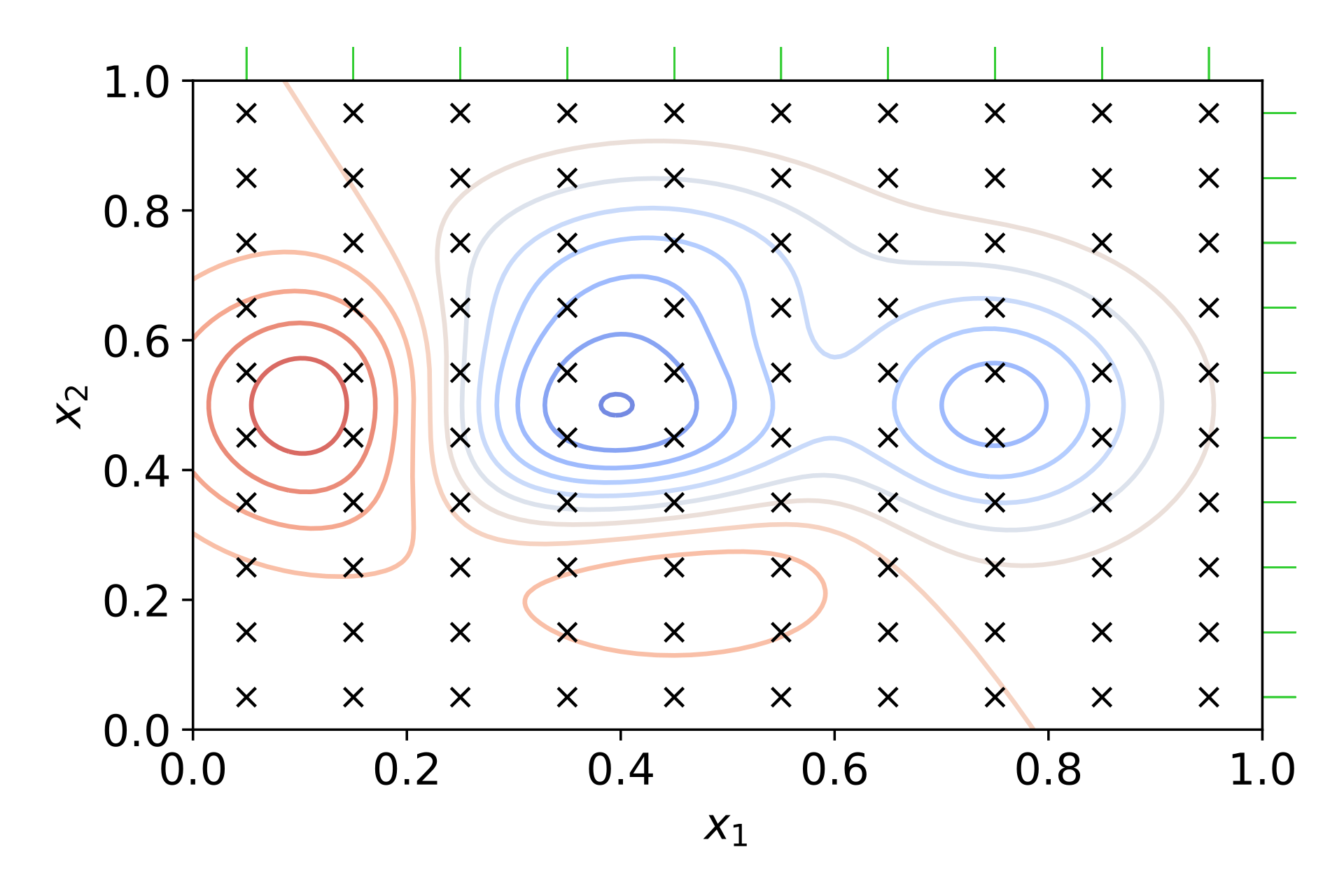
👉 각 하이퍼파라미터들이 가질 수 있는 값들을 일정 간격을 갖는 구간으로 정해두고, 모든 가능한 조합을 탐색 및 평가하는 기법
👉 단순하면서도 어느 정도 준수한 결과를 보장하기 떄문에 많이 사용되는 기법
👉 하이퍼파라미터 수가 많거나, 값의 구간을 넓게 설정할 수록 오랜 탐색 시간이 소요되므로 데이터 세트가 작은 경우에 유리한 기법
👉 설정한 값의 범위 내에서의 최적값을 찾아낸다는 한계점 존재
❓ 만약, learning rate 값의 범위를 0.01부터 0.05까지 0.01의 간격으로 설정한 뒤 Grid Search를 실시한다면?
실제 learning rate의 최적값이 0.018임에도 불구하고 0.018의 값은 찾을 수 없으며, 오직 0.02의 근사 최적값만을 찾을 수 있을 뿐 !
💻 코드 예제
from sklearn.model_selection import GridSearchCV
# 탐색 범위 정의
params = {'min_impurity_decrease' : np.arange(0.0001, 0.001, 0.0001),
'max_depth' : range(5, 20, 1),
'min_samples_split' : range(2, 100, 10),
}
dt = DecisionTreeClassifier()
gs = GridSearchCV(estimator=dt, param_grid=params, cv=3, n_jobs=-1)
gs.fit(train_input, train_target)
print('Grid Search 최적 파라미터 :', gs.best_params_) # 각 하이퍼파라미터 별 최적값
print(gs.best_score_) # 최적값을 통한 교차 검증 결과의 최고 점수# result
GridSearch 최적 파라미터 : {'max_depth': 11, 'min_impurity_decrease': 0.0002, 'min_samples_split': 42}
0.86453803738238893. 랜덤 탐색(Random Search)
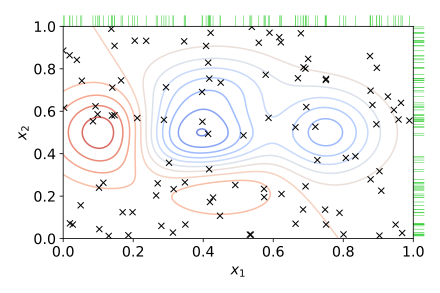
👉 각 하이퍼파라미터들의 값의 범위를 설정해둔 상태에서, 값을 무작위로 선정하여 만들어지는 조합들을 탐색 및 평가하는 기법
👉 격자 형식의 그리드 탐색과 달리, 그 사이의 값들도 무작위로 탐색할 수 있으므로 더 빠르게, 더 좋은 최적값을 찾을 수 있다는 장점이 존재
💻 코드 예제
params = {'min_impurity_decrease' : uniform(0.0001, 0.001),
'max_depth' : randint(20, 50),
'min_samples_split' : randint(2, 25),
'min_samples_leaf' : randint(1, 25),
}
dt = DecisionTreeClassifier()
gs = RandomizedSearchCV(estimator=dt, param_distributions=params, n_iter=100, n_jobs=-1)
gs.fit(train_input, train_target)
print('Random Search 최적 파라미터 :', gs.best_params_) # 각 하이퍼파라미터 별 최적값
print(gs.best_score_) # 최적값을 통한 교차 검증 결과의 최고 점수# result
Random Search 최적 파라미터 : {'max_depth': 27, 'min_impurity_decrease': 0.00012166984017841667, 'min_samples_leaf': 8, 'min_samples_split': 24}
0.86549876130913444. 베이지안 최적화(Baysian Optimization)
📌 알고리즘 작동원리
STEP#1. 최초에는 무작위로 하이퍼파라미터들을 샘플링하여 성능결과를 관측STEP#2. 관측된 값을 기반으로 Surrogate model(대체 모델)은 최적의 함수를 예측 추정
STEP#3. Acquisition function에서 다음으로 관측할 하이퍼파라미터 추출
STEP#4. 해당 하이퍼파라미터로 관측된 값을 기반으로 Surrogate model은 다시 최적함수 예측 추정
STEP#5. 1-4까지의 과정 반복 수행
Random Search와 통계적 기법(Gaussian Distribution)을 기반으로 실제 data와 surrogate model을 이용하여 실제 model을 찾지 않아도 최적해를 도출해낼 수 있는 최적화 기법
🙏 Reference
https://huidea.tistory.com/32
https://www.scaler.com/topics/machine-learning/hyperparameter-search/
https://m.blog.naver.com/winddori2002/221858114122
