
📢 개요
현대의 디지털 사회는 인터넷을 통해 본인이 원하는 정보에 매우 쉽게 접근할 수 있는 세상이다. 인터넷은 무수히 많은 정보들이 넘쳐 흐르는 곳으로 흔히 정보의 바다라고 불리기도 한다. 이러한 엄청난 양의 데이터, 즉 빅데이터를 효과적으로 분석하고 활용하기 위해서는 프로파일링, 정보 추출, 데이터 분석기술이 필수적이며 그 영향력이 점점 커져가고 있다. 앞선 기술들은 데이터 기반의 합리적인 의사결정을 가능케하며 더 나은 솔루션을 제시하기도 한다. 이번 포스트에서는 데이터 분석의 핵심 요소 중 하나로 꼽히는 데이터 프로파일링에 대해서 정리해보고자 한다.
📚 탐색적 데이터 분석(EDA)
📗 EDA란?
👉 수집한 데이터를 분석하기 전에 그래프나 통계적인 방법을 이용하여 다양한 각도에서 데이터의 특징을 파악하고 변수 간 잠재적 관계를 찾아내는 조사 방법
👉 본격적인 데이터 분석에 들어가기에 앞서 필수적으로 거쳐야 하는 과정
👉 EDA를 통해서 데이터 전처리, 피쳐 엔지니어링 방향 확보
📘 EDA 목적
👉 여러 가지 시각화 도구 및 통계 기법을 사용하여 데이터를 한눈에 파악하기 위함
👉 어떤 변수가 예측력이 높고 낮은지를 확인하기 위함
👉 예측 모델을 구축하기 전에 적합한 통계 도구를 선택하기 위함
👉 도출하고자 하는 결과의 기본이 되는 가설의 검증 과정이 될 수 있음
👉 데이터를 다양한 각도에서 살펴보면서 다양한 패턴들을 발견하고 새로운 더 좋은 가설을 세울 수 있음
📙 EDA 과정
STEP#1. 데이터의 속성(변수, feature) 확인
STEP#2. 각 피쳐별 단변량 데이터 분석
STEP#3. 피쳐간 상관관계 분석
STEP#4. 결측치 처리
STEP#5. 이상치 처리
STEP#6. 피쳐 엔지니어링을 통한 피쳐 선택, 추가, 삭제
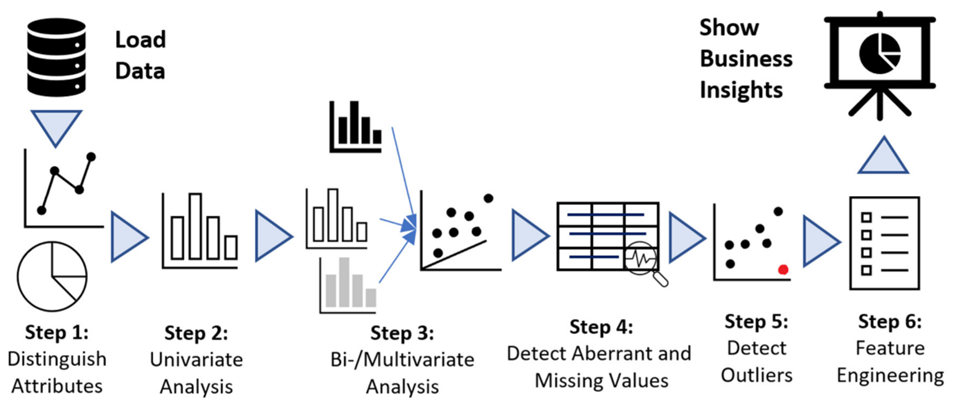
📕 EDA 대상(Target)
✅ 단변량 분석(Univariate Analysis)
👉 변수의 분포, 중심 경향, 변동성 및 기타 통계 측정을 이해하기 위해 한 번에 하나의 변수를 분석
👉 변수 하나에 대해 기술통계량(descriptive statistics) 을 확인
👉 데이터를 설명하고 그 안에 존재하는 패턴을 찾는 것이 주요 목적
👉 Histogram이나 Boxplot을 사용해서 평균, 최빈값, 중간값 등과 함께 각 변수들의 분포를 확인
👉 범주형 변수의 경우 Boxplot을 사용해서 빈도 수 분포를 체크
✅ 이변량 분석(Bivariate Analysis)
👉 두 변수 간의 관계를 분석하여 패턴, 상관관계 또는 연관성을 식별
👉 보통의 이변량 통계량은 간단히 '상관관계'라고 불리는 이변량 상관관계(Bivariate Correlation)으로 측정
👉 변수의 유형에 따라 적절한 시각화 및 분석 방법 적용
✅ 다변량 분석(Multivariate Analysis)
👉 여러 현상이나 사건에 대한 측정치를 개별적으로 분석하지 않고 변수를 동시에 한 번에 분석하는 통계적 기법
👉 여러 변인들 간의 관계성을 동시에 고려해 효과를 밝히는 분석 기법
🧩 변수들간의 인과관계(Causal Relationship)를 분석 회귀분석, 분산분석
🧩 변수들간의 상관관계(Correlationship)를 이용하여 데이터의 차원을 축소 주성분분석, 요인분석
🧩 개체들의 유사성에 의해 개체를 분류 판별분석, 군집분석
📗 EDA 종류
✅ 시각화
👉 차트, 그림 등을 이용하여 데이터를 확인하는 방법
👉 데이터를 한눈에 파악하여 대략적인 패턴과 관계를 파악 가능
✅ 비시각화
👉 시각적인 요소를 사용하지 않고, 주로 요약통계로 데이터 확인
👉 정확한 값을 파악하기 좋은 방법
📗 EDA 유형
✅ 일변량 비시각화(Uni-Non Graphic)
👉 데이터의 분포를 확인하는 것이 주 목적
✅ 일변량 시각화(Uni-Graphic)
👉 데이터를 전체적으로 살펴보는 것이 주 목적
✅ 다변량 비시각화(Multi-Non Graphic)
👉 주어진 둘 이상의 변수 간 관계를 확인하는 것이 주 목적
✅ 다변량 시각화(Multi-Graphic)
👉주어진 둘 이상의 변수 간 관계를 전체적으로 살펴보는 것이 주 목적
✏️ 데이터 프로파일링(Profiling)이란?
👉 잠재적 오류 징후를 찾아내기 위해 자료를 수집하고 분석하는 과정
👉 데이터 내 값의 분포, 변수 간의 관계, Null 값과 같은 결측값(missing values) 존재 유무 등을 분석
👉 메타데이터를 통한 데이터의 특성을 파악
👉 데이터의 통계적 분석 결과를 통해 잠재적 오류데이터를 추정
👉 표준화 수준, 테이블 구조, 정규화 수준, 컬럼 및 관계 정의 등 데이터의 구조적 결함을 측정
📌 통계적 분석 (Statistical Analysis) 과정
1. DDA (Descriptive Data Analysis)
👉 '문제'를 규명하는 기술적 분석 단계
👉 통계 대표값을 계산하여 데이터의 현재 모습을 요약 기술하는 단계
🧩 분석도구 : 평균, 표준편차, 빈도수, 백분위수, 첨도, 왜도, 신뢰구간 등2. EDA (Exploratory Data Analysis)
👉 '문제'를 파악하는 탐색적 분석 단계
👉 그래프를 활용하여 수집된 여러 데이터의 패턴을 이해
👉 가능성이 큰 변수의 관계 가설을 도출
🧩 분석도구 : Histogram, Boxplot, Scatterplot, Pareto 등3. CDA (Confirmatory Data Analysis)
👉 EDA 단계에서 도출한 '가설'을 '검증'하는 확증적 분석 단계
👉 검정통계량을 이용하여 가설 검정을 진행하며 이 때 p-value를 기준으로 의사결정 진행
🧩 분석도구 : t-test, F-test, ANOVA, 상관분석, 회귀분석, 카이제곱검정 등4. PDA (Predictive Data Analysis)
👉 CDA를 통해 검증된 가설을 통해 분석된 변수가 결과에 얼마나 영향을 주는지 파악하는 단계
👉 의미있는 최적 관계식을 모델링하고 최적 조건을 예측
🧩 분석도구 : 선형회귀모델, 다중선형모델, SVM, 로지스틱 회귀, 인공신경망 등5. 실행
👉 모델링된 새로운 대안을 실행하여 통계적이며 합리적인 문제해결과 의사결정을 내릴 수 있게 됨
👉 새로운 대안에 대해 새로운 문제가 발생하면 위 과정을 반복하여 특정 system의 모델을 계속해서 개선할 수 있음
🔔 데이터 프로파일링 목적
👉 메타데이터와 대상 소스데이터에 대한 통계적 분석 결과를 통해 데이터 품질 문제를 이슈화하고 개선점을 찾는 것이 주된 목적
📕 데이터 프로파일링 수행 단계
📣 데이터 프로파일링은 아래와 같은 절차로 수행되는데, 특히 도메인을 정의하고 진단방법을 선정하는 단계에서 많은 시간이 소요된다. 따라서 진단대상의 표준화 수준, 산출물 보유 여부 등 데이터베이스 관리 수준이 높을수록 프로파일링에 소요되는 비용이 줄어들 수 있다.
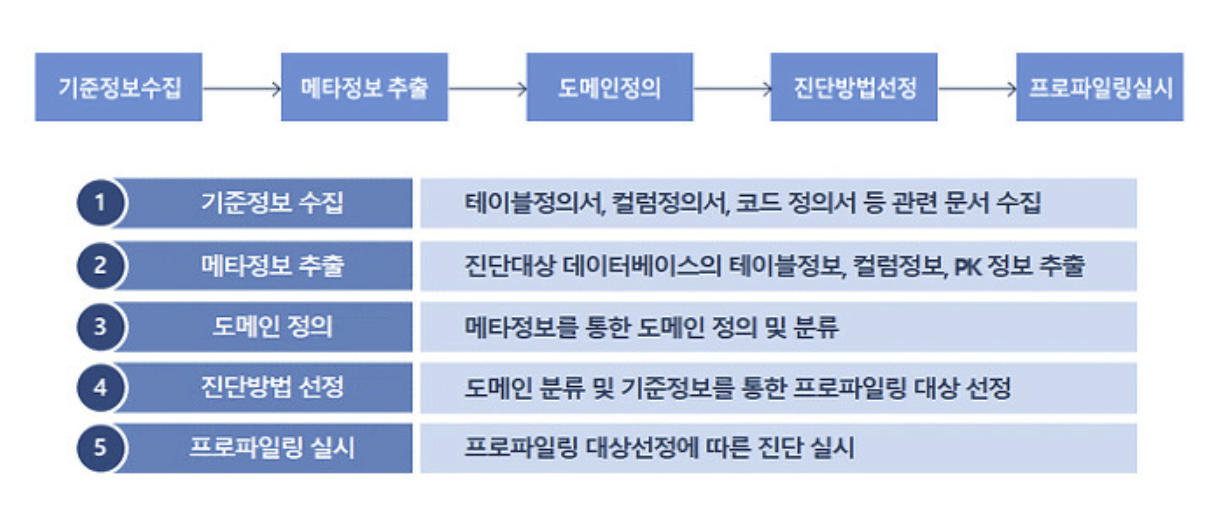
STEP#1. 메타데이터 수집 및 분석
👉 실제 데이터베이스에 설계 반영도니 물리 메타데이터를 수집하고 사전 수집된 테이블 및 컬럼 목록을 대조하여 분석
STEP#2. 프로파일링 대상 및 유형 선정
👉 프로파일링 분석을 수행할 대상 업무 및 테이블을 선정하고 프로파일링 분석 유형을 선정
STEP#3. 프로파일링 수행
👉 데이터 현상을 분석하여 누락값, 비유효값, 유일하지 못한 값, 구조 무결성 위반사항을 분석
STEP#4. 프로파일링 결과 리뷰
👉 프로파일링 결과를 취합하고, 해당 결과를 리뷰하여 결과를 확정
STEP#5. 프로파일링 결과 종합
👉 확정된 프로파일링 결과물을 취합하여 프로파일링 보고서를 작성
📕 데이터 프로파일링 기법
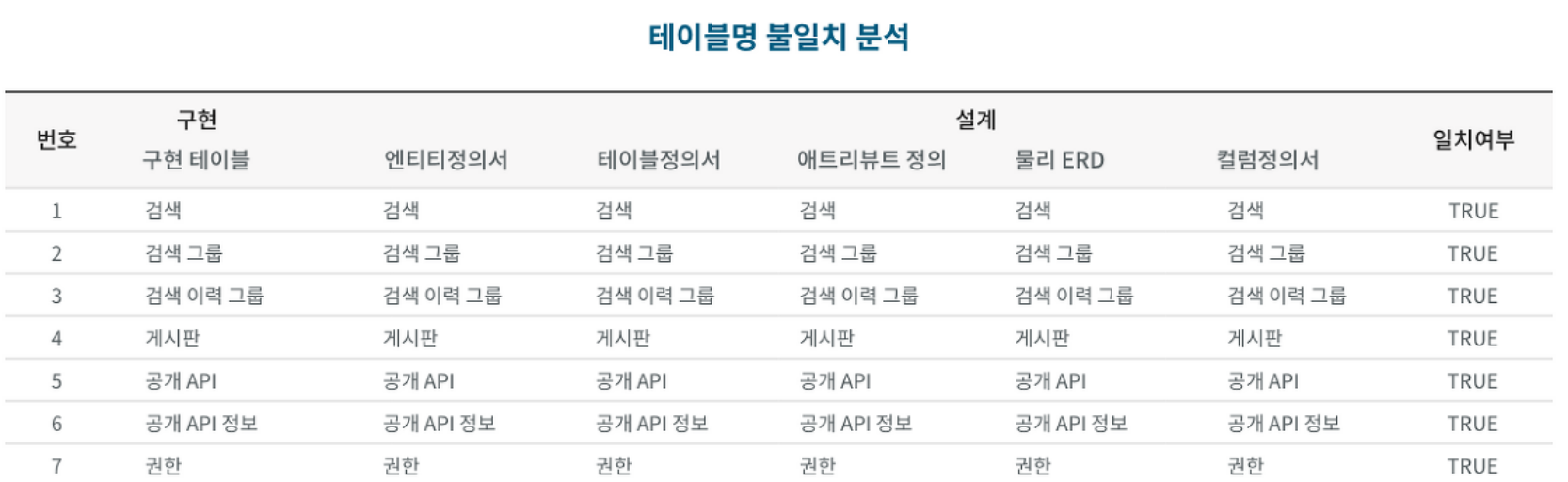
(1) 메타데이터 수집 및 분석
👉 실제 운영 중인 데이터베이스의 테이블명, 컬럼명, 제약조건 등의 정보를 분석하는 절차
👉 데이터 관리 문서의 정보를 분석하고 추출된 테이블 및 컬럼에 대한 메타데이터와 데이터 관리 문서를 매핑하여 불일치 사항을 분석
📍 예시
(2) Column 속성 분석
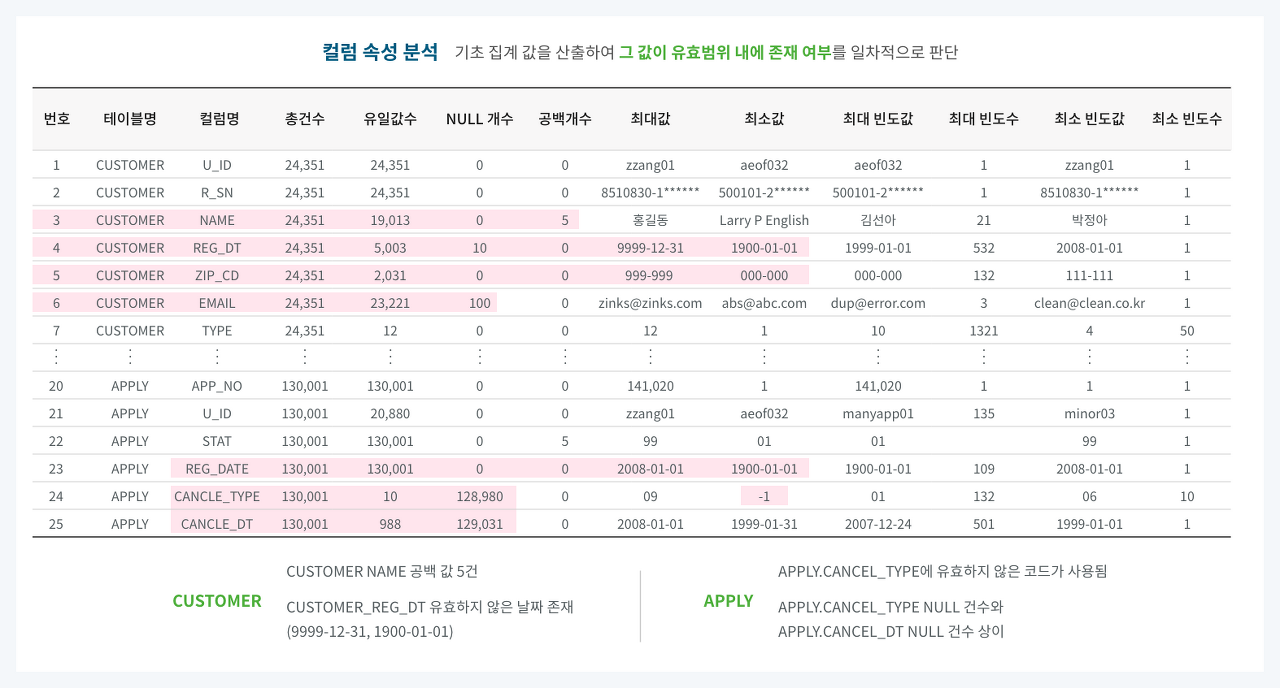
👉 대상 컬럼의 비유효한 값을 확인하는 절차
👉 컬럼의 총 건수, 유일값 수, NULL값 수, 공백값 수, 최댓값, 최솟값, 최대 빈도, 최소빈도 등 기초 집계값을 산출하여 값이 유효한 범위 내에 있는지 판단
📍 예시
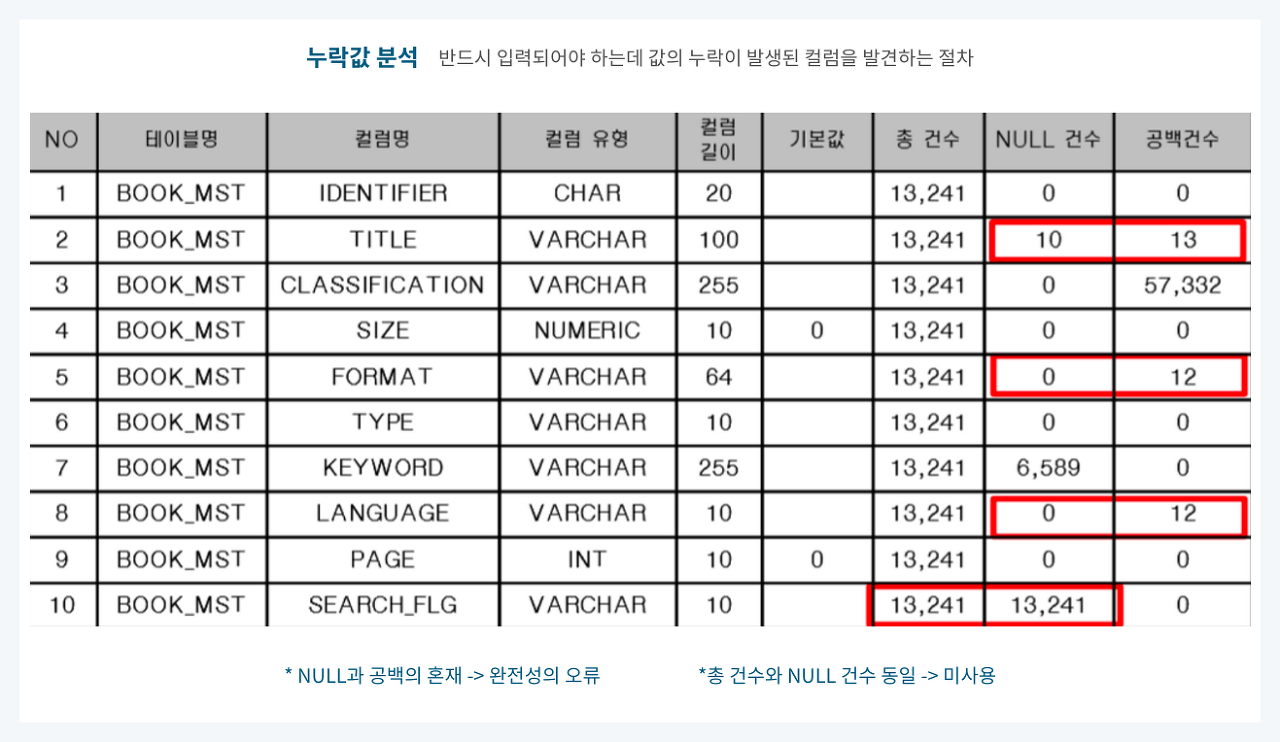
(3) 결측치 분석
👉 반드시 입력되어야 하는 데 누락이 발생한 컬럼을 발견하는 절차
👉 NULL값, 공백값 또는 숫자 ‘0’ 등의 분포를 파악하여 실시
👉 NULL 허용 컬럼일지라도 NULL과 공백이 혼재하는 경우와 총건수와 NULL 건수가 같아 미사용으로 추정되는 컬럼을 발견하는 일도 포함하는 단계
📍 예시
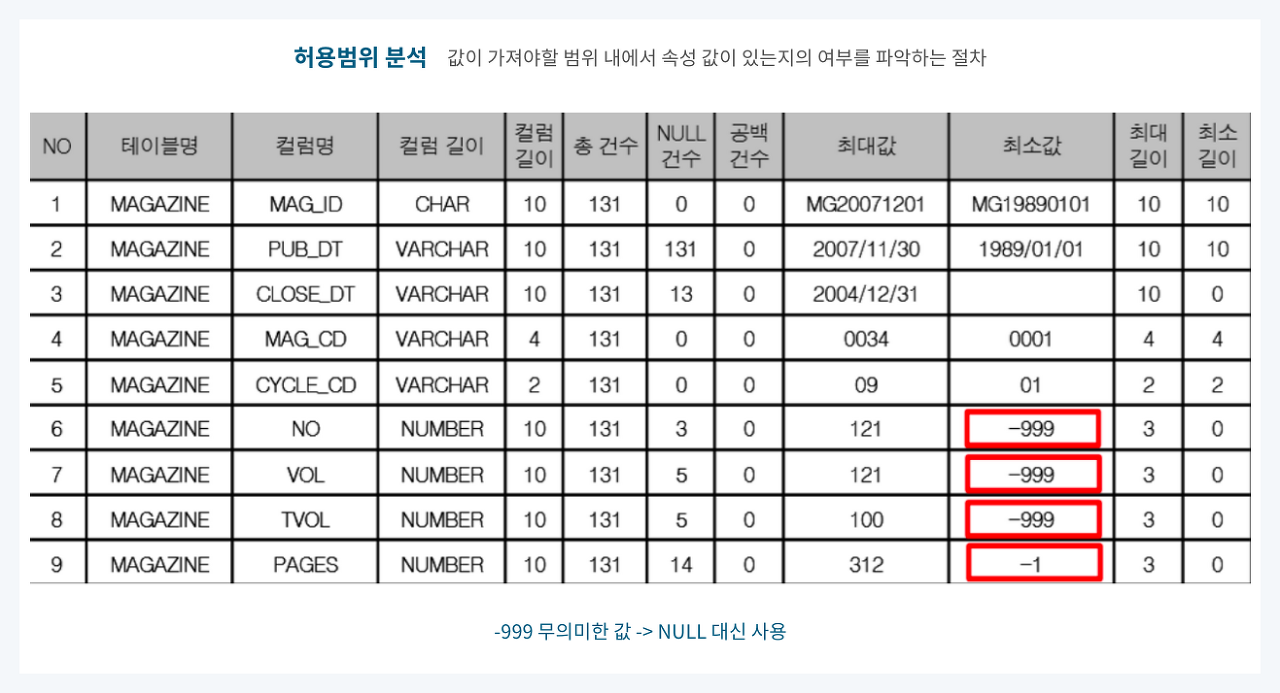
(4) 값 허용범위 분석
👉 컬럼의 속성 값이 가져야 할 범위 내에 그 값이 있는지 여부를 파악하는 기법
👉 해당 속성의 도메인 유형에 따라 정해짐
📍 예시
🧩 MAGAZINE 테이블의 'NO', 'VOL', 'TVOL', 'PAGES' 컬럼은 0 이상의 값을 가져야 하지만 최솟값이 -999 등으로 이루어진 것으로 보아 NULL 대신 무의미한 값을 부여한 데이터일 가능성이 큼
🧩 해당값이 오류 데이터임이 확인될 경우 NULL값을 부여
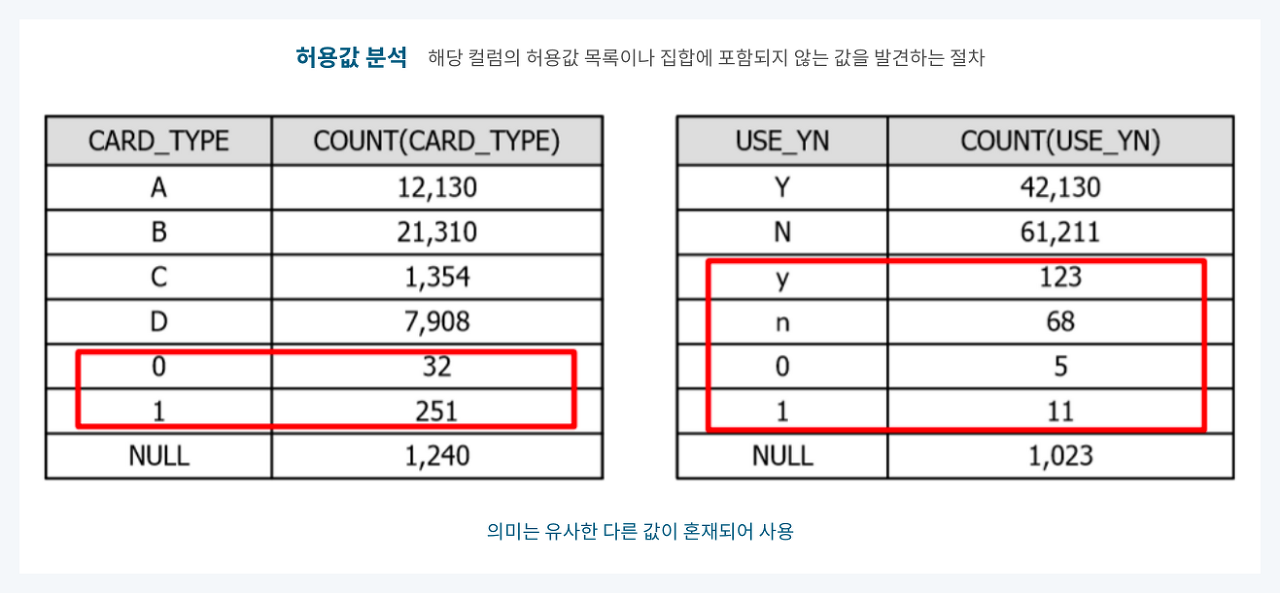
(5) 허용값 분석
👉 해당 컬럼의 허용값 목록이나 집합에 포함되지 않는 값을 발견하는 절차
📍 예시
🧩 등록되지 않은 코드가 포함되어 있거나 의미는 유사하나 다른 값으로 혼재된 경우를 확인 가능
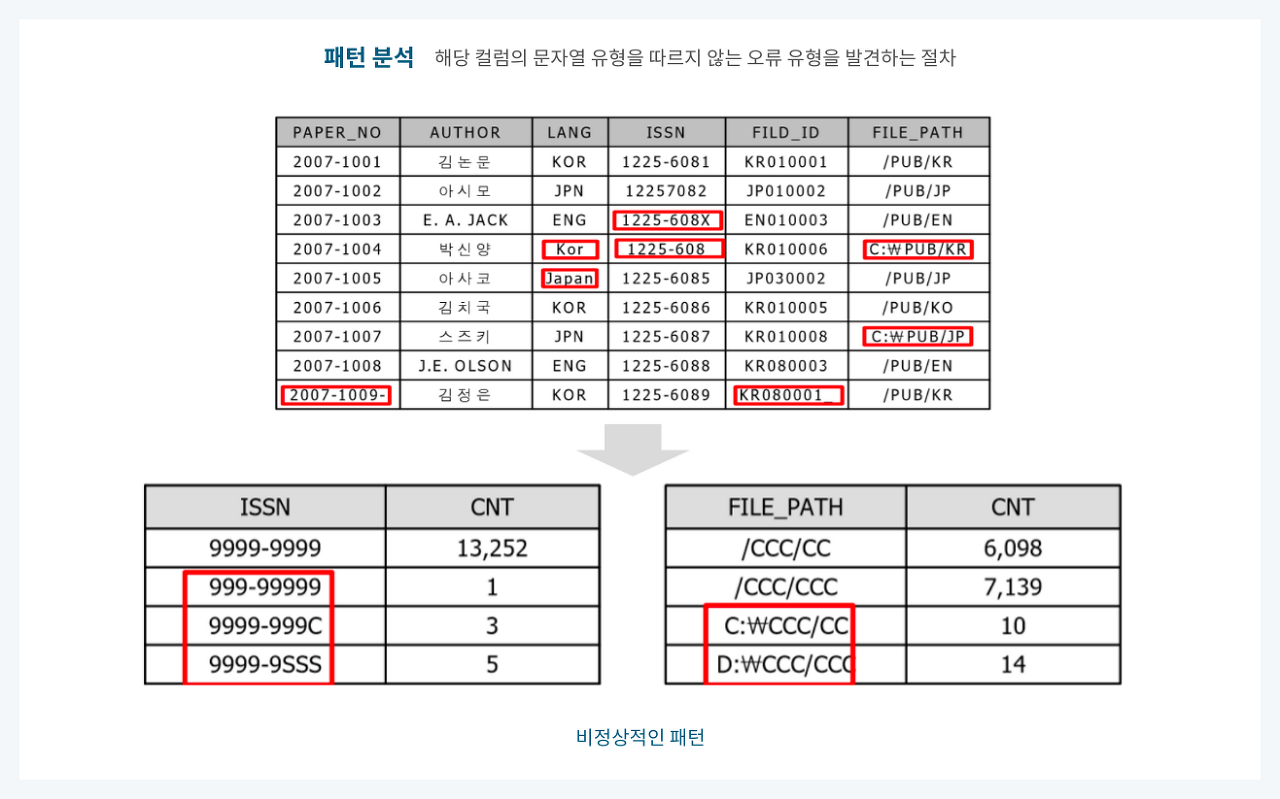
(6) 문자열 패턴 분석
👉 해당 컬럼의 문자열 유형을 따르지 않는 오류 유형을 발견하는 절차
👉 문자열 데이터의 패턴 분석 시, 문자일 경우 'C', 숫자일 경우 '9', 공백일 경우 'S'를 반환하는 함수를 만들어 사용
👉 해당 컬럼의 데이터를 패턴화하여 SQL로 조회하면 비정상적인 형태를 보인 값을 오류로 추정 가능
📍 예시
(7) 날짜 유형 분석
👉 날짜유형을 표현할 경우 다음의 두 가지 방법을 많이 사용
- DBMS애서 제공하는 DATETIME의 유형을 사용하는 경우
- 문자형에 날짜패턴을 적용하여 활용하는 경우
📍 예시
🧩 문자형 데이터 타입에 날짜 데이터를 입력하면 위와 같은 사례 발생 가능
🧩 문자열 패턴 검증 절차를 통하여 검증 가능
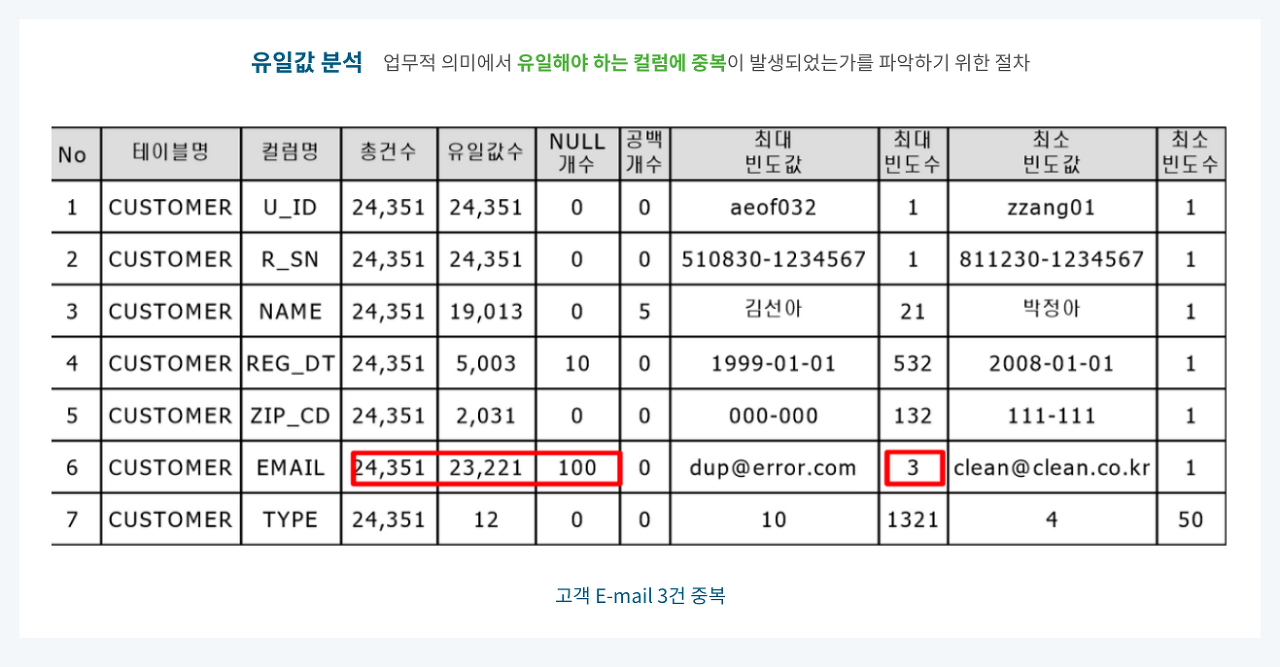
(8) 유일값 분석
👉 업무적 의미에서 유일해야 하는 컬럼에 중복이 발생하였는지를 파악하는 절차
👉 테이블의 식별자로 활용되는 컬럼 속성 값들이 주요 유일값 분석 대상
📍 예시
🧩 CUSTOMER 테이블의 EMAIL 컬럼은 PK(Primary Key) 컬럼이 아니지만, 업무적으로 고객의 이메일은 유일해야 하는 경우 최대 빈도수를 통해 중복 데이터를 확인 가능
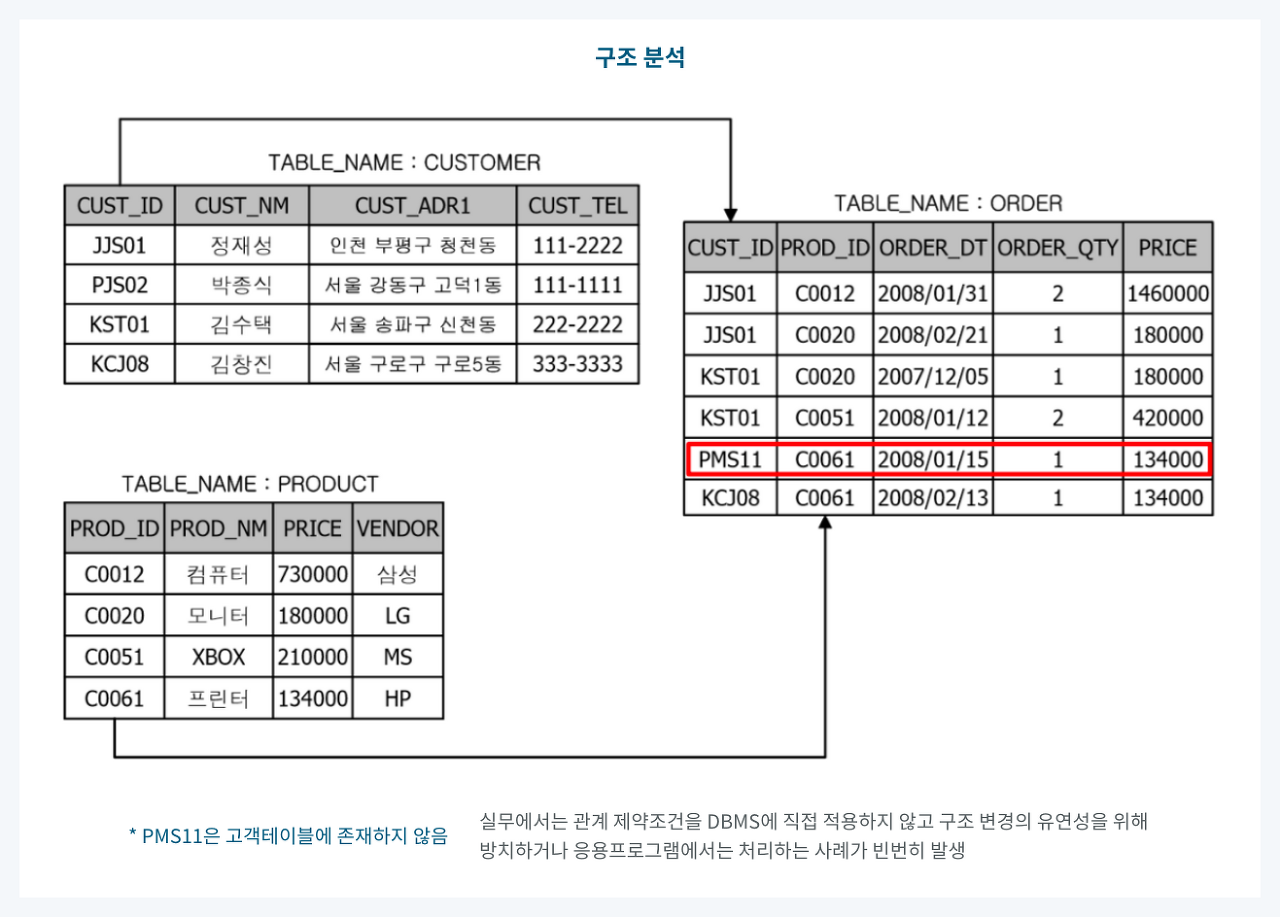
(9) 구조 분석
👉 구조 결함으로 인해 일관되지 못한 데이터를 발견하는 분석 기법
👉 잘못된 데이터 구조로 인해 데이터 값에서 일관되지 못하거나 부정확한 값이 발견되는 현상을 파악하는 작업
📍 예시
🧩 ORDER 테이블에 CUSTOMER 테이블에는 존재하지 않는 데이터가 존재하여 데이터의 일관성이 없는 오류 데이터 발생
🖥️ Python Packages for data profiling
(1) klib
import klib
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')📍 Missing Value Plot
klib.missingval_plot(data)# result example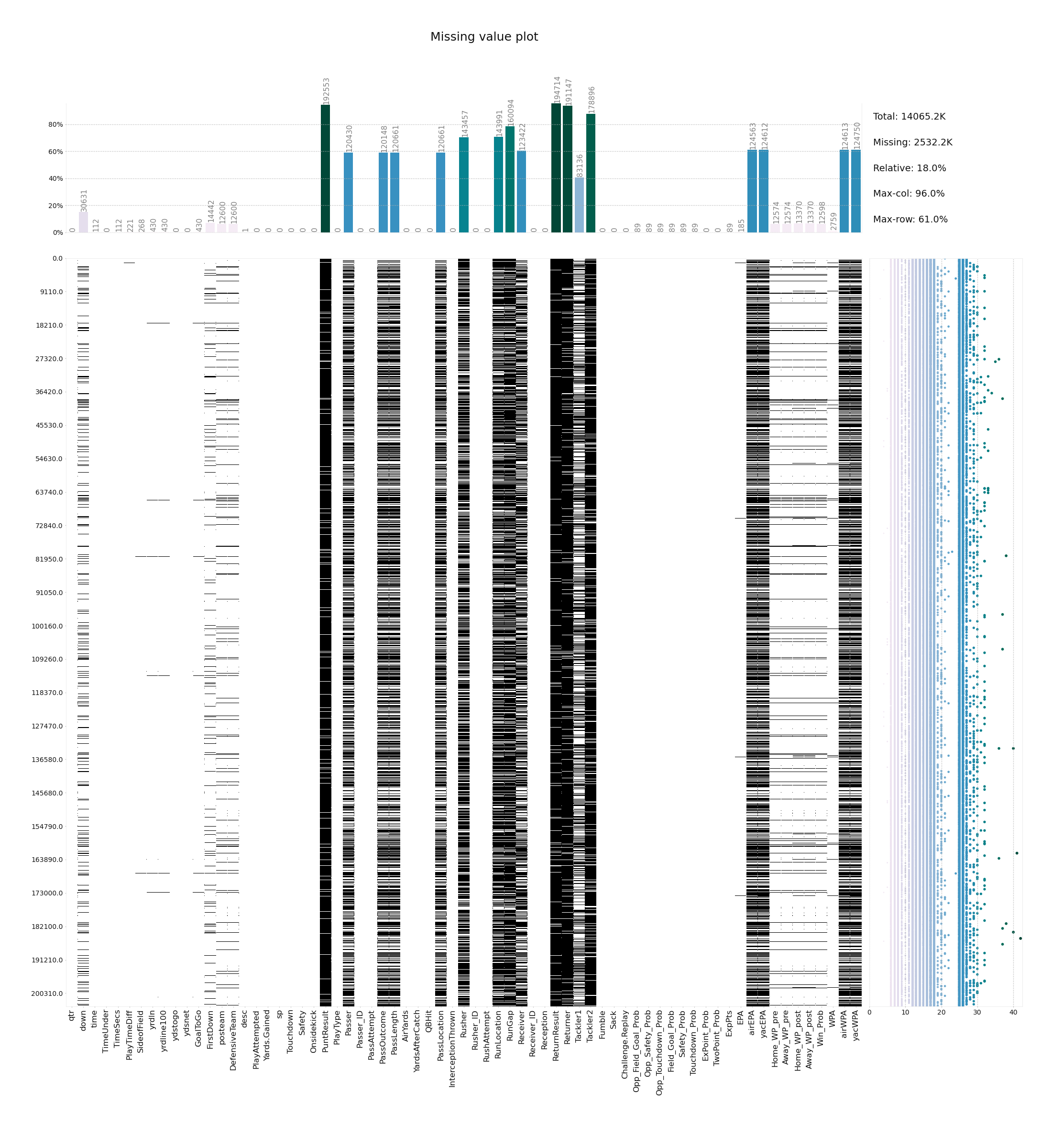
📍 Correlation Plot
klib.corr_plot(data, split='pos') # displaying only positive correlations
klib.corr_plot(data, split='neg') # displaying only negative correlations# result example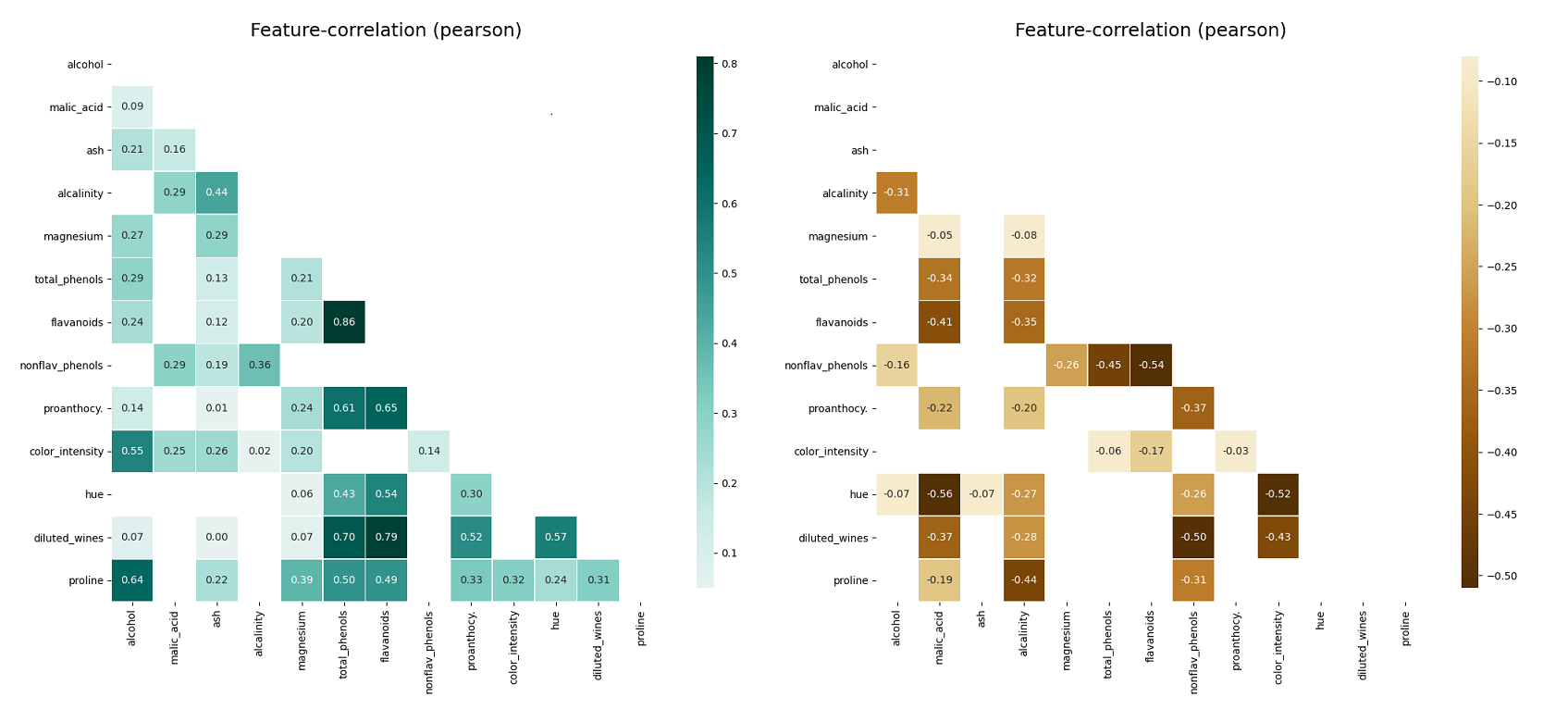
# default representation of correlations with the feature column
klib.corr_plot(data, target='column_name')# result example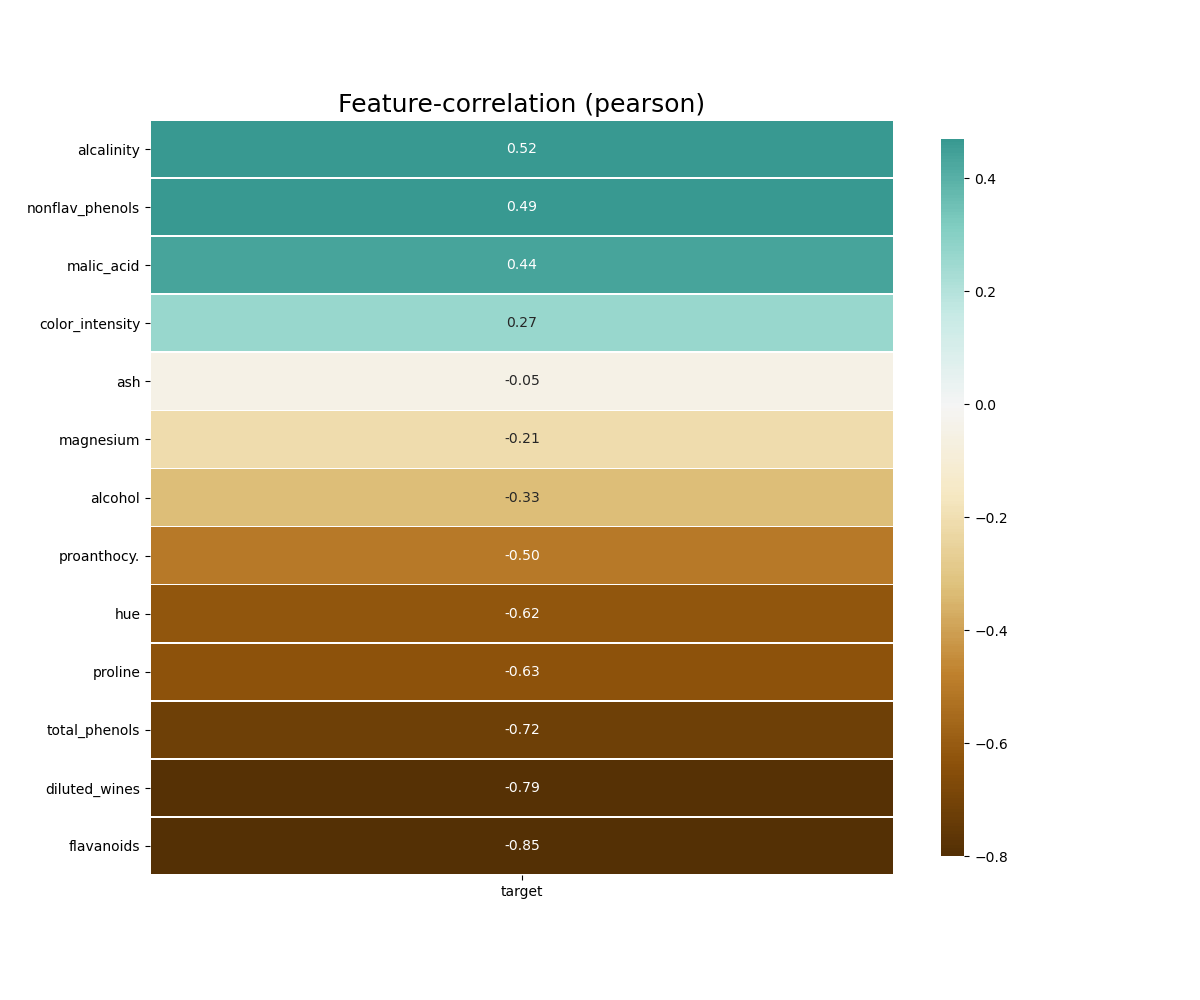
📍 Numerical Data Distribution Plot
# returns a distribution plot for every numeric feature
klib.dist_plot(data) # result example
📍 Categorial Data Plot
# returns a visualization of the number and frequency of categorical features.
klib.cat_plot(data, top=4, bottom=4)# result example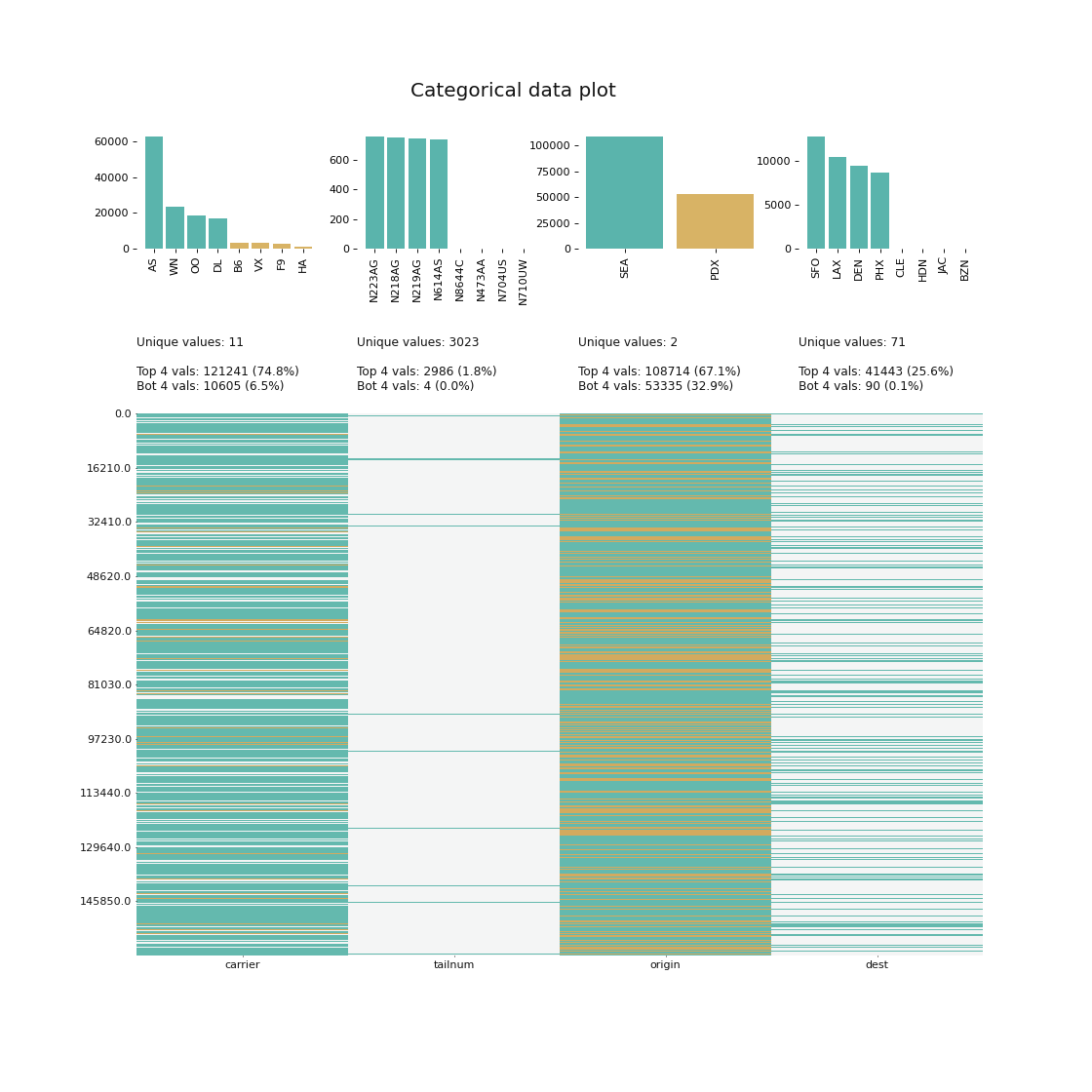
📍 Data Cleaning and Aggregation
# performs datacleaning (drop duplicates & empty rows/columns, adjust dtypes,...) on a dataset
klib.data_cleaning(data)(2) ydata_profiling
💻 코드 예시
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReport
df = pd.DataFrame(np.random.rand(100, 5), columns=["a", "b", "c", "d", "e"])
profile = ProfileReport(df, title="Ydata Profiling Report")
#profile.to_widgets() # jupyter notebook에서 위젯으로 보기
profile.to_notebook_iframe() # HTML 보고서와 유사한 방식으로 셀에 직접 포함
profile.to_file("my_profiling_report.html") # HTML로 별도 저장(3) pygwalker
💻 코드 예시
import pandas as pd
import pygwalker as pyg
import seaborn as sns
df_titanic = sns.load_dataset('titanic')
gwalker = pyg.walk(df_titanic).display_on_jupyter()🙏 Reference
https://data-soin.tistory.com/81
https://peimsam.tistory.com/228
https://blog.b2en.com/298
https://klib.readthedocs.io/en/latest/examples.html
