
📢 개요
앞선 포스트들에서 데이터를 수집하고, 탐색 과정을 거쳐 정제하는 방법들에 대해서 정리해보았다. 데이터를 본격적으로 분석 하기에 앞서 스케일링 과정이 필요한지 파악하는 것은 중요한데, 수집한 데이터 별로 값들의 범위가 다양하게 존재할 수 있기 때문이다. 예를 들어 값이 대체로 큰 '키'와 값이 대체로 작은 '몸무게' 데이터의 경우, 동일한 값을 가진다 하더라도 서로 다른 영향을 미칠 것이며 이는 모델 학습에 악영향을 줄 수있다. 따라서 스케일링 전처리를 통해 서로 다른 변수가 일정한 수준의 값 범위를 갖도록 하여 비교 분석하기 쉽게 처리해주어야 한다. 이번 포스트에서는 데이터 변환 전처리 과정 중 스케일링에 대해 정리해보고자 한다.
✏️ 스케일링(Scaling)이란?
👉 서로 다른 변수(feature)의 값 범위를 일정한 수준으로 맞추는 작업
👉 변수(feature)들마다 데이터 값의 범위가 다 제각각이기 때문에, 범위 차이가 클 경우 데이터를 갖고 모델을 학습할 때 0으로 수렴하거나 무한으로 발산하는 문제가 발생하므로 이를 방지하기 위한 목적으로 수행
👉 다차원의 값들을 동일한 수준에서 비교 분석하기 용이하게 만들어 줌
👉 값을 조정하는 과정이므로 수치형(Numerical) 변수에만 적용 가능
👉 비트수로 인하여 다른 값으로 인식되는 오버플로우(overflow) 및 언더플로우(underflow) 문제를 방지
- 예를 들어 x1 feature는 0과 1 사이의 값을 갖고, x2 feature는 100,000과 100,000,000 사이의 값을 가지며, y는 1,000,000부터 100,000,000사이의 값을 갖는다고 가정하자. 이 경우 x1의 특성은 y를 예측하는데 큰 영향을 주지 않을 것임을 판단할 수 있음.
- 따라서 스케일링 전처리 과정을 통해 모든 변수(feature)들의 범위(분포)를 동일하게 만들어 주어야 함. 해당 과정을 수행하지 않을 경우 머신러닝 모델의 성능 저하가 발생할 가능성이 높아짐.
📂 종류
1. StandardScaler
👉 각 Feature들의 범위를 평균 0, 분산 1인 표준정규분포가 되도록 스케일링하는 방법
👉 이상치는 데이터의 평균과 분산에 크게 영향을 주기 때문에 이상치가 존재하는 데이터에는 적절하지 않은 방법
👉 회귀(Regression) 문제보다 분류(Classification) 문제에 용이
💻 코드 예시
from sklearn.preprocessing import StandardScaler
# 객체 생성
std_scaler = StandardScaler()
# 학습 및 변환
std_data = std_scaler.fit_transform(data)
# 데이터프레임 변환
df_std = pd.DataFrame(std_data, columns=data.columns)2. RobustScaler
👉 각 Feature들의 중앙값(Median)을 0, 사분위수범위(IQR=Q3-Q1)을 1로 스케일링하는 방법
👉 이상치의 영향을 최소화할 수 있는 방법
👉 모든 Feature들이 동일 크기를 갖는다는 점에서 StandardScaler와 유사
💻 코드 예시
from sklearn.preprocessing import RobustScaler
# 객체 생성
robust_scaler = RobustScaler()
# 학습 및 변환
robust_data = robust_scaler.fit_transform(data)
# 데이터프레임 변환
df_robust = pd.DataFrame(robust_data, columns=data.columns)3. MinMaxScaler
👉 각 Feature들을 하한값(min)을 a, 상한값(max)을 b로 하여 스케일링 하는 방법
👉 대부분 0과 1 사이의 범위로 스케일링 진행
👉 이상치가 존재하는 데이터의 경우, 이상치가 극단값이 되어 데이터가 아주 좁은 범위에 분포하게 되는 문제가 발생하므로 적절하지 않은 방법
👉 분류보다 회귀에 유용합니다.
👉 분류(Classification) 문제보다 회귀(Regression) 문제에 용이
💻 코드 예시
from sklearn.preprocessing import MinMaxScaler
# 객체 생성
minmax_scaler = MinMaxScaler()
# 학습 및 변환
minmax_data = MinMaxScaler.fit_transform(data)
# 데이터프레임 변환
df_minmax = pd.DataFrame(minmax_data, columns=data.columns)4. MaxAbsScaler
👉 각 Feature들의 절대값이 0 과 1 사이가 되도록 스케일링하는 방법
👉 모든 값은 -1 과 1 사이로 표현되며, 데이터가 양수일 경우 MinMaxScaler와 동일
👉 이상치가 존재하는 데이터에는 적절하지 않은 방법
💻 코드 예시
from sklearn.preprocessing import MaxAbsScaler
# 객체 생성
maxabs_scaler = MaxAbsScaler()
# 학습 및 변환
maxabs_data = MaxAbsScaler.fit_transform(data)
# 데이터프레임 변환
df_maxabs = pd.DataFrame(maxabs_data, columns=data.columns)5. Normalizer
👉 한 행의 모든 Feature들 사이의 유클리드 거리(L2 norm)가 1이 되도록 스케일링하는 방법
👉 각 Feature(열, column)의 통계량을 이용한 앞선 4가지의 스케일링 방법(StandardScaler, RobustScaler, MinMaxScaler, MaxAbsScaler)과 달리, 각 Sample(행, row)마다 정규화가 진행되는 방법
👉 딥러닝 모델 내 학습 벡터에 주로 사용하는 방법
💻 코드 예시
from sklearn.preprocessing import Normalizer
# 객체 생성
normal_scaler = Normalizer()
# 학습 및 변환
normal_data = Normalizer.fit_transform(data)
# 데이터프레임 변환
df_normal = pd.DataFrame(normal_data, columns=data.columns)6. QuantileTransformer
👉 데이터를 N개의 분위(quantile)로 나누어 균등하게 분포시키는 방법
👉 MinMaxScaler와 유사하게 0과 1 사이의 값으로 변환
👉 이상치에 민감하지 않음
💻 코드 예시
from sklearn.preprocessing import QuantileTransformer
# 객체 생성
gaussian_scaler = QuantileTransformer(n_quantile = 1000, output_distribution='normal')
uniform_scaler = QuantileTransformer(n_quantile = 1000, output_distribution='uniform')
# 데이터 변환
df_gaussian = pd.DataFrame(gaussian_scaler.fit_transform(data), columns=data.columns)
df_uniform = pd.DataFrame(uniform_scaler.fit_transform(data), columns=data.columns)7. PowerTransformer
👉 데이터의 각 Feature별로 정규분포의 형태에 가깝게 변환해주는 방법
💻 코드 예시
from sklearn.preprocessing import PowerTransformer
# 객체 생성
power_scaler = PowerTransformer()
# 학습 및 변환
power_data = PowerTransformer.fit_transform(data)
# 데이터프레임 변환
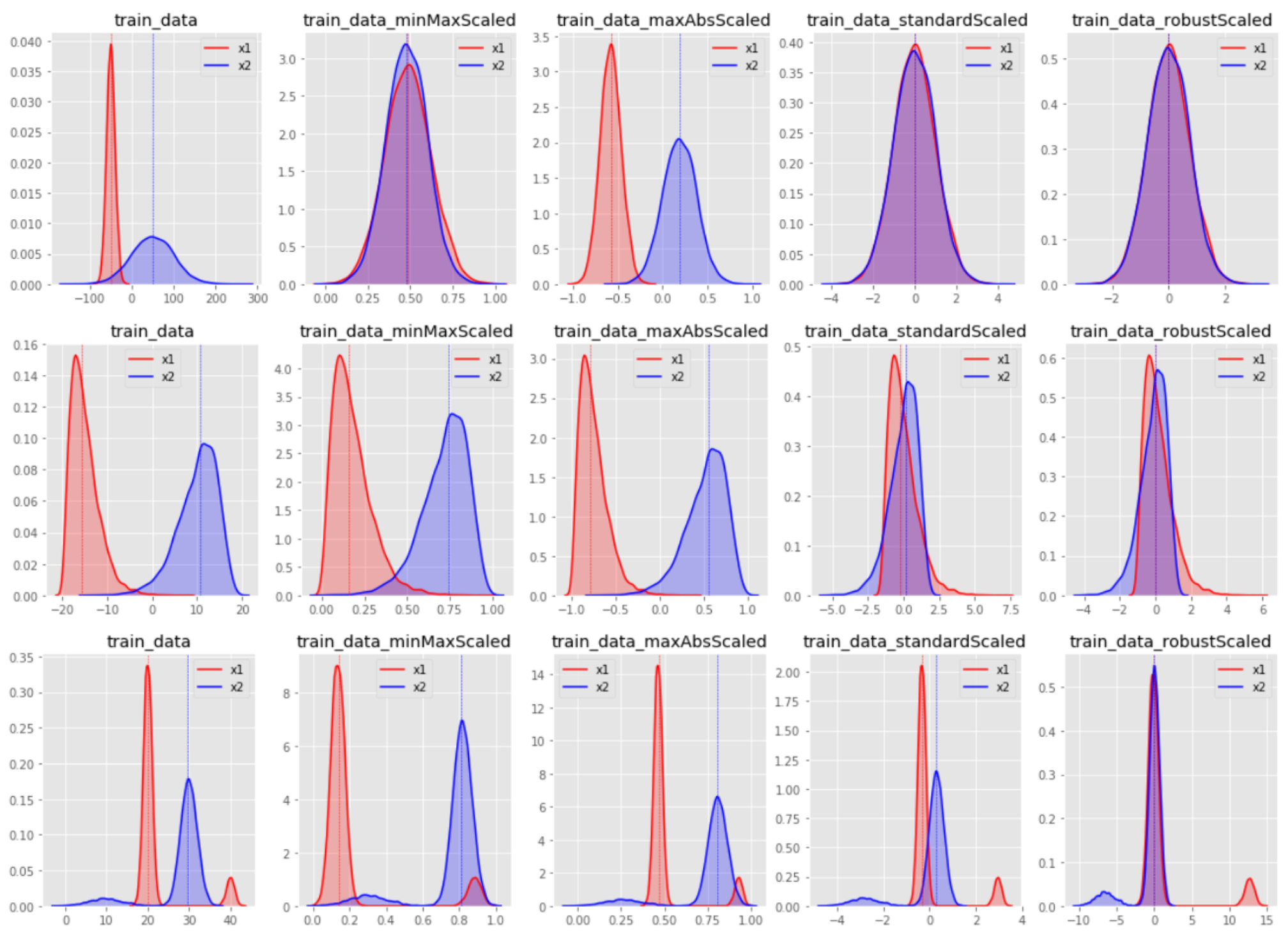
df_power = pd.DataFrame(power_data, columns=data.columns)📌 스케일링 방법별 변환 결과
🙏 Reference
https://ctkim.tistory.com/entry/%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%8A%A4%EC%BC%80%EC%9D%BC%EB%A7%81Data-Scaling
https://junklee.tistory.com/18
https://wooono.tistory.com/96
https://lovelydiary.tistory.com/417
https://jhryu1208.github.io/data/2020/12/03/ML_dataprocessing_scaler_control/
