0. Introductoin
부제목(Pre-training of Deep Bidirectional Transformers for
Language Understanding)에서 알 수 있듯이 BERT의 주요 특징으로는 다음과 같다.
- Pre - training parameters 사용
-> Large - dataset에 대한 self-supervised learning이 이를 가능하게 했다.
- Transformer Encoder 사용
-> Bidirectional Encoder Representations from Transformers. BERT는 Transformer 아키텍쳐에서 인코더 부분만 따로 분리해서 사용했다. 그럼 본격적으로 BERT에 대해서 자세히 알아보자
- 모든 Embeddings은 학습 가능한 parameter다.
-> 예를들어, Transformer에서는 positional encoding의 경우 학습의 대상이 아니였지만 BERT에서는 이것 역시 하나의 Embedding으로 간주해서 학습의 대상으로 삼았다. 또한 Token type embdding 역시 학습 가능하게 해놓았다.
주요한 특징은 위와 같고 하나 하나 살펴 보도록 하자.
1. What is BERT?
BERT는 위에서 언급한 것과 같이 Bidirectional Encoder Representations from Transformers의 준말로서 트랜스포머를 이용하여 구현되었으며, 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델입니다.
BERT 는 크게 pre-training 단계와 fine-tuning 단계로 구분 할 수 있습니다.
Pre-training 단계에서는 레이블링 하지 않는 데이터를 기반으로 학습을 진행한다. Fine-tuning 과정에서 모델은 우선적으로 pre-train된 파라미터로 초기화된다. 이후 모델을 레이블링된 데이터로 fine-tuning 한다. 여기서 fine -tunning이란 다른 작업에 대해서 파라미터 재조정을 위한 추가 훈련 과정을 말한다. 예를들어 기존에 위키피디아 데이터로 pre-training것을 바탕으로 스팸 분류기를 만다는 것을 예를 들 수 있다. 아래 그림은 pre-training과 fine-tunning의 예를 보여준다.
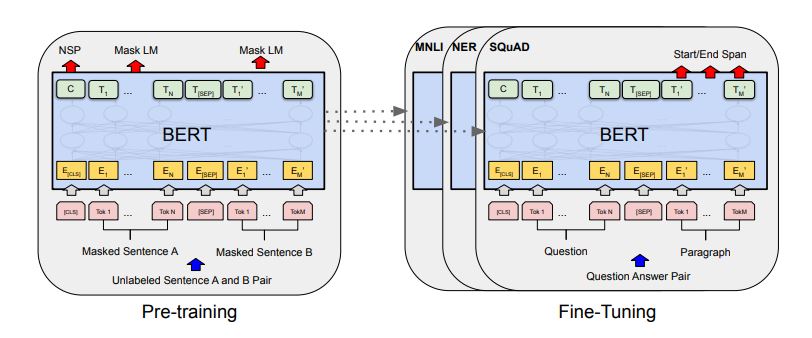
[출처] : https://arxiv.org/pdf/1810.04805.pdf
2. Model의 크기 및 구조
위의 특징 2번에서 서술한 것처럼 BERT는 Transformer의 Encoder 구조와 동일하다.
크기에 따라서 단지 층의 개수가 다를 뿐이다. Base 버전에서는 총 12개를 쌓았으며, Large 버전에서는 총 24개를 쌓았습니다.
L : layer 수
A : Attetion head 수
D :
- BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
3. Embedding
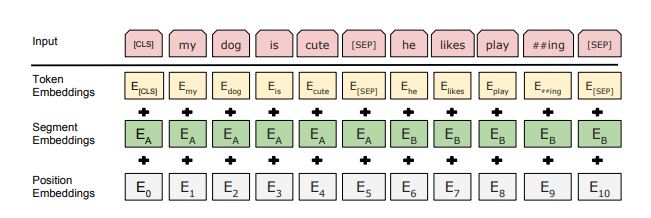
[출처] : https://arxiv.org/pdf/1810.04805.pdf
BERT는 모든 Embedding이 학습 가능한 파라미터입니다.
위의 그림에서는 input representation을 보여주고 있는데 하나의 input은 Token Embeddings, Segment Embeddings 그리고 Position Embeddings의 element-wise summation으로 표현이 가능합니다. 여기서 눈여겨 볼만 한 특징으로는 Position Embeddings역시 Transformer와는 다르게 학습의 대상이 되었으며 Bert는 하나의 input으로 여러 문장이 들어 올 수 있는데 이러한 문장들을 구분하기 위해서 특별한 토큰들이 사용됩니다.
CLS(Special classification token)의 경우 모든 문장의 가장 첫번째로 삽입 되는 token을 의미하고 SEP(Special Separator token)의 경우 문장과 문장 사이에 위치하여 두 문장을 구분 시키는 token을 의미합니다.
실습 코드 링크
Transformer의 인코더를 활용한 실습입니다.
https://colab.research.google.com/drive/1-9JqRRAD2FQFNiPzYCTytplqIqC22gXS?usp=sharing
https://colab.research.google.com/drive/1vmL2l1w6snngMK5UUH8V2pmN57rjwMDP?usp=sharing
참고 자료
https://arxiv.org/pdf/1810.04805.pdf
