시작하기 전에 import 하기
import numpy as np import pandas as pd import numba
함수를 이용한 열 단위 결합 (combine)
DataFrame.combine(other, func, fill_value=None, overwrite=True)
개요
combine 메서드는 두 pandas 객체를 func함수를 이용하여 결합하는 메서드입니다.
사용법
기본 사용법
self.combine(other, func, fill_value=None, overwrite=True)
other : 결합 할 DataFrame객체 입니다.
func : 결합에 이용할 함수 입니다.
fill_value : 결합하기전 Na의 값을 이 값으로 대체합니다.
overwrite : other에 존재하지 않는 self의 열의 값을 NaN으로 대체합니다.
예시
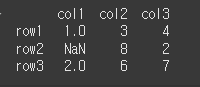
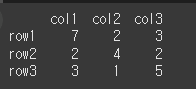
먼저 np.nan이 포함된 간단한 3x3짜리 데이터 2개를 만들어보겠습니다.
n=np.nan col = ['col1','col2','col3'] row = ['row1','row2','row3'] data1 = [[1,3,4], [n,8,2], [2,6,7]] data2 = [[7,2,3], [2,4,2], [3,1,5]] df1 = pd.DataFrame(data1,row,col) df2 = pd.DataFrame(data2,row,col)
(실행 예시1)
print(df1)
(실행 예시2)print(df2)
기본적인 사용법
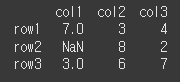
func 인수에 np.maximum을 입력하여 df1과 df2의 요소를 비교, 큰 값으로 결합하여 보겠습니다.
print(df1.combine(df2,np.maximum))
두 DataFrame 객체의 각 요소중 큰 값들로만 이루어진 것을 확인할 수 있습니다.
fill_value를 이용하여 결측치 채우기
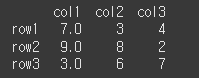
fill_value에 값을 입력하면, 결측치가 해당 값으로 채워진 후 결합이 진행됩니다.print(df1.combine(df2,np.maximum,fill_value=9))
col1, row2의 값이 NaN에서 9로 변경 된후 np.maximum이 진행된 것을 확인할 수 있습니다.
overwrite 인수의 사용
overwrite인수는 other에 존재하지 않는 self의 열의 요소를 NaN으로 변경하는 메서드입니다.
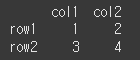
먼저 이해를 돕기 위해 2x2 데이터인 df3을 만들어 보겠습니다.col3 = ['col1','col2'] row3 = ['row1','row2'] data3 = [[1,2], [3,4]] df3 = pd.DataFrame(data3, row3, col3) print(df3)
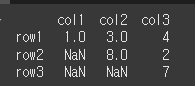
overwrite가 False일 경우 존재하지 않는 열에 대해서는 기존값으로 채워집니다.
print(df1.combine(df3, np.maximum,overwrite=False))
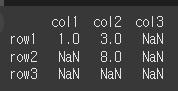
overwrite가 True일 경우 존재하지 않는 열에 대해서는 NaN으로 채워집니다.
col3의 값이 모두 NaN으로 채워진 것을 확인할 수 있습니다.print(df1.combine(df3, np.maximum,overwrite=True))
다른 객체로 결측치 덮어쓰기 (combine_first)
DataFrame.combine_first(other)
개요
combine_first 메서드는 other의 값으로 self(df)의 NaN값을 덮어쓰는 메서드입니다.
사용법
self.combine_first(other)
other : self객체의 결측치를 덮어쓸 객체 입니다.
예시
기본 사용법
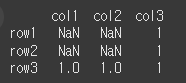
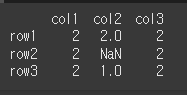
먼저 np.nan이 포함된 간단한 3x3짜리 데이터 2개를 만들어보겠습니다.n=np.nan col = ['col1','col2','col3'] row = ['row1','row2','row3'] data1 = [[n,n,1], [n,n,1], [1,1,1]] data2 = [[2,2,2], [2,n,2], [2,1,2]] df1 = pd.DataFrame(data1,row,col) df2 = pd.DataFrame(data2,row,col)
(실행 예시1)
print(df1)
(실행 예시2)print(df2)
기본적인 사용법
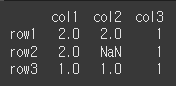
self객체의 NaN값을 other객체의 같은위치의 인수로 덮어쓰기 합니다.
만약 self에서 NaN인 값이 other에서도 NaN이라면 NaN을 출력합니다.print(df1.combine_first(df2))
인덱스기준 병합 (join)
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
개요
join 메서드는 두 객체를 인덱스 기준으로 병합하는 메서드 입니다.
사용법
self.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
other : self와 합칠 객체 입니다.
on : self의 열이나 인덱스 중에서 other의 어떤 열을 기준으로 결합할지 입니다.
즉, other의 (인덱스 기준이 아닌) 열 기준으로 결합할 때 on인수를 사용합니다.
how : {left : self기준 / right : other기준 / inner : 교집합 / outer : 합집합} 출력할 인덱스의 기준입니다.
lsuffix / rsffix : 이름이 중복되는 열이 있을 때 그 열에 추가로 붙일 접미사입니다.
lsuffix는 self의 열에 붙을 접미사고, rsuffix는 other의 열에 붙을 접미사입니다.
sort : 출력되는 데이터의 index를 사전적으로 정렬할지 여부입니다.
예시
기본 사용법
먼저 3개의 데이터를 만들겠습니다.
df1 : row1, row2, row3을 가지며 col1을 가짐
df2 : row3, row4를 가지며 col2를 가짐
df3 : row3, row4를 가지며 col1을 가짐, 즉 df1과 중복되는 열을 가짐
(사용 예시1)
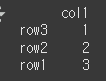
df1 = pd.DataFrame({'col1':[1,2,3]},index=['row3','row2','row1']) print(df1)
(사용 예시2)df2 = pd.DataFrame({'col2':[13,14]},index=['row4','row3']) print(df2)
(사용 예시3)df3 = pd.DataFrame({'col1':[23,24]},index=['row4','row3']) print(df3)
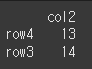
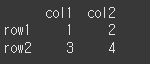
how를 통한 인덱스의 설정
how인수를 통해 인덱스의 기준을 어떤 값으로 할지 정할 수 있습니다.
how=left인 경우 (기본값) df1의 인덱스를 기준으로 합니다.print(df1.join(df2,how='left'))
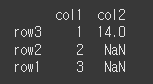
how=right인 경우 df2의 인덱스를 기준으로 합니다.
print(df1.join(df2,how='right'))
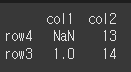
how=outer인 경우 df1와 df2의 인덱스의 합집합을 기준으로 합니다.
print(df1.join(df2,how='outer'))
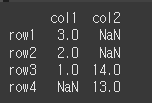
how=inner인 경우 df1와 df2의 인덱스의 교집합을 기준으로 합니다.
print(df1.join(df2,how='inner'))
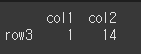
sort 인수를 통한 인덱스의 정렬
sort인수를 True로 설정할 경우 인덱스의 값을 사전적으로 정렬 할 수 있습니다.
sort가 False 인경우(기본값)print(df1.join(df2,how='left'))
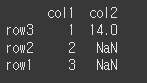
sort가 True 인경우 인덱스가 정렬 된 것을 확인할 수 있습니다.
print(df1.join(df2,how='left',sort=True))
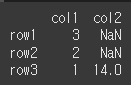
lsuffix / rsuffix 인수를 통해 중복 열 구분하기
df1과 df3은 col1이라는 이름이 중복된 열을 가지기 때문에, join메서드를 사용할 경우 오류가 발생하게 됩니다.
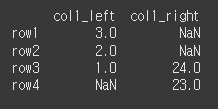
이때, lsuffix / rsuffix 인수를 입력함으로서 기존 열 이름에 접미사를 붙일 수 있습니다.print(df1.join(df3,how='outer',lsuffix="_left",rsuffix='_right'))
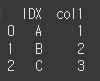
인덱스가 아닌 열 기준으로 결합하기(+ on 인수의 사용) 먼저 IDX라는 이름의 열을 갖는 두 객체를 생성해보겠습니다.
(실행 예시1)df4 = pd.DataFrame({'IDX':['A','B','C'],'col1':[1,2,3]}) print(df4)
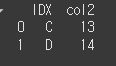
(실행 예시2)df5 = pd.DataFrame({'IDX':['C','D'],'col2':[13,14]}) print(df5)
join메서드는 기본적으로 index를 기준으로 결합하기 때문에, 열 기준으로 결합하기 위해서는
set_index메서드를 활용해 열을 인덱스로 변경하여 join메서드를 사용하면 됩니다.print(df4.set_index('IDX').join(df5.set_index('IDX')))
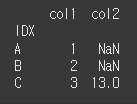
하지만 위와 같이 진행 할 경우 기존 인덱스가 열 값으로 변경됩니다.
이를 방지하고 순수하게 열 기준으로 병합하려면 on 인수를 사용하면 됩니다.print(df4.join(df5.set_index('IDX'),on='IDX'))
객체병합 (merge)
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
개요
merge메서드는 두 객체를 병합하는 메서드입니다. join과 비슷하지만 더 세부적인 설정이 가능한 메서드로,
인덱스-열 기준 병합도 가능하며, indicator인수를 통한 병합정보확인, validate를 통한 병합방식 확인등이 가능합니다.
사용법
left.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
right: left와 함께 병합할 객체입니다.
how : 병합시 기준이 될 인덱스를 정하는 방식입니다. left는 기존객체, right는 병합할 객체, inner은 두 객체의 인덱스의 교집합, outer은 두 객체의 인덱스의 합집합, cross는 행렬곱 입니다.
on : 열 기준 병합시 기준으로할 열의 이름이 양측이 동일하다면, on인수에 입력함으로써 기준 열을 정할 수 있습니다.
left_on / right_on : 열기준 병합 시 기준으로 할 열의 양측 이름이 다르다면, 각각 어떤 열을 기준으로 할지 정해줍니다.
열의 이름을 입력하면 됩니다.
left_index / right_index : 인덱스 기준 병합 시 True로 하면 해당 객체의 인덱스가 병합 기준이됩니다.
즉 left_on을 입력하고 right_index를 True로 한다면 열-인덱스 기준 병합도 가능합니다.
sort : 병합 후 인덱스의 사전적 정렬 여부입니다. join메서드와 기능이 동일하므로 참고 바랍니다.
suffixes : 병합할 객체들간 이름이 중복되는 열이 있다면, 해당 열에 붙일 접미사를 정합니다.
기본적으로 join메서드의 lsuffix / rsuffix와 기능이 동일하지만, suffixes인수는 튜플로 두 값을
한번에 입력한다는 차이가 있습니다.
copy : 사본을 생성할지 여부입니다.
indicator : True로 할경우 병합이 완료된 객체에 추가로 열을 하나 생성하여 병합 정보를 출력합니다.
validate : {'1:1' / '1:m' / 'm:1' / 'm:m'} 병합 방식에 맞는지 확인할 수 있습니다. 만약 validate에 입력한 병합방식과, 실제 병합 방식이 다를경우 오류가 발생됩니다.
예를들어, validate="1:m"으로 입력하였는데, 실제로 m:1 병합방식일 경우 오류가 발생됩니다.
예시
기본 사용법
인수가 많은만큼 예시가 많기 때문에, 설명할때마다 샘플 객체를 만들어서 설명 진행하겠습니다.
열 기준으로 병합 (left_on / right_on)
left_on / right_on에 열 이름을 입력하므로서 열 기준으로 병합이 가능합니다.
먼저 객체 2개를 만들어 보겠습니다.
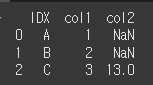
(객체 1)df1 = pd.DataFrame({'IDX1':['a','b','c','a'],'VAL':[1,2,3,4]}) print(df1)
(객체 2)df2 = pd.DataFrame({'IDX2':['a','c','d'],'VAL':[5,6,7]}) print(df2)
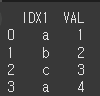
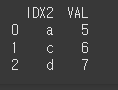
df1에서는 IDX1을, df2에서는 IDX2를 기준으로 하여 두 객체를 병합하겠습니다.
IDX1과 IDX2의 값을 매칭하여 병합된 후 이름이 같은 VAL열에 대해서는 _x와 _y가 붙었습니다.print(df1.merge(df2, left_on='IDX1',right_on='IDX2'))
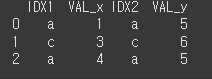
suffixes를 통한 동명인 열 구분
suffixes에 ('_left', '_right')를 입력하므로써 열 이름에 _left, _right를 붙일 수 있습니다.print(df1.merge(df2, left_on='IDX1',right_on='IDX2',suffixes=('_left','_right')))``` 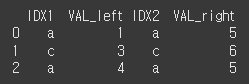
인덱스 기준으로 병합(left_index / right_index)
left_index / right_index를 통해 인덱스 기준으로 두 객체를 병합할 수 있습니다.
먼저 병합할 두 객체를 만들어보겠습니다.
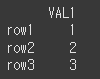
(객체1)df3 = pd.DataFrame({'VAL1':[1,2,3]},index=['row1','row2','row3']) print(df3)
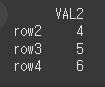
(객체2)df4 = pd.DataFrame({'VAL2':[4,5,6]},index=['row2','row3','row4']) print(df4)
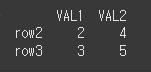
left_index와 right_index를 True로 입력하여 두 객체 모두 인덱스를 기준으로 병합할 수 있습니다.
print(df3.merge(df4, left_index=True,right_index=True))
열과 인덱스를 혼합하여 병합하기
left_on / right_on 과 left_index / right_index를 이용하여 양쪽의 기준을 설정해줌으로서, 인덱스와 열의 혼합 병합도 가능합니다.
예시를 위해서 새 객체 두개를 만들어보겠습니다.
df5는 인덱스를, df6은 열을 기준으로 하겠습니다.
(실행 예시1)df5 = pd.DataFrame({'VAL1':[1,2,3]},index=['row1','row2','row3']) print(df5)
(실행 예시2)df6 = pd.DataFrame({'IDX':['row2','row3','row4'],'VAL2':[4,5,6]}) print(df6)
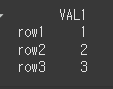
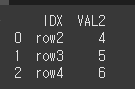
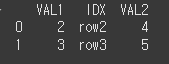
이제 left_index는 True로하여 인덱스를 기준으로하고 right_on은 IDX로 하여 열 기준으로 병합하겠습니다.
print(df5.merge(df6, left_index=True,right_on='IDX'))
how 인수의 사용
how인수를 사용하여 병합된 객체의 인덱스의 기준을 정할 수 있습니다.
먼저 예시에 이용될 두 객체를 만들어 보겠습니다.
(객체 1)df7 = pd.DataFrame({'IDX':['a','b','c','a'],'VAL':[1,2,3,4]}) print(df7)
(객체 2)df8 = pd.DataFrame({'IDX':['a','c','d'],'VAL':[5,6,7]}) print(df8)

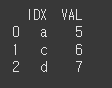
how=left인 경우 왼쪽 객체의 인덱스를 기준으로 합니다.
print(df7.merge(df8,how='left',on='IDX'))
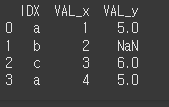
how=right인 경우 오른쪽 객체의 인덱스를 기준으로 합니다.
print(df7.merge(df8,how='right',on='IDX'))
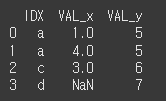
how=inner인 경우 양쪽 객체 모두가 공통으로 갖는 인덱스를 기준으로 합니다.(교집합)
print(df7.merge(df8,how='inner',on='IDX'))
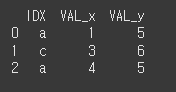
how=outer인 경우 양쪽 객체의 인덱스 모두를 기준으로 합니다.(합집합)
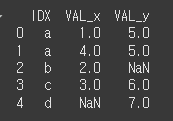
print(df7.merge(df8,how='outer',on='IDX'))
cross에 대해서는 뒤에 후술하겠습니다.
indicator인수를 통한 병합 정보 출력
indicator인수를 True로 할 경우 마지막 열에 _merge열을 추가하여 병합 정보를 출력합니다.print(df7.merge(df8,how='outer',on='IDX',indicator=True))
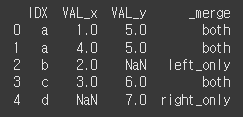
validate를 통한 병합방식 검증
validate인수에 값을 입력하여 해당 병합방식이 맞는지 검증이 가능합니다. 병합 방식이 다를경우 오류를 출력합니다.
1:m인지 검증print(df7.merge(df8,how='outer',on='IDX',validate='1:m'))

m:1인지 검증. 병합 방식이 m:1이 맞기 때문에 결과값을 출력합니다.
print(df7.merge(df8,how='outer',on='IDX',validate='m:1'))
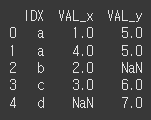
how인수에 cross를 적용하는 경우
how인수중 cross는 행렬의 곱집합을 의미합니다. 단순히 말하면 행렬의 모든 경우의수를 출력합니다.
예시를 위해 두 객체를 생성해보겠습니다.
(실행 예시1)df9 = pd.DataFrame({'IDX1':['a','b']}) print(df9)
(실행 예시2)df10 = pd.DataFrame({'IDX2':['c','d']}) print(df10)
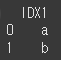
이제 how인수에 cross를 입력하므로써 두 객체의 행렬곱을 출력하겠습니다.
print(df9.merge(df10,how='cross'))
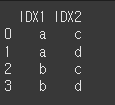
객체 병합_결측제어 가능 (align)
DataFrame.align(other, join='outer', axis=None, level=None, copy=True, fill_value=None, method=None, limit=None, fill_axis=0, broadcast_axis=None)
개요
align메서드는 두 객체를 특정 기준들에 맞추어 정렬하는 메서드입니다.
두개의 데이터를 튜플 형태로 반환한다는것을 반드시 명심하시기 바랍니다.
인수들에 따라 다양한 구현이 가능하므로 아래 사용법을 참고 바랍니다.
사용법
self.align(other, join='outer', axis=None, level=None, copy=True, fill_value=None, method=None, limit=None, fill_axis=0, broadcast_axis=None)
other : self와 함께 정렬할 객체 입니다.
join : {inner / left / right / outer} 정렬 기준이 될 인덱스 입니다. inner이면 교집합, left면 self의 인덱스, right면 other의 인덱스, outer이면 합집합으로 인덱스를 사용합니다.
axis : {0 : index / 1 : columns} 정렬할 레이블입니다. 기본값으로 두 축 모두 정렬합니다.
level : multi index의 경우 실행할 수준(level)을 설정합니다.
copy : 사본을 생성할지의 여부입니다.
fill_value : 결측치를 어떤 값으로 채울지의 여부입니다. 기존 객체에 포함된 결측치의 경우는 바뀌지 않습니다.
method : {ffill / bfill} 결측치를 어떻게 채울지 여부입니다. ffill의 경우 위의값과 동일하게, bfill의 경우 아래 값과 동일하게 채웁니다.
limit : 결측치를 몇개나 채울지 여부입니다. limit에 설정된 갯수만큼만 결측치를 변경합니다.
fill_axis : {0 : index / 1 : columns} method와 limit를 가로로 적용할지 세로로 적용할지 여부입니다.
broadcast_axis : {0 : index / 1 : columns} 어느 축을 기준으로 브로드캐스트할지 여부입니다.
브로드캐스트란 서로 차원이 다른 두 객체에 대해서 저차원 데이터의 차원을 고차원 데이터에 맞추는 과정입니다.
자세한것은 [추후 brodcast항목 추가 예정] 에서 확인 가능합니다.
예시
기본 사용법
먼저 일부 레이블을 공유하는 3x3짜리 데이터 2개를 만들어보겠습니다.
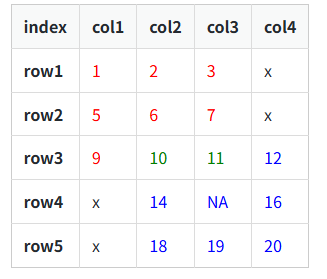
전체적으로 보면 아래와 같습니다.(빨강이 df1, 파랑이df2, 녹색이 레이블이 겹치는구간)
편의를 위해 겹치는 부분의 값을 동일하게 했습니다.
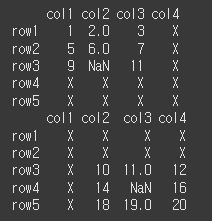
두개의 데이터를 튜플 형태로 반환하기 때문에, 달라도 상관없습니다.n=np.nan col1 = ['col1','col2','col3'] row1 = ['row1','row2','row3'] data1 = [[1,2,3],[5,6,7],[9,n,11]] col2 = ['col2','col3','col4'] row2 = ['row3','row4','row5'] data2 = [[10,11,12],[14,n,16],[18,19,20]] df1 = pd.DataFrame(data1,row1,col1) df2 = pd.DataFrame(data2,row2,col2)
(실행 예시1)
print(df1)
(실행 예시2)print(df2)
join 인수의 사용을 통한 레이블 설정
join 인수를 이용해 {outer : 합집합 / left : df1기준 / right : df2기준 / inner : 교집합} 인 index로 출력합니다.
두개의 데이터를 튜플 형태로 반환하기 때문에 리스트 슬라이싱으로 따로 print를 진행해보겠습니다.
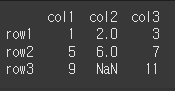
outer로 출력시 레이블이 df1과 df2 모두의 합집합으로 사용되고 있는것을 알 수 있습니다.print(df1.align(df2,join='outer')[0]) print(df1.align(df2,join='outer')[1])
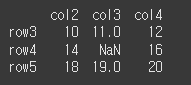
left로 출력시 df1의 레이블만 사용되는 것을 알 수 있습니다.
print(df1.align(df2, join='left')[0]) print(df1.align(df2, join='left')[1])
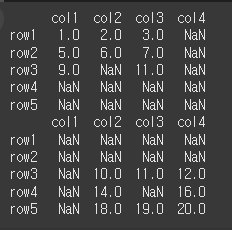
left로 출력시 df1의 레이블만 사용되는 것을 알 수 있습니다.
print(df1.align(df2,join='left')[0]) print(df1.align(df2,join='left')[1])
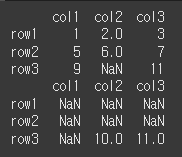
right로 출력시 df2의 레이블만 사용되는 것을 알 수 있습니다.
print(df1.align(df2,join='right')[0]) print(df1.align(df2,join='right')[1])
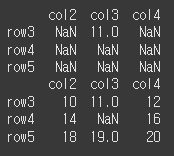
inner로 출력시 레이블이 df1과 df2 모두의 교집합으로 사용되고 있는것을 알 수 있습니다.
print(df1.align(df2,join='inner')[0]) print(df1.align(df2,join='inner')[1])
axis 인수의 사용을 통한 정렬 축 설정
axis인수를 통해 정렬을 진행 할 축을 정할 수 있습니다. 기본적으로 두축 모두 입니다.
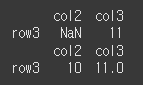
df1에 대해서만 inner로 출력하여 확인해보겠습니다.
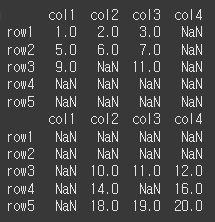
axis를 0으로 하였을 경우 행 기준 inner인 row3만 정렬되었습니다.print(df1.align(df2,join='inner',axis=0)[0])
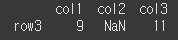
axis를 1으로 하였을 경우 열 기준 inner인 col2, col3만 정렬되었습니다.
print(df1.align(df2,join='inner',axis=1)[0])
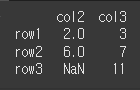
fill_value를 사용한 결측치 입력
fill_value를 사용해서 결측치를 원하는 값으로 변경이 가능합니다.
단, 기존 객체에 입력되어있던 결측치의 경우 변경되지 않습니다.print(df1.align(df2,join='outer',fill_value='X')[0]) print(df1.align(df2,join='outer',fill_value='X')[1])
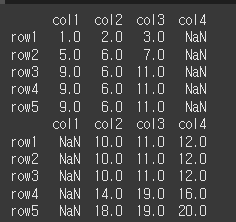
method / limit인수를 사용한 결측치 보정
method인수는 {ffill / bfill}를 이용해 위쪽 또는 아래쪽 값으로 결측치 보정이 가능합니다.
limit인수의 경우는 method인수를 통해 결측치 보정할 때, 몇개의 값을 보정할지 설정합니다.
ffill로 입력 시 결측값을 바로 위의 값과 동일하게, bfill로 입력 시 결측값을 바로 아래 값과 동일하게 변경 된것을 확인할 수 있습니다.print(df1.align(df2,join='outer',method='ffill')[0]) print(df1.align(df2,join='outer',method='bfill')[1])
limit 설정시 각 레이블에 대해서 아래와 같이 설정한 갯수만 변경 됩니다.
print(df1.align(df2,join='outer',method='bfill',limit=1)[1])
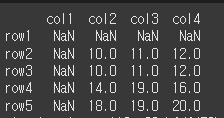
fill_axis 인수의 사용
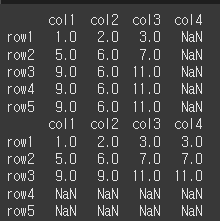
fill_axis는 method및 limit를 어느축 기준으로 실행할지 여부입니다. 즉, 가로로 할지 세로로할지 여부입니다.print(df1.align(df2,join='outer',method='ffill',fill_axis=0)[0]) print(df1.align(df2,join='outer',method='ffill',fill_axis=1)[0])
업데이트 (update)
DataFrame.update(other, join='left', overwrite=True, filter_func=None, errors='ignore')
개요
update메서드는 DataFrame의 열을 other객체의 동일한 열의 값으로 덮어씌우는 메서드입니다.
반환값 없이 원본이 변경됩니다.
사용법
self.update(other, join='left', overwrite=True, filter_func=None, errors='ignore')
other : self에 덮어씌울 객체 입니다.
join : {left} 기준이 될 인덱스 입니다. left만 선택 가능하므로 무시해도됩니다.
overwrite : {True / False} 덮어씌울 방식입니다. True면 self의 모든 데이터에 other을 덮어씌웁니다.
False면 self에서 Na인 값에 대해서만 덮어씌우기를 진행합니다.
filter_func : 덮어씌울값을 함수로 정할 수 있습니다.
errors : {raise / ignore} raise일 경우 self와 other 모두 Na가 아닌 값이 있을경우 오류를 발생시킵니다.
예시
기본 사용법
먼저 3x2짜리 데이터 2개를 만들어보겠습니다.
(데이터 1)
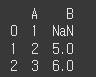
df1 = pd.DataFrame({'A':[1,2,3],'B':[n,5,6]}) print(df1)
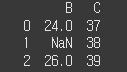
(데이터 2)df2 = pd.DataFrame({'B':[24,n,26],'C':[37,38,39]}) print(df2)
overwrite인수로 업데이트 방식 설정
overwrite인수가 True면 df1과 df2가 이름을 공유하는 열에 대해서 df2의 값을 df1에 덮어씌웁니다.
False일 경우 df1에서 Na인 값에 대해서만 덮어씌우기를 진행합니다.
df2에서 Na인 값의 경우 덮어씌워지지 않습니다.
overwrite=True일 경우(기본값)df1.update(df2,overwrite=True) print(df1)
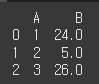
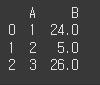
overwrite=False일 경우
df1.update(df2,overwrite=False) print(df1)

filter_func로 원하는 값만 업데이트
filter_func에 함수를 넣음으로서 원하는 값만 업데이트가 가능합니다.
6인 값에 대해서만 업데이트를 하도록 filter_func를 설정하겠습니다df1.update(df2,filter_func=lambda x: x==6) print(df1)
errors인수의 사용법
errors인수를 raise로 할 경우 df1과 df2 모두 같은 위치에 Na가 아닌 값이 있을 경우 오류를 발생시킵니다.df1.update(df2,errors='raise') print(df1)