시작하기 전에 import 하기
import numpy as np import pandas as pd import numba from pandas import DataFrame from datetime import datetime
열 인덱스 반복자 반환 (iter)
DataFrame.iter()
개요
iter 메서드는 열 인덱스를 map 오브젝트 형태의 반복자(iterator)로 반환하는 메서드입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.iter( )
예시
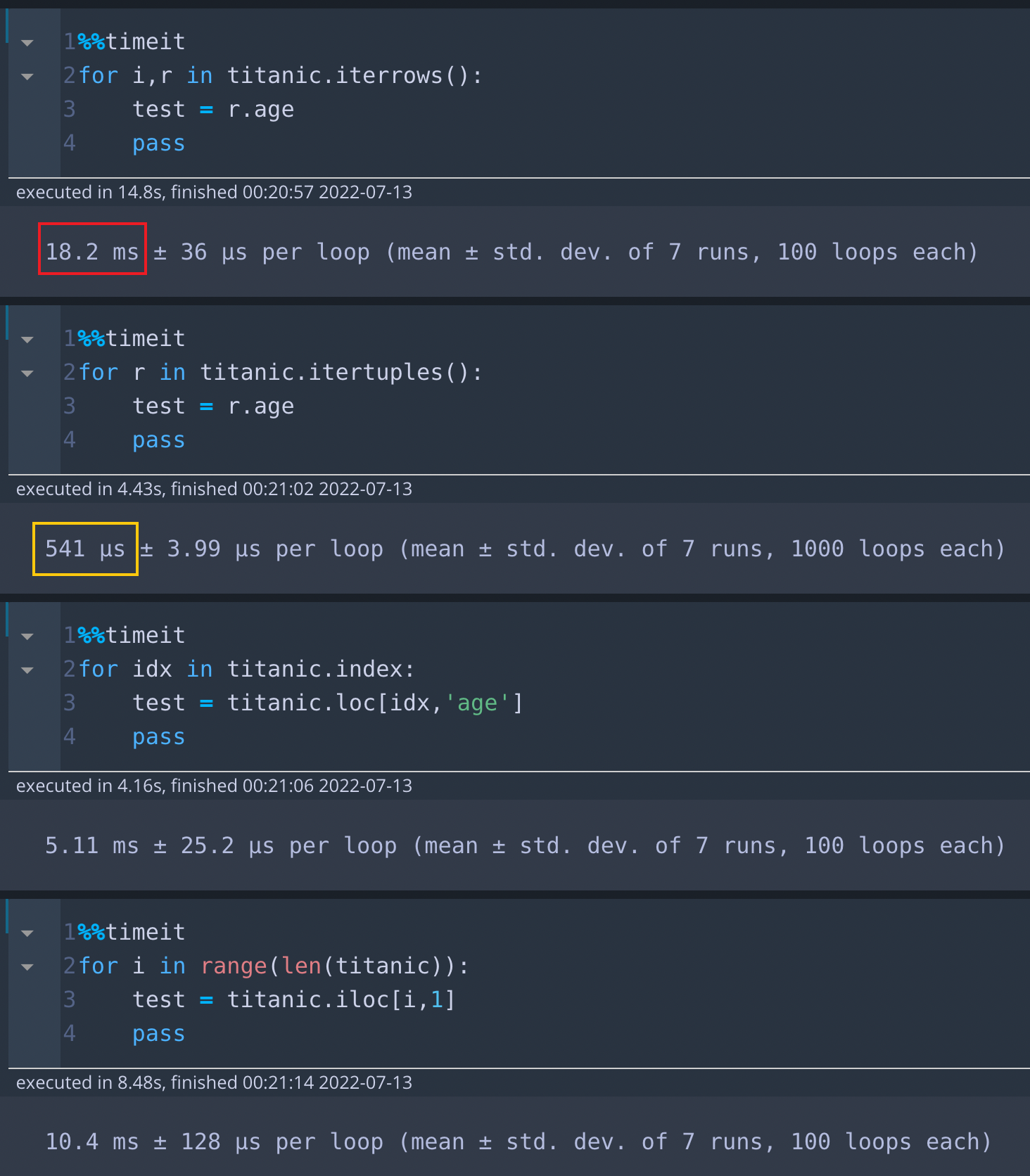
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
``python
data = {'col1':[1,2],'col2':[3,4]}
df = pd.DataFrame(data = data)
print(df)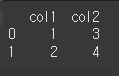
기본적인 사용법
기본적으로 df.iter( ) 형태로 사용하며, 열 인덱스의 map 오브젝트를 반환합니다.df2 = df.__iter__() print(df2)

map 오브젝트는 range함수처럼 하나씩 꺼내서 쓰는형태이기 때문에 단순 print로는 출력이 불가합니다.
반복자 (iterator)이기 때문에 next 메서드를 통해 하나씩 확인할 수 있습니다.
(실행 결과1)print(next(df2))
(실행 결과2)print(next(df2)) print(next(df2))

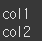
list 메서드를 이용하면 리스트 형태로 반환이 가능합니다.
print(list(df))
열과 내용의 반복자 반환 (items, iteritems)
DataFrame.items()
개요
items 메서드는 데이터의 열-행/데이터 정보를 튜플 형태의 generator 객체로 반환하는 메서드입니다.
(열 이름, 내용의 Series객체) 형태로 반환하는데, Series객체는 행, 값 형태로 반환됩니다.
※ iteritems 메서드와 동일한 메서드입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.items()
예시
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
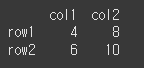
data = {'col1':[4,6],'col2':[8,10]} idx = ['row1','row2'] df = pd.DataFrame(data = data, index=idx) df2 = df.items() print(df)
기본적인 사용법
기본적으로 df.items() 형태로 사용하며, 출력 시 generator 객체인 것을 확인 할 수 있습니다.df2 = df.items() print(df2)

generator 역시 iterator(반복자) 로 for문이나 list로 내용을 확인 할 수 있습니다.
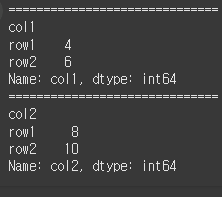
df2 = df.items() for i in df2: print("="*100) print(i)

for문을 한번 더 사용해서 튜플의 내용을 한 줄마다 출력하면 보다 더 직관적으로 확인할 수 있습니다.
df2 = df.items() for i in df2: print("="*30) for j in i: print(j)
행과 내용의 반복자 반환 (iterrows)
DataFrame.iterrows()
개요
iterrows 메서드는 데이터의 행-열/데이터 정보를 튜플 형태의 generator 객체로 반환하는 메서드입니다.
(행 이름, 내용의 Series객체) 형태로 반환하는데, Series객체는 열 - 값 형태로 반환됩니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.iterrows()
예시
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
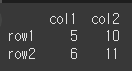
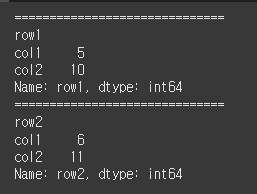
data = {'col1':[5,6],'col2':[10,11]} idx = ['row1','row2'] df = pd.DataFrame(data = data, index=idx) print(df)
기본적인 사용법
기본적으로 df.iterrows() 형태로 사용하며, 출력 시 generator 객체인 것을 확인 할 수 있습니다.df2 = df.iterrows() print(df2)

generator 역시 iterator(반복자) 로 for문이나 list로 내용을 확인 할 수 있습니다.
df2 = df.iterrows() for i in df2: print("="*30) print(i)
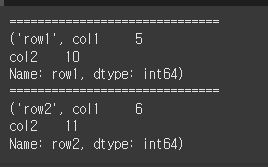
for문을 한번 더 사용해서 튜플의 내용을 한 줄마다 출력하면 보다 더 직관적으로 확인할 수 있습니다.
df2 = df.iterrows() for i in df2: print("=" * 30) for j in i: print(j)
튜플형태 반복자 반환 (itertuples)
DataFrame.itertuples(index=True, name='Pandas')
개요
itertuples 메서드는 데이터의 인덱스, 열-값 정보를 map오브젝트의 튜플 형태로 반환하는 메서드입니다.
튜플은 name인수를 통해 원하는named tuple로 출력이 가능합니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.itertuples(index=True, name='Pandas')
index : 인덱스를 출력할지 여부 입니다.
name : 출력하게 될 named tuple의 이름을 지정합니다. None으로 하면 일반 튜플로 출력되며 기본값은 Pandas입니다.
예시
먼저 기본적인 사용법 예시를위하여 2x2 짜리 데이터를 만들어 보겠습니다.
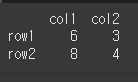
data = {'col1':[6,8],'col2':[3,4]} idx = ['row1','row2'] df = pd.DataFrame(data = data, index=idx) print(df)
기본적인 사용법
df.itertuples() 형태로 사용가능하며 기본적으로 map 오브젝트로 반환하기 때문에, list, next, for문 등으로 확인이 가능합니다.print(df.itertuples())

list를 이용해 출력해보면, 구성이 튜플(인덱스, 열=값, 열=값...) 형태인 것을 확인할 수 있습니다.
print(list(df.itertuples()))

index인수의 사용
index=False로 입력할 경우 반환되는 튜플값에서 인덱스 정보가 제외됩니다.print(list(df.itertuples(index=False)))

name인수의 사용
name인수를 지정해주면, 튜플이 namedtuple 형태로 반환됩니다. 기본값은 Pandas이며 None 입력시 일반 튜플로 반환합니다.
(사용 예시1)print(list(df.itertuples(name=None)))
(사용 예시2)print(list(df.itertuples(name="테스트")))


