시작하기 전에 import 하기
import numpy as np import pandas as pd import numba from pandas import DataFrame
행↔열 교환 (swapaxes)
DataFrame.swapaxes(axis1, axis2, copy=True)
개요
swapaxes메서드는 행/열을 바꿔주는 메서드입니다. 값들도 교환됩니다.
사용법
기본 사용법
df.swapaxes(axis1, axis2, copy=True)
axis1, axis2 : {0 : index / 1 : columns} 교환할 행과 열 입니다.
copy : 사본을 생성할지 여부입니다.
예시
먼저 2x2짜리 객체를 만들어보겠습니다.
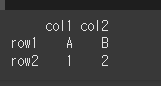
idx = ['row1','row2'] col = ['col1','col2'] data= [['A','B'],[1,2]] df = pd.DataFrame(data, idx, col) print(df)
기본적인 사용법
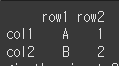
axis1과 axis2에 행/열을 지정하여 교환할 수 있습니다. 행<->열 교환이나 열<->행 교환이나 완벽히 동일합니다.print(df.swapaxes(axis1=0,axis2=1))
axis1과 axis2이 같다면, 당연히 원래 값과 같습니다.
print(df.swapaxes(axis1=1,axis2=1))
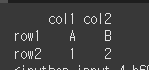
레이블명 변경 (rename)
DataFrame.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='ignore')
개요
rename 메서드는 레이블의 이름을 변경하는 메서드 입니다.
사용법
기본 사용법
df.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='ignore')
mapper : 변경할 {레이블명 : 값} 입니다. dict나 함수형태가 올 수 있는데, 축이 지정되어있지 않으므로 axis인수와 함께 사용해야 합니다.
axis : mapper의 변경값이 적용될 축 입니다.
index, columns : 변경할 {레이블명 : 값}입니다. 미리 축을 지정하기 때문에 axis인수와 병행사용할 수 없습니다.
copy : 사본을 생성할지 여부입니다.
inplace : Pandas 공통 인수인 inplace는 원본을 수정할지의 여부를 지정합니다.
level : Multi Index의 경우 레벨을 지정해줍니다.
errors : {'ignore' / 'raise'} mapper, index, columns에서 지정한 dict에 해당하는 key값이 없을경우, 오류를 발생시킬지 여부 입니다.
예시
먼저 2x2짜리 객체를 만들어보겠습니다. 레이블명 변경 관련 메서드이므로 보기 쉽게 값들은 전부 하이픈으로 하겠습니다.
data= [['-','-'],['-','-']] df1 = pd.DataFrame(data) print(df1)

mapper와 axis를 이용하는 방법
mapper를 이용해 변경 내용을 설정해준 경우, axis인수를 이용해 적용 축을 설정해주어야합니다.# mapper를 통해 0을 col1로, 1을 col2로 설정하고 축을 열(1:columns)로 설정 print(df1.rename(mapper={0:'col1',1:'col2'}, axis=1))
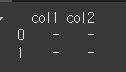
index나 columns를 이용하는 방법
index나 columns에 변경 내용을 설정해주는 경우 axis설정 없이 적용이 됩니다.# index에 변경값을 입력 print(df1.rename(index = {0:'row1',1:'row2'}))
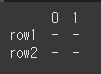
inplace인수를 이용한 원본 변경
pandas 공통사항으로 inplace=True인 경우 원본의 값이 변경됩니다.df1.rename(index={0:'row1',1:'row2'}, columns={0:'col1',1:'col2'},inplace=True) print(df1)
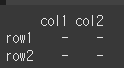
Multi Index의 경우
먼저 예시를 위한 Multi Index를 만들어 보겠습니다idx = [['row1','row1','row2','row2'],[1,2,3,4]] col = ['col1','col2'] data = [['-','-'],['-','-'],['-','-'],['-','-']] df2 = pd.DataFrame(data, idx, col) print(df2)
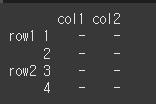
level의 지정
Multi Index의 경우 rename으로 레이블명을 변경할 경우 level을 통해 레벨을 설정해주어야 합니다.print(df2.rename(level=1, index={1:'val1',2:'val2',3:'val3',4:'val4',5:'val5'}))
레벨1 의 인덱스가 변경된 것을 확인할 수 있습니다. 그런데 { ... , 5:'val5'}는 존재하지 않는 인덱스인데, 오류가 발생하지 않았습니다.
이는 errors인수를 통해 오류 발생이 가능합니다.
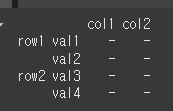
errors인수의 사용
errors는 기본적으로 ignore으로 존재하지 않은 인덱스에 대해 dict를 입력하더라도 오류를 발생시키지 않습니다.
위의 예시를 errors='raise'를 이용하여 다시 실행해보겠습니다.print(df2.rename(errors='raise',level=1, index={1:'val1',2:'val2',3:'val3',4:'val4',5:'val5'}))

축 이름 변경 (rename_axis)
DataFrame.rename_axis(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False)
개요
rename_axis메서드는 축의 이름을 지정하는 메서드입니다.
사용법
기본 사용법
df.rename_axis(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False)
mapper : 변경할 값 입니다. dict나 함수, 스칼라형태가 올 수 있는데, 축이 지정되어있지 않으므로 axis인수와 함께 사용해야 합니다.
axis : mapper의 변경값이 적용될 축 입니다.
index, columns : 변경할 축을 지정해서 값을 변경합니다.
copy : 사본을 생성할지 여부입니다.
inplace : Pandas 공통 인수인 inplace는 원본을 수정할지의 여부를 지정합니다.
예시
먼저 2x2짜리 객체를 만들어보겠습니다. 축 이름 변경 관련 메서드이므로 보기 쉽게 값들은 전부 하이픈으로 하겠습니다.
df = pd.DataFrame(data=[['-','-'],['-','-']],index=['row1','row2'],columns=['col1','col2']) print(df)
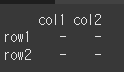
mapper와 axis를 이용하는 방법
mapper를 통해 변경값을 지정해주는 경우 axis를 통해 적용될 축을 지정해주어야 합니다.df = df.rename_axis(mapper='index',axis=0) print(df)
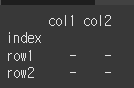
index나 columns를 이용하는 경우
index나 columns에 값을 지정해주는경우 별도의 축을 지정해줄 필요가 없습니다.df = df.rename_axis(columns='columns') print(df)
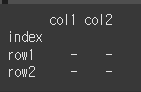
inplace의 사용
pandas 공통사항으로 inplace=True인 경우 원본을 변경하게 됩니다. 지정해준 축 이름을 대문자로 변경하는 함수와 함께 inplace를 사용해보겠습니다.df.rename_axis(index=str.upper, columns=str.upper, inplace=True) print(df)
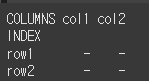
열을 인덱스로 설정 (set_index)
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
개요
set_index메서드는 기존의 열을 인덱스로 설정하는 메서드입니다.
사용법
기본 사용법
df.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
keys : 인덱스로 설정할 열의 이름입니다. list형태로 설정할 경우 Multi Index로 설정됩니다.
drop : 인덱스로 설정한 열을 기존 열에서 제거할지 여부입니다. 기본값은 True로 열에서 제거됩니다.
append : 기존 인덱스를 유지하면서 새 인덱스를 추가할 지 여부입니다.
inplace : pandas 공통 인수로 원본을 대체할지 여부입니다.
verify_integrity : 추가하려는 인덱스에 중복값이 있을경우 오류를 띄울지 여부 입니다.
예시
먼저 5x4 짜리 DataFrame 객체를 만들겠습니다.
data={'col1':['A','A','A','B','B'], 'col2':['[1]','[2]','[3]','[1]','[2]'], 'col3':[2,5,3,4,1], 'col4':['X','X','Y','Z','Z']} idx=['row1','row2','row3','row4','row5'] df = pd.DataFrame(data=data,index=idx) print(df)
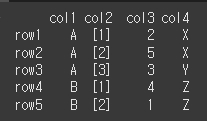
기본적인 사용법
keys로 인덱스가 될 열 이름을 지정할 수 있습니다.# col1을 인덱스로 만들기 print(df.set_index(keys='col1'))
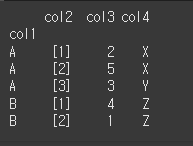
keys에 list가 입력될 경우 Multi Index 형태로 설정이 됩니다.
print(df.set_index(keys=['col1','col2']))
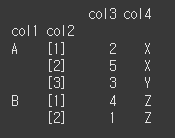
append 인수의 사용
append인수를 True로 설정 할 경우 기존 Index를 유지하고 새 인덱스를 추가하게됩니다.print(df.set_index(keys='col1',append=True))
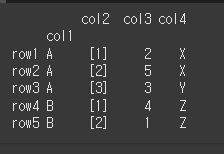
drop 인수의 사용
drop 인수가 False일 경우 인덱스가 설정된 이후에도 해당 열이 유지됩니다.
기본값은 True로 keys에 설정된 열이 인덱스로 설정될 경우 열이 삭제됩니다.print(df.set_index(keys='col1',drop=False))
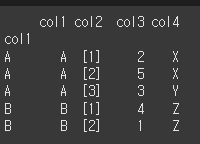
verify_integrity인수의 사용
verify_integrity인수의 기본값은 False로 인덱스에 중복된 값이 있더라도 출력합니다. 만약 True일 경우 중복값이 있다면 오류를 출력하게 됩니다.# 기본값은 False로 중복을 허용 print(df.set_index(keys='col4'))
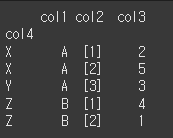
True일 경우 인덱스에 중복값이 있다면 오류를 출력하게됩니다.
print(df.set_index(keys='col4',verify_integrity=True))
(오류 코드)# True일 경우 인덱스에 중복값이 있다면 오류를 출력하게됩니다.<br> print(df.set_index(keys='col4',verify_integrity=True))

레이블명 변경 (set_axis)
DataFrame.set_axis(labels, axis=0, inplace=False)
개요
set_axis메서드는 레이블명을 원하는 값으로 변경하는 메서드입니다.
사용법
기본 사용법
df.set_axis(labels, axis=0, inplace=False)
labels : 변경할 이름입니다. list형태로 사용 가능합니다.
axis : {0 : index / 1 : columns} 변경값을 적용할 축 입니다.
inplace : pandas 공통인수인 inplace는 True인 경우 원본을 변경하게 됩니다.
예시
먼저 2x2 짜리 DataFrame 객체를 만들겠습니다.
df = pd.DataFrame(data=[[1,2],[3,4]]) print(df)
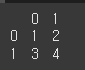
기본적인 사용법
labels에 변경할 값을 입력하고, axis를 통해 축을 설정해주어서 레이블명을 변경할 수 있습니다.
(사용 예시1)df=df.set_axis(labels=['row1','row2'],axis=0) print(df)
(사용 예시2)df = df.set_axis(labels=['col1','col2'],axis=1) print(df)
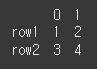
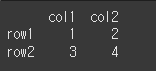
inplace인수의 사용
pandas 공통인수로 inplace가 True일 경우 원본값에 덮어씌우게 됩니다.
즉, df.set_axis(inplace=True) 는 df = df.set_axis( )와 완벽히 같은 기능을 수행합니다.df.set_axis(labels=['idx1','idx2'],axis=0,inplace=True) print(df)
접미사/접두사 (suffix / prefix)
DataFrame.add_prefix(prefix)
DataFrame.add_suffix(suffix)
개요
add_suffix와 add_preffix메서드는 각각 열 이름에 접미사/접두사를 붙이는 메서드 입니다.
사용법
기본 사용법
df.add_suffix(suffix)
df.add_prefix(prefix)
suffix / prefix : 열 이름에 추가할 문자열입니다.
예시
먼저 2x2 짜리 DataFrame 객체를 만들겠습니다.
df = pd.DataFrame(data=[[1,2],[3,4]]) print(df)

기본적인 사용법
add_suffix메서드를 이용할 경우 열 이름의 뒤쪽에 해당 문자열이 붙게 됩니다.print(df.add_suffix('_열'))

add_prefix메서드를 이용할 경우 열 이름의 앞쪽에 해당 문자열이 붙게 됩니다.
print(df.add_prefix('열_'))
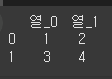
인덱스 변경 (reindex)
DataFrame.reindex(labels=None, index=None, columns=None, axis=None,method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
개요
reindex 메서드는 인덱스를 새 인덱스로 덮어씌우고 내용을 채우는 메서드 입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.reindex(labels=None, index=None, columns=None, axis=None,method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
labels : 변경할 값입니다. labels인수를 이용할 경우 axis인수를 통해 축을 지정해줘야합니다. 추가된 index의 경우 NaN을 요소로 갖습니다.
index / columns : 변경할 값입니다. 행과 열을 미리 지정해줍니다. 추가된 index의 경우 NaN을 요소로 갖습니다.
method : {bfill / ffill / nearest이 결측치를 채울 규칙입니다.
ffill : 바로 전 값으로 결측치를 채웁니다.
bfill : 바로 뒤 값으로 결측치를 채웁니다.
nearest : 근처의 유효값으로 결측치를 채웁니다.
※ 결측치를 채울 때 값의 전/후 값을 기준으로하는것이 아닌 인덱스의 전/후 인덱스를 기준으로 합니다.
copy : 사본을 생성할지 여부입니다.
level : Multi Index의 경우 레벨을 선택할 수 있습니다.
fill_value : 결측값을 이 값으로 변경할 수 있습니다.
limit : method인수를 사용할 경우 몇개까지 변경할지 제한할 수 있습니다
tolerance : method인수를 사용할 때 index가 다를 경우 허용 범위 입니다.
★│변경 전 인덱스 - 변경 후 인덱스│≤ tolerance 를 만족하게 method 적용 허용 범위를 정할 수 있습니다. 자세한건 예시 참고바랍니다.
예시
먼저 3x4 짜리 DataFrame 객체를 만들겠습니다.
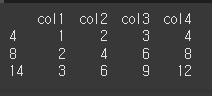
idx = [3,6,11] col = ['col1','col2','col3','col4'] data = [[1,2,3,4],[2,4,6,8],[3,6,9,12]] df = pd.DataFrame(data,idx,col) print(df)
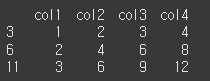
기본적인 사용법(+fill_value인수)
기본적으로 새 index가 될 list를 형성하고 labels / axis나 index / columns를 사용해서 적용 할 수 있습니다.
labels / axis를 이용할 경우col2 = ['col1','idx2','idx3','col4'] print(df.reindex(labels=col2,axis=1)) # labels로 변경값을 정해주면 axis를 이용해 적용할 축을 지정해줘야함.
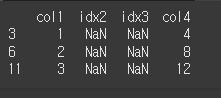
index / columns를 이용할 경우
print(df.reindex(columns=col2)) # index나 columns를 이용해 대상 축에 변경값을 바로 적용할 수 있다.
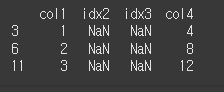
fill_value를 설정하면 NaN을 원하는 값으로 지정하여 변경할 수 있습니다.
print(df.reindex(columns=col2,fill_value='-'))
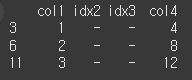
method 와 limit의 사용
method를 이용하면 결측치를 앞/뒤/근처의 인덱스를 기준으로 변경이 가능합니다.
먼저 기존 열에 새 열을 reindex메서드를 이용해 추가해보겠습니다.col3 = ['col0','col1','col2','col3','col4','col5','col6','col7'] print(df.reindex(columns=col3))
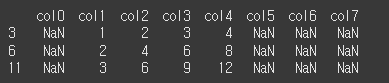
method='bfill'인 경우 뒤의 열의 값을 가져옵니다.
print(df.reindex(columns=col3,method='bfill'))
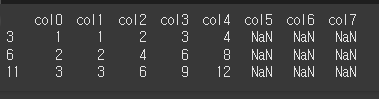
method='ffill'인 경우 앞의 열의 값을 가져옵니다.
print(df.reindex(columns=col3,method='ffill'))
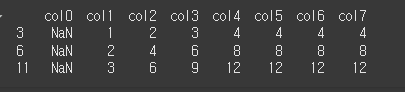
limit는 method로 변경할 열의 갯수를 제한할 수 있습니다.
print(df.reindex(columns=col3,method='ffill',limit=2))
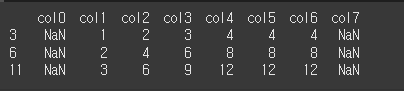
tolerance 인수의 사용
│변경 전 인덱스 - 변경 후 인덱스│≤ tolerance 를 만족하게 method 적용 허용 범위를 정할 수 있습니다.
tolerance=1인 경우idx2 = [4, 8, 14] print(df.reindex(index=idx2,method='ffill',tolerance=1))
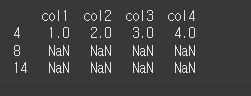
tolerance=2인 경우
idx2 = [4, 8, 14] print(df.reindex(index=idx2,method='ffill',tolerance=2))
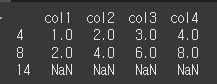
tolerance=3인 경우
idx2 = [4, 8, 14] print(df.reindex(index=idx2,method='ffill',tolerance=3))
인덱스 변경 (reindex_like)
DataFrame.reindex_like(other, method=None, copy=True, limit=None, tolerance=None)
개요
reindex_like메서드는 other의 인덱스를 기준으로 self의 인덱스와 값을 적용하는 메서드입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
self.reindex_like(other, method=None, copy=True, limit=None, tolerance=None)
method : {bfill / ffill / nearest이 결측치를 채울 규칙입니다.
ffill : 바로 전 값으로 결측치를 채웁니다.
bfill : 바로 뒤 값으로 결측치를 채웁니다.
nearest : 근처의 유효값으로 결측치를 채웁니다.
※ 결측치를 채울 때 값의 전/후 값을 기준으로하는것이 아닌 인덱스의 전/후 인덱스를 기준으로 합니다.
copy : 사본을 생성할지 여부입니다.
limit : method인수를 사용할 경우 몇개까지 변경할지 제한할 수 있습니다
tolerance : method인수를 사용할 때 index가 다를 경우 허용 범위 입니다.
★│변경 전 인덱스 - 변경 후 인덱스│≤ tolerance 를 만족하게 method 적용 허용 범위를 정할 수 있습니다.
reindex 메서드의 tolerance인수와 사용이 동일하므로 참고 바랍니다.
예시
먼저 self가 될 객체와, other가 될 객체를 만들어보겠습니다.
(실행 결과1)col1 = ['col1','col3','col6'] idx1 = ['row0','row2','row3'] data1 = [['A','X','+'],['B','Y','-'],['C','Z','=']] self = pd.DataFrame(data1, idx1, col1) print(self)
(실행 결과2)col2 = ['col1','col2','col3','col4','col5','col6'] idx2 = ['row1','row2','row3'] data2 = [[1,2,3,4,5,6],[2,3,6,8,10,12],[3,6,9,12,15,18]] other = pd.DataFrame(data2, idx2, col2) print(other)
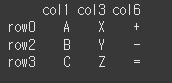
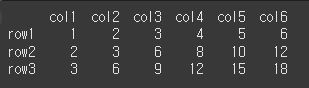
기본적인 사용법
other의 인덱스를 기준으로 self의 인덱스와 값을 적용해보겠습니다. 일치하지 않는경우 NaN을 반환합니다.print(self.reindex_like(other=other))
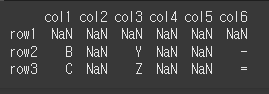
method와 limit의 사용
method를 이용하여 결측치를 채울 수 있습니다. method='ffill'이면 결측치를 앞의 값을 가져와서 채웁니다.print(self.reindex_like(other=other,method='ffill'))
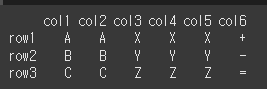
method='bfill'이면 결측치를 뒤의 값을 가져와서 채웁니다.
print(self.reindex_like(other=other,method='bfill'))
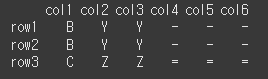
limit메서드를 이용할 경우 결측치를 채울 열의 수를 제한할 수 있습니다.
print(self.reindex_like(other=other,method='bfill',limit=1))
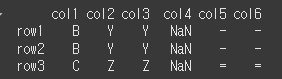
인덱스를 열로 변환 (reset_index)
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
개요
reset_index메서드는 설정 인덱스를 제거하고 기본 인덱스(0,1,2, ... , n)으로 변경하는 메서드 입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
self.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
level : Multi Index의 경우 제거할 인덱스의 레벨을 설정할수 있습니다. 기본적으로 모든 레벨입니다.
drop : 제거한 인덱스를 열에 추가할지 여부입니다. 기본값은 False로 제거된 인덱스는 열로 변환됩니다.
inplace : pandas 공통 인수로, 원본을 변경할지 여부 입니다.
col_level / col_fill : Multi Index의 경우 제거된 인덱스를 열에 추가할 때 레벨과 열의 이름을 설정할 수 있습니다.
col_level을 통해 레벨을 설정하고, col_fill을통해 해당 열의 이름을 정합니다.
예시
먼저 기본적인 사용법 예시를 위해 3x2 짜리 객체를 생성하겠습니다.
df = pd.DataFrame([[1,2],[3,4],[5,6]],['row1','row2','row3'],['col1','col2']) print(df)
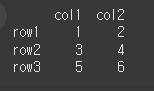
기본적인 사용법(+drop, inplace)
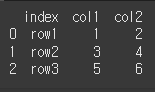
기본적으로 아무 인수 없이 사용하게 되면, 모든 레벨에 대해 인덱스가 제거되며, 열에 추가됩니다.print(df.reset_index())
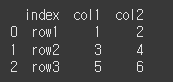
drop = True인 경우 열이 밖으로 꺼내지는게 아니라 완전히 삭제됩니다.
print(df.reset_index(drop=True))
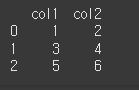
inplace=True인 경우 원본이 변경되게 됩니다.
df.reset_index(inplace=True) print(df)
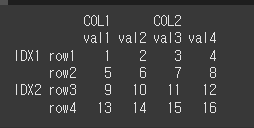
Multi Index 예시
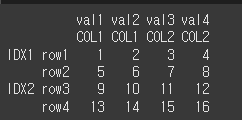
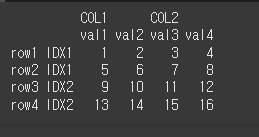
Multi Index의 예시를 위하여 4x4짜리 Multi Index를 하나 생성하겠습니다.idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']] col = [['COL1','COL1','COL2','COL2'],['val1','val2','val3','val4']] data = [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]] df2 = pd.DataFrame(data,idx,col) print(df2)
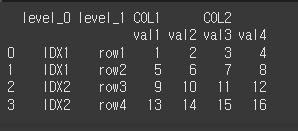
기본적인 사용법(+level)
Multi Index의 경우 level을 설정해줌으로서 제거할 인덱스의 레벨을 선택할 수 있습니다.
level을 입력하지 않은 경우 모든 index에 대해서 수행됩니다.print(df2.reset_index())
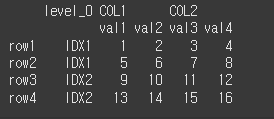
level=0인 경우
print(df2.reset_index(level=0))
level=1인 경우
print(df2.reset_index(level=1))
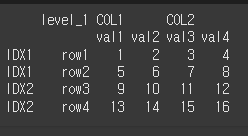
col_fill / col_level의 사용
col_fill을 이용하여 열로 변경되는 인덱스의 열 이름을 설정할 수 있습니다. COL0으로 설정해보겠습니다.print(df2.reset_index(level=1,col_fill='COL0'))
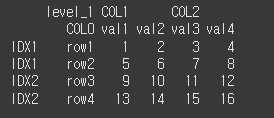
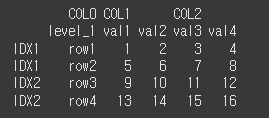
col_level을 이용해 열 이름의 레벨을 정할 수 있습니다. COL0을 다른 열이름에 맞게 LEVEL을 변경해보겠습니다.
print(df2.reset_index(level=1,col_fill='COL0',col_level=1))
멀티인덱스 레벨 변경 (reorder_levels)
DataFrame.reorder_levels(order, axis=0)
개요
reorder_levels메서드는 Multi Index에서 Index의 위치를 변경하는 메서드입니다.
사용법
기본 사용법
※ 자세한 내용은 아래 예시를 참고 바랍니다.
df.reorder_levels(order, axis=0)
order : 새로 정렬할 인덱스 순서입니다. 리스트 형태입니다.
axis : {0 : index / 1 : columns} 순서를 적용할 축 입니다.
예시
먼저 기본적인 사용법 예시를 위해 Multi Index 객체를 생성하겠습니다.
idx = [['IDX1','IDX1','IDX2','IDX2'],['row1','row2','row3','row4']] col = [['COL1','COL1','COL2','COL2'],['val1','val2','val3','val4']] data = [[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]] df = pd.DataFrame(data,idx,col) print(df)
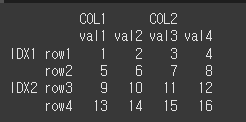
기본적인 사용법
order에 리스트 형태의 level 순서를 입력하므로써 인덱스 순서의 변경이 가능합니다.print(df.reorder_levels([1,0])) #인덱스 순서를 레벨1 - 레벨0으로 변경
axis를 설정하여 적용될 축을 지정할 수 있습니다.
print(df.reorder_levels([1,0],axis=1))