시작하기 전에 import 하기
import plotly.express as px import plotly.graph_objects as go import plotly.express as px import numpy as np
Plotly의 Basic Chart 사용법에 대해 알아봅니다.
Scatter Plots, Line Charts, Bar Charts, Pie Charts, Gantt Charts, Table
Scatter Plot
Express를 활용한 기본 사용방법
# 직접 입력 px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) # 데이터셋을 활용한 입력 px.scatter(data_frame= df, x="sepal_width", y="sepal_length")[사용 함수]
px.scatter()
[함수 input 내용]
데이터 직접 입력
x = x값 리스트
y = y값 리스트
데이터셋을 활용한 입력
data_frame = pandas 데이터 프레임
x = x값 컬럼 명
y = y값 컬럼 명
예제 1
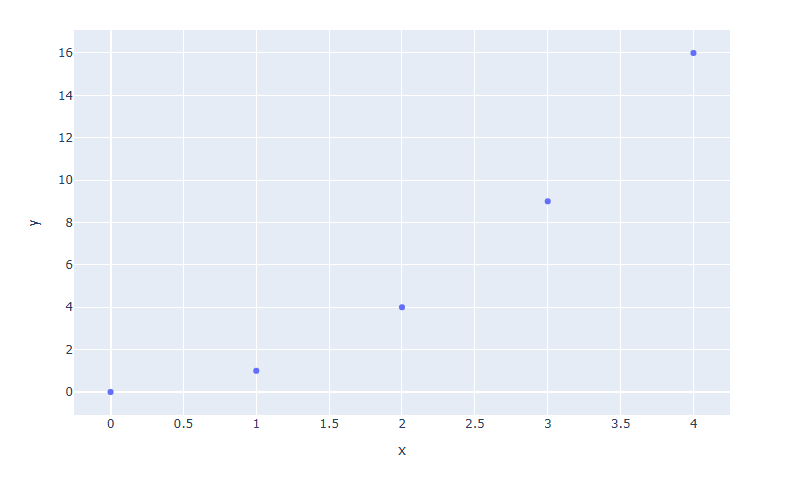
fig = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) fig.show()
예제 2
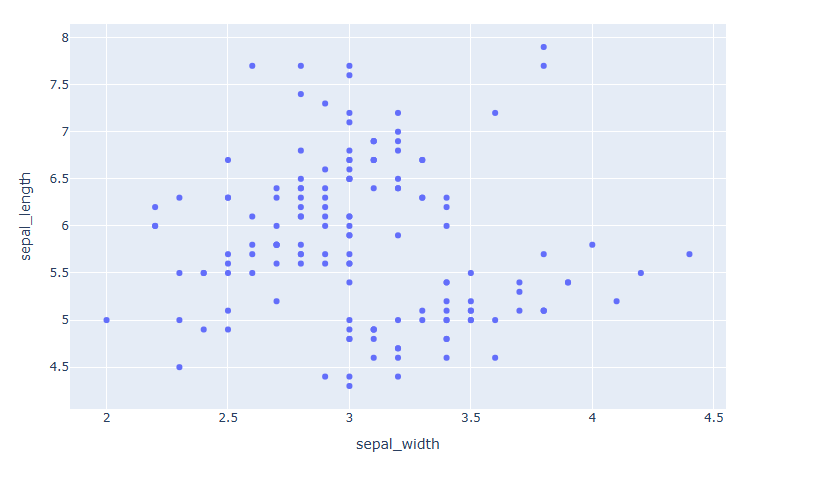
# 데이터 불러오기 df = px.data.iris() fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length") fig.show()
graph_objects를 활용한 기본 사용
fig.add_trace(go.Scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16],mode='markers'))[사용 함수]
fig.add_trace() : Trace를 추가할때 사용
go.Scatter() : fig.add_trace() 안에 넣은 Scatter Trace
[함수 input 내용]
x = x값 리스트
y = y값 리스트
mode = {'markers', 'lines', 'lines+markers'}
markers : 점으로 표시
line : 선으로 표시
lines+markers : 점 선 모두로 표시
예제
import numpy as np np.random.seed(1) N = 100 random_x = np.linspace(0, 1, N) random_y0 = np.random.randn(N) + 5 random_y1 = np.random.randn(N) random_y2 = np.random.randn(N) - 5
Figure 생성
fig = go.Figure()
Scatter Trace 추가
fig.add_trace(go.Scatter(x=random_x, y=random_y0,
mode='markers',
name='markers'))
fig.add_trace(go.Scatter(x=random_x, y=random_y1,
mode='lines+markers',
name='lines+markers'))
fig.add_trace(go.Scatter(x=random_x, y=random_y2,
mode='lines',
name='lines'))
fig.show()
express 를 활용한 다양한 기능
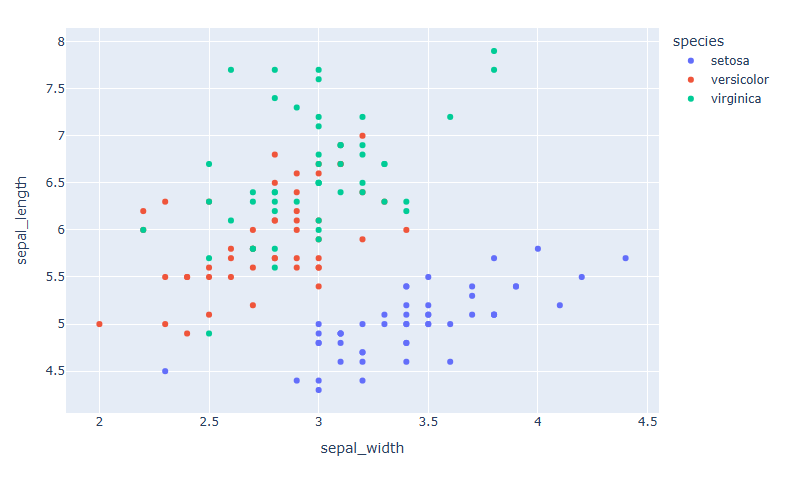
마커 색으로 데이터 분류하기
df = px.data.iris() fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length", color="species") fig.show()
색으로 구분하고 싶은 데이터 컬럼명을 "color= " 로 지정합니다.
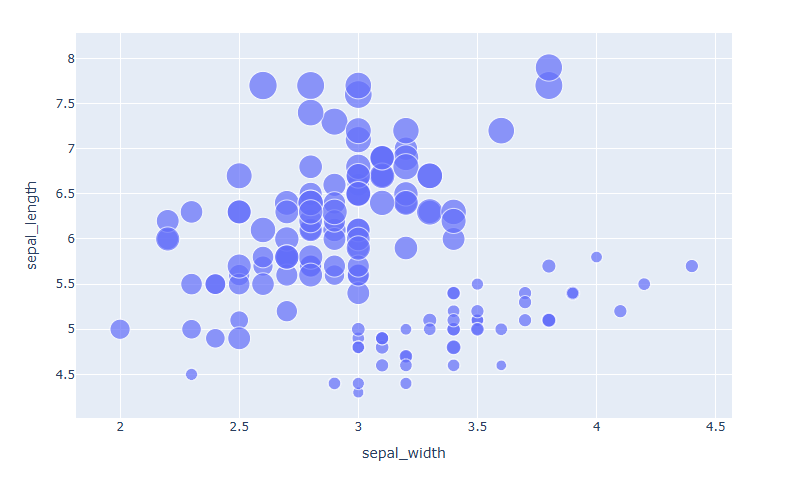
마커 크기 다르게 표시하기
df = px.data.iris() fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length", size='petal_length') fig.show()
점 크기를 반영하고 싶은 데이터 컬럼명을 "size= " 로 지정합니다.
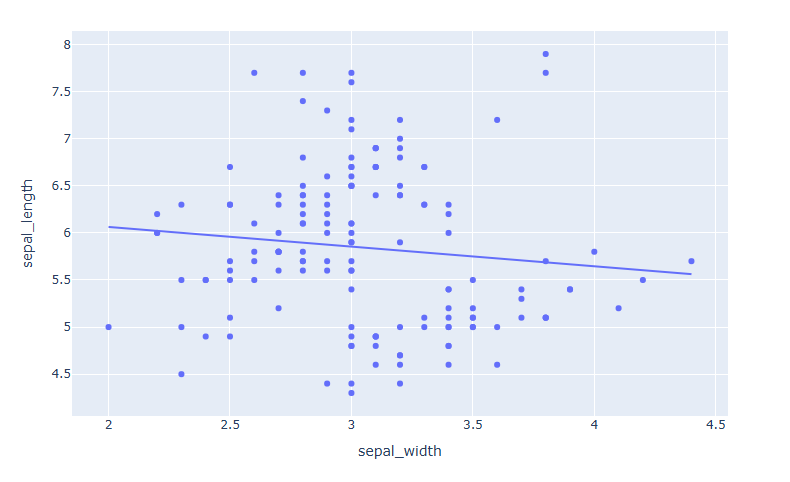
추세선 추가하기
df = px.data.iris() fig = px.scatter(data_frame=df, x="sepal_width", y="sepal_length", trendline="ols") fig.show()
해당 기능을 활용하기 위해선 statsmodels 패키지를 추가 설치해야 합니다.
추세선을 "trendline= " 을 활용해서 추가 가능합니다. trendline의 추가 옵션에 대한 설명은 링크 를 통해 확인 가능합니다.
여러개로 나눠 그리기 (Facet)
df = px.data.tips() fig = px.scatter(data_frame=df, x="total_bill", y="tip", facet_col="sex") fig.show()Plotly express 함수의 Facet 기능을 활용하여 범주형 데이터에 따라 자동으로 그래프 나눠그리기가 가능합니다. [링크 추가]
"facet_col= " 또는 "facet_row= " 에 나눠 그리고자 하는 범주형 데이터의 컬럼명을 입력하면 자동을 분류하여 그래프가 생성합니다.
아래 예제는 facet_col = "sex" 를 입력하여 성별에 따라 두개의 컬럼으로 나눠 시각화 되었습니다.
마커 스타일 변경하기
fig.update_traces(marker_color= 마커 색, marker_size=마커 크기, marker_line_width=마커 테두리 두깨, marker_line_color=마커 테두리 색, marker_angle = 마커 각도, marker_symbol = 마커 모양, marker_opacity = 마커 투명도, )[사용 함수]
fig.update_traces()
marker_color= 마커 색
marker_size=마커 크기
marker_line_width=마커 테두리 두깨
marker_line_color=마커 테두리 색
marker_angle = 마커 각도
marker_symbol = 마커 모양
marker_opacity = 마커 투명도
예제
df = px.data.iris() # Scatter Plot 생성 fig = px.scatter(df, x="sepal_width", y="sepal_length",color="species") #마커 스타일 변경 fig.update_traces(marker_size=12, marker_symbol="arrow", marker_angle=45, marker_line_width=2, marker_line_color="DarkSlateGrey") fig.show()
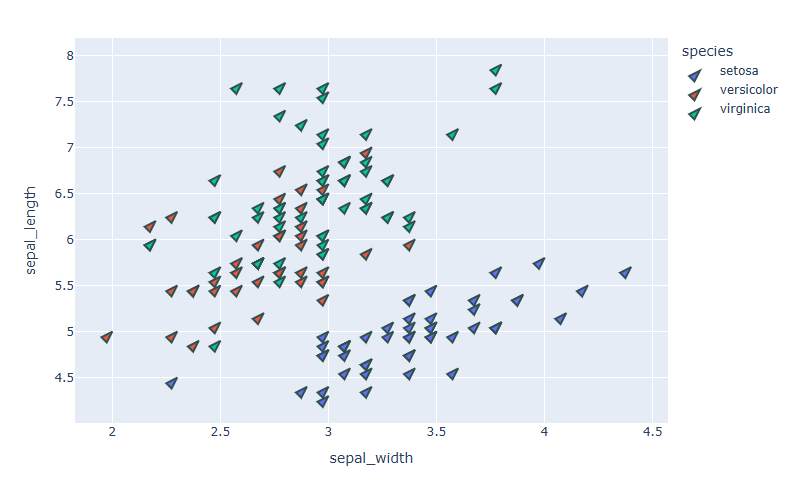
마커 symbol 종류 확인하기
Plotly 에서 지원하는 다양한 마커 symbol 의 종류를 확인해봅니다.
import plotly.graph_objects as go from plotly.validators.scatter.marker import SymbolValidator raw_symbols = SymbolValidator().values namestems = [] namevariants = [] symbols = [] for i in range(0,len(raw_symbols),3): name = raw_symbols[i+2] symbols.append(raw_symbols[i]) namestems.append(name.replace("-open", "").replace("-dot", "")) namevariants.append(name[len(namestems[-1]):]) fig = go.Figure(go.Scatter(mode="markers", x=namevariants, y=namestems, marker_symbol=symbols, marker_line_color="midnightblue", marker_color="lightskyblue", marker_line_width=2, marker_size=15, hovertemplate="name: %{y}%{x}<br>number: %{marker.symbol}<extra></extra>")) fig.update_layout(title="Mouse over symbols for name & number!", xaxis_range=[-1,4], yaxis_range=[len(set(namestems)),-1], margin=dict(b=0,r=0), xaxis_side="top", height=1400, width=400) fig.show()
Line Plot
Plotly를 활용하여 Line Plot 을 그리는 방법에 대해 알아보도록 하겠습니다.
Express를 활용한 기본 사용방법
# 직접 입력 px.line(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) # 데이터셋을 활용한 입력 px.line(data_frame= df, x="year", y="lifeExp")[사용 함수]
px.line()
[함수 input 내용]
데이터 직접 입력
x = x값 리스트
y = y값 리스트
데이터셋을 활용한 입력
data_frame = pandas 데이터 프레임
x = x값 컬럼 명
y = y값 컬럼 명
예제 1
import plotly.express as px fig = px.line(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) fig.show()
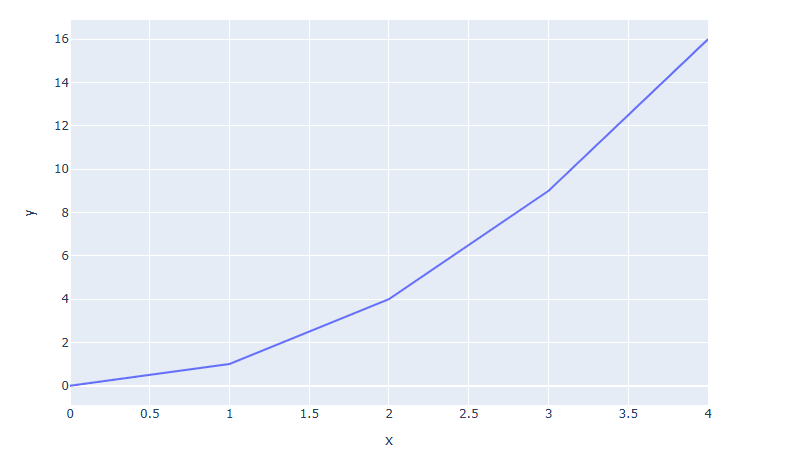
예제 2) 데이터셋을 활용한 입력
df = pd.read_csv("서울기온.csv") # 날짜 열을 datetime 형식으로 변환 df["날짜"] = pd.to_datetime(df["날짜"]) # 원하는 날짜 범위만 필터링 df_selected = df[(df["날짜"] >= "2025-05-12") & (df["날짜"] <= "2025-06-10")] # 시각화: x축을 날짜로 해서 보기 쉽게 fig = px.line(df_selected, x="날짜", y="평균기온(℃)", title="2025-05-12 ~ 2025-06-10 평균기온 추이") fig.show()
graph_objects를 활용한 기본 사용
fig.add_trace(go.Scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16], mode='lines'))[사용 함수]
fig.add_trace() : Trace를 추가할때 사용
go.Scatter() : fig.add_trace() 안에 넣은 Scatter Trace
[함수 input 내용]
mode = {'markers', 'lines', 'lines+markers'}
markers : 점으로 표시
line : 선으로 표시
lines+markers : 점 선 모두로 표시
예제
import numpy as np x = np.arange(10) # Figure 생성 fig = go.Figure() # Line Trace 추가 fig.add_trace(go.Scatter(x=x, y=x**2, mode='lines')) fig.show()
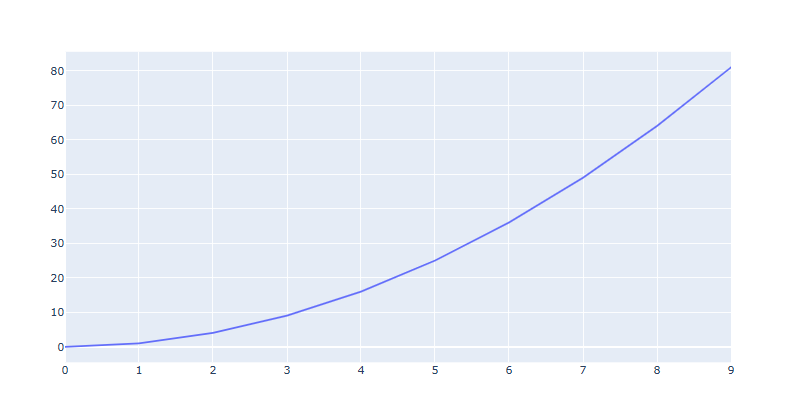
express 를 활용한 다양한 기능
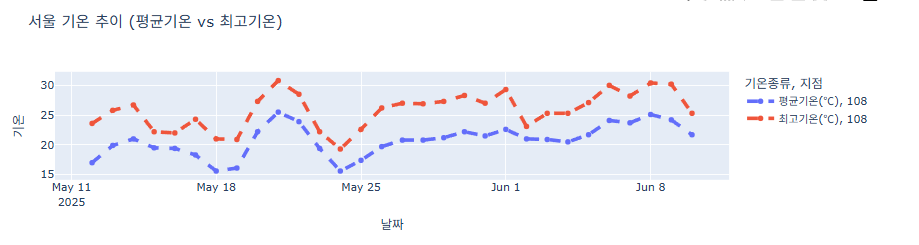
라인 색 다르게 표시하기
df = pd.read_csv('서울기온.csv') df['날짜'] = pd.to_datetime(df['날짜']) # 평균기온, 최고기온을 긴(long) 형태로 변환 (melt) df_long = df.melt(id_vars=['날짜', '지점'], value_vars=['평균기온(℃)', '최고기온(℃)'], var_name='기온종류', value_name='기온') fig = px.line(df_long, x='날짜', y='기온', color='기온종류', line_dash='지점', title='서울 기온 추이 (평균기온 vs 최고기온)') fig.update_layout(width=1000, height=300) fig.show()
색으로 구분하고 싶은 데이터 컬럼명을 "color= " 로 지정합니다.
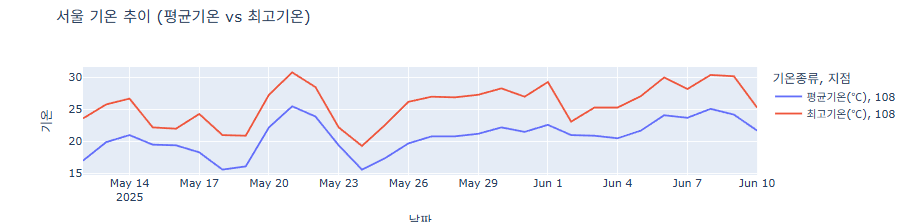
마커 같이 표시하기
df = pd.read_csv('서울기온.csv') # 날짜 컬럼을 datetime 형식으로 변환 df['날짜'] = pd.to_datetime(df['날짜']) # 평균기온, 최고기온을 긴(long) 형태로 변환 (melt) df_long = df.melt(id_vars=['날짜', '지점'], value_vars=['평균기온(℃)', '최고기온(℃)'], var_name='기온종류', value_name='기온') # 선 그래프 그리기 (마커 포함) fig = px.line( df_long, x='날짜', y='기온', color='기온종류', line_dash='지점', title='서울 기온 추이 (평균기온과 최고기온)', markers=True ) # 그래프 크기 조절 (가로 길고 세로 짧게) fig.update_layout(width=1000, height=300) fig.show()
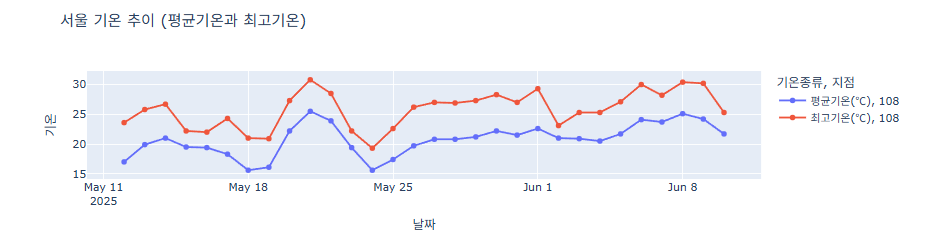
마커 스타일 다르게 표시하기
df = pd.read_csv('서울기온.csv') df['날짜'] = pd.to_datetime(df['날짜']) df_long = df.melt(id_vars=['날짜', '지점'], value_vars=['평균기온(℃)', '최고기온(℃)'], var_name='기온종류', value_name='기온') fig = px.line( df_long, x='날짜', y='기온', color='기온종류', line_dash='지점', symbol='지점', # 여기서 마커 스타일 다르게 지정 title='서울 기온 추이 (평균기온 vs 최고기온)', markers=True ) fig.update_layout(width=1000, height=300) fig.show()
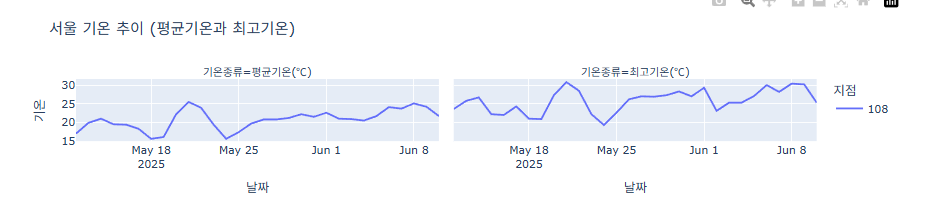
여러개로 나눠 그리기 (Facet)
import pandas as pd import plotly.express as px df = pd.read_csv('서울기온.csv') df['날짜'] = pd.to_datetime(df['날짜']) df_long = df.melt( id_vars=['날짜', '지점'], value_vars=['평균기온(℃)', '최고기온(℃)'], var_name='기온종류', value_name='기온' ) fig = px.line( df_long, x='날짜', y='기온', color='지점', line_dash='지점', facet_col='기온종류', title='서울 기온 추이 (평균기온과 최고기온)' # symbol 제거됨 → 마커 사라짐 ) fig.update_layout(width=1000, height=350) fig.show()
Plotly express 함수의 Facet 기능을 활용하여 범주형 데이터에 따라 자동으로 그래프 나눠그리기가 가능합니다. [링크 추가]
"facet_col= " 또는 "facet_row= " 에 나눠 그리고자 하는 범주형 데이터의 컬럼명을 입력하면 자동을 분류하여 그래프가 생성합니다.
아래 예제는 facet_col = "country" 를 입력하여 나라에 따라 두개의 컬럼으로 나눠 시각화 되었습니다.
라인 스타일 변경하기
fig.update_traces(line_color= 라인 색, line_width= 라인 두깨, line_dash= 라인 스타일, )[사용 함수]
fig.update_traces()
[함수 input 내용]
line_color = 라인 색
line_width = 라인 두깨
line_dash = {"dash", "dot", "dashdot"} 라인 스타일
예제
import pandas as pd import plotly.express as px df = pd.read_csv('서울기온.csv') df['날짜'] = pd.to_datetime(df['날짜']) # '최저기온(℃)' 컬럼도 포함시키기 df_long = df.melt( id_vars=['날짜', '지점'], value_vars=['평균기온(℃)', '최고기온(℃)', '최저기온(℃)'], # 최저기온 추가 var_name='기온종류', value_name='기온' ) fig = px.line( df_long, x='날짜', y='기온', color='기온종류', # 기온종류로 색 구분 line_dash='지점', # 지점별로 선 스타일 구분 symbol='지점', # 마커 스타일도 지점별 다르게 title='서울 기온 추이 (평균기온, 최고기온, 최저기온)', markers=True ) fig.update_traces(line_width=4, line_dash='dash') fig.update_layout(width=1000, height=500) fig.show()
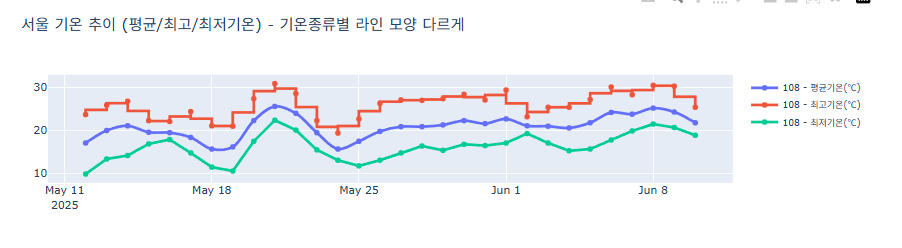
라인 Interpolation 방법 설정하기
점과 점 사이를 Interploation 하는 다양한 방법에 대해 소개합니다.
go.Scatter(line_shape = 인터폴레이션 방법 설정)[사용 함수]
go.Scatter()
[함수 input 내용]
line_shape
linear : 점과 점 사이를 직선으로 연결합니다.
spline : 점과 점 사이를 곡선으로 연결합니다.
vhv : 점과 점 사이를 두 점의 평균선으로 연결합니다.
hvh : 가장 가까운 점의 값으로 선을 연결합니다.
vh : 다음 점의 위치로 선을 연결합니다.
hv : 이전 선의 위치로 선을 연결합니다
예제
import pandas as pd import plotly.graph_objects as go # 데이터 불러오기 및 전처리 df = pd.read_csv('서울기온.csv') df['날짜'] = pd.to_datetime(df['날짜']) # 긴 포맷으로 변환 df_long = df.melt( id_vars=['날짜', '지점'], value_vars=['평균기온(℃)', '최고기온(℃)', '최저기온(℃)'], var_name='기온종류', value_name='기온' ) # 기온종류별로 다른 line_shape 설정 line_shapes = { '평균기온(℃)': 'spline', '최고기온(℃)': 'vhv', '최저기온(℃)': 'linear' } fig = go.Figure() # Trace 추가 (지점별, 기온종류별) for station in df['지점'].unique(): station_data = df_long[df_long['지점'] == station] for temp_type in line_shapes: subset = station_data[station_data['기온종류'] == temp_type] fig.add_trace(go.Scatter( x=subset['날짜'], y=subset['기온'], mode='lines+markers', name=f"{station} - {temp_type}", line=dict( width=3, shape=line_shapes[temp_type] ), marker=dict(size=6) )) # 레이아웃 설정 fig.update_layout( title='서울 기온 추이 (평균/최고/최저기온) - 기온종류별 라인 모양 다르게', width=1000, height=500, legend=dict(font_size=10) ) fig.update_layout(width=1000, height=300) fig.show()
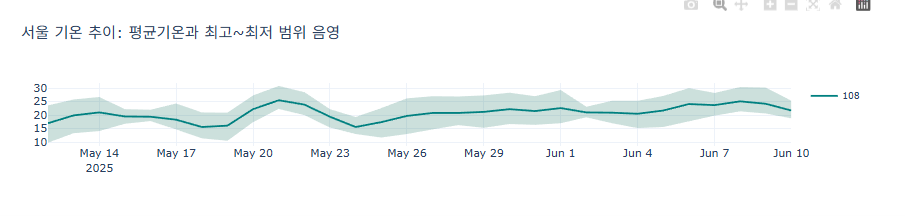
선과 선 사이 채우기
선과 선 사이를 채우면 순대 모양의 마치 오차범위를 내는 듯한 효과를 낼 수 있습니다.
go.Scatter(x = 범위 둘례 X 좌표, y = 범위 둘례 Y 좌표, fill = 'toself' fillcolor = 범위 색 line_color = 테두리 색)[사용 함수]
go.Scatter()
[함수 input 내용]
line_shape
x = 범위 둘례 X 좌표
y = 범위 둘례 Y 좌표.
fill = 'toself'
fillcolor = 범위 색
line_color = 테두리 색
예제
import pandas as pd import plotly.graph_objects as go # CSV 데이터 불러오기 df = pd.read_csv('서울기온.csv') df['날짜'] = pd.to_datetime(df['날짜']) fig = go.Figure() # 지점별로 처리 for station in df['지점'].unique(): station_df = df[df['지점'] == station] x = station_df['날짜'].tolist() x_rev = x[::-1] # 상하 경계 upper = station_df['최고기온(℃)'].tolist() lower = station_df['최저기온(℃)'].tolist()[::-1] # 음영 영역 추가 (최고 ~ 최저) fig.add_trace(go.Scatter( x=x + x_rev, y=upper + lower, fill='toself', fillcolor='rgba(0,100,80,0.2)', line_color='rgba(255,255,255,0)', showlegend=False, hoverinfo='skip' )) # 평균기온 선 추가 fig.add_trace(go.Scatter( x=x, y=station_df['평균기온(℃)'], mode='lines', name=f'{station}', line=dict(color='teal', width=2) )) # 레이아웃 설정 fig.update_layout( title='서울 기온 추이: 평균기온과 최고~최저 범위 음영', width=900, height=400, template='plotly_white', legend=dict(font_size=10) ) fig.update_layout(width=1000, height=250) fig.show()