
이 포스팅에서 코드는 다루지 않았다.
여러 방법을 적용한 코드는 깃허브 커밋 기록으로 남겨두었다.
https://github.com/hyeona01/Data-Structures/blob/master/malloc-lab/mm.c
CS:APP의 malloc lab을 하면서 대부분의 시간은 segmentation fault를 마주하면서 보냈다.
눈물이 날 만큼 괴로웠지만, 결국에는 어느 주차보다 즐겁고 충만한 한 주였다. 교과서적으로 암기했던 파편들이 연결될 때의 짜릿함은 이루 말할 수 없다.
흥미가 파바박 생겨난 세 가지 시점이 있다. 점진적으로 증가할 수는 없었고, 특정 스팟에서 수직으로 증가했다.
그 스팟을 기록하려 한다.
코드를 통해 메모리 관리를 이해하게 되었을 때
malloc lab을 처음 마주했을 때, 우선 가상 메모리를 더 파고들었다. 동작하는 방식을 머릿속에 넣으려고 노력하면서 한 줄, 한 줄을 읽어나갔다. 이해 되지 않는 것들은 GPT 선생님, 동료들에게 물어가며 해소했다.
그런 다음에 malloc lab의 기본적인 코드를 봤다.
CS:APP에 기재된 코드만 따라쳤는데도 300줄이었다..
이 코드의 큰 흐름을 이해하고,
세부적인 매크로의 구조, 각 함수들의 동작을 세세히 이해하는 데 집중했다.
특히, 아래 주제를 기준으로 더 공부했다.

그러던 중에,
🤨'malloc 요청으로 적합한 메모리를 반환해주는 것까지 했다면 그 이후에는 어떻게 사용하는 거지?'
🤨🤨'배웠던 내용으로는 뭐 페이지 교체니 페이지 폴트니 이런 게 있었는데? 어떻게 연결되지?'
이런 의문이 생겼고 다시 CSAPP 교재로 돌아갔다.
이 개념 먼저 잡고 다시 시작했더니, 훨씬 가상 메모리에 대한 이해도가 높아진 느낌을 받았다.
Heap 영역의 '의사결정 트리'
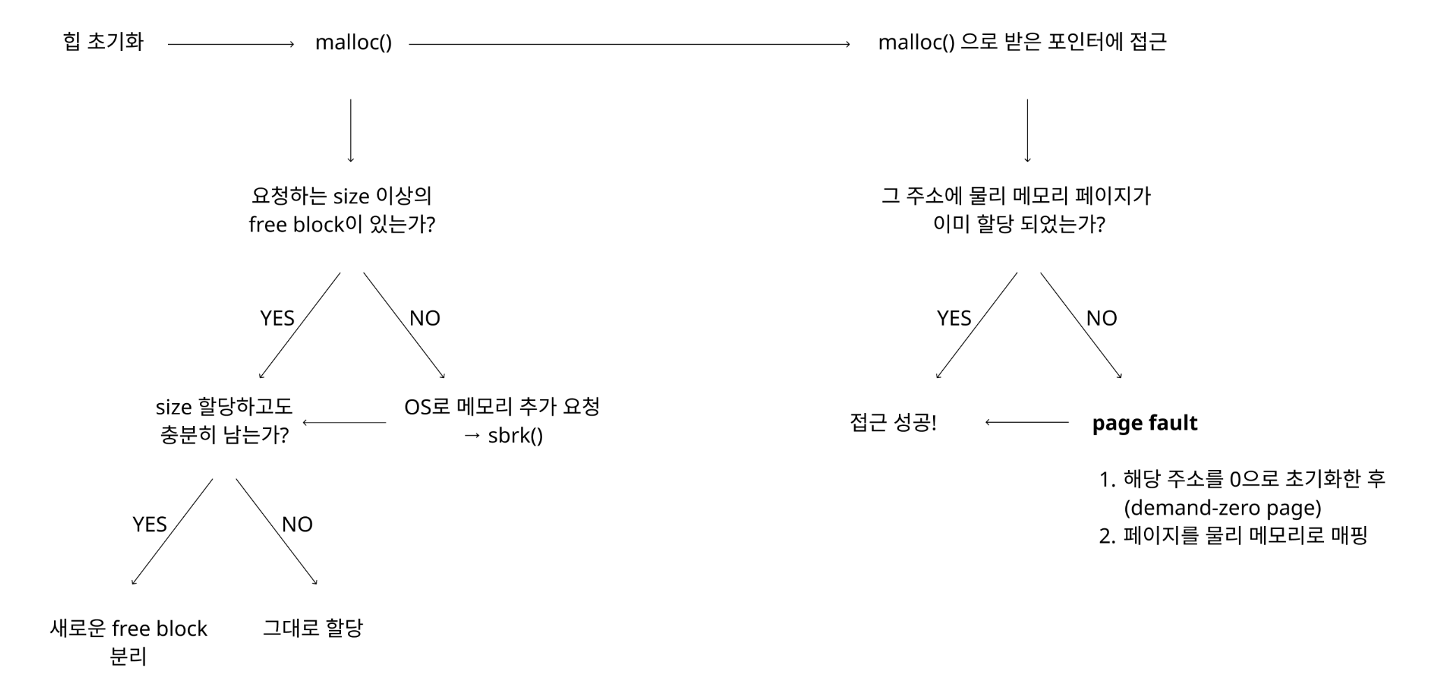
- 힙 영역을 초기화하면서 시작
- malloc() 으로는 힙 영역이 요청한 사이즈에 비해 넉넉한지 아닌지를 판단하여 메모리를 필요에 따라 확장하며 할당한다.
- malloc()으로 받은 포인터에 접근하는 시점에 또다시 분기가 생긴다. 이미 물리 메모리 페이지에 할당이 되었는지에 따라 페이지 폴트가 발생하며 초기화를 시켜 접근할 수 있도록 제공한다.
이렇게 동작을 정리하면 내가 만들고 있는 malloc()의 목적을 잃지 않게 된다. 결국 사용자가 더 잘, 더 빠르게, 더 많은 메모리를 사용할 수 있게 하는 게 malloc, 할당기의 목적이다.
개발 환경의 중요성을 살갗으로 확인하면서
이전 포스팅에서도 살짝 언급했지만, 교재는 32비트 시스템 체제를 기반으로 한다. 하지만 내 환경은 macOS 64비트 시스템 체제이다.
가장 큰 문제점은 포인터 크기가 다르다는 점이다.
교재에서는 포인터 크기를 4바이트로 세팅한다.(진짜 숫자 4 이렇게 말이다.)
4바이트 포인터로 인코딩한 코드를 사용하면 뭐하나, 그를 실행하고 실제로 주소를 갖고 노는 os는 64비트 체제인데!
사실 이 내용은 C언어를 시작할 때부터 코치님들이 줄기차게 중요성을 강조한 내용이다. 내가 다 이해했다고 생각했는데, 이 문제에 맞닥뜨렸을 때, 과장해서 30시간은 고생했다. 🥲
고마운 동료로 인해 내 컴퓨터에서는 자꾸만 이상한 상황이 일어났던 코드가 동료의 컴퓨터에서는 잘 동작한다는 점을 발견했고,
이게 '체제에 따라 다르게 동작할 수 있구나' 직접 느껴볼 수 있었던 값진 경험이었다.
64비트 시스템에서 포인터 크기를 4바이트로 주었을 때 나타나는 수많은 에러 중 하나를 겪었고 이를 기록한다.
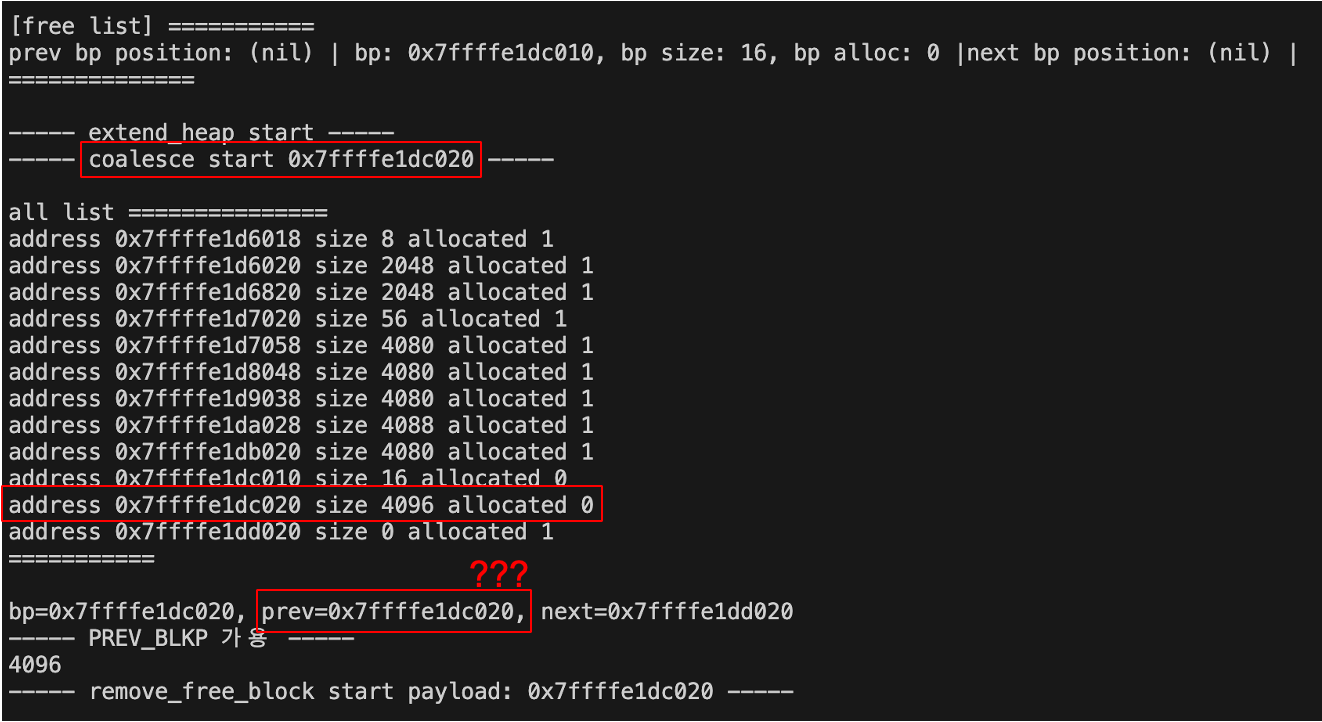
디버깅한 코드를 보면, 힙 확장 이후 병합 단계에서 이상한 점이 발견된다.
all list에서 직전 블록과 현재 블록이 allocated 0으로 병합해야 하는 상황이다.
그런데 자꾸 size 16인 이전 블록과 병합되지 않고, 자기 자신(0x7ffffe1dc020)으로 덮어써졌다.
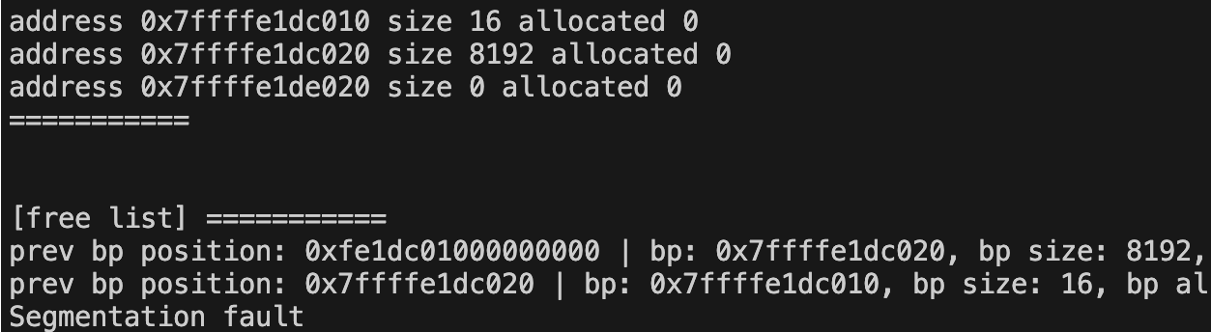
보이는가?
병합되어, 사이즈가 증가했어야 하는 블록 0x7ffffe1dc010의 사이즈가 그대로 16이며,
병합으로 삭제되어야 했을 블록 0x7ffffe1dc020 블록에 사이즈(4096)가 추가되어 남아있다.
그런데 프로그램은 정상적으로 병합된 줄 알고, 그 주소에 접근한다. 바로 쓰레기값을 참조하게 되면서 segmentation fault가 발생한다.
하나씩 이유를 찾아봤더니,
병합 시점에서 이전 블록의 주소를 잘못 참조하고 있다는 사실을 발견했다. 사이즈가 잘못된 것도 아니었다. 이상하다..
사실 이 부분이 잘못되었다는 것을 발견하기까지도 험난한 디버깅을 거친 이후였고, 머리가 멍 해졌다....
팀원에게 SOS를 청했더니,
나의 문제가 그 컴퓨터에서는 발생하지 않더라. 이게 머지.. 🤯
너무 시달렸어서 해방감이 컸고, 내 코드가 틀리지 않았고, 내 논리가 틀리지 않았음에 안도하며 이만 손을 놓고 싶었다..ㅋㅋㅋㅋㅋ
그 원인을 고민하고, 단지 이 포인터 크기였다는 것을 알게 되었다.

이렇게 바꿔주면
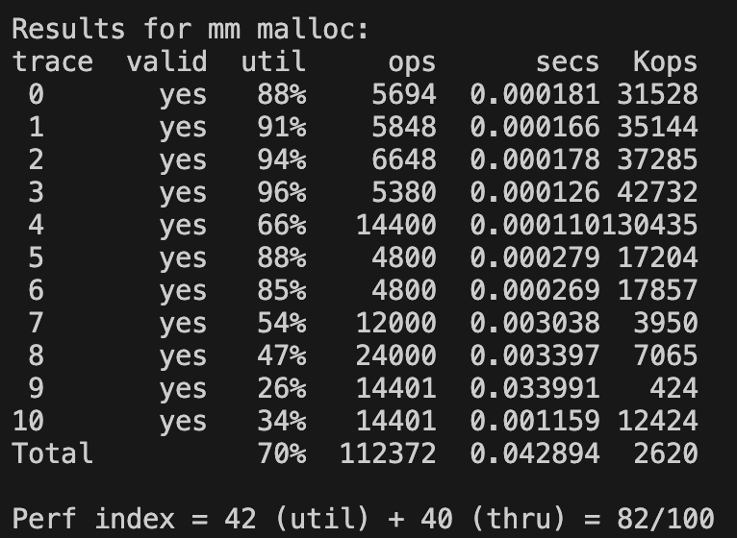
짜잔~ 이렇게 나온다.(explicit + LIFO + first fit 방식)
어처구니 없는 테스트 케이스에 대해 팀원들과 고찰하면서
explicit까지 구현한 상황에서, 한 발 더 갈지, 멈춰서 정리를 할지 고민했다. 듣자하니, explicit에서 다음 스텝으로 예정했던 segregated list 방법에서 유의미한 점수 차이를 기대하기 어렵다고 해서 고민했다.
(사실 80점대 점수를 받고 내심 만족하기도 했다.)
하지만 팀 코어시간에 팀원들과 의견을 나누었던 과정에서 또다시 동기부여가 되었다.
한 팀원은 내 코드가 특정 trace에서 점수가 낮은 이유를 분석했다.
그 테스트 케이스가 어떤 것을 요구하는 지를 파악하고 있었다.
이 모습을 보면서도,
'아니 왜 범용적으로 좋은 코드를 버리고 굳이 이 테스트 케이스만을 위한 코드를 고민해야 하나? 시간 낭비 아닌가?'
라고 생각했다.
하지만 더 많이 대화하면서 내가 틀렸다는 것을 깨달았다.
우리가 해결하고자 하는 것은 범용적인 것이 아니다.
이미 척척박사님들이 범용적으로 유용한 알고리즘, 방법론을 연구했고 실제로 쓰여지고 있다.
우리는 이를 잘 익히고,
우리가 해결할 문제에 어떻게 잘 적용하여 문제를 해결할 수 있을 지 고민해야 한다.
이 점을 알아차리고 아차 싶었다!
'이정도만 하면 되겠지' 하는 생각을 조금은 고쳐먹을 수 있었다.
내가 소프트웨어, 더 나아가 컴퓨터 구조까지 공부하는 이유가 여기에 있지 않나. 누군가가 제시한 해결책이 아니라, 새로 발생한 문제를 어떻게 기존의 것들을 잘 조합해서 해결할 수 있는가?
여튼,
이런 점에서 동기부여가 되어
segregated list, address ordered, best fit, next fit까지 다 구현(따라친 것도 있다)하면서 견문을 넓힐 수 있었던 주간이 아니었다 싶다.
좋은 깨달음이다!
