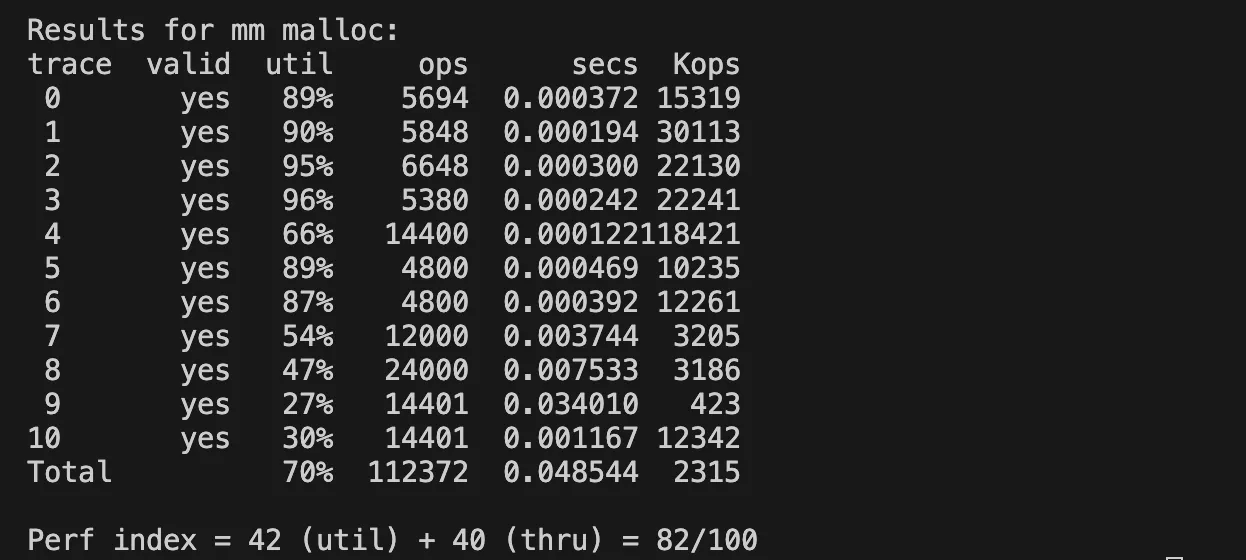
explicit free list + next fit
구상
마지막으로 할당된 주소를 기억(last_alloc)하고 다음 할당은 그 주소 이후부터 탐색
- 기존 fb을 할당하는 시점에 last_alloc을 업데이트 한다. → place 함수
- 초기화 진행시, last_alloc을 free_listp로 설정한다.
고칠 함수
-
mm_init
초기화시, last_alloc(next fit 기준의 포인터)를 업데이트한다.
int mm_init(void) { if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) { return -1; } PUT(heap_listp, 0); // 정렬 패딩 PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더 PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터 PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 헤더 heap_listp += (2 * WSIZE); // payload 위치 free_listp = NULL; // 초기화 if (extend_heap(CHUNKSIZE / WSIZE) == NULL) { return -1; } last_alloc = free_listp; // 힙 확장 성공시, next fit 포인터 변경 return 0; } -
find_fit
기존 first fit은 free list의 root 부터 탐색했지만, last_alloc(직전 할당된 fb의 다음 블록 포인터)부터 탐색한다.
list 중간에 위치할 수 있기 때문에 원형으로 탐색한다.
void *find_fit(size_t asize) { if (free_listp == NULL) return NULL; // 만약, last_alloc이 없다면 free_listp 부터 first fit 탐색한다. void *start = last_alloc ? last_alloc : free_listp; void *bp = start; do { if (asize <= GET_SIZE(HDRP(bp))) { return bp; } bp = SUCC(bp); if (bp == NULL) // 끝에 도달하면 root로 다시 설정 bp = free_listp; } while (bp != start); // 시작 노드와 같아지면 종료 return NULL; } -
place
malloc 요청에 의해 fb을 할당하고 분할 되었다면 분할된 블록으로, 분할되지 않았다면 다음 free block으로 last_alloc을 설정한다.
void place(void *bp, size_t asize) { size_t csize = GET_SIZE(HDRP(bp)); // csize: free block 크기 remove_free_block(bp); if ((csize - asize) >= (2 * DSIZE)) // 남는 블록이 free block 최소 크기(24B->정렬 32B)보다 크다면 { PUT(HDRP(bp), PACK(asize, 1)); PUT(FTRP(bp), PACK(asize, 1)); // 나머지는 free block으로 분할 bp = NEXT_BLKP(bp); // 나중에 free block 합침(지연 연결) // 블록 정보 업데이트 PUT(HDRP(bp), PACK(csize - asize, 0)); PUT(FTRP(bp), PACK(csize - asize, 0)); // free list 업데이트 insert_free_block(bp); last_alloc = bp; // 분할된 블록을 next fit 포인터 지정 } else { // 분할 불가 - 잔여 block이 넉넉치 않고 fit함 PUT(HDRP(bp), PACK(csize, 1)); PUT(FTRP(bp), PACK(csize, 1)); last_alloc = (SUCC(bp) != NULL) ? SUCC(bp) : free_listp; // 할당된 블록의 다음 블록으로 next fit 포인터 지정 } }
문제사항
무한 루프 🫨
remove 할 때 삭제하는 노드가 last_alloc일 경우 여전히 같은 주소를 가지고 있게 된다.(전후 관계만 변경해주는 함수이기 때문)
따라서, last_alloc을 삭제하는 경우에도 별도의 로직으로 분기해야 한다.
- remove_free_block
void remove_free_block(void *bp) { if (bp == last_alloc) { last_alloc = SUCC(bp); } if (bp == free_listp) // 이 경우가 더 이해가 쉬움 { free_listp = SUCC(bp); if (free_listp != NULL) { PRED(free_listp) = NULL; } } else { if (PRED(bp)) { SUCC(PRED(bp)) = SUCC(bp); } if (SUCC(bp)) { PRED(SUCC(bp)) = PRED(bp); } }
그렇게 딱 4개의 함수만 수정해주면 next fit 정책으로 구현할 수 있다.
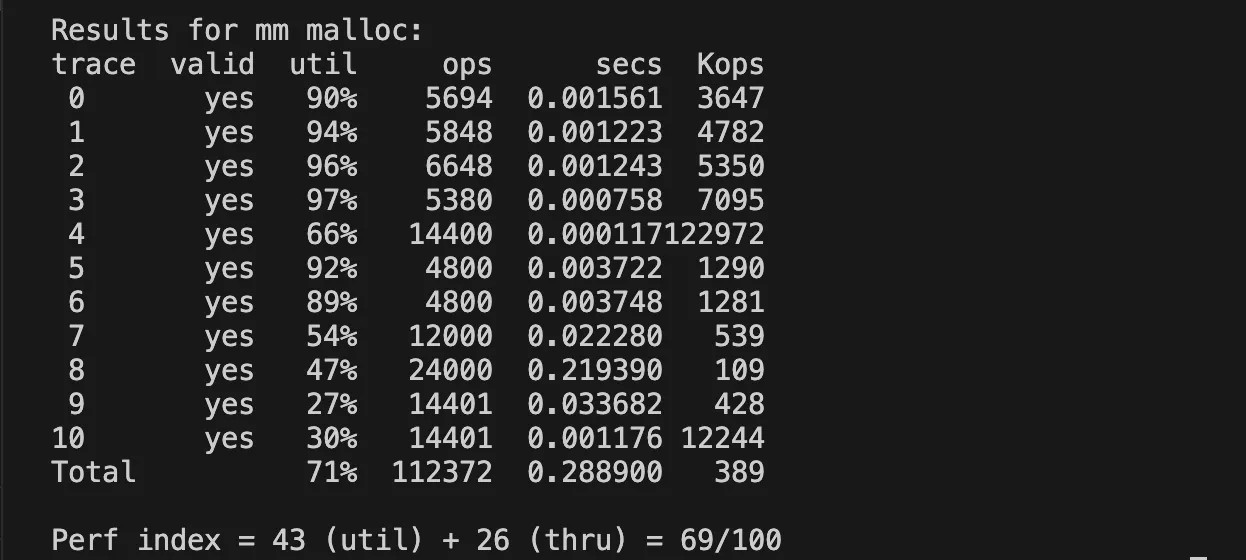
explicit + FIFO + next fit
이건 단지 궁금증에서 구현해본 것이다.
LIFO 방식으로 구현했을 때는 오래된 free block은 나중에 할당하게 된다. 그런데 큰 메모리 할당이 반복적으로 요청된다면 FIFO가 효율적이지 않을까?!
반면, LIFO 방식으로 하는 이유는 기장 최근에 free 된 블록의 크기를 다시 사용할 가능성이 높다는 이유다.
그렇게 된다면 캐시 히트율도 좋아진다!
역시나 FIFO 방식으로 했을 때는 시간도 오래 걸리는 데 반해 메모리 이용률도 주어진 케이스 내에서는 비슷하다. 오래된 free block은 낡고 크기 때문에 주어진 케이스 내에서는 재사용 가능성이 떨어진다.
// free block 노드 삽입(FIFO)
void insert_free_block(void *bp)
{
// printf("----- insert_free_block start ----- \n");
// print_free_list();
PRED(bp) = NULL;
SUCC(bp) = NULL;
if (free_listp == NULL)
{
free_listp = bp;
return;
}
void *tail = free_listp;
while (SUCC(tail) != NULL)
{
tail = SUCC(tail);
}
SUCC(tail) = bp;
PRED(bp) = tail;
// printf("%p insert!\n", bp);
// print_free_list();
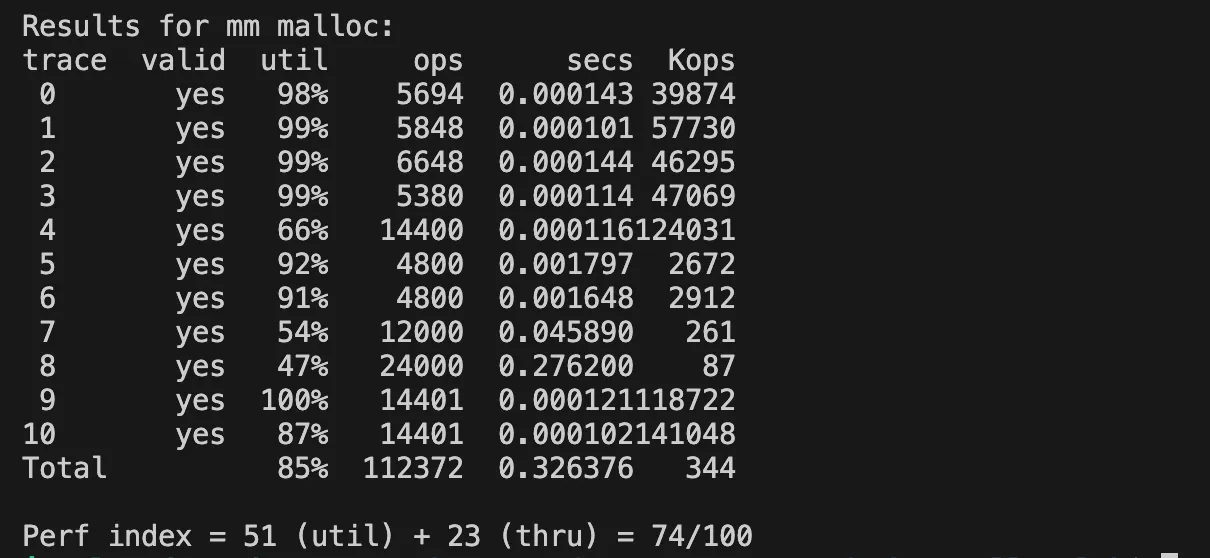
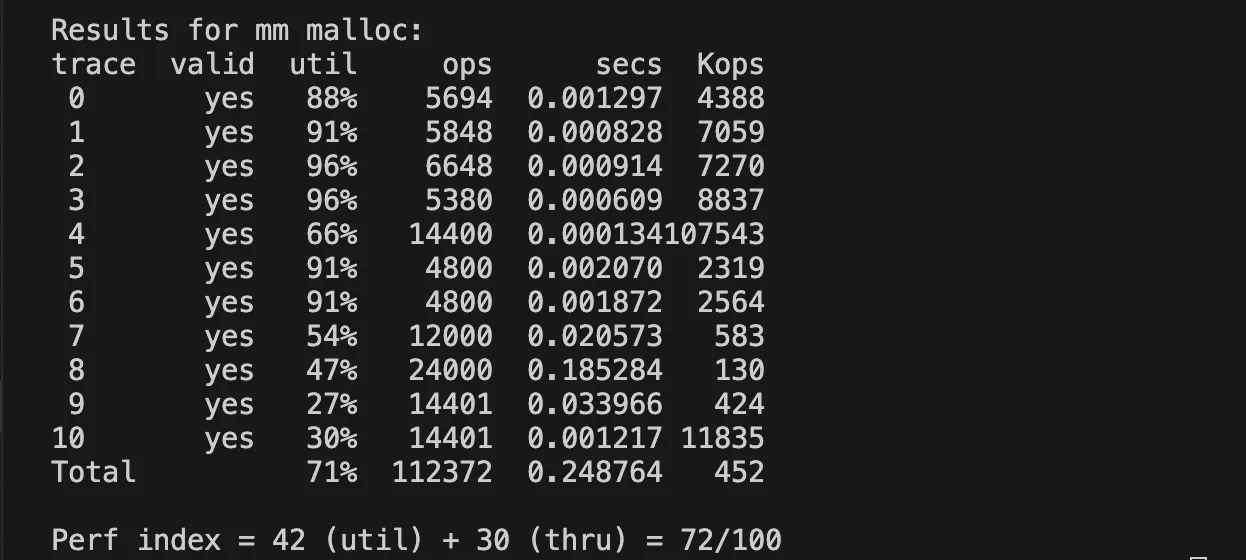
}explicit + 주소순
allocated block들이 인접한 주소에 위치한다면 free를 통해 메모리를 반환했을 때 병합될 가능성이 크다. 그래서 주소 순의 free list 관리와 first fit 정책의 조합은 병합 확률을 높이는 방법이 된다.
주소순으로 free list를 관리하면 확실히 메모리 이용률 점수가 높아지는 것을 볼 수 있다.
특히나 first fit 정책에서는 메모리 이용률이 85%까지 늘어났다.
- first fit
- next fit
// free block 노드 삽입(주소순)
void insert_free_block(void *bp)
{
if (free_listp == NULL)
{
PRED(bp) = NULL;
SUCC(bp) = NULL;
free_listp = bp;
return;
}
void *curr = free_listp;
void *prev = NULL;
while (curr != NULL && bp > curr)
{
prev = curr;
curr = SUCC(curr);
}
PRED(bp) = prev;
SUCC(bp) = curr;
// 이전 노드가 있다면
if (prev != NULL)
{
SUCC(prev) = bp;
}
else
{
free_listp = bp;
}
// 다음 노드가 있다면
if (curr != NULL)
{
PRED(curr) = bp;
}
}
