소스코드는 여기를 참고해주세요!
https://github.com/hyeona01/Data-Structures/blob/master/malloc-lab/mm.c
들어가기 전에, 실행 환경에 관련하여 엄청난 삽질을 한 이야기를 먼저 꺼낸다.
나는 맥북 M1칩에서 docker 우분투(22.04버전) OS를 돌려 X64 환경으로 세팅하였다.
하지만 도커 위에서 돌릴 때는 기존 운영체제의 포인터는 여전히 8바이트이다. 이 책에서는 실제 리눅스 환경의 32bit 시스템을 기준으로 하기 때문에 환경이 맞지 않으면 seg fault 가 생긴다.
실습 코드는 32비트 방식으로 인코딩했지만, 실제 실행환경은 64비트 환경이다. Docker든 뭐든 리눅스 커널이 x86_64이면, 아무리 코드에서 WSIZE=4 해놔도, 포인터는 8바이트이다.
더 이야기 해보자면, C에서 포인터 크기는 시스템 아키텍처에 따라 결정된다. 컴파일할 때 고칠 수 없고, 하드웨어/커널 기반으로 결정되기 때문이다.
이 사실을 이틀내내 디버깅으로 골머리 앓다가, 포기 직전에 동료를 통해 알 수 있었다 🥹
그래서 나는 WSIZE를 sizeof(void *) 로 수정해주었다. 당연히 DSIZE는 WSIZE * 2로 설정했다.
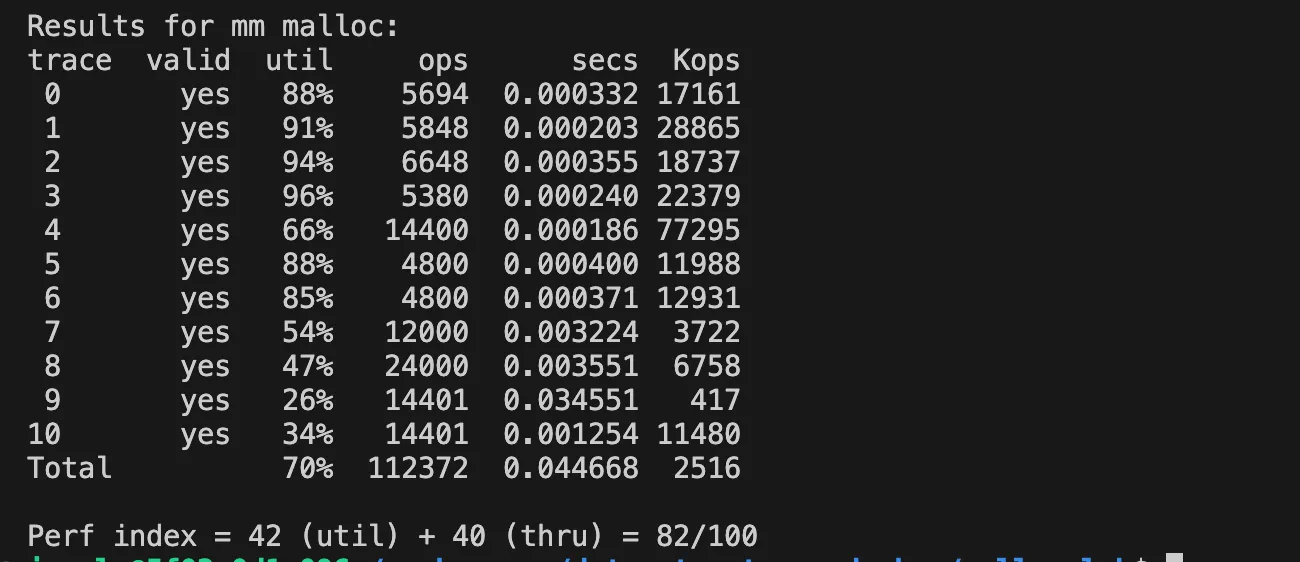
이 포스팅은 explicit free list, 명시적 가용 리스트를 LIFO+fist fit 방식으로 구현한 내용이다.
점수는 82점!
시작하자!
explicit free list
implicit free list와 다른 주요 키워드
- 블록 리스트의 시작을 가리키는 포인터
- 블록 리스트를 연결하는 구조
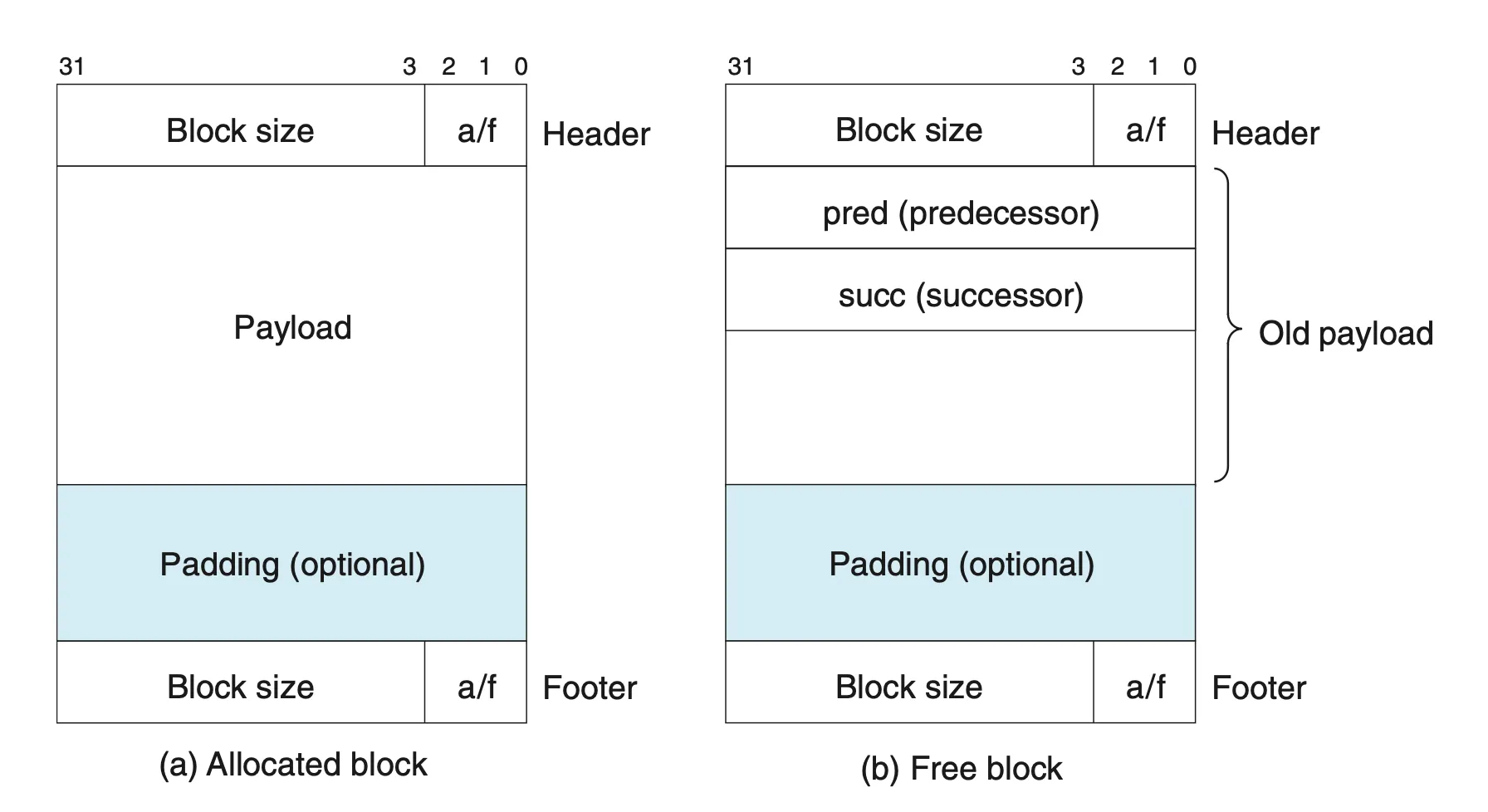
explicit free list는 Linked List 형태로 free block을 연결한다. 순서를 지정하는 데는 두 가지 방법이 있다. 1. LIFO + first fit 방식 2. 주소 순 + first fit 방식
각각 장단점이 있지만 주소 순이 LIFO 방식 보다 더 좋은 메모리 이용도를 가진다. 하지만 Linked List를 구성하는 데 더 오랜 시간이 걸리기에 LIFO 방식으로 구현한다.
흐름은 이러하다.
malloc 요청이 있을 때마다, root free block에 접근하고 size와 맞다면 할당한다.
이 방법을 위해서는 free block 의 list를 Linked List로 관리해주는 추가 작업이 필요하다.
- insert_free_block
-
최근 반환된(추가된) free block을 처음으로 순회하는 LIFO 방식으로 구현하기 때문에 free block이 추가될 때는 root를 업데이트 해준다.
-
추가된 블록의 다음 노드로 기존 root(free_listp)를 지정한다.
-
반대로 root의 이전 노드도 업데이트 해야 하지만, 존재하지 않을 경우 세그 폴트를 유발하므로 조건문으로 변경한다.
-
마지막에는 root(free_listp)를 새로운 블록의 포인터로 변경한다.
// free block 노드 삽입(LIFO) void insert_free_block(void *bp) { PRED(bp) = NULL; SUCC(bp) = free_listp; if (free_listp) PRED(free_listp) = bp; free_listp = bp; }
-
- remove_free_block
-
삭제하는 노드가 root인 경우
- root를 다음 노드로 바꿔준다.
- 새로운 root의 이전 노드를 NULL로 바꿔주며 연결을 끊는다.
-
삭제하는 노드가 중간 노드일 경우
1. 이전 노드가 있다면 이전 노드의 다음 노드를 재설정 한다.
2. 다음 노드가 있다면 다음 노드의 이전 노드를 재설정 한다.void remove_free_block(void *bp) { if (bp == free_listp) // 이 경우가 더 이해가 쉬움 { free_listp = SUCC(bp); if (free_listp != NULL) { PRED(free_listp) = NULL; } } else { if (PRED(bp)) { SUCC(PRED(bp)) = SUCC(bp); } if (SUCC(bp)) { PRED(SUCC(bp)) = PRED(bp); } } /* // 위와 같은 코드 ver.2 if (PRED(bp)) SUCC(PRED(bp)) = SUCC(bp); else free_listp = SUCC(bp); if (SUCC(bp)) PRED(SUCC(bp)) = PRED(bp); */ }
-
자, 이제 사전 세팅은 끝난거다. 본격적으로 malloc을 구성하는 함수를 구현해보자.
mm_malloc (malloc 함수)
이 함수는 지금 구현하는 과제의 메인 함수라고 볼 수 있다. 여기서 호출한 다른 함수들과 초기화는 아래에서 다룬다.
큰 흐름 먼저 알고 가는 것이 좋을 듯 하여 첫 번째로 배치한다.
malloc을 호출할 때 내부적으로 일어나는 동작들을 포함한 함수이다.
우선, CPU는 각자의 64bit 시스템, 32bit 시스템 등 각 시스템에 따라 word 단위가 달라진다. 그리고 그 단위에 맞게 데이터를 정렬하는 편이 CPU의 성능면에서 매우 메우! 좋다.
CSAPP에서는 32bit 시스템을 기준으로 WSIZE = 4Bytes, DSIZE = 8Bytes 로 설정한다.
-
할당할 메모리의 size 설정
그래서 실제 요청된 size를 정렬에 맞추어 asize라는 변수에 변경해준다.
만일, 요청된 size가 최소 데이터 정렬 단위(DSIZE)보다 작다면 블록의 헤더와 푸터의 크기를 포함한 크기만큼 할당한다.
size가 최소 단위 보다 크다면, 헤더와 푸터의 크기를 포함하고 그 크기를 올림하여 데이터 정렬 단위를 맞춰준다.
-
메모리에 할당하고, 할당된 메모리에 해결 가능한 내부 단편화가 있다면 해결한다. →
place()
void *mm_malloc(size_t size)
{
char *bp;
size_t asize; // 실제 할당할 블록 크기
size_t extendsize; // free 블록이 없을 때 확장 요청할 크기
if (size == 0)
{
return NULL;
}
if (size <= DSIZE) // payload
{
asize = 2 * DSIZE; // 헤더+푸터(8B) payload(8B)
}
else
{
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
}
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize);
return bp;
}
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
{
return NULL;
}
place(bp, asize);
return bp;
}
mm_free (malloc 반환)
해당 주소의 할당 표시를 해제 해준다.
연속된 free block과 병합하여 free list에 추가한다.
void mm_free(void *ptr)
{
// printf("----- free start ----- \n");
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
coalesce(ptr);
}mm_init (heap 초기화)
implicit 방식과 동일하게 초기화 한다.
처음에는 정렬 패딩, 프롤로그 블록, 에필로그 블록으로만 초기화 하면 된다.
단, free_listp 를 heap 초기화 단계에서 동시에 초기화 해야 한다.
heap을 재시작할 경우에도 free_listp이 초기화 되도록 신경쓰자.
int mm_init(void)
{
/* 힙 영역의 기본 구조를 위한 4 워드(4*WSIZE 바이트) 확보 - 정렬패딩, 프롤로그 헤더/푸터, 에필로그 헤더 */
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1)
{
return -1;
}
PUT(heap_listp, 0); // 정렬 패딩
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 헤더
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 푸터
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 헤더
heap_listp += (2 * WSIZE); // payload 위치
free_listp = NULL; // 초기화
/* CHUNKSIZE 바이트(보통 4096B 등)만큼 빈 블록 생성 */
if (extend_heap(CHUNKSIZE / WSIZE) == NULL)
{
return -1;
}
return 0;
}extend_heap (heap 확장)
새로운 free block이 추가되는 시점이기도 하다.
sbrk()로 정상적으로 메모리를 할당 받았다면 직전, 직후 블록과 병합할 수 있는 지 확인한다.
static void *extend_heap(size_t words)
{
char *bp; // 반환된 새 블록의 payload 시작 주소를 가리킬 포인터
size_t size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; // WSIZE를 곱하여 결국 8의 배수가 되도록 보장함
if ((long)(bp = mem_sbrk(size)) == -1)
{
return NULL;
}
PUT(HDRP(bp), PACK(size, 0)); // 새 빈 블록의 헤더 초기화
PUT(FTRP(bp), PACK(size, 0)); // 새 빈 블록의 푸터 초기화
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 새 에필로그 헤더 설정
return coalesce(bp);
}coalesce (free block 병합)
이전 블록(free list의 이전 노드가 아니다.)과 다음 블록이 할당되어있는 지 확인한다.
[ case 1: 양쪽 전부 할당 ]
현재 블록만 free block list에 추가한다.
[ case 2: 다음 블록(=free block)과 병합 가능 ]
-
병합될 다음 블록을 free list에서 제거한다.(현재 블록에 합쳐짐)
-
현재 블록과 다음 블록의 size를 더한다.
-
현재 블록 헤더에 size를 수정한다.
-
현재 블록의 푸터는 2번의 과정을 통해 자동으로 주소가 변경되며, size를 수정해준다.
자동으로 변경되는 이유는 위에 선언된 매크로의 영향이다.
#define HDRP(bp) ((char *)(bp) - WSIZE) // 1 word 패딩 이후 #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) // 2 word header 이후FTRP매크로는 헤더를 참조하여 현재 시점의 size만큼 이동하여 반환한다.
[ case 3: 이전 블록(=free block)과 병합 가능 ]
case 2와 달리, 추가로 처리해주어야 하는 점이 있다.
이전 블록과 병합했을 때는 현재 블록의 포인터가 이전 블록의 포인터 위치로 이동해야 한다.
- 병합될 이전 블록을 free list에서 제거한다.(현재 블록에 합쳐짐)
- 현재 블록과 이전 블록의 size를 더한다.
- 현재 블록 포인터를 이전 블록 포인터로 이동시킨다.
- 현재 블록 헤더에 size를 수정한다.
- 현재 블록의 푸터는 2번의 과정을 통해 자동으로 주소가 변경되며, size를 수정해준다.
[ case 4: 이전 블록, 다음 블록과 전부 병합 가능 ]
세 개의 블록 모두 현재 블록으로 합쳐지게 만들어야 한다.
- 병합될 이전 블록, 다음 블록을 free list에서 제거한다.(현재 블록에 합쳐짐)
- 현재 블록, 이전 블록, 다음 블록의 size를 더한다.
- 현재 블록 포인터를 이전 블록 포인터로 이동시킨다.
- 현재 블록 헤더에 size를 수정한다.
- 현재 블록의 푸터는 2번의 과정을 통해 자동으로 주소가 변경되며, size를 수정해준다.
static void *coalesce(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
if (prev_alloc && next_alloc)
{
// printf("----- 양쪽 블록 할당 중 ----- \n");
}
else if (prev_alloc && !next_alloc)
{
// printf("----- NEXT_BLKP 가용 ----- \n");
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc)
{
// printf("----- PREV_BLKP 가용 ----- \n");
remove_free_block(PREV_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else
{
// printf("----- 양쪽 블록 가용 상태 ----- \n");
remove_free_block(PREV_BLKP(bp));
remove_free_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(HDRP(NEXT_BLKP(bp)));
bp = PREV_BLKP(bp);
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
insert_free_block(bp); // free block 추가
return bp;
}
find_fit (적합한 free block 찾기)
- 마지막에 free된 순서(LIFO)로 free block을 순회한다.
- 요청된 크기에 맞는 지 확인하며 Linked List로 연결된 다음 free block(SUCC)으로 이동한다.
void *find_fit(size_t asize)
{
void *bp;
// first fit
for (bp = free_listp; bp != NULL; bp = SUCC(bp))
{
if (asize <= GET_SIZE(HDRP(bp)))
{
return bp;
}
}
return NULL;
}place (malloc 요청에 따른 블록 배치 및 잔여 free block 분할)
적당한 크기의 블록을 배정받는다면 두 가지 경우로 나뉘게 된다.
- 딱 맞는 크기여서 내가 쓸 만큼 쓰고나면 남는 공간이 적다.(분할하기에)
- 내가 쓸 만큼 쓰고도 남는다.
2번의 경우는 그냥 할당해주면 된다.
1번의 경우를 좀 더 살펴보자.
우선 요청하는 size는 malloc 단계에서 정렬*이 완료된 상태로 넘겨 받게 된다.
그 사이즈를 할당한 후에도 free block의 최소 크기(헤더, 푸터, PRED 포인터, SUCC 포인터 → 2 DSIZE) 보다 넉넉한 크기로 남는다면 내부 단편화를 방지하기 위해 분할한다.
*정렬 : 64비트 시스템에서는 8바이트, 32비트 시스템에서는 4바이트로 정렬되면 CPU가 빠르게 읽을 수 있다.
따라서, 내가 할당받은 블록의 사이즈 - 내가 실제로 사용할 사이즈 가 최소 free block의 크기보다 크다면 새로운 free block으로 분할한다.
- 내가 사용하려는 크기의 블록을 만든다.
- 사용할 블록의 다음 블록 위치 찾는다.
- 가용상태(0)으로 수정하고 사이즈를 설정한다.
- 초기화한 free block을 free list에도 추가한다.
void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp)); // csize: free block 크기
remove_free_block(bp);
if ((csize - asize) >= (2 * DSIZE)) // 남는 블록이 free block 최소 크기(24B->정렬 32B)보다 크다면
{
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
// 나머지는 free block으로 분할
bp = NEXT_BLKP(bp); // 나중에 free block 합침(지연 연결)
// 블록 정보 업데이트
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
// free list 업데이트
insert_free_block(bp);
}
else
{
// 분할 불가 - 잔여 block이 넉넉치 않고 fit함
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}이틀 내내 삽질하면서 다양한 구현 방식을 알 수 있었다.
WSIZE를 시스템에 맞춰주지 않으니, 자꾸 free list에 쓰레기 값이 들어가는 것을 확인했다. 쓰레기값을 방지하기 위해서 방어 코드도 열심히 구현해보았다. 물론 지금 포스팅한 코드에는 불필요하다고 판단하여 배제했지만 깃허브 커밋 기록은 남겨두었다.
다양한 방식으로 시도하면서 코드를 완전하게 이해하는 시간이 되었다.
결코 헛된 시간은 없다!
