[논문 리뷰 - 2] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
논문 리뷰
목록 보기
28/42
‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2310.11511
Introduction
- 본 연구는 언어 모델(LLM)의 생성 품질과 사실 정확성을 유연성을 해치지 않으면서도 개선하기 위해, 필요할 때만 검색을 수행하고 자기 성찰(self-reflection)을 적용하는 Self-Reflective Retrieval-Augmented Generation(SELF-RAG)을 제안한다.
- 임의의 언어 모델(LM)을 end-to-end 방식으로 훈련시켜, 작업 입력이 주어졌을 때 자신의 생성 과정을 반성(reflect)하도록 하며, 이때 작업 결과와 함께 중간중간 특수 토큰(즉, 반성 토큰, reflection tokens)을 생성한다.
- 반성 토큰은 검색 필요성(retrieval token)과 생성 품질(critique token)을 각각 나타내는 것으로 분류된다.
작동 원리
- 입력 프롬프트와 이전 생성 결과가 주어지면 Self-RAG는 우선 검색된 지문을 추가하는 것이 계속되는 생성에 도움이 될지 판단한다.
- 만약 도움이 된다고 판단되면, 반성 토큰 중 하나인 retrieval token을 출력하여 필요할 때 검색 모델(retriever)을 호출한다(Step 1).
- 이후 Self-RAG는 여러 검색된 지문을 동시에 처리하면서, 각 지문의 관련성을 평가한 뒤 해당 작업에 맞는 출력을 생성한다(Step 2).
- 마지막으로, Self-RAG는 자신의 출력을 비평하는 critique token(비평 토큰)을 생성하여, 사실성(factuality)과 전반적인 품질을 기준으로 가장 좋은 답변을 선택한다(Step 3)
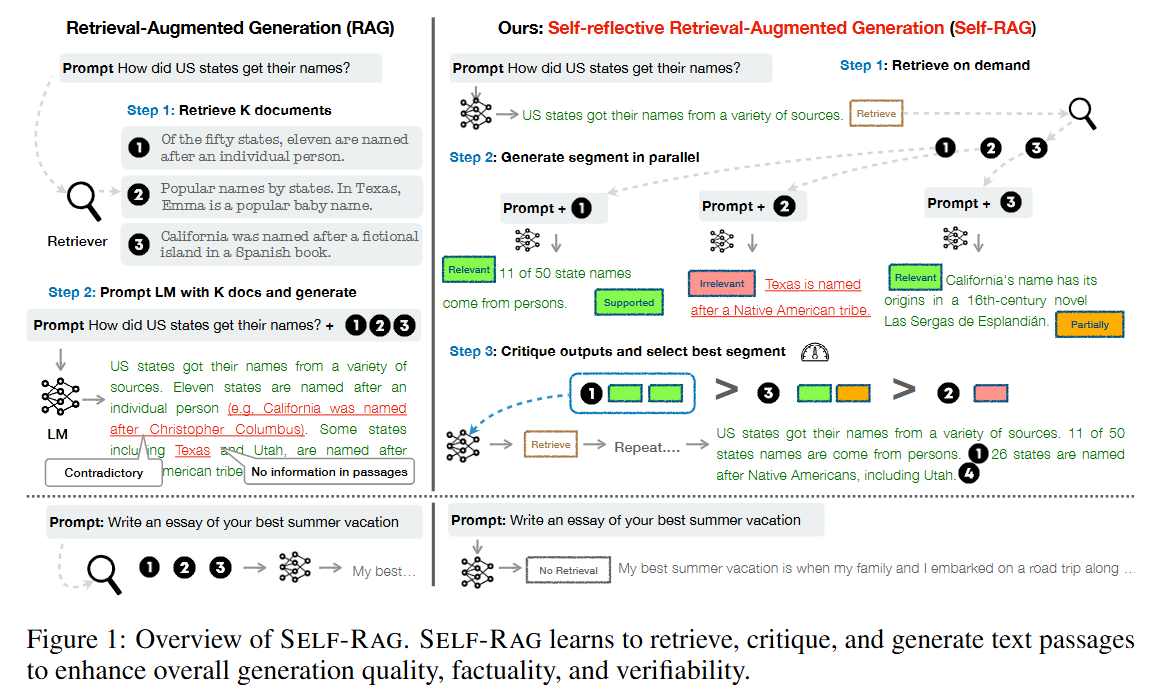
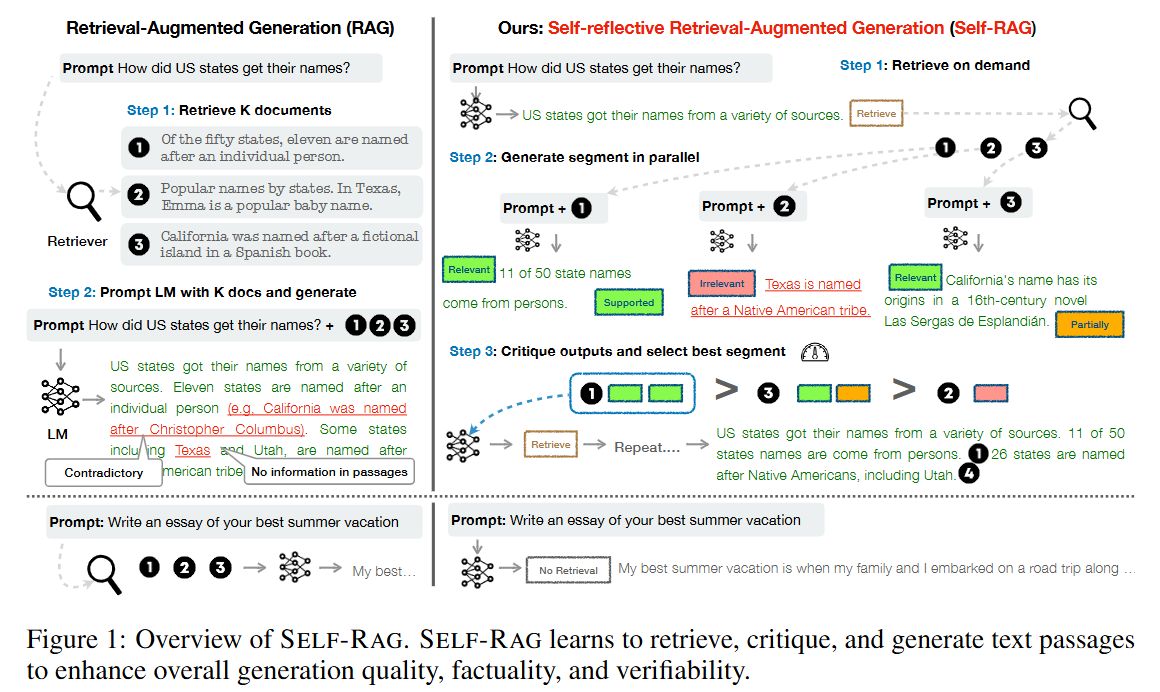
기존 RAG와의 차이점(Figure 1 설명)
- 기존 RAG는 검색이 필요한지 여부와 상관없이 항상 고정된 수의 문서를 검색해 생성에 활용하며(예: 아래 그림의 예시처럼 사실 정보가 필요 없는 경우에도), 생성 결과의 품질을 다시 점검하지 않는다.
- 반면, SELF-RAG는 각 세그먼트(문단/문장)마다 인용을 제공하고, 자신의 출력이 해당 지문에 의해 뒷받침되는지 스스로 평가한다. 이로 인해 사실 검증이 더 쉬워진다
Self-RAG 학습 방식
- Self-RAG는 임의의 언어 모델(LM)이 반성 토큰(reflection tokens)을 포함한 텍스트를 생성하도록 훈련시키며, 이때 반성 토큰을 확장된 모델 어휘의 일부(다음 토큰 예측 대상)로 통합한다.
- 생성기 LM은 다양한 텍스트와 반성 토큰, 그리고 검색된 지문이 섞인 데이터셋을 바탕으로 학습한다.
- 반성 토큰은 강화학습에서 사용되는 보상 모델(Ziegler et al., 2019; Ouyang et al., 2022)에서 영감을 받아, 훈련된 비평가 모델(critic model)이 오프라인으로 원본 말뭉치에 삽입한다. 이로 인해 학습 과정에서 별도의 비평가 모델을 계속 사용할 필요가 없어 오버헤드가 줄어든다.
- 비평가 모델은 GPT-4와 같은 대형 언어 모델을 사용해 생성된 입력, 출력, 그리고 그에 해당하는 반성 토큰 데이터셋을 바탕으로 지도학습된다.
- 텍스트 생성의 시작과 흐름을 조절하는 컨트롤 토큰을 활용한 기존 연구(Lu et al., 2022; Keskar et al., 2019)에서 영감을 받았지만, Self-RAG에서는 학습된 LM이 각 생성 세그먼트 이후 자신의 예측을 평가하는 비평 토큰(critique tokens)을 생성 결과의 필수 요소로 사용한다.
Self-RAG의 추론 알고리즘
- Self-RAG는 반성 토큰(reflection token) 예측 결과를 바탕으로 강(hard) 또는 약(soft) 제약 조건을 충족하는 맞춤형 디코딩 알고리즘을 추가로 제공한다.
- Self-RAG의 추론(inference) 알고리즘은
(1) 다양한 하위 작업에 따라 검색 빈도를 유연하게 조정할 수 있고,
(2) 반성 토큰의 확률을 가중된 선형 합으로 계산하여 세그먼트별 점수로 활용함으로써, 사용자 선호에 맞게 모델의 행동을 맞춤화할 수 있다. - 이 과정은 세그먼트 단위의 빔 서치(segment-level beam search)를 통해 이루어진다.
Self-RAG 성과(연구 성과)
- 추론 및 장문 생성 등 6가지 과제에 대한 실험 결과, Self-RAG는 파라미터 수가 더 많은 사전 학습 및 명령어 튜닝된 LLM과 널리 사용되는 RAG 접근법보다 인용 정확도(citation accuracy)에서 크게 앞선 성능을 보인다.
- 특히, Self-RAG는 검색 기반 ChatGPT를 네 가지 과제에서, 그리고 Llama2-chat(Touvron et al., 2023)과 Alpaca(Dubois et al., 2023)는 모든 과제에서 능가한다.
- 분석 결과, 반성 토큰(reflection tokens)을 활용한 학습 및 추론이 전반적인 성능 향상과 함께, 테스트 시 모델의 맞춤화(예: 인용 예측과 완전성 사이의 균형 조정 등)에도 효과적임을 확인했다.
Conclusion
- 본 연구는 필요할 때만 검색을 수행하고 자기 성찰(self-reflection)을 적용하여 대형 언어 모델(LLM)의 품질과 사실성을 높이는 새로운 프레임워크인 Self-RAG를 제안한다.
- Self-RAG는 언어 모델(LM)이 기존 어휘와 새로 추가된 특수 토큰(반성 토큰, reflection tokens)을 모두 예측함으로써, 텍스트 구문을 검색·생성·비평하고, 자신이 생성한 결과에 대해 평가하는 방법을 학습한다.
- 또한, Self-RAG는 반성 토큰을 활용하여 추론(테스트) 단계에서 모델의 행동을 맞춤화할 수 있다.
- 여섯 가지 과제에서 여러 지표를 통해 평가한 결과, Self-RAG는 파라미터가 더 많은 LLM이나 기존의 검색 기반 생성(RAG) 접근법보다 훨씬 우수한 성능을 보인다.

데이터 분석가