1. Prompt Engineering
(1) 프롬프트(Prompt)란?
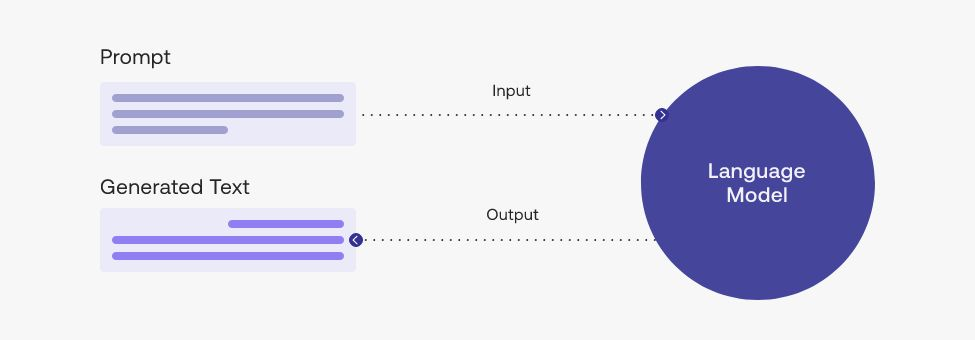
프롬프트(Prompt)란 생성 인공지능(Generative AI) 분야에서 거대 언어 모델(Large Language Model; LLM)로부터 응답을 생성하기 위한 입력값이다.
우리가 ChatGPT에게 던지는 질문이 바로 '프롬프트'이다.
(2) 프롬프트 엔지니어링(Prompt Engineering)이란?
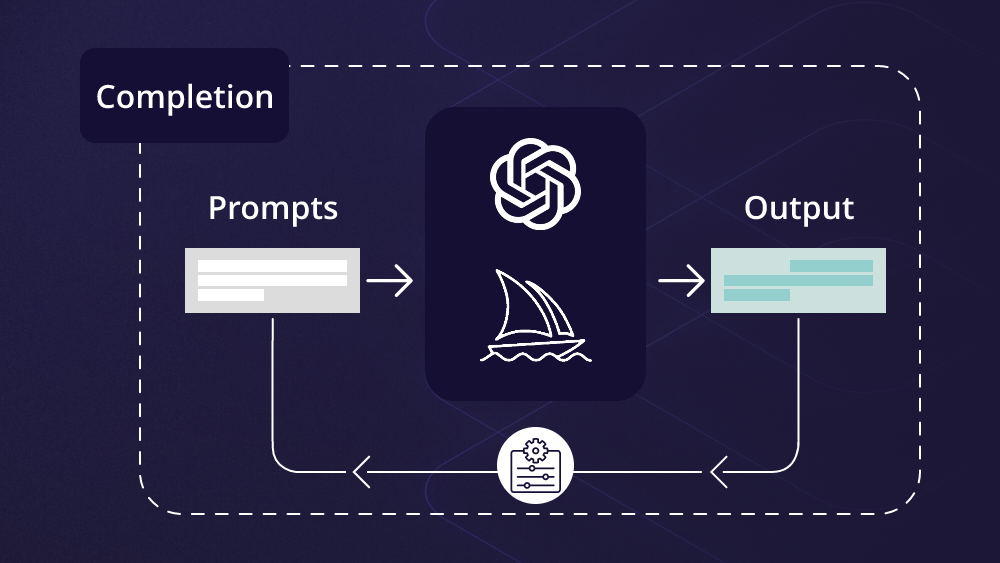
프롬프트 엔지니어링(Prompt Engineering)은 거대 언어 모델로부터 높은 품질의 응답을 얻어낼 수 있는 이러한 프롬프트 입력값들의 조합을 찾는 작업을 의미한다.
쉽게 말해, AI로부터 최상의 답변을 끌어내기 위해 최적의 단어, 즉 입력값들의 조합을 찾는 작업이다.
더 쉽게 말하자면, 더 좋은 답변을 얻어내기 위해 좋은 질문을 찾는 작업이다.
프롬프트 엔지니어링이 필요한 이유
아니, 그동안 별 생각 없이 ChatGPT를 이용했는데 더 좋은 답변을 얻어낼 수 있는 방법이 있었다고?
근데 내가 질문을 잘 해야 좋은 답을 받을 수 있다고?
나는 지금까지 잘 이용했고 답변도 충분히 만족스러웠는데?
이렇게 생각할 수도 있다.
그러나 다음을 확인해보면 프롬프트 엔지니어링의 중요성을 알 수 있다.
1) ChatGPT의 허구성

기사로도 날 정도로 유명해진 "세종대왕 맥북프로 던짐 사건"
많은 사람들이 ChatGPT로 과제를 하거나 정보를 확인하는 등 유용하게 사용하고 있지만, 사실 ChatGPT가 내놓는 답변은 완전히 신뢰할 수 없다.
이를 단적으로 보여주는 예시가 바로 위 이미지에서 볼 수 있는 세종대왕 맥북프로 던짐 사건 이다.
ChatGPT는 생성 AI 모델이다.
다시 말해, ChatGPT는 input으로 들어오는 값과 본인이 알고있는 정보들을 조합해 굉장히 그럴듯해 보이는 말을 만드는 모델이다.
그렇기 때문에 ChatGPT가 제공하는 답변을 그대로 쓸 수 없고,
이렇게 정확하지 않은 정보를 제공하는 일을 방지하기 위해, 내가 원하는 답변을 받을 수 있도록 이에 맞는 질문을 작성해야 할 필요가 있다.
실제로 우리의 프로젝트 믿어방 에서 특정 특약과 관련된 기사나 판례를 찾는 작업에 ChatGPT를 활용하려고 했는데, 결론만 말하자면 실패했다.
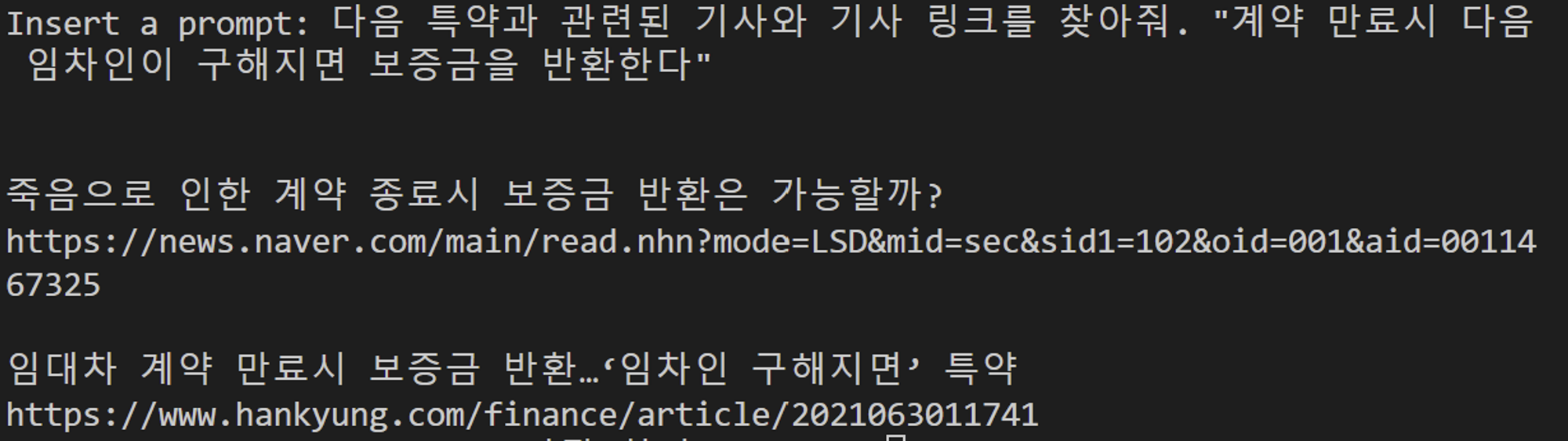
일단, ChatGPT는 2021년 9월까지의 데이터로 학습되었기 때문에 최신 정보를 가져올 수 없다.
그리고 실제로 ChatGPT가 제공해준 기사/판례/유튜브 URL은 존재하지 않거나 아예 다른 기사의 링크였다.
그렇기 때문에 기사/판례를 찾는 일에 ChatGPT를 활용하는 것은 결국 포기했고,
이로 인해 프롬프트 엔지니어링의 중요성을 절감하게 되었다.
(+)
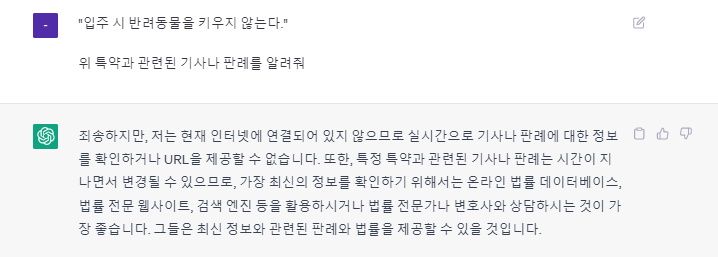
2023년 5월 16일 기준, ChatGPT의 답변 내용이 바뀌었다.
3월까지만 해도 엉뚱한 내용을 알려줬었다.
2) 더 높은 퀄리티의 응답
GPT와 같은 거대 언어 모델에서는 프롬프트에 포함된 문구들의 미세한 조정이 결과물에 극적인 차이를 가져올 수 있다.
다음 두 문장을 살펴보자.
" Tell me who invented the email. "
" Tell me about the person invented the email. "
두 문장은 둘 다 이메일을 발명한 사람에 대해 알려달라는 문장으로, 의미적으로 차이가 없다.
그러나 이 두 문장은 ChatGPT의 프롬프트에 입력한 결과는 놀랍도록 다르다.
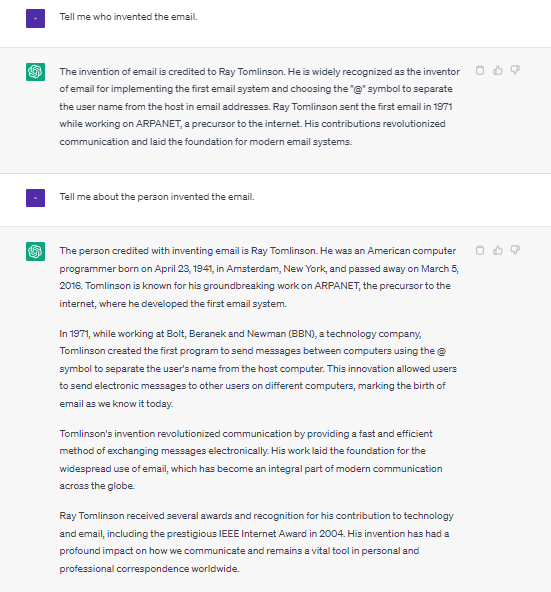
who 를 about the person 으로 바꾸는, 아주 미세하게 조금 더 인물에 집중하는 문장으로 바꿨을 뿐인데 ChatGPT가 작성한 답변의 양과 질은 아주 판이하다.
이처럼 더 퀄리티 높은, 그리고 내가 원하는 답변을 받기 위해서는 ChatGPT와 같은 모델이 잘 이해할 수 있도록 정제된 언어로 구조화된 프롬프트를 작성하는 것이 중요하다.
사실 일반 사용자 입장에서, 프롬프트 엔지니어링이란 결국 수많은 실험의 연속일 수밖에 없다.
(3) 프롬프트를 잘 작성하는 방법
✔️ 최신 모델을 사용하자
https://platform.openai.com/docs/models
위 링크에서 openai가 제공하는 모델들의 정보를 확인할 수 있다.

현재 GPT-4 모델까지 나왔는데, 보이다시피 아직 Limited beta 이다.
그래서 설명은 GPT-3.5 중심으로 하겠다.
GPT-3.5 는 다음과 같다.

-
gpt-3.5-turbo:
대화형 AI 모델로, 텍스트에 기반한 질문과 답변, 자유로운 대화, 요약, 번역 등 다양한 자연어 처리 작업에 사용될 수 있다. -
gpt-3.5-turbo-0301:
gpt-3.5-turbo의 2023년 3월 1일의 Snapshot이다. gpt-3.5-turbo와 달리 업데이트가 되지 않고, 3개월 뒤에 deprecated 된다. 그리고 (ex) gpt-3.5-turbo-0601 와 같이 새 버전이 나온다. -
text-davinci-003:
더 크고 더 강력한 AI 모델로, 복잡한 자연어 이해와 생성 작업에 사용된다.
다양한 분야의 글 작성, 기사 생성, 스토리 텔링, 문장 완성 등에 적합하다. -
text-davinci-002:
text-davinci-003의 이전 버전으로, 비슷한 기능을 제공하지만 더 작은 모델 크기와 제한된 성능을 가진다. -
code-davinci-002:
프로그래밍에 특화된 AI 모델로, 소스 코드 생성, 문제 해결, 코드 리뷰 등에 사용된다.
여기서 최신 모델을 사용하라는 말은, text-davinci-002 모델보다는 text-davinci-003 모델을 사용하라는 말이다.
우리는 ChatGPT와 같이 대화형 모델을 사용하고 싶으므로 text-davinci-003 대신 gpt-3.5-turbo 을 사용해 API를 사용할 예정이다.
(실제로 text-davinci-003도 사용해보았는데 개인적으로는 gpt-3.5-turbo를 사용했을 때 답이 더 좋았다.)
✔️ 프롬프트는 instruction으로 시작하고, context와 instruction을 구분하자.
내가 요구하고자 하는 사항이 무엇인지 프롬프트의 제일 첫 부분에 명시하고,
### 나 """ 을 사용해 context를 분리해 보다 더 잘 인지할 수 있도록 한다.
instruction: 모델이 수행하기를 원하는 특정 태스크 또는 지시 사항context: 모델이 보다 더 나은 답변을 하도록 유도하는 외부 정보 또는 추가 내용
-예시-
[기존]
Summarize the text below as a bullet point list of the most important points.
{text input here}[적용]
Summarize the text below as a bullet point list of the most important points.
Text: """
{text input here}
"""✔️ 최대한 명확하게 작성해야 하며 내가 원하는 결과 또한 자세하게 알려준다.
내가 어떠한 답변을 원하는지 명확하고 자세하게 작성하고,
내가 원하는 답변의 스펙에 대해서도 최대한 자세하게 작성한다.
ex) 답변의 길이, 형식, 스타일 등
-예시-
[기존]
Write a poem about OpenAI.[적용]
Write a short inspiring poem about OpenAI, focusing on the recent DALL-E product launch (DALL-E is a text to image ML model) in the style of a {famous poet}✔️ 예시를 사용하자.
내가 어떠한 답변을 원하는지 예시를 같이 제공해 내가 원하는 응답을 받을 수 있게 한다.
-예시-
[기존]
Extract the entities mentioned in the text below. Extract the following 4 entity types: company names, people names, specific topics and themes.
Text: {text}[적용]
Extract the important entities mentioned in the text below. First extract all company names, then extract all people names, then extract specific topics which fit the content and finally extract general overarching themes
Desired format:
Company names: <comma_separated_list_of_company_names>
People names: -||-
Specific topics: -||-
General themes: -||-
Text: {text}✔️ Zero-Shot -> Few-Shot -> fine-tune 순으로 진행하자.
먼저 Zero-Shot으로 시작하고,
그 후에 Few-Shot을,
그리고 두 방법 다 결과가 별로라면 그 때 fine-tune 을 진행한다.
-예시-
[Zero-Shot]
Extract keywords from the below text.
Text: {text}
Keywords:[Few-Shot]
Extract keywords from the corresponding texts below.
Text 1: Stripe provides APIs that web developers can use to integrate payment processing into their websites and mobile applications.
Keywords 1: Stripe, payment processing, APIs, web developers, websites, mobile applications
##
Text 2: OpenAI has trained cutting-edge language models that are very good at understanding and generating text. Our API provides access to these models and can be used to solve virtually any task that involves processing language.
Keywords 2: OpenAI, language models, text processing, API.
##
Text 3: {text}
Keywords [fine-tune]
분량상 생략[더 좋은 프롬프트 작성을 위한 프레임워크들]
Zero-Shot Prompting
Zero-Shot Prompting은 추가 학습 또는 예제 데이터 없이 답변을 생성하게 하는 프레임워크로, 거대 언어 모델에게 아무런 instruction 없이 완수할 태스크를 주는 것을 의미한다.
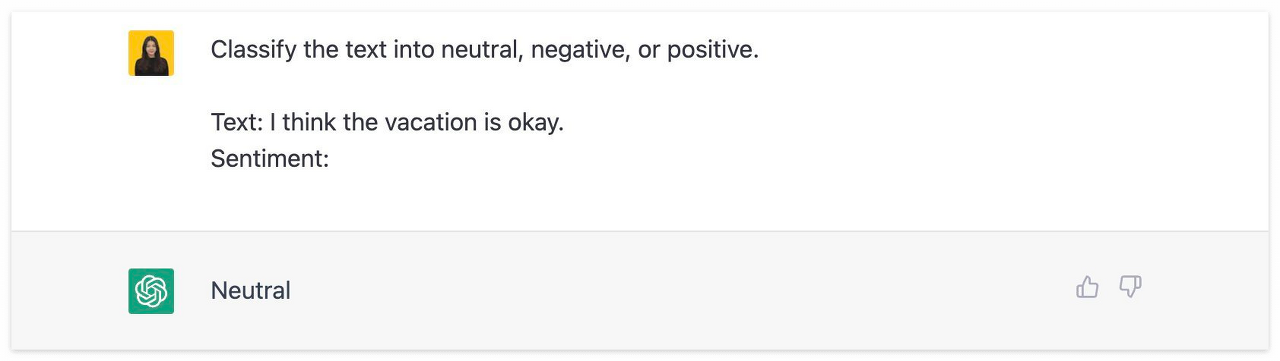
아무것도 알려주지 않아도 'Text:' 다음에 오는 문장의 'Sentiment (감정)'이 Neutral (중립)이라는 것을 올바르게 추론하였다.
One-Shot Prompting
One-Shot Prompting은 하나의 예제 또는 템플릿를 기반으로 답변을 생성하게 하는 기법으로, ialogue management, context modeling 과 같은 기타 NLP 기법들과 조합되어 보다 정확한 답변을 유도한다.
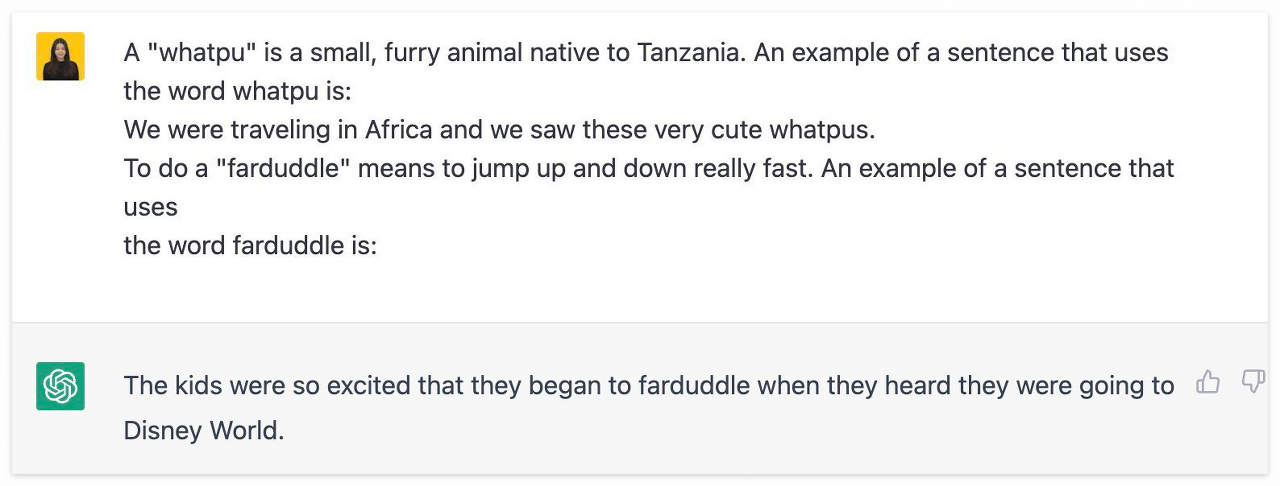
우선 'whatpu'라는 단어의 뜻과 해당 단어를 활용하여 문장을 생성하여 이를 하나의 예제로 제공한 후, 'farduddle'이라는 단어의 뜻을 주고 해당 단어를 활용하여 문장을 생성하라고 지시했다.
Few-Shot Prompting
Few-Shot Prompting은 두 개에서 다섯 개의 예제를 바탕으로 답변을 생성하게 하는 기법으로, 프롬프트 앞단에 One-Shot Prompting 기법 보다 조금 더 AI에게 직접적으로 원하는 답변에 도달할 수 있도록 유도한다.
다만, 답변에 도달하기까지 몇 단계의 추가적인 추론 과정을 거쳐야하는 보다 복잡한 문제의 경우 풀 수 없다는 한계가 있는데, 이는 CoT(Chain-of-Thought)에서 보완 가능하다.
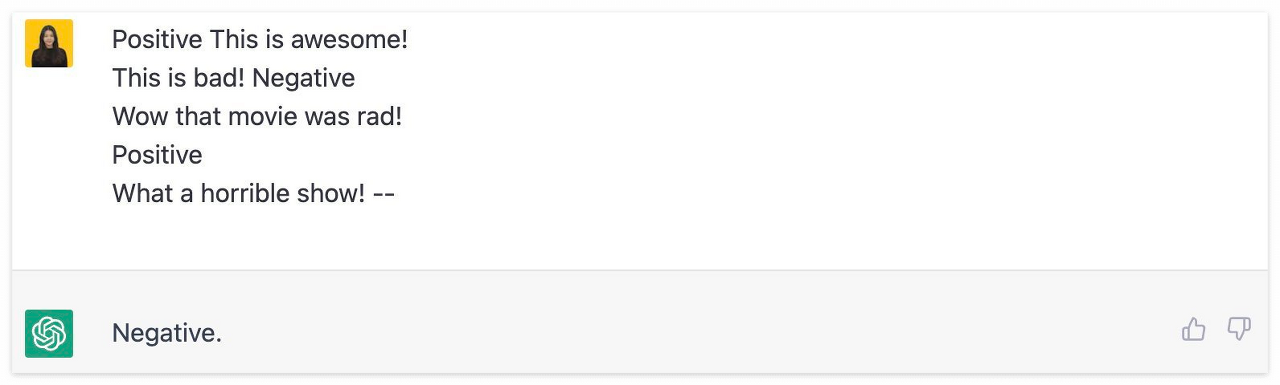
두 개에서 다섯개의 예제를 먼저 제공한 후, 마지막에 오는 문장에 알맞는 감정을 추론하게 하였다.
CoT (Chain-of-Thought)
CoT (Chain-of-Thought)는 단지 답변을 내놓기 위한 것이 아닌, 답변에 도달하는 과정을 학습시키는 것을 목적으로 본 질문 전에 미리 태스크와 추론 과정을 포함한 답변 예제를 AI에게 제공하는 프레임워크이다.
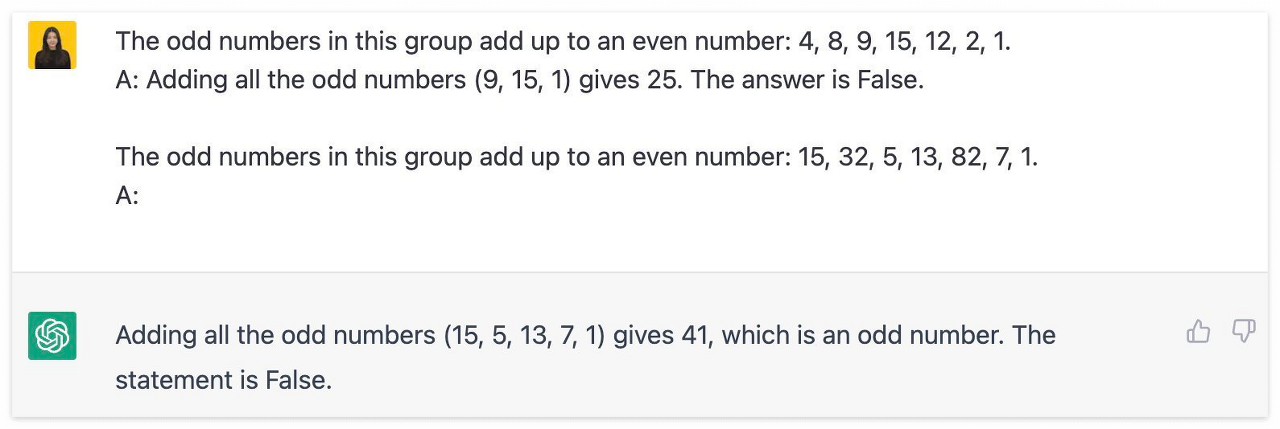
위 예시들과 유사하게 먼저 질문과 답변 예시를 주는 것은 동일하나, 답변까지 어떻게 도달하였는지 추론 과정을 포함하여 예제를 제공한다.
즉, AI가 이번에는 단순하게 다음 질문에 대한 답변만을 주는 것이 아니고, 어떻게 해당 답변에 도달하였는지 스스로 설명을 한다.
Zero-Shot CoT (Chain of Thought)
Zero-Shot CoT (Chain of Thought)는 트리거 문장 "Let's think step by step (단계별로 생각해보자)" 을 프롬프트에 추가하여 거대 언어 모델이 단계에 따라 결과에 도달하게 하는 프레임워크이다.
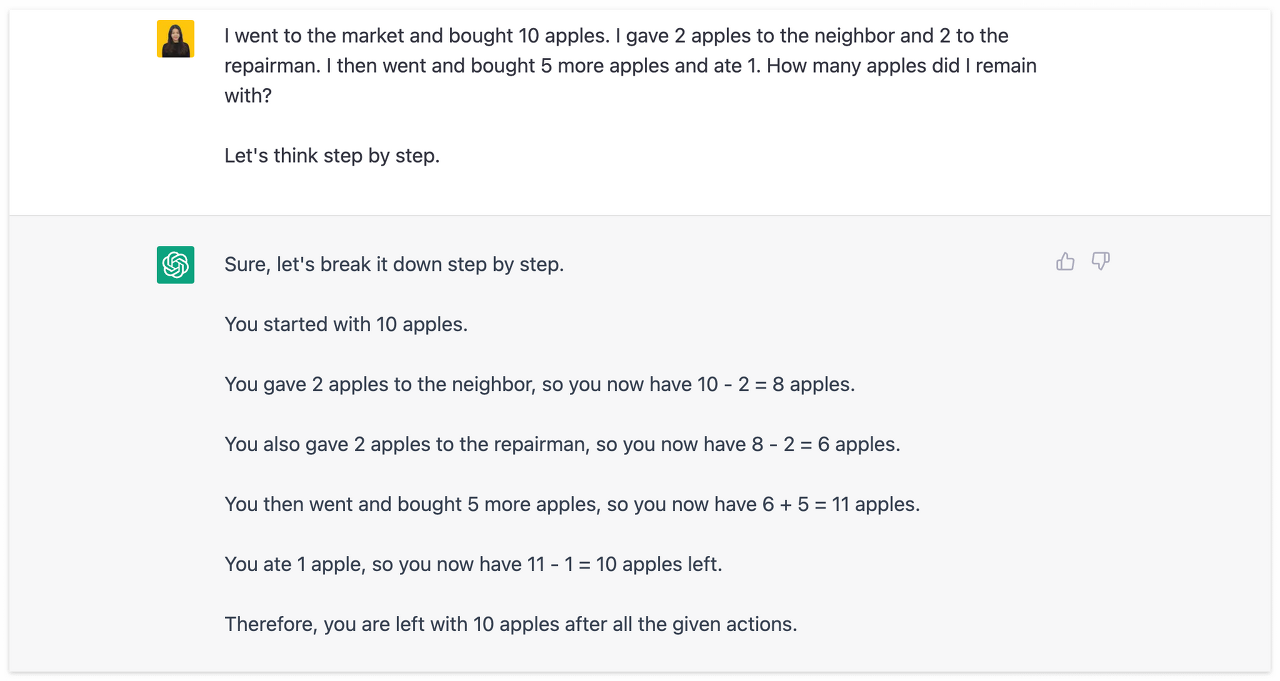
앞선 CoT 프롬프트에 "Let's think step by step (차근차근 생각해보자)" 한 문장만 추가한 것이 전부인데 이번에는 추론 과정을 '단계'별로 풀어서 설명한다.
Self-Consistency
Self-Consistency는 CoT의 심화버전으로, 보다 다양한 추론 과정을 예제로 제공하여 AI가 보다 일관성 있는 답변을 선택하여 생성할 수 있도록 돕는 프레임워크이다.
기존에 CoT 프레임워크와의 차이점은, 수학적 & 상식적인 추론이 요구되는 태스크 수행 능력이 향상되었다는 점이다.
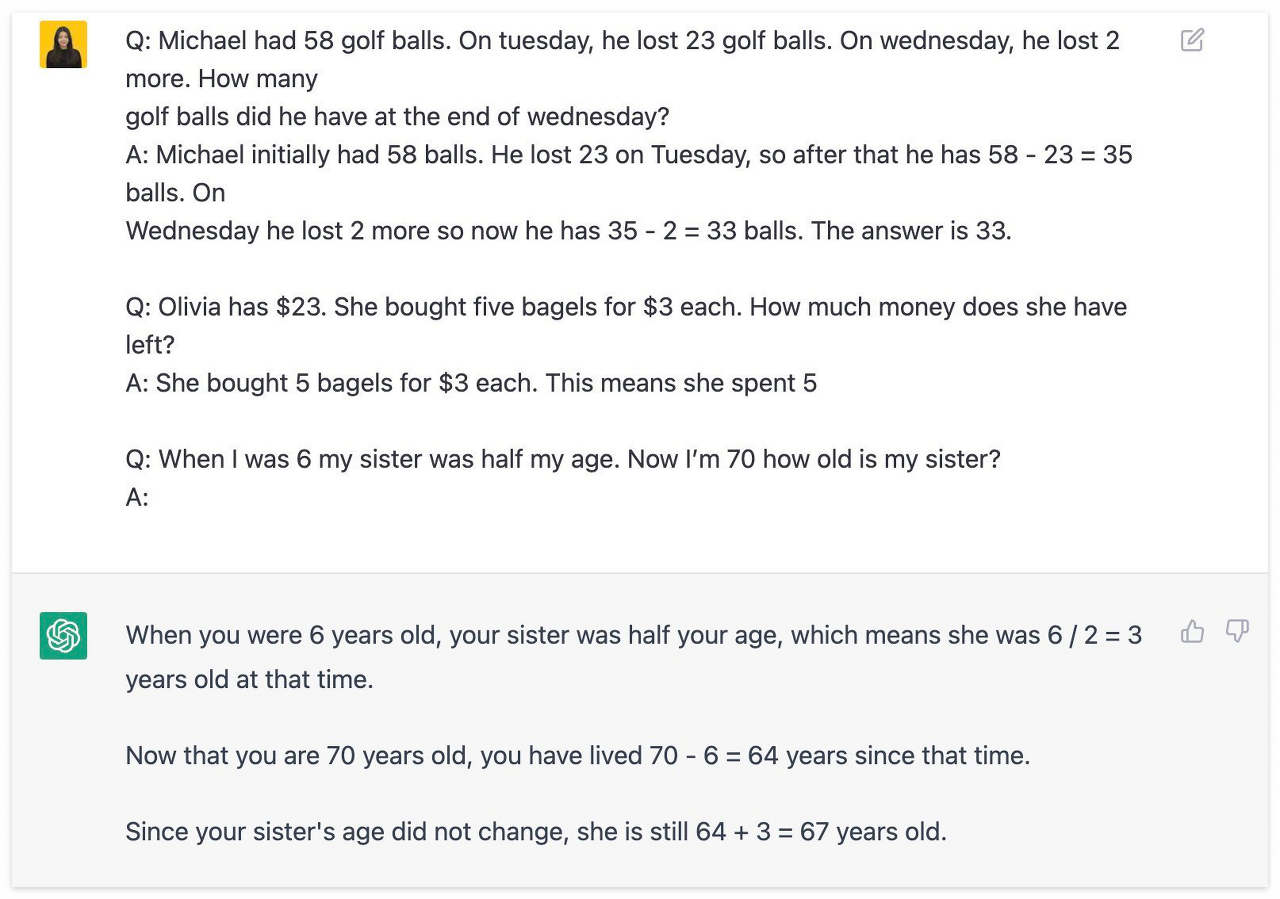
CoT와 동일한 기법이나 수학적, 상식적으로 조금 더 복잡한 추론이 요구되는 질문에 대한 추론 과정을 예제에 포함하여 넣는다
Generated Knowledge Prompting
Generated Knowledge Prompting은 모델이 보다 정확한 답변을 산출해 내기 위해 지식이나 정보를 통합할 수 있도록 질문과 함께 관련 지식이나 정보를 함께 제공하는 기법으로,
기존 모델의 유연성은 유지하면서 상식 추론 (Commonsense Reasoning) 능력을 향상시킬 수 있는 장점이 있다.

질문과 함께 해당 질문과 관련된 '지식'을 제공하면 모델이 답변 예제가 없어도 제공된 '지식'을 기반으로 기반으로 추론을 하여 답변을 내놓는다.
✔️ 애매모호한 표현을 줄이자.
부정확하고, 모호한 표현들은 최대한 사용하지 않는다.
-예시-
[기존]
The description for this product should be fairly short, a few sentences only, and not too much more.[적용]
Use a 3 to 5 sentence paragraph to describe this product.✔️ '하지마' 보다는 '해라'
하지 말아야 할 것을 언급하는 대신에, 무엇을 해야 하는지를 말한다.
-예시-
[기존]
The following is a conversation between an Agent and a Customer. DO NOT ASK USERNAME OR PASSWORD. DO NOT REPEAT.
Customer: I can’t log in to my account.
Agent:[적용]
The following is a conversation between an Agent and a Customer. The agent will attempt to diagnose the problem and suggest a solution, whilst refraining from asking any questions related to PII. Instead of asking for PII, such as username or password, refer the user to the help article www.samplewebsite.com/help/faq
Customer: I can’t log in to my account.
Agent:✔️ 코드 생성 시: leading words 를 사용하자.
-예시-
[기존]
# Write a simple python function that
# 1. Ask me for a number in mile
# 2. It converts miles to kilometers[적용]
# Write a simple python function that
# 1. Ask me for a number in mile
# 2. It converts miles to kilometers
importimport를 추가함으로써 이 코드가 python으로 작성될 수 있도록 힌트를 제공한다.
비슷하게, SQL같은 경우는 SELECT를 사용하면 된다.
✔️ Parameters 조정하기
아래의 parameter의 값을 조절하여 모델의 output을 조정한다.
-
model
성능이 높은 모델일수록 비용과 latency가 높다. -
temperature
temperature 값이 높을수록 더 창의적이고 random한 답변을 제공한다.
데이터 추출 및 진실한 Q&A와 같은 대부분의 사실적 사용 사례의 경우에는 보통 0으로 설정한다.
(주의해야 할 점은, 이 값이 "truthfulness"과는 다르다는 점이다.) -
max_tokens (maximum length)
모델이 처리할 수 있는 입력 텍스트의 최대 토큰 수를 나타내는 매개변수로, max_token 값을 설정하여 모델이 처리할 수 있는 입력의 크기를 제한할 수 있다.
큰 max_token 값을 사용할수록 더 긴 텍스트를 처리할 수 있지만, 처리 시간과 비용이 증가할 수 있다. -
stop (stop sequences)
모델의 생성 결과에 영향을 주는 매개변수로, 텍스트 생성을 중단하는 용도로 사용된다.
stop에 지정된 문자열 또는 토큰을 만나면 모델은 생성을 중단하고 결과를 반환하기 때문에 이를 활용하여 원하는 길이의 생성 결과를 제어하거나 원치 않는 내용이 생성되는 것을 방지할 수 있다.
2. Prompt Engineering 테스트
(0) "믿어방"의 챗쪽이
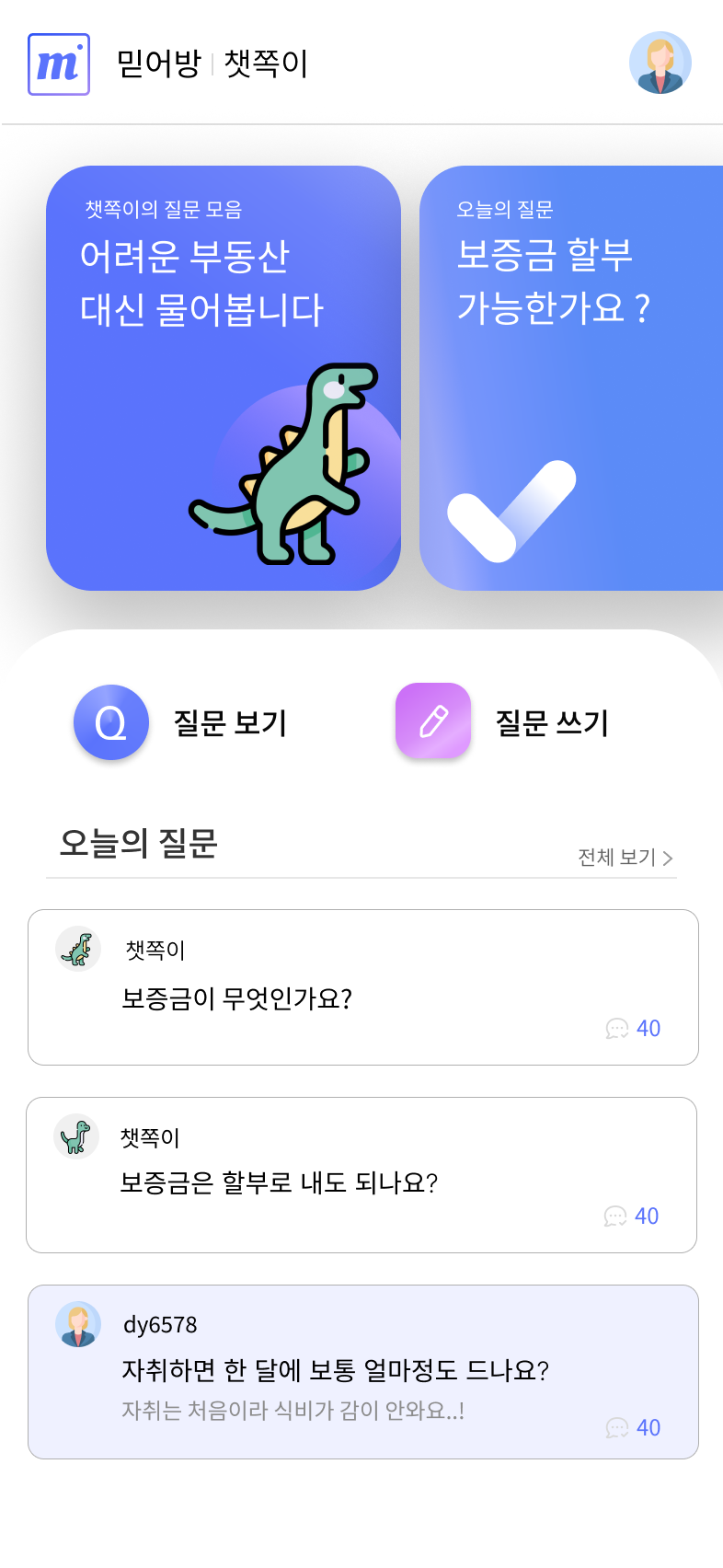
"믿어방"의 커뮤니티는 조금 독특하다.
유저들이 자유롭게 질문과 답변을 올리는 기능만 있는 일반 커뮤니티와는 달리,
"믿어방"의 커뮤니티에는 챗쪽이 가 있다.
물론 "믿어방"에도 유저들끼리 질문을 올리고 답을 달 수 있는 일반 게시판 기능이 존재한다.
챗쪽이 는 ChatGPT의 의외성과 허구성을 역으로 사용한 기능이다.
ChatGPT는 매일 오전 6시에 질문을 2개씩 올린다.
하나의 질문은 "보증금이란 무엇인가요?" 처럼, 계약에 대해 잘 모르는 사회초년생이 할 법한 질문이다.
다른 하나의 질문은 "보증금은 할부로 내도 되나요?" 처럼 다소 황당하고 웃기게 보일 수 있는 질문이다.
이 기능을 통해 유저들은 본인이 알고있는 정보 및 지식을 댓글을 통해 공유할 수 있고,
만약 잘못된 정보를 알고 있었다면 다른 유저들이 정정해줄 수 있고,
또 몇몇 유저들은 자연스럽게 지식을 습득할 수 있다.
후자의 질문은 조금 유치하게 보일 수 있는 질문이라 이 질문이 과연 도움이 될까 라는 의문이 들 수도 있지만,
정말 이에 대해 궁금했는데 익명임에도 부끄러워서 물어보지 못 한 사람이 있을 수 있고,
생각 안 해봤는데 듣고 보니 궁금한 사람이 있을 수도 있고,
다소 어렵고 무거운 '임대차계약'이라는 분야를 조금 편하게 느낄 수도 있기 때문에
유치하게 보일 수 있는 질문도 포함시켰다.
그리고 여기서 생성 AI인 ChatGPT가 큰 도움이 될 거라고 생각했다.
그래서 ChatGPT가 매일 올리는 질문 2개, 여기에 Prompt Engineering을 적용했다.
(1) 임대차 계약에 대해 잘 모르는 사회 초년생이 할 법한 질문

ChatGPT에 "임대차 계약에 대해 잘 모르는 사회초년생이 할 법한 질문 리스트 좀 만들어줘" 문장을 입력하니 다음과 같은 답변을 받았다.
질문 리스트를 봤을 때 질문들은 정말 사회초년생이 할 법한 질문이었다.
그러나 "보증금도 할부가 되나요?" 와 같은 다소 황당한 질문은 포함되지 않았다.
(2) 황당한 질문 추가

일단, instruction이 제일 처음에 오도록 하였다.
context는 그 뒤에 붙여 설명했다.
"임대인과 임차인이 서로 동갑이면 누가 우선권이 있는 건가요?"
🤣🤔😃🤔
이렇게 처음엔 웃기지만 생각할수록 궁금해지는 질문을 원했다.
그러나 이 답변에선 이러한 질문이 하나밖에 없어서 조금 아쉬운 느낌이 있었다.
(3) 질문의 조건 상세하게

'황당한' 질문에서 '황당하고 웃긴' 질문으로 조건을 추가하니 (2)보다 훨씬 다채로운 질문이 나왔다.
그러나 다른 문제가 생겼다.
나는 '진지한' 질문과 '황당하고 웃긴' 질문 1개씩 원하는데, 이렇게 뭉탱이로 주면 어떤 게 어떤 성격의 질문인지 알 수가 없었다.
(4) 답변의 개수 지정

질문(ChatGPT의 답변)의 개수를 지정하니까 원하는대로 결과가 나왔다 !
하지만 여전히 문제는 존재했다.
하루에 2개씩 올리는데 과연 중복 질문이 안 나올까?
이를 방지할 수 있는 조건이 필요했다.
(5) 중복 질문 방지

ChatGPT한테 보낼 수 있는 프롬프트에는 토큰 제한이 있었다.
그래서 DB에 있는 모든 질문을 보내지는 못 하고, DB에서 최근 질문 10개를 가져와 이 질문들과는 중복이 되지 않도록 하였다.
그러나 이번에도 문제는 존재했다.
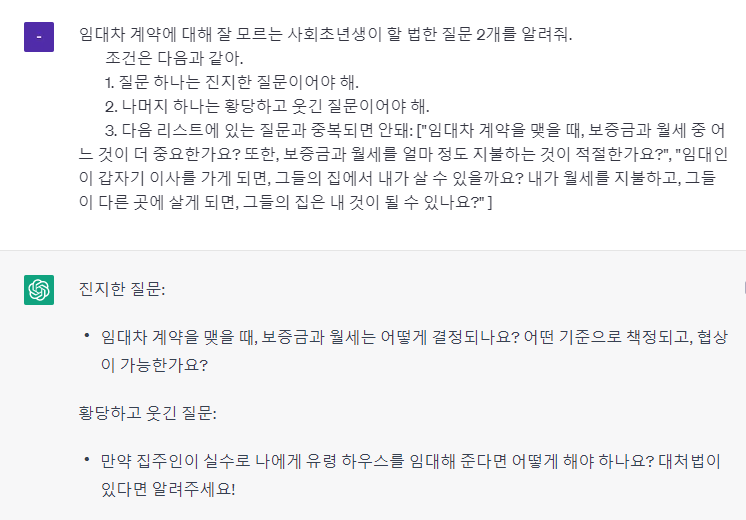


내가 보낸 프롬프트의 형식은 같았는데,
ChatGPT가 준 답변의 형식은 다 달랐다.
이 답변을 processing해서 DB에 저장해야 하는 입장에서는 답변의 형식이 통일될 필요가 있었다.
(6) 답변의 형식 지정

처음에는 지정한 형식대로 잘 응답해주는 거 같았다.
그러나 여러 번 테스트 해보니까 한 번은 이런 답을 받았다.
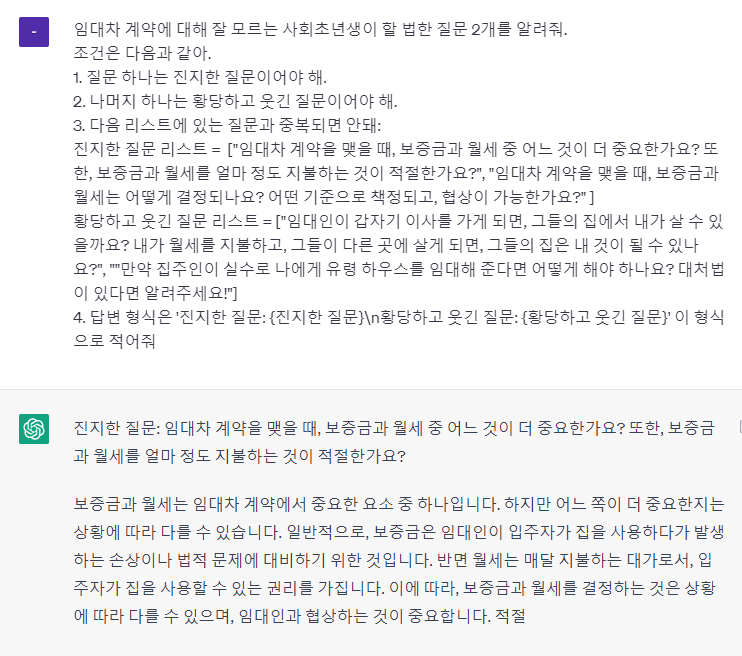
갑자기 의도와는 완전히 다른 답변이 나왔다.
조건이 너무 많은 거 같기도 하고, input의 토큰 제한도 있어서 이번에는 조건을 분리하였다.
(7) 조건 분리
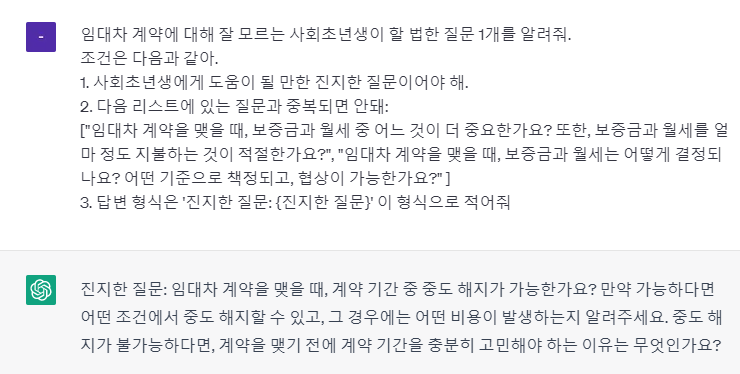

프롬프트를 이렇게 작성하니까,
내가 의도한 답변을 제공해주었고
답변의 형식도 통일되어 프로젝트에 적용할 수 있게 되었다 !
하지만 ..
문제는 여전히 존재했다 .. ^_^
저도 알고 싶지 않았어요 🥲
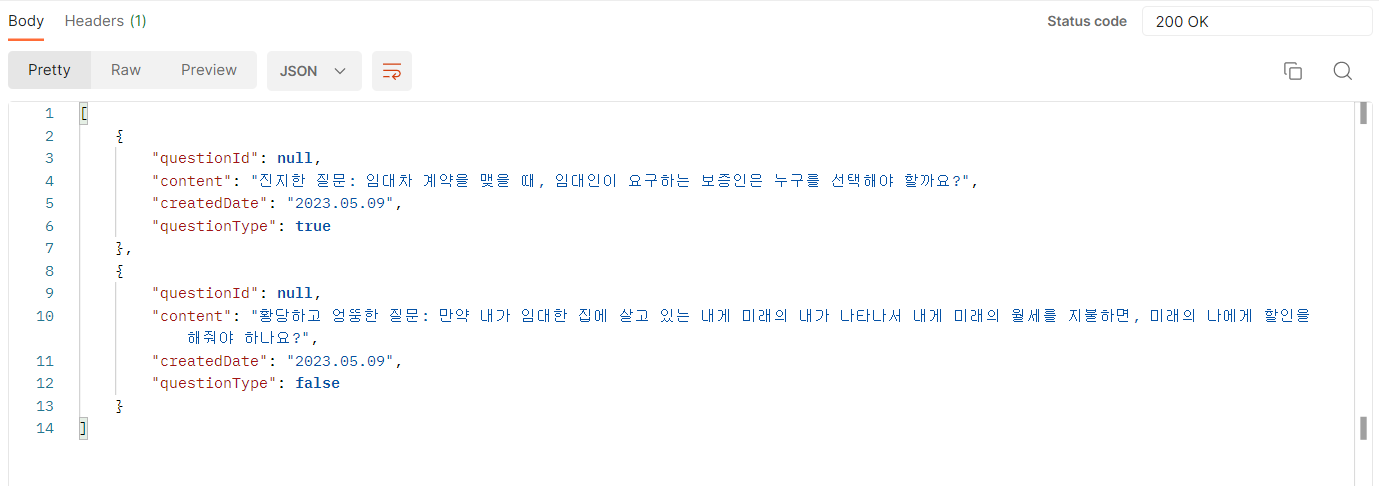


보이는가?
'진지한' 질문은 괜찮은데, '황당하고 엉뚱한' 질문이 문제였다.
분명 ChatGPT로 테스트 할 때는 괜찮았는데,
API상에서는 비슷한 성격의 질문만 나왔다.
그래서 조건을 '중복 금지' 에서 '비슷한 질문' 금지로 바꿨는데도 결과는 같았다.
(8) 예시 추가

예시를 넣으니까 API에서 봤던 질문과 비슷한 질문이 나오지는 않았다.
그러나 이번에 나온 질문들은 ..
황당하고 엉뚱한 질문을 원했지만 너 ~ 무 엉뚱했다.
"보증금도 할부가 되나요?"
이 질문은 아는 사람들한테는 말도 안 되는 웃긴 질문이지만,
아예 아무것도 모르는 사람한테는 궁금할 수도 있는 질문이다.
이러한 질문과 그에 따른 댓글을 통해 유저가 자연스럽게 지식을 습득할 수 있는 게 우리의 목표였다.
그러나,
"내가 월세 대신에 팬케이크를 제공하면 월세를 지불하지 않아도 되나요?"
이건 아무것도 모르는 사람이라도 확실하게 답할 수 있는 질문이다.
재미도 없고, 유익하지도 않다.
그래서 어떻게 하면 이 묘한 성격의 질문을 유지할 수 있을까 고민했고,
다음과 같은 방법을 도입했다.
(9) '키워드' 조건 추가

우리 프로젝트는 단어 사전에 사용할 부동산 용어 DB를 가지고 있었다.
약 300개의 부동산 관련 단어와 그 해설로 구성되어 있는 테이블이었다.
그래서 이 DB에서 부동산 단어를 하나 가져와 그걸 키워드로 설정하고,
이 키워드와 관련된 질문을 생성하면 지나치게 엉뚱한 질문은 나오지 않겠다고 생각했다.
그리고 ChatGPT가 준 질문 목록들이 꽤 괜찮아 이대로 진행하기로 결정했다.
(10) 최종 프롬프트

그래서 우리의 최종 프롬프트는 이렇게 구성되었다.
정리하자면,
조건은 총 3개로, 다음과 같다.
- 질문(ChatGPT의 답변)의 성격과 그 예시
- 부동산 키워드
- 답변 형식
"어? 근데 아까는 비슷한 질문을 제외한다는 조건이 있었는데 이번엔 없네요?"
이러한 의문이 들 수도 있다.
앞에서 말했다시피 우리가 가지고 있는 단어 데이터셋은 약 300개이다.
이 데이터셋에 랜덤 접근하여 키워드를 가지고 오는데, 데이터의 개수가 꽤 많아 중복 질문이 나올 확률이 현저히 적었다.
또한, 중복 질문을 제외하려면 DB에 접근해 질문 데이터를 가져오고 이걸 다시 프롬프트에 추가해야 했는데,
이렇게 하면 차이가 크지는 않지만 그래도 계속 DB에 접근해야 하기 때문에 이번 방법에 비해 성능이 떨어진다는 단점이 있었고,
어차피 프롬프트 input에 있어 토큰 제한이 존재해 몇 개의 질문만 조건에 포함시켜야 했는데 이 깔끔하지 못한 방식도 해결 되었다.
다음과 같이 결과는 괜찮았다.



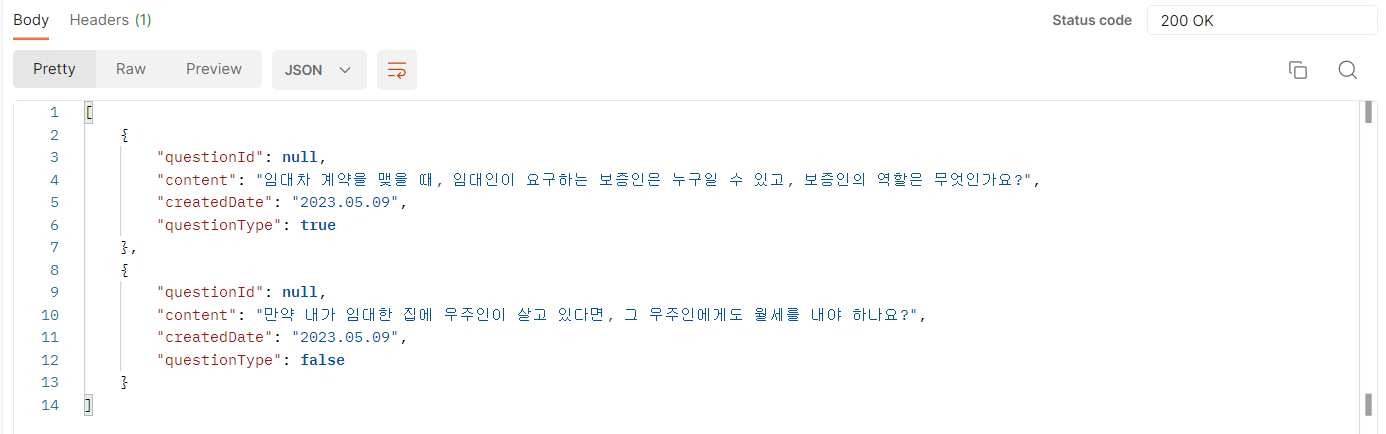
실제 API를 적용한 우리 프로젝트에서 생성된 질문은 다음과 같다.
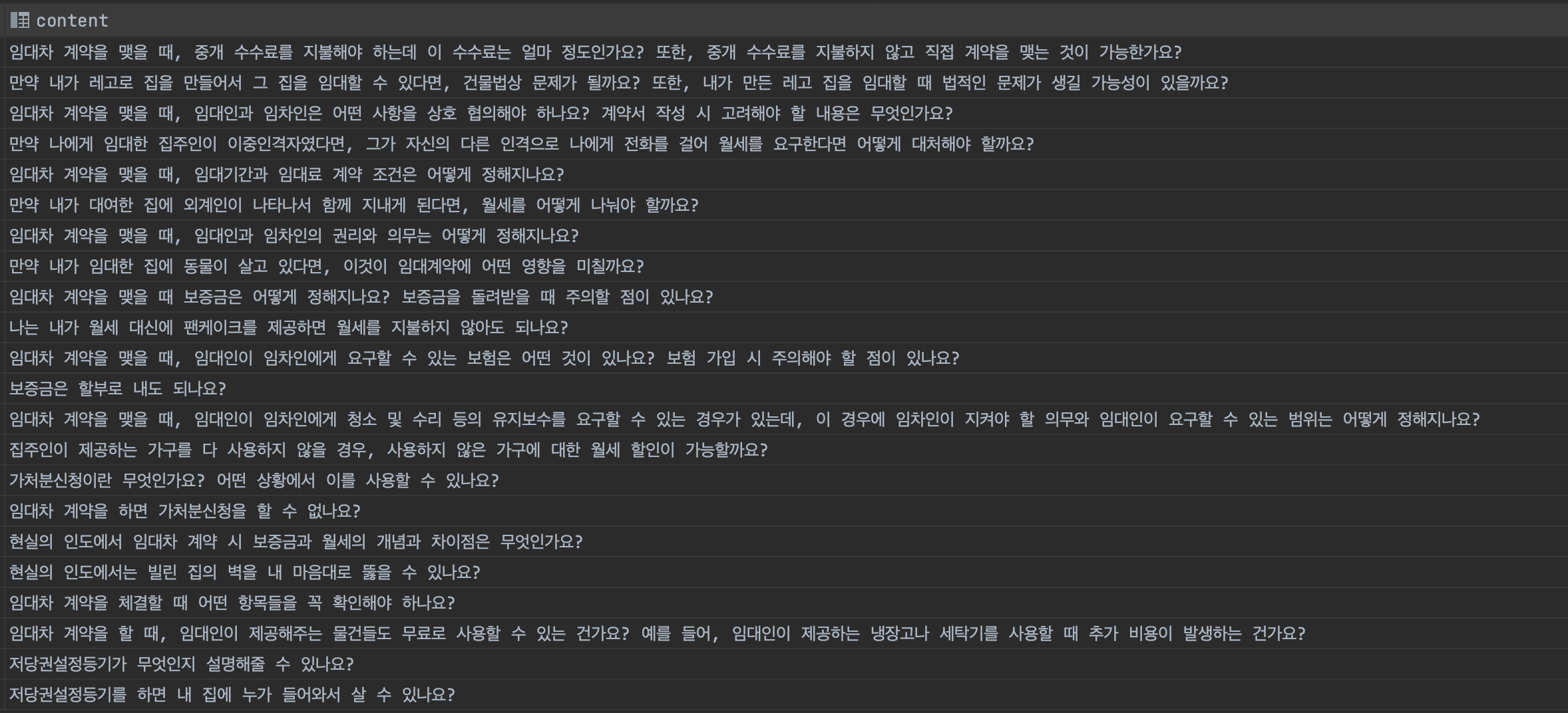
3. SpringBoot에서 ChatGPT API 사용하기
(1) OpenAI 회원가입
https://openai.com/
https://platform.openai.com/overview
위 사이트에 가입한다. (두 개는 같은 사이트)
참고로 ChatGPT 사용도 가입이 필수다 !
(2) API 키 발급 받기
View API keys 에 들어간다.
Create new secret key 를 통해 API를 발급 받는다.
내가 "Midubang"에서 쓰는 key는 이미 발급 되어있다.
🚨 이 때 API 키 관리를 진짜 조심해서 해야 한다.
OpenAI API는 무료가 아니다!
일정 금액까지는 무료로 사용하게 해주지만, 그 이상부터는 결제해야 쓸 수 있다.
넉넉하게 지원해주기 때문에 대다수의 사람들이 편하게 이용하고 있지만,
API 키가 털리면 어느 순간 AWS처럼 과금이 되거나 더이상 키를 사용하지 못 할 수 있기 때문에 .gitignore 등을 통해 특히 Github에서 노출되지 않도록 해야 한다.
(3) application-secret.yml
openai:
model: gpt-3.5-turbo
api:
url: https://api.openai.com/v1/chat/completions
key: {발급 받은 API key}우리 프로젝트에서는 application-secret.yml 파일을 따로 만들어 Github에 노출되지 않게 했다.
모델은 아까 언급했듯 gpt-3.5-turbo 를 사용했다.
(4) DTO
[Message]
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Message {
private String role;
private String content;
}[ChatRequest]
@Data
public class ChatRequest {
private String model;
private List<Message> messages;
private int n;
private double temperature;
public ChatRequest(String model, String prompt) {
this.model = model;
this.messages = new ArrayList<>();
this.messages.add(new Message("user", prompt));
this.n = 1;
this.temperature = 0.5;
}
}[ChatResponse]
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ChatResponse {
private List<Choice> choices;
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Choice {
private int index;
private Message message;
}
}(4) Service
@Service
@Slf4j
@RequiredArgsConstructor
public class CommunityService {
@Value("${openai.model}")
private String model;
@Value("${openai.api.url}")
private String apiUrl;
@Value("${openai.api.key}")
private String openaiApiKey;
private HttpEntity<ChatRequest> getHttpEntity(ChatRequest chatRequest) {
HttpHeaders headers = new HttpHeaders();
headers.set("Content-Type", "application/json");
headers.set("Authorization", "Bearer " + openaiApiKey);
HttpEntity<ChatRequest> httpRequest = new HttpEntity<>(chatRequest, headers);
return httpRequest;
}
@Scheduled(cron = "0 0 6 * * *", zone = "Asia/Seoul")
public void getDailyQuestions() {
List<Question> newQuestionList = new ArrayList<>();
Random random = new Random();
random.setSeed(System.currentTimeMillis());
Long randomNum = Long.valueOf(random.nextInt(308) + 1);
String randomWord = wordRepository.findWordById(randomNum).getWord();
String query1 = "임대차 계약에 대해 잘 모르는 사회초년생이 할 법한 질문 1개를 알려줘.";
query1 += "\n질문의 조건은 다음과 같아.";
query1 += "\n1.사회초년생에게 도움이 될 수 있을만한 진지한 질문이어야 해.";
query1 += "\n2.다음 키워드와 관련된 질문이어야 돼: ";
query1 += randomWord;
query1 += "\n3.답변 형식은 '진지한 질문: {진지한 질문}' 이 형식으로 적어줘";
// Create a request
ChatRequest request1 = new ChatRequest(model, query1);
// Call the API
RestTemplate restTemplate1 = new RestTemplate();
ChatResponse response1 = restTemplate1.postForObject(apiUrl, getHttpEntity(request1), ChatResponse.class);
if (response1 == null || response1.getChoices() == null || response1.getChoices().isEmpty()) {
throw new RuntimeException();
}
String trueQuestion = response1.getChoices().get(0).getMessage().getContent().substring(8);
Question newQuestion1 = new Question(trueQuestion, getCurrentDate(), Boolean.TRUE, null);
newQuestionList.add(newQuestion1);
//
String query2 = "임대차 계약에 대해 잘 모르는 사회초년생이 할 법한 질문 1개를 알려줘.";
query2 += "\n조건은 다음과 같아.";
query2 += "\n1.다소 황당하고 엉뚱한 질문이어야 해. ex) 보증금도 할부가 되나요?";
query2 += "\n2.다음 키워드와 관련된 질문이어야 돼: ";
query2 += randomWord;
query2 += "\n3.답변 형식은 '황당하고 엉뚱한 질문: {황당하고 엉뚱한 질문}' 이 형식으로 적어줘";
ChatRequest request2 = new ChatRequest(model, query2);
RestTemplate restTemplate2 = new RestTemplate();
ChatResponse response2 = restTemplate2.postForObject(apiUrl, getHttpEntity(request2), ChatResponse.class);
if (response2 == null || response2.getChoices() == null || response2.getChoices().isEmpty()) {
throw new RuntimeException();
}
String falseQuestion = response2.getChoices().get(0).getMessage().getContent().substring(13);
Question newQuestion2 = new Question(falseQuestion, getCurrentDate(), Boolean.FALSE, null);
newQuestionList.add(newQuestion2);
questionRepository.saveAll(newQuestionList);
}
}
코드의 길이가 길어 ChatGPT API 관련 로직만 작성했다.
우리 프로젝트에서는 클라이언트단에서 호출하는 건 없고,
그냥 매일 아침 6시에 질문 2개만 올리면 되기 때문에
따로 Controller단은 구현하지 않았다.
대신 @Scheduled(cron = "0 0 6 * * ", zone = "Asia/Seoul")를 통해 자동으로 매일 아침 6시에 로직이 실행되도록 하였다.
만약 API 호출을 해야하면 상황에 맞게 Controller를 구현하면 된다.
[참고]
https://seongjin.me/prompt-engineering-in-chatgpt/
https://tech.kakaoenterprise.com/188
https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api

Está à procura de uma forma fácil de comunicar em Português? Não procure mais do que https://gptportugues.com/ e o nosso fantástico ChatGPT Português. Com a nossa interface avançada e intuitiva do ChatGPT, não precisa de passar horas a criar contas ou a comprar tokens. Tudo o que precisa de fazer é entrar no nosso site e pode ter acesso instantâneo à mais recente aplicação ChatGPT.
O ChatGPT Português fornece-lhe uma plataforma poderosa para interagir em Português com apenas alguns cliques do rato. Usando o processamento de linguagem natural, pode escrever mensagens, fazer perguntas e até participar em conversas no idioma. Para além disso, é tudo gratuito e ilimitado!