CS224W- 8강 GNN application 내용 정리
실제 industry에서의 GNN 응용 관점을 정리한 강의 내용
GNN Prediction
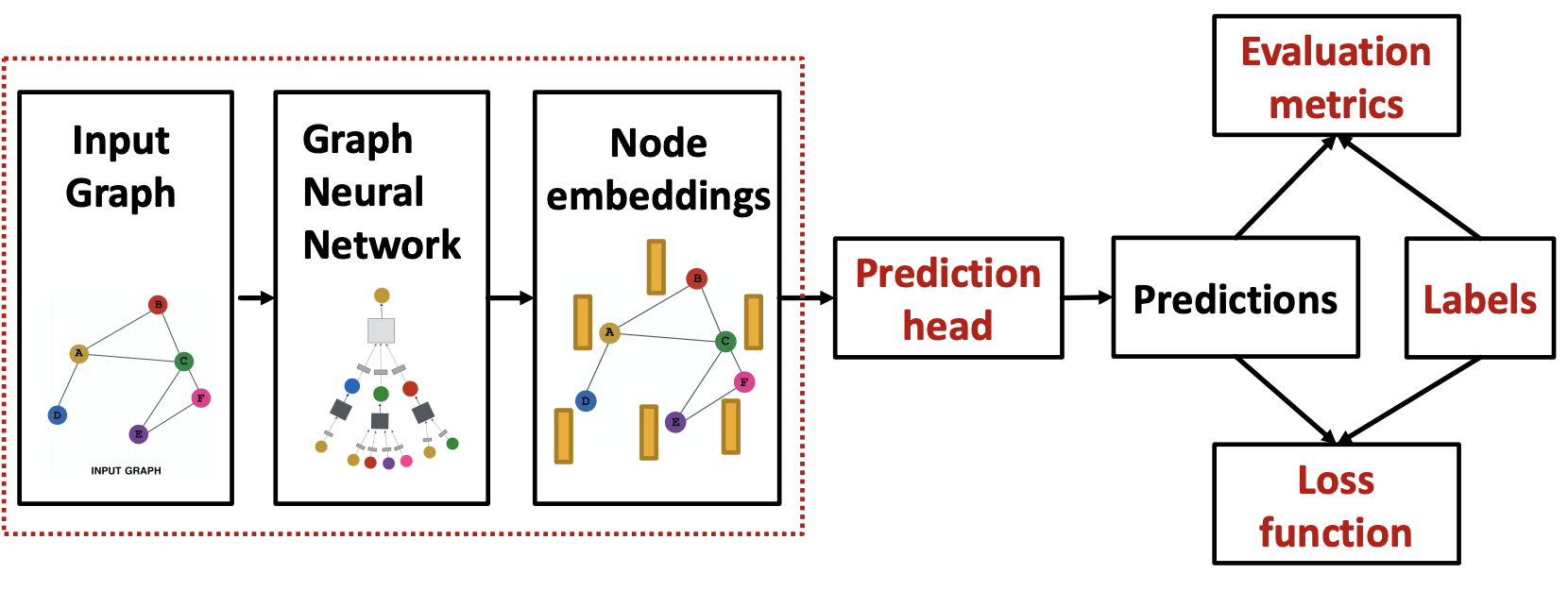
Node level predction
Edge level prediction
-
u,v가 연결되어 있는지 두 가지 방법중 하나를 씀
1)
2) → 1-way 버전
k-way 버전은 multi-head attention 사용
Graph level prediction
-
Head는 max, mean, sum이 될 수 있음(좀 무식한듯?)
Hierachically하게 node 조합을 나눠 sum 하는 방식도 있음(Diffpool)
graph의 signal 종류
- supervised signals
- 그래프 외부의 라벨 정보
- unsupervised signals
- 그래프 안에서 찾을수 있는 정보(ex. link 연결 정보)
- self-supervision → unsupervision learning 에서 supervised learning을 하는 느낌
- 강의 advice로는 node, edge, graph level의 문제에서 좀 더 작은 단위를 먼저 접근하는 것을 추천 → node를 알면 graph에 대해 유추 가능하니
self-supervision 의 예측 요소( 외부 라벨없이)
1) node level : 노드 통계량(클러스터 계수, Pagerank)
2) edge level : link prediction(일부러 일부 노드 숨김)
3) graph level : 그래프 통계량( 두 그래프가 동형인가?)
Setting-up GNN Prediction tasks
Q. train/test/validation set 을 어떻게 나눌까?
random sampling X → 다른 데이터와 달리 샘플끼리 독립적이지 않음(message Passing으로 인해 영향을 미침)
- Transductive Setting
- Input 그래프를 전체 사용하고 node label만 split해서 사용
- tran/test/valid on same graph
- entire graph 모두 관측 가능(label 정보만 쪼개짐)
- node/edge prediction에만 적용가능

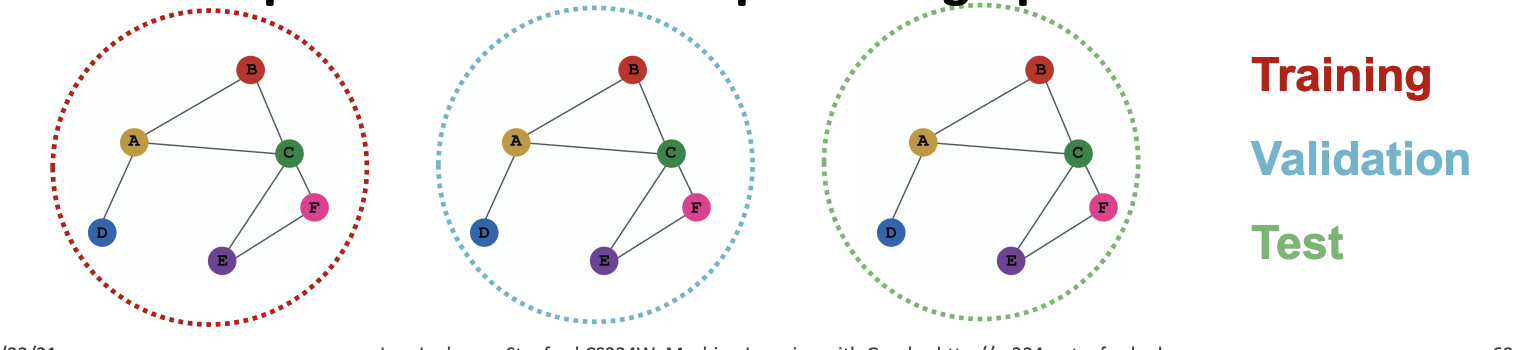
2. Inductive Setting
- 그래프를 쪼개서 일부는 training 일부는 valid 로 사용
- train/test/valid set on different graph
- multiple 그래프 dataset 사용해야함
- node/edge/graph task 모두 가능
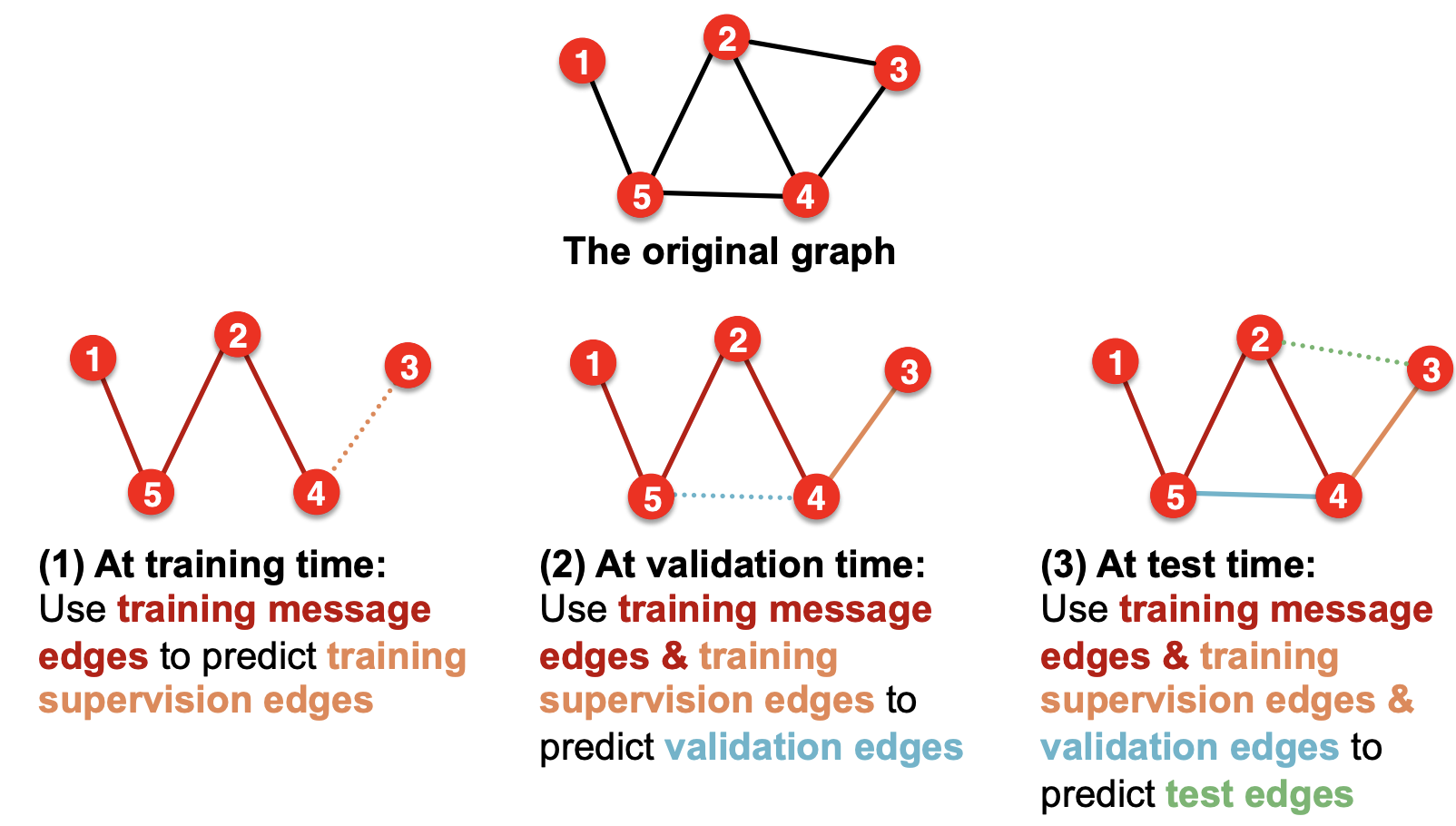
Setting up link prediction
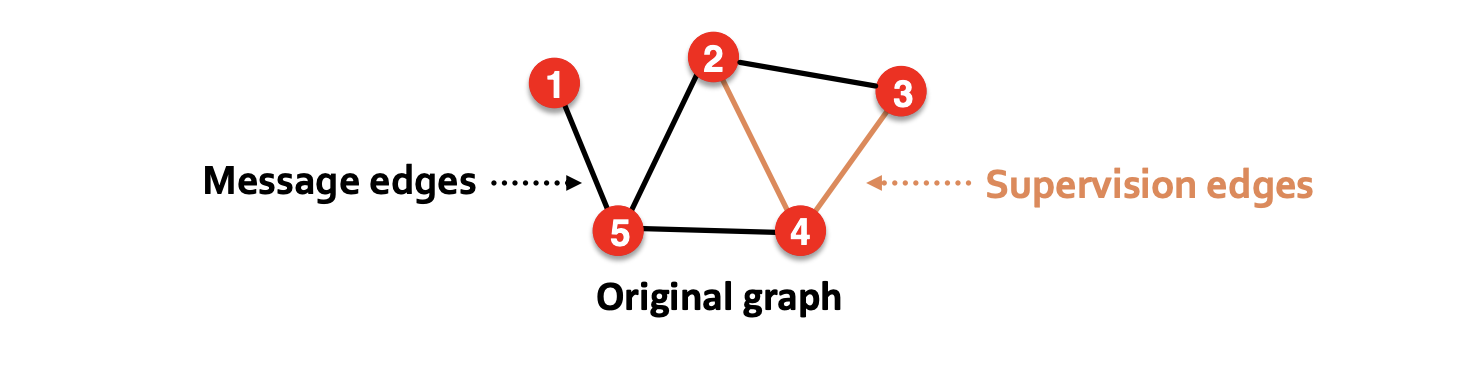
1) 2타입의 edges를 정의
2) train/test/valid split
trainsductive method와 inductive method가 조금 다름
- inductive split
- 독립 적인 3개의 그래프 안에서 message/supervision edge를 나눔
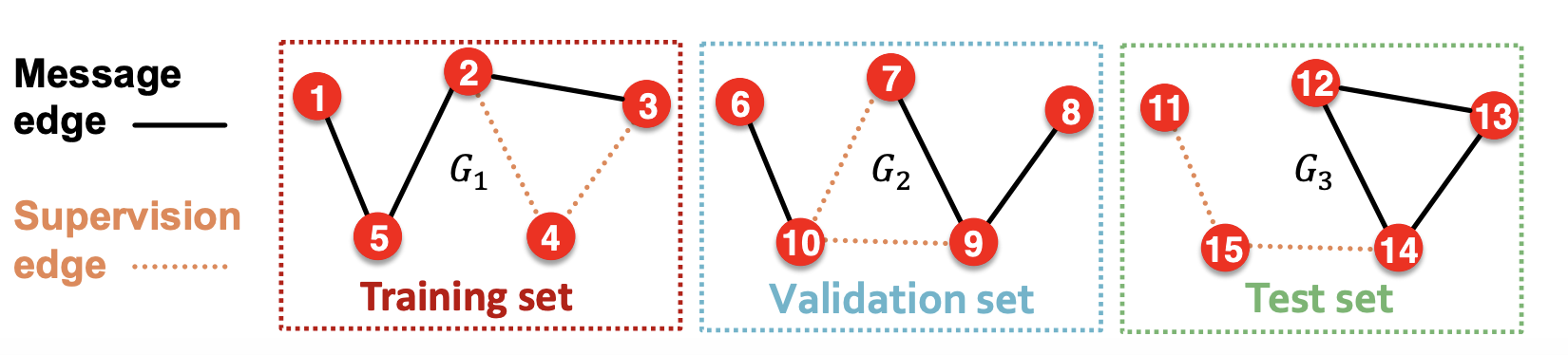
2.transductive split(link prediction task의 default 세팅임)
- 여러 edge type을 추가한 이유는 training 이후에 supervision edge는 알 수 있게 되므로 message passing에 사용되어야 함.
- 원래 링크 예측 세팅이 tricky하고 복잡하니 다른 paper도 참고하길 권장