Algorithm
1.BOJ 1759 암호 만들기 [Java]
문제 BOJ 1759보통 사용자의 입력에 따라 길이가 정해지는 문제는 재귀를 활용하는 경우가 많음그래서 BFS로 접근사전식이라고 언급되었기 때문에 정렬을 먼저 생각모든 경우의 수를 방문해야 할 것 같기는 하지만, 사전식이라는 점에서 중간중간 탈출을 꾀할 수 있을 것 같
2.BOJ 1713 후보 추천하기 [Java]
BOJ 1713 후보 추천하기조건이 많은 문제가 오히려 쉬울 때가 많다조건 따라가면서 경우의 수 전개ArrayList 정렬 활용여러 조건으로 정렬을 여러번 할 때, 마지막 정렬기준이 첫번째 분기 기준
3.BOJ 3055 탈출 [Java]
문제 BOJ 3055 탈출 접근 방법 DFS는 동시에 하나 씩 이동하는 것을 처리할 수 없음 BFS는 DFS로 해결한 문제를 모두 풀 수 있지만 DFS는 아니다. 결론 : 이 문제는 BFS이다... 구현 제출
4.BOJ 1806 부분합 [Java]
BOJ 1806 부분합슬라이드 윈도우, 투포인터 개념을 알고 있다면 크게 어렵지 않을 줄 알았는데 break 조건에서 애를 먹었다.else if일 때는 맞고, if로 넣으면 틀리다. 생각할 때 어쩌면 if가 더 맞다고 생각했는데 아주 어렴풋이 end는 커지더라도, st
5.BOJ 1806 수들의 합 2 [Java]
BOJ 1806 수들의 합 2BOJ 1806 부분합 과 매우 유사슬라이딩 윈도우, 투포인터로 해결하는 문제 else if (end == N) break; 에 한 번 데였더니,, 이제는 쉽게 구현한다.
6.BOJ 2143 두 배열의 합 [Java]
BOJ 2143 두 배열의 합부배열과 투포인터 활용전체 부배열을 담는 List가 필요아래는 부배열 생성할 때 직접^~^ 그린 그림이다. 행색이 초라해도 용이하게 쓰였다.시간복잡도를 Big-O 표기법으로 나타내면 사실 부배열 생성 시 O(N^2) 이지만, 이 문제의 쟁점
7.BOJ 2805 나무 자르기 [Java]
BOJ 2805 나무 자르기이진탐색 문제이다기준을 정하는 것만 해결하면 쉽다.
8.BOJ 1202 보석 도둑 [Java]
BOJ 1202 보석 도둑욕심쟁이 알고리즘이다조건에 만족하는 것 중에 가장 큰 것을 고르는 방법으로 하면 최적의 답이 나온다.알고리즘 자체가 어렵지는 않은데 정렬에 대해 명확히 알고 있어야 할 것 같다.
9.BOJ 2042 구간 합 구하기 [Java]
BOJ 2042 구간 합 구하기\\음 내가 느끼기에는 이 문제는 자료구조 쪽의 스택, 큐 스탠다드 문제처러 인덱스트리에 대한 기본적인 문제인 것 같다.인덱스 트리(세그먼트 트리)가 처음에는 되게 낯설게 느껴졌었는데 조금씩 해보니까 오히려 편하다는 생각이 가끔 들 정도이
10.BOJ 1717 집합의 표현 [Java]
BOJ 1717 집합의 표현 그래프 이론에서 가장 기본 함수인 find(), union() 학습 유무를 묻는 문제고려할 점이 find()가 재귀함수인데, 할당도 동시에 해줘야 메모리소모 및 시간이 훠얼씬 줄어든다.
11.BOJ 2252 줄 세우기 [Java]
BOJ 2252 줄 세우기위상정렬의 대표적인 문제이다.진입차수라는 개념을 알면 쉽다.이 문제에서의 진입차수 : 자신을 가르키는 화살표의 개수 (자신보다 작다고 판별된 사람 수)n^2 크기의 정수형 배열을 만들어서 화살표 정보를 넣으려고 했지만 처음에는 메모리 초과가 떴
12.BOJ 1753 최단경로 [Java]

가장 기본적인 다익스트라 알고리즘 문제이다.사람마다 표현 방법이 조금씩 다르니 자기가 이해하기 쉽게 코딩하면 맞는다단계별로 진행이 되니, 다익스트라 알고리즘 자체를 모른다면 유튜브 영상 검색 추천제출
13.BOJ 1932 정수 삼각형 [Java]
BOJ 1932 정수 삼각형아주 쉬운 dp 문제이다.점화식이랑 index 조건만 살피면 직과적으로 금방 풀리는 문제
14.BOJ 10868 최솟값 [Java]

BOJ 10868 최솟값인덱스 트리 (세그먼트 트리)의 가장 기본적인 형태에서 연산 형식만 바뀐 문제이다.구간 합이 아닌 구간 최솟값!나머진 다 똑같당
15.BOJ 3425 고스택 [Java]

BOJ 3425 고스택어려운 풀이방법보다는 구현의 완성도에 좌우되는 문제에러 조건 하나씩 대조하기개인적으로 do-while문 보다 while(true)에서 적당한 탈출조건 명시가 더 직관적(명령어 10개 작성하는 거 약간 노가다)
16.BOJ 10828 스택 [Java]

BOJ 10828 스택스택 기본 문제스택에 대해 알고있고, java의 stack의 메서드들 활용하면 쉽게 풀이
17.BOJ 11050 이항계수 [Java]
재귀 팩토리얼로 가장 기본적으로 잘 풀린다.유의 및 이 게시글을 쓴 이유) 반복으로도 풀려고 하였는데, 계속 채점 결과가 오답이 나왔다. 그 이유는 K가 0인 경우를 고려하지 않아서이다..... 조심하자!
18.BOJ 11051 이항 계수2 [Java]

처음에 재귀나 반복으로 풀었을 때는 시간초과가 난다.그래서 아래 그림과 같이 이항계수를 다시 이해하고, 동적 계획법으로 풀이하였다.(출처 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogI
19.[프로그래머스] 문자열 압축 JAVA
문제 링크엄청 어려운 문제풀이였다기보다는, 문제 전개를 이해한다면 큰 챌린지는 없다아래와 같이 풀었는데, 보시다시피 한 범위 보다 작은 마지막 부분은 임의로 붙였다그런데 다른 분의 풀이를 보니 애초에 마지막 부분까지 반복문을 통해 붙이는 인덱스 오류가 나지 않기 위해
20.[프로그래머스] 추석 트래픽 JAVA

문제링크처음에는 dp, 그 다음에는 슬라이딩 윈도우로 풀어보려고 했지만 공간적, 시간적 복잡도가 문제 출제자께 죄송할 정도로 터무니 없을 것 같아 아니라고 판단하였다.그리고 한참 고민하다가, 임계값을 이용하라는 힌트를 가지고 아래와 같이 풀이하였다.정답을 확인하고 다른
21.[프로그래머스] 로또의 최고 순위와 최저 순위 JAVA

문제링크쉬운 문제이다.최고, 최저를 마지막에 다시 순위로 바꾸는 대신 시작점을 둘 다 7, 7로 잡아서 자연스레 순위로 보이도록 하였다.스트림 활용하였다.
22.[프로그래머스] 오픈채팅방 JAVA
문제링크평이한 난이도였다. 키-값 형태를 사용하는 HashMap을 쓴다면 매우 유용하게 쓰이는 문제이다.굳이 Log라는 클래스까지 만들 필요는 없었던 것 같기두
23.[프로그래머스] 신규아이디추천 JAVA
문제링크문자열에 대해 이것저것 연산해보는 문제이다.정규식을 이용해서 풀이하면 매우 간단하다if문보다 삼항연산이 더 시간이 짧기 때문에 간단한 조건은 최대한 삼항연산자를 쓰려고 하는데 오히려 가독성이 떨어진 것 같기도 하다
24.[프로그래머스] N으로 표현 JAVA

문제링크재귀 구현은 항상 조금씩 애를 먹는 것 같다.사칙연산의 모든 경우의 수를 탐색한다고 생각하면 구조를 이해하기 쉬워지다.
25.[프로그래머스] 양궁대회 JAVA

문제링크우선 문제에서 주어진 값들의 최대 크기가 11 안팍으로 작다. 그래서 완전탐색임을 유추하였다.완전탐색 및 중복조합을 dfs로 구현하였고 주어진 보기 4개도 모두 올바르게 출력하였다.불필요한 탐색은 최대한 없애자!예를 들어 for (int i = point; i
26.[프로그래머스] 카카오프렌즈 컬러링북 JAVA
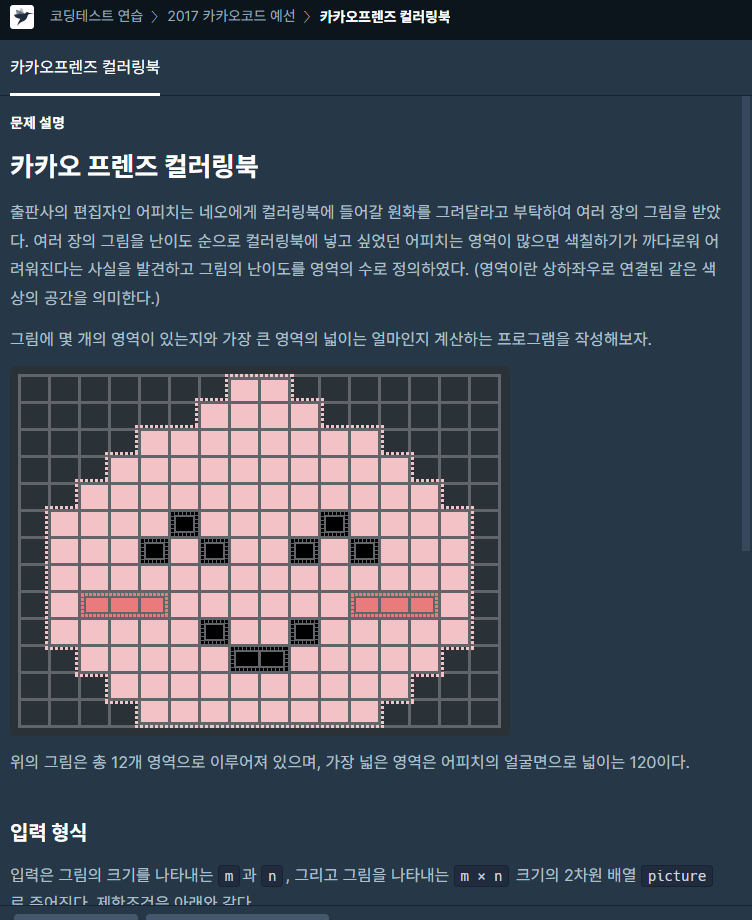
문제링크dfs의 대표적인 문제인 것 같았다.순간적으로 착각을 한 게, 각 색깔별로 방문 여부를 판단해야 하나 고민한 것이다.결론적으로 방문을 했다는 건 다른 색이라는 뜻으로 하나의 방문 배열로 판단하면 되었다.
27.[프로그래머스] 숫자 문자열과 영단어 JAVA
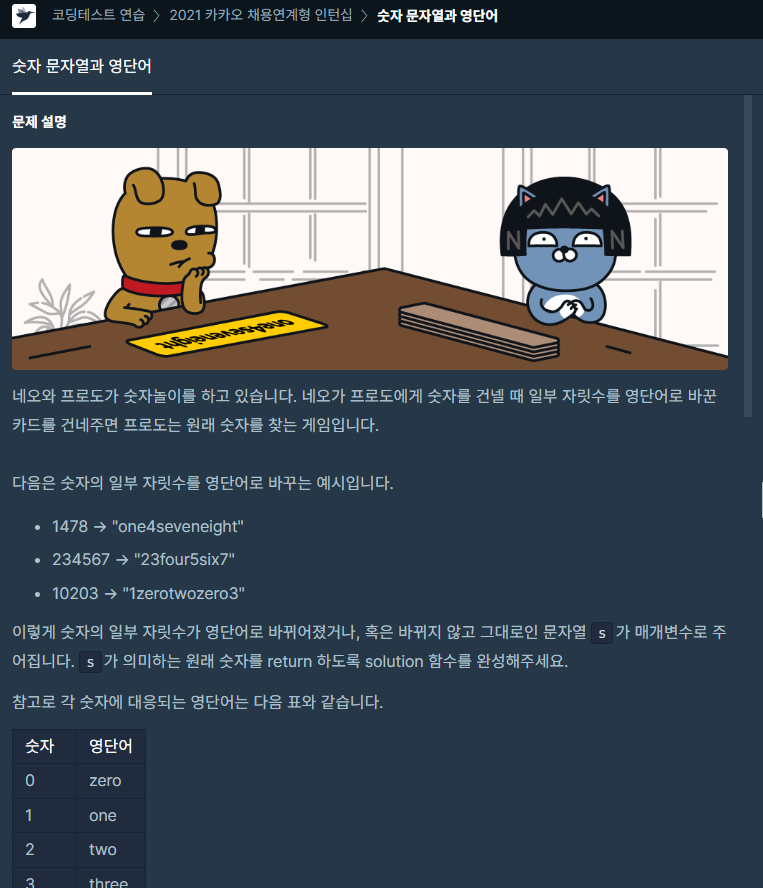
문제 접근 매우 쉬운 문제이다. replace라는 문법과 인덱스를 이용하는 아이디어로 쉽게 풀었다. 소스 코드
28.[프로그래머스] 가장 먼 노드 JAVA
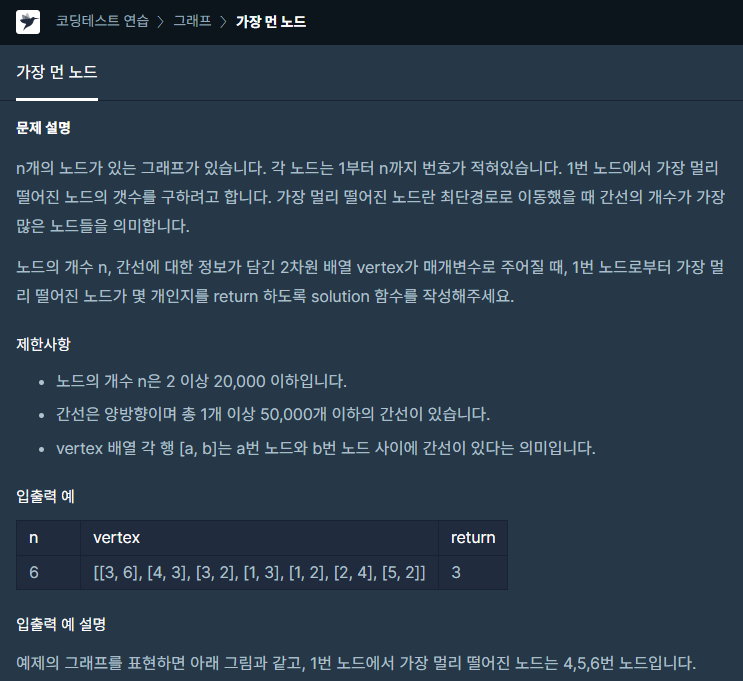
문제링크다익스트라 형태로 풀이하였다.20분 컷인줄 알았는데... Queue의 자료형을 LinkedList이 아닌 PriorityQueue를 아무 생각 없이 쓴게 삽질 원인ㅜㅜ이었다.개인적으로 정점의 개수는 정해져있기 때문에 이중 ArrayList가 아닌 ArrayLis
29.[프로그래머스] 키패드 누르기 JAVA
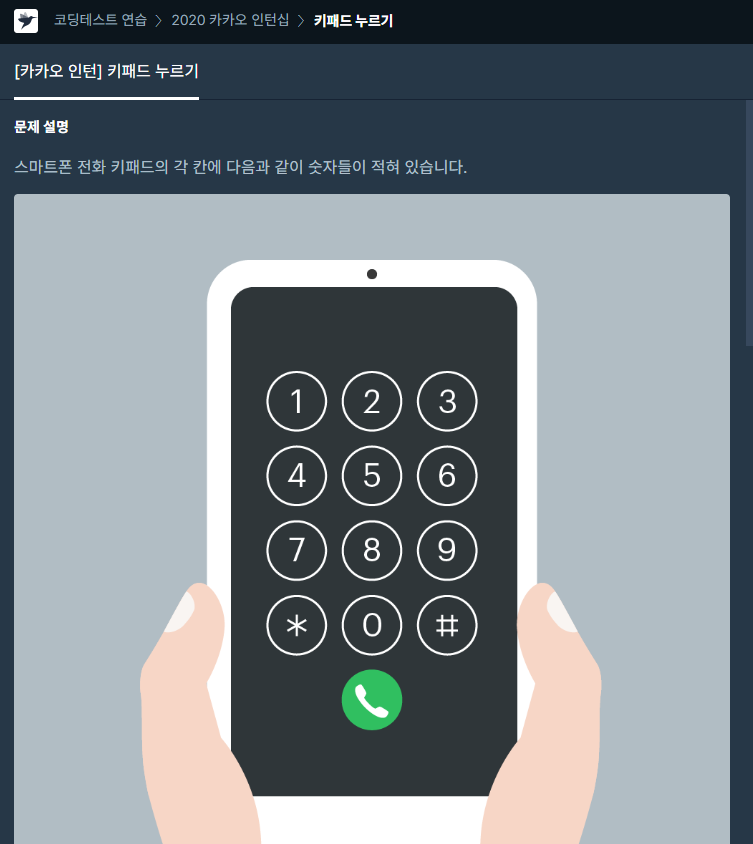
문제링크키패드의 숫자를 3으로 나누거나, 그 나머지를 통해서 좌표라고 인식하면 된다.조금 더 간략하게 코드를 작성할 수 있는 방법은, 오른손은 1,4,7에 절대 안 가기 때문에 나머지 연산을 할 때 따로 분기하기 보다 오른손에 한정지어 -1을 한 뒤 연산을 해도 무방하
30.[프로그래머스] 완주하지 못한 선수 JAVA

문제링크처음에 단순하게 contains 메서드를 활용하여 탐색하였지만, 이는 사실상 루프를 하나 더 사용하는 것이었기 때문에 효율성에 0점을 맞았다ㅜㅜ그래서 정렬을 한 뒤, 같은 인덱스끼리 비교하여 빠진 선수의 이름을 탐색하는 방법을 생각해냈다.
31.[프로그래머스] 멀쩡한 사각형 JAVA
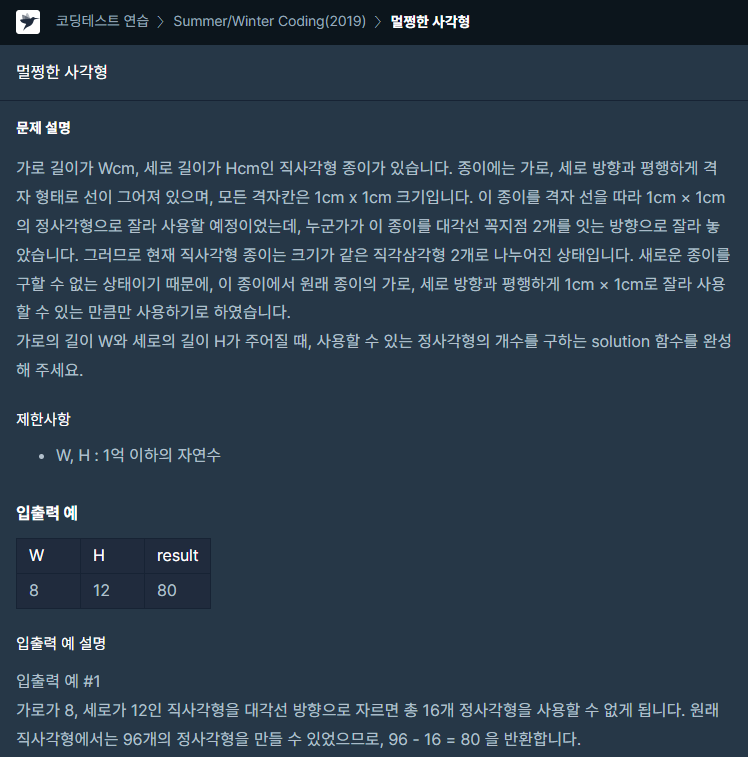
문제링크업로드중..그림을 계속 보다가 저런 모양이 계속 반복되는 것을 보고 최대공약수를 생각해내었다.자료형 유의하기
32.[프로그래머스] 스킬트리 JAVA
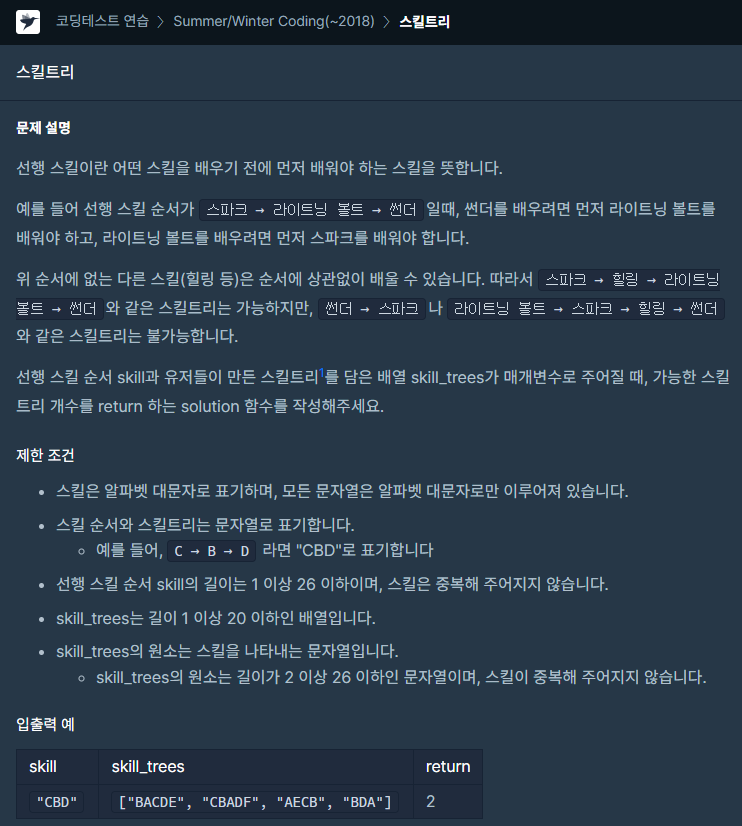
문제링크보자마자 정규식으로 문자열 정리 후, 그 결과로 비교해야 한다고 생각했다필요 없는 글자를 제외하고는 순서대로 같아야 하니, 같은 인덱스로 구분하였다.
33.[프로그래머스] 크레인 인형뽑기 게임 JAVA
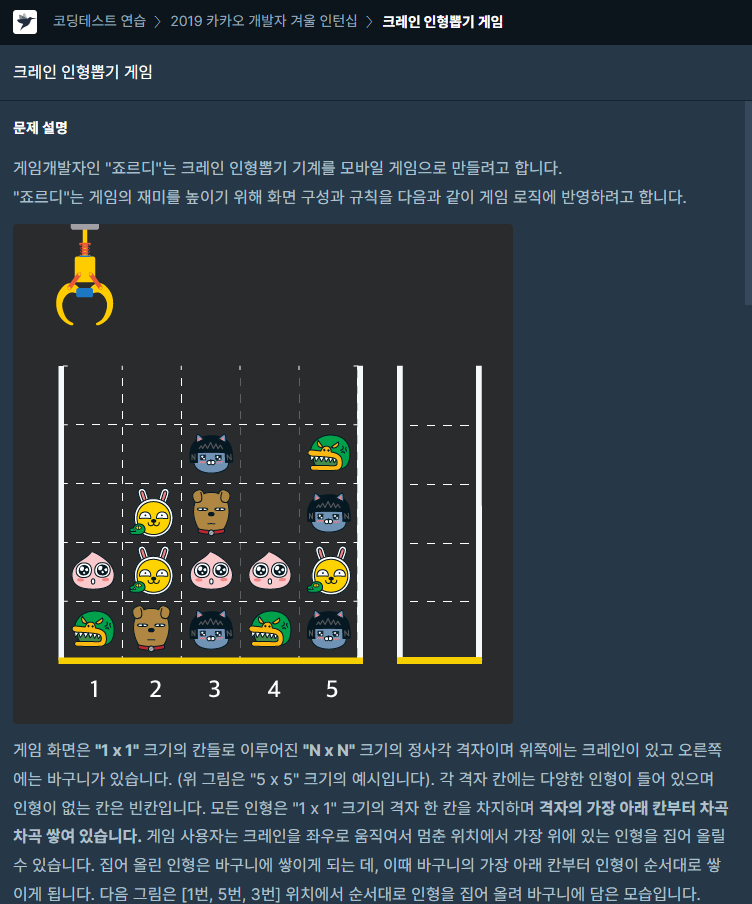
문제링크2차원 배열에서 인덱스를 활용하여 접근하는 것만 가능하다면 평이한 수준의 문제스택 간단 활용
34.[프로그래머스] 최소 직사각형 JAVA

문제링크간단한 완전탐색 문제이다.가로로 눕힐지, 세로로 눕힐지 정해야하는데, 작은 쪽은 작은 쪽끼리, 긴 쪽은 긴 쪽끼리 나열하여 이에 맞는 크기를 탐색한다.
35.[프로그래머스] 124나라의 숫자 JAVA

문제링크우선 3으로 나눈 몫과 나머지를 통해 코드를 작성하였는데, 3진법이라는 용어가 가장 걸맞는 것 같다.조건이 조금씩 헷갈렸지만 평이한 수준이었다.
36.[프로그래머스] 없는 숫자 더하기 JAVA
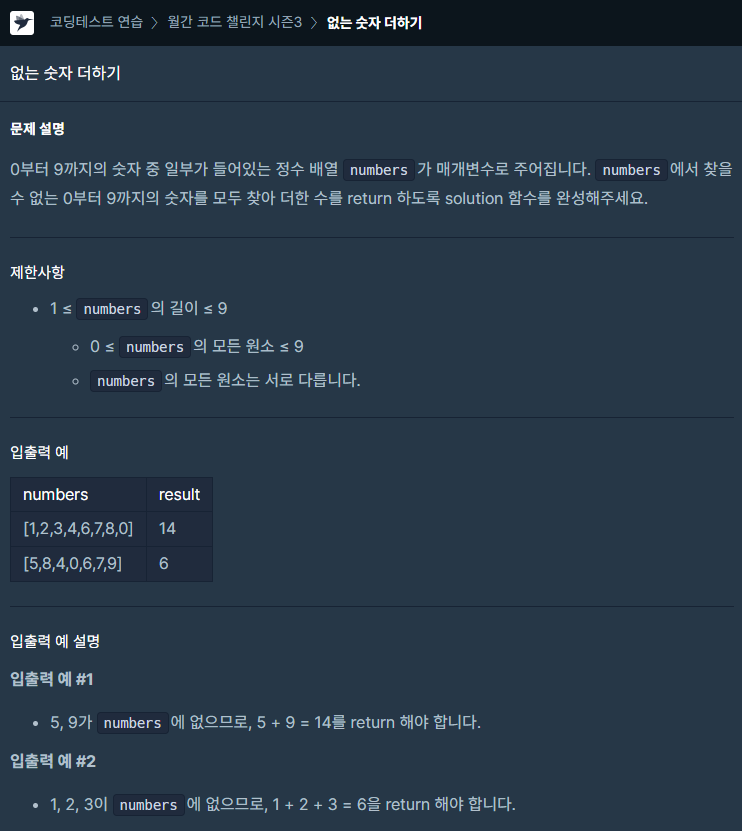
문제링크투 포인터 문제라는 생각을 가장 먼저했다.정렬 후 배열을 사용하면 논리가 훨씬 쉽다.배열 인덱스 관련 조건을 항상 살피자
37.[프로그래머스] 두 큐 합 같게 만들기 JAVA

문제링크처음에 엄청난 탐색 알고리즘이 있을 것 같았지만, 막상 풀어보니 순서대로 값을 넣고 빼며 비교하며 답을 찾으면 되는 문제였다.큐에 대한 이해가 기반이 되어야 한다.계속 1번 테케가 실패라고 뜨길래 다른 사람의 글을 참고하였는데, 2배가 아닌 3배로 하면 해결이
38.[프로그래머스] 주차 요금 계산 JAVA
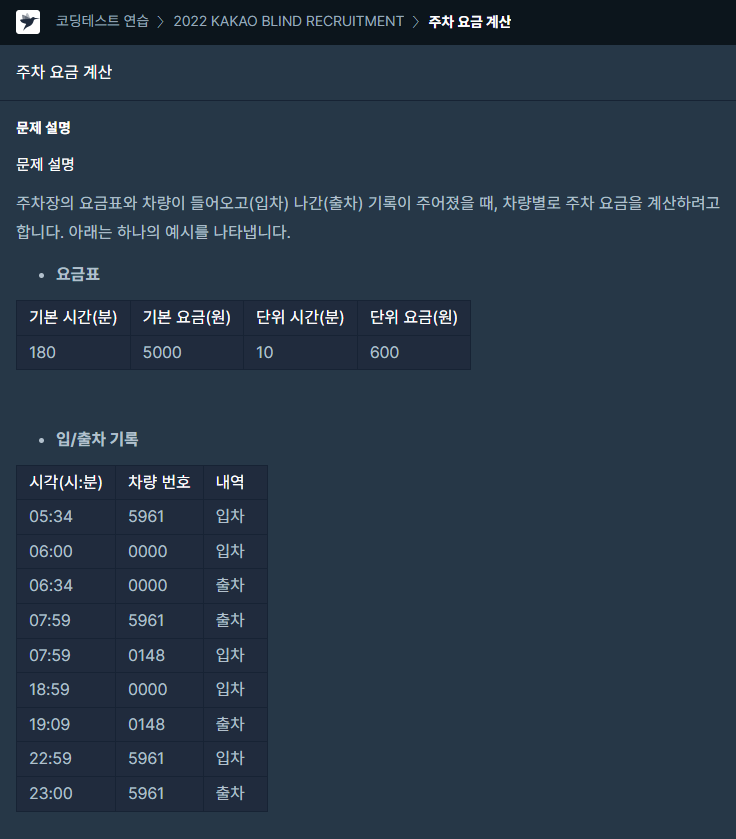
문제링크(https://school.programmers.co.kr/learn/courses/30/lessons/92341Hashmap을 통하여 키-값을 통한 여러 가지 연산을 통해 구현하였다.테케도 통과하였는데, 일부 문제들에서 런타임 오류가 생겼다.이를 질
39.[프로그래머스] 더 맵게 JAVA
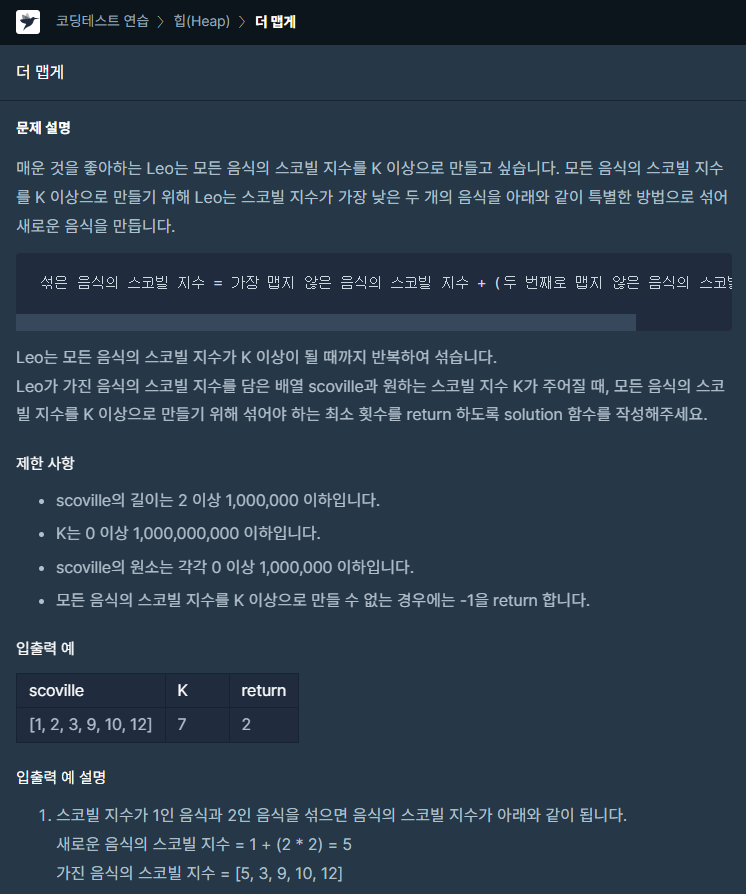
문제링크우선순위큐를 떠올렸다면 거의 해결되는 문제이다.반복문에서 적당히 연산 후 큐에 넣고 등을 반복하는 로직이 그렇게 어렵지 않게 만들어진다.
40.[프로그래머스] k진수에서 소수 개수 구하기 JAVA

문제링크순차적으로 진법 변환 - split - 소수 판별을 구현하면 된다.모두 구현하고 채점을 하였는데, 1번 11번 테케에서 런타임오류가 났다. 이는 소수 판별 과정에서 int를 long으로 바꾸었더니 해결되었다.그 다음은 1번에서 시간초과가 났는데, 이는 소수 판별
41.[프로그래머스] 정수삼각형 JAVA
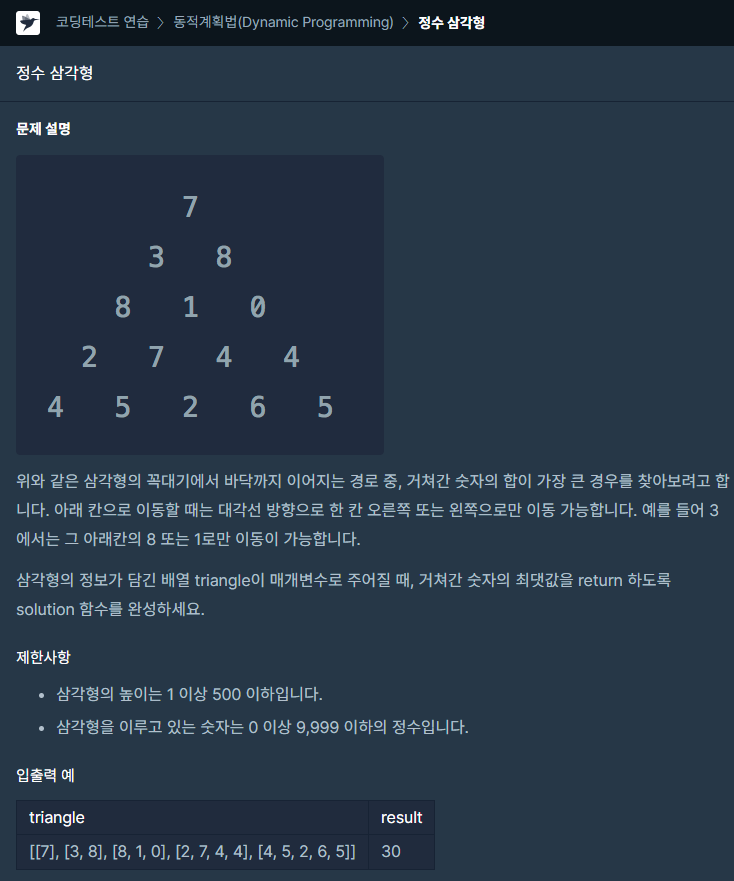
문제링크dp문제의 대표적인 문제이다.각 층마다 내려오면서 양쪽 위 중 큰 값을 가져와서 더해나가는 방식이다.인덱스 범위 체크 및 좌우 인덱스 설정만 하면 구현에는 큰 챌린지가 없었다.
42.[프로그래머스] 내적 JAVA
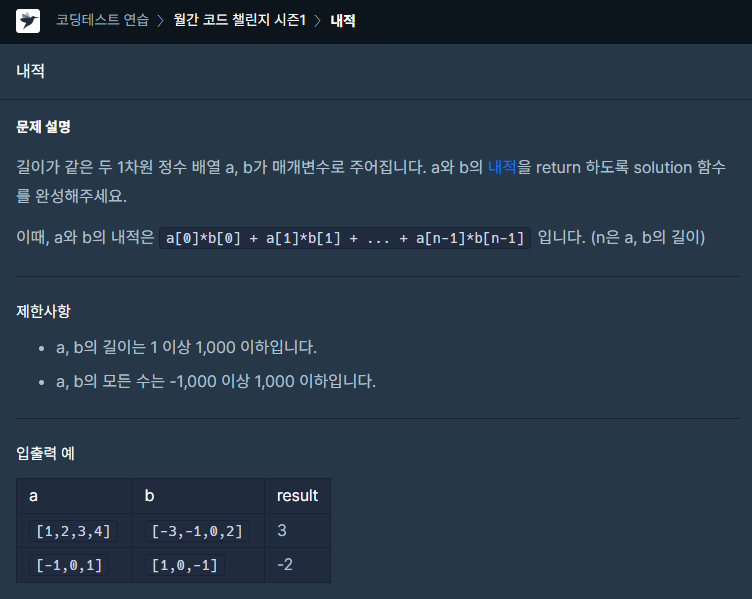
문제링크너무 쉬운 문제이다반복문을 통해 해당 인덱스의 두 배열 값을 곱해서 누적합을 구하면된다.이전에 for문의 조건문 안에 i < a.length와 같이 값을 메서드로 항상 불러오도록 하는 것보다, size = a.length과 같이 변수를 따로 설정 한 뒤,
43.[프로그래머스] 타겟 넘버 JAVA
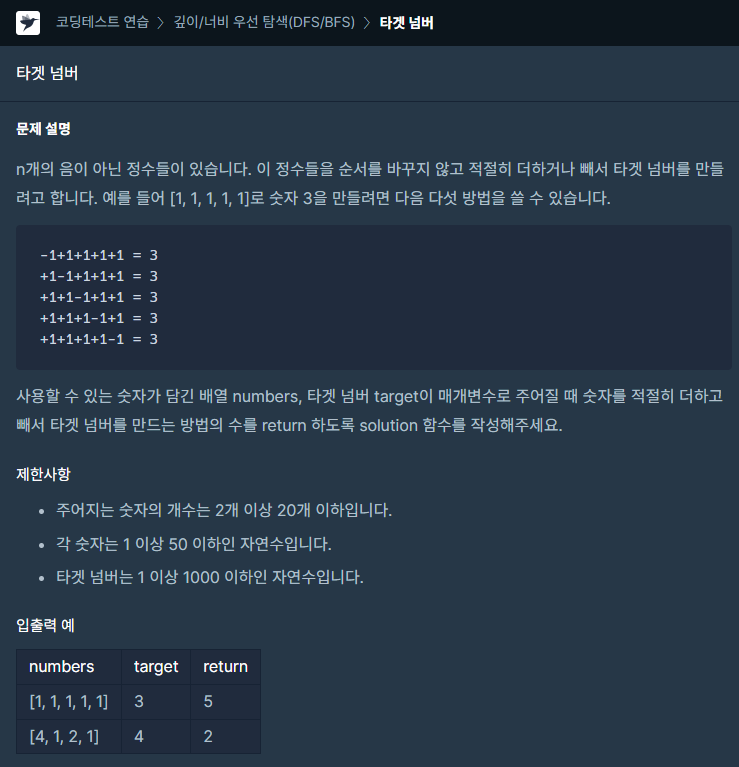
문제링크dfs을 응용하여 풀었다. 모든 값이 1로 초기화 되어있는 배열을 선언한 뒤, dfs로 각 경우의 수를 방문하면서 -1로 그 자리를 바꾸도록 하였다.그럼 부호의 모든 경우의 수를 방문할 수 있으며, 방문할 때마다 각 자리의 수를 곱해서 더하였다.중복된 경우의 수
44.[프로그래머스] n^2배열 자르기 JAVA
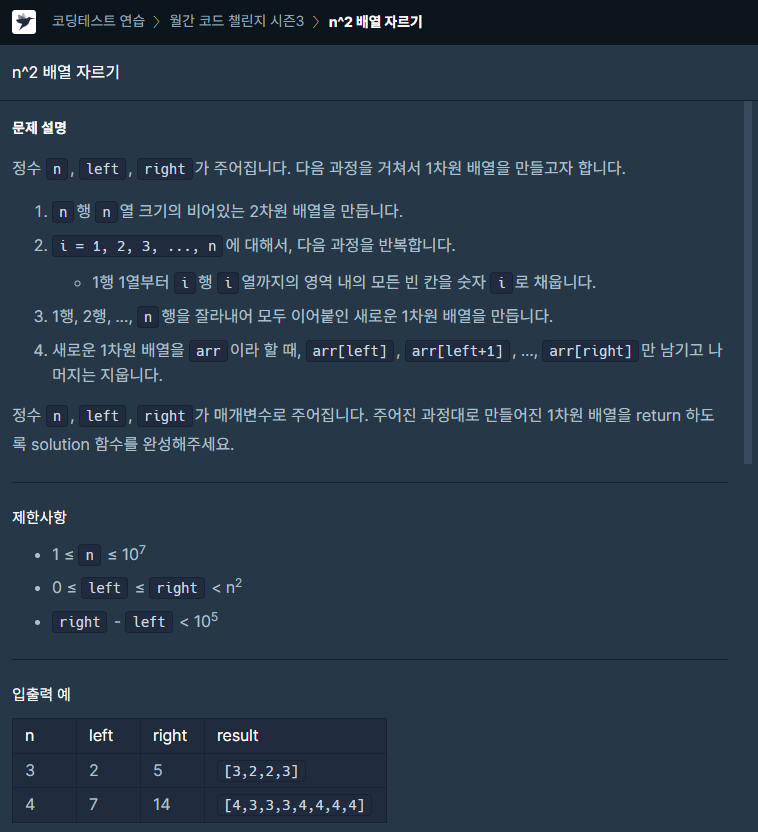
문제링크 처음에는 아래와 같이 구현하지 않고, 그림에 현혹되어 board라는 2차원 배열을 만들고 해당 값들을 대입하였다. 그리고 대충 left, right 좌표를 2차원 배열 좌표 값으로 변환하고 안에 있는 값들을 반환하였다. 물론 이것도 정답으로 통과 되었다.그런데
45.[프로그래머스] 소수 만들기 JAVA
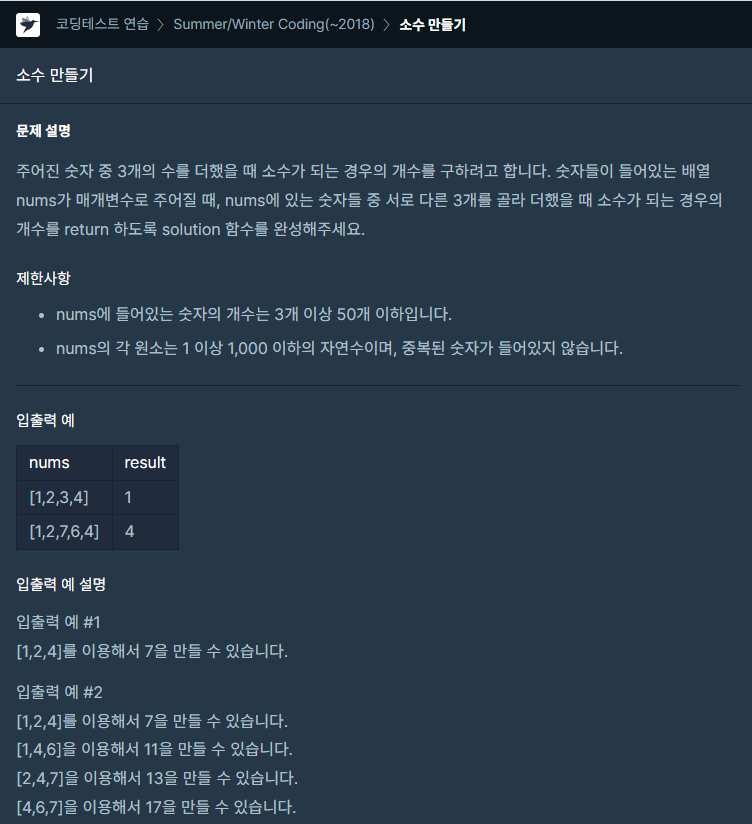
문제링크우선 주어진 개수가 최대 50이라는 사항에 완전탐색임을 확인하였다.isPrime 함수를 따로 만들고, 모든 경우의 수에 본 함수를 호출하는 간단한 로직이다.
46.[프로그래머스] 짝지어 제거하기 JAVA
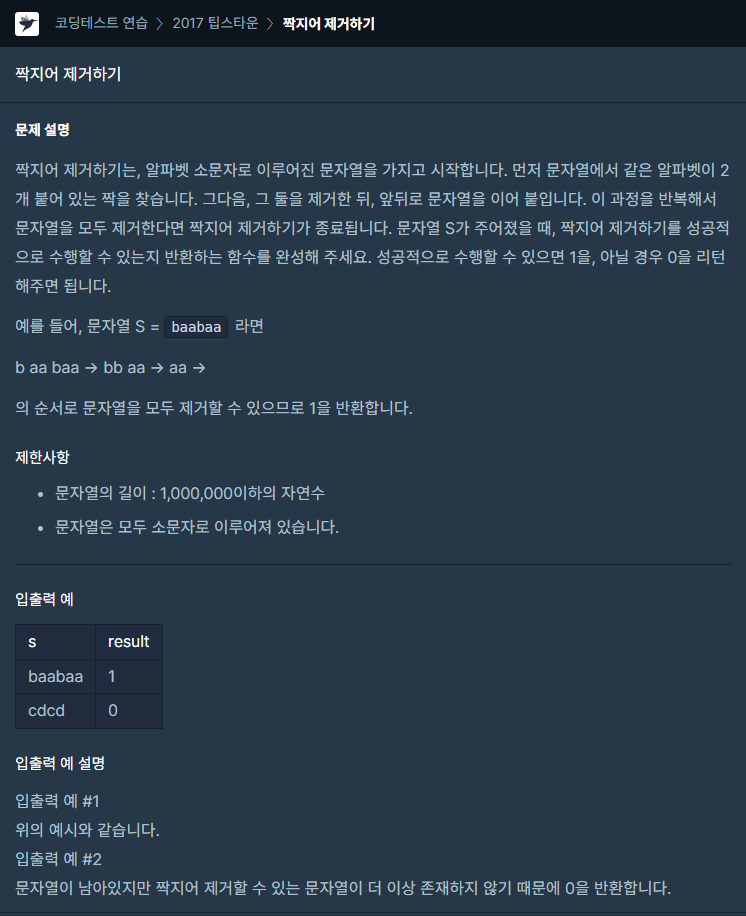
문제링크처음에는 간단한 이용하여 풀려고 하였지만, 시간 초과가 나서 복잡도 O(n)인 방법을 고민하였다.'제일 끝에 있는 것과 같은 것'이라는 개념을 생각하다가 스택이 떠올랐고, 스택을 떠올린 뒤에는 매우 간단하게 풀이하였다.
47.[프로그래머스] 네트워크 JAVA

문제링크연결된 모든 곳을 탐색한다는 점에서 dfs를 떠올렸다.union-find와 같이 아예 집합을 다르게 구분을 해야한다는 생각을 잠깐 했다가, 출발점으로 구분을 하면 되겠다 생각하였다.그래서 dfs를 제어 반복문 안에서 호출하여 해결하였다.
48.[프로그래머스] 튜플 JAVA

순서에 대해 해석하는 것이 생각보다 오래걸렸다. 원소가 먼저 있는지 없는지를 판별해야 하니, 각 원소의 길이로 정렬 후, 원소의 원소를 가지고 처리하면 된다.
49.[프로그래머스] 메뉴리뉴얼 JAVA

문제링크전체 부분집합을 구하는데 dfs를 사용하였다. 이 방법에 빨리 익숙해져야 할 것 같다.set을 이용하면서 시간복잡도를 줄이려고 했는데 막상 구현 후에는 그 장점을 많이 이용하지 못한 것 같아서 아쉽다.이후 숏코딩을 도전해볼 필요가 있다.
50.[프로그래머스] 후보키 JAVA
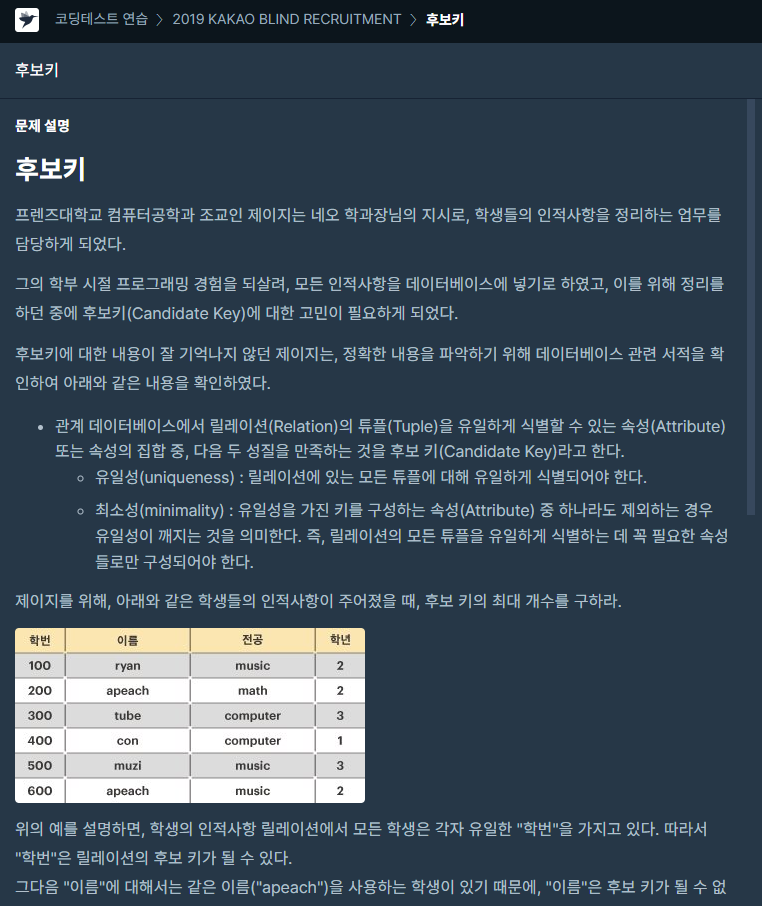
문제링크dfs로 전체 부분 집합을 구하였다.숫자지만 문자열로 다루면서 정규식을 적극 활용하였다.else문 없이 코딩하기 연습 중..!!
51.[프로그래머스] 단체사진찍기 JAVA
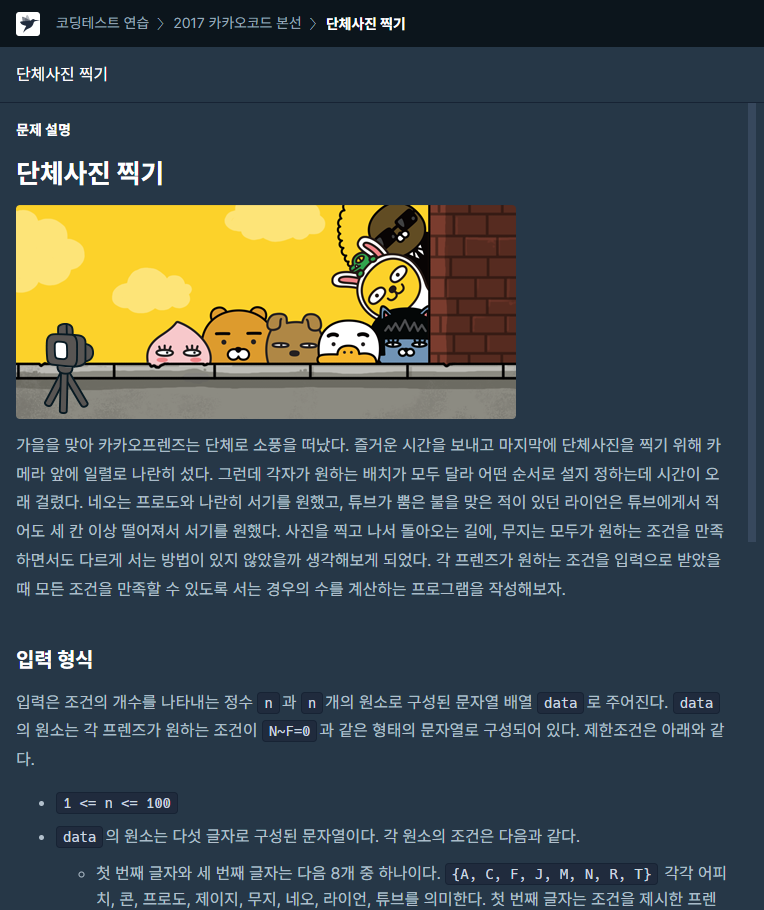
문제링크조건의 길이가 100이하로 작은 수이며, 사람이 8명이므로 완전탐색을 떠올렸다.모든 경우의 수를 방문하면서 조건에 부합하는지 확인하면 된다.유의할 점은 두 인덱스의 차가 거리가 아니라, (두 인덱스 차) - 1 이 거리가 된다는 것이다.
52.[프로그래머스] 롤케이크 자르기 JAVA
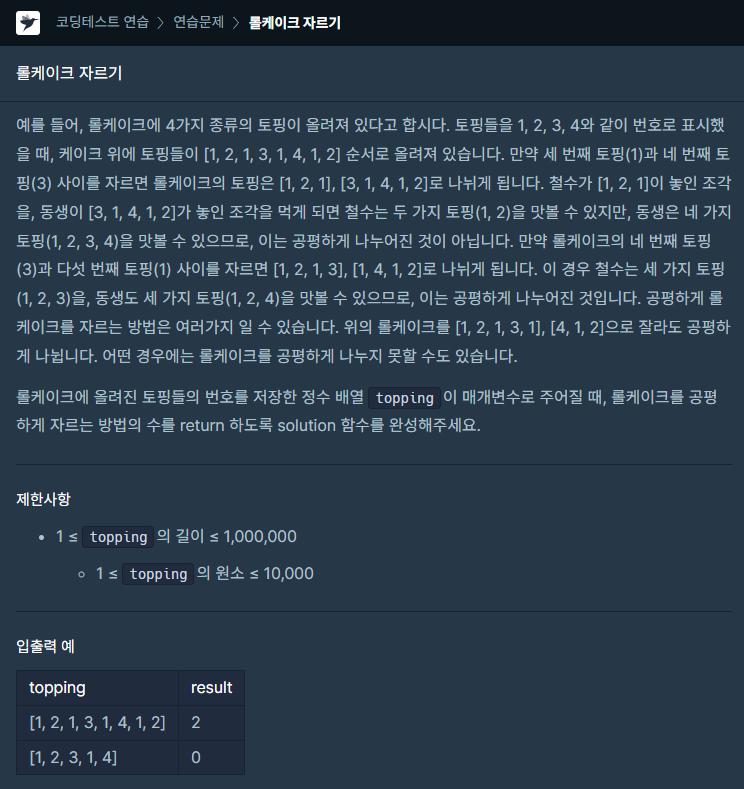
문제링크
53.[프로그래머스] 디펜스 게임 JAVA

문제링크enemy의 길이가 짧지만은 않아서 모든 경우의 수를 따지기에는 부담이 따를 것이라고 예상했다.사고의 흐름은 지금까지의 뺀 값들 중에 가장 큰 것을 롤백한다는 상상이 먼저 떠올랐다.그래서 거쳐온 모든 값을 저장해놓고, 그 중에 최대값을 다시 복구하는 순서로 구현
54.[프로그래머스] 요격 시스템 JAVA

문제링크끝나는 구간을 오름차순으로 정렬하고, 한 범위에 대해서 최대한 뒤쪽에 요격 하면 이후의 범위에 최대한 들 수 있다.양쪽이 개구간이라는 것이 유의할 점이다.
55.[프로그래머스] 수식 최대화 JAVA

문제링크스택을 활용한 연산을 할 때 우선순위를 사용하여 더 꺼낼지 말지 판단한다.그래서 이 문제도 그 우선순위에 대하여 완전탐색하면 최대값을 구할 수 있다.정규식으로 연산자와 피연산자를 각각 처리하여 쉽게 파싱하였다.내부 값이 딱히 필요 없기 때문에 속도 향상을 위하여
56.[프로그래머스] 아이템 줍기 JAVA
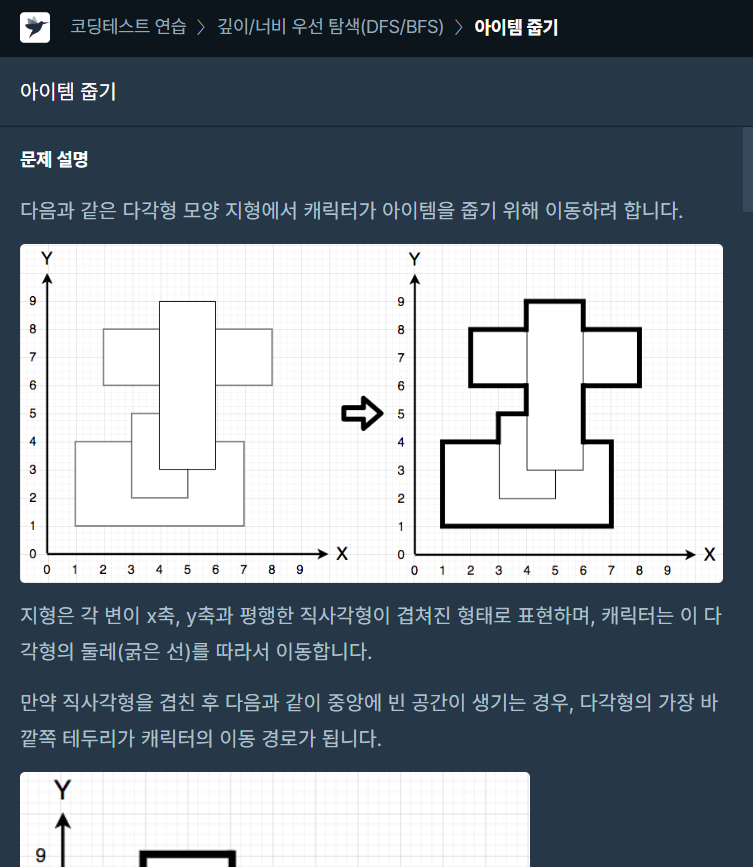
문제 링크가장 먼저 가장자리에 따라 BFS 탐색을 해야 한다는 생각에서 출발하였다.테두리 정보를 쉽게 입력에 따라 배열에 표시하여 쉽게 얻을 수 있을 것 같다 생각하였다.그런데 특정 점 좌표와 채워진 면적 정보를 2차원 배열로 고민하는 과정에 두 용도를 구분하여 2개의
57.[프로그래머스] 연속 펄스 부분 수열의 합 JAVA
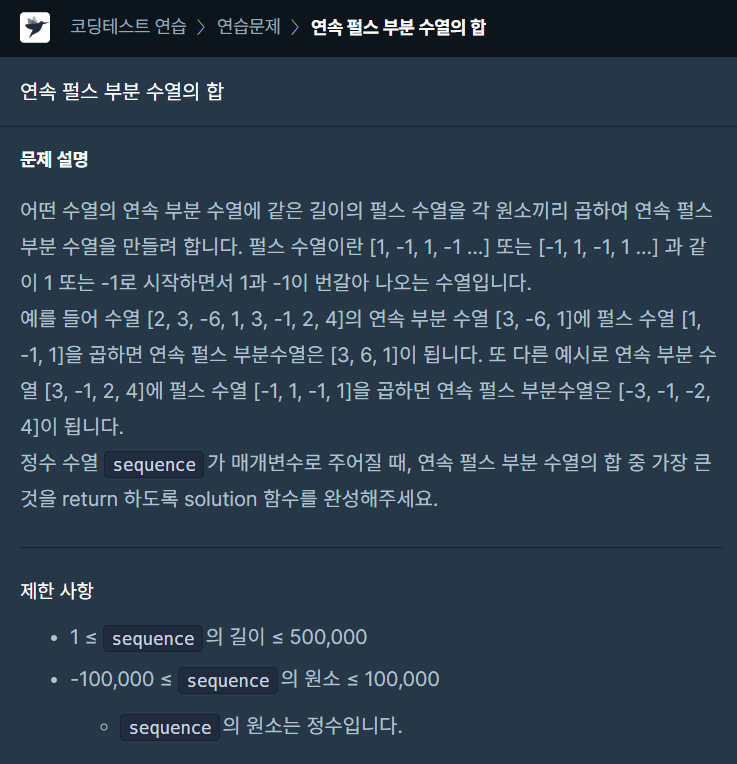
문제링크1로 시작하는 누적합 배열과, -1로 시작하는 누적합 배열을 구분하여 풀이를 시작하였다.해당 인덱스 전까지 경우의 수들을 비교하며 최댓값을 탐색하였는데, 줄어드는 이중반복문이라 O(nlogn)의 시간복잡도를 가진다. -> 시간초과O(n) 수준의 시간복잡도를 고민
58.[프로그래머스] 모음사전 JAVA
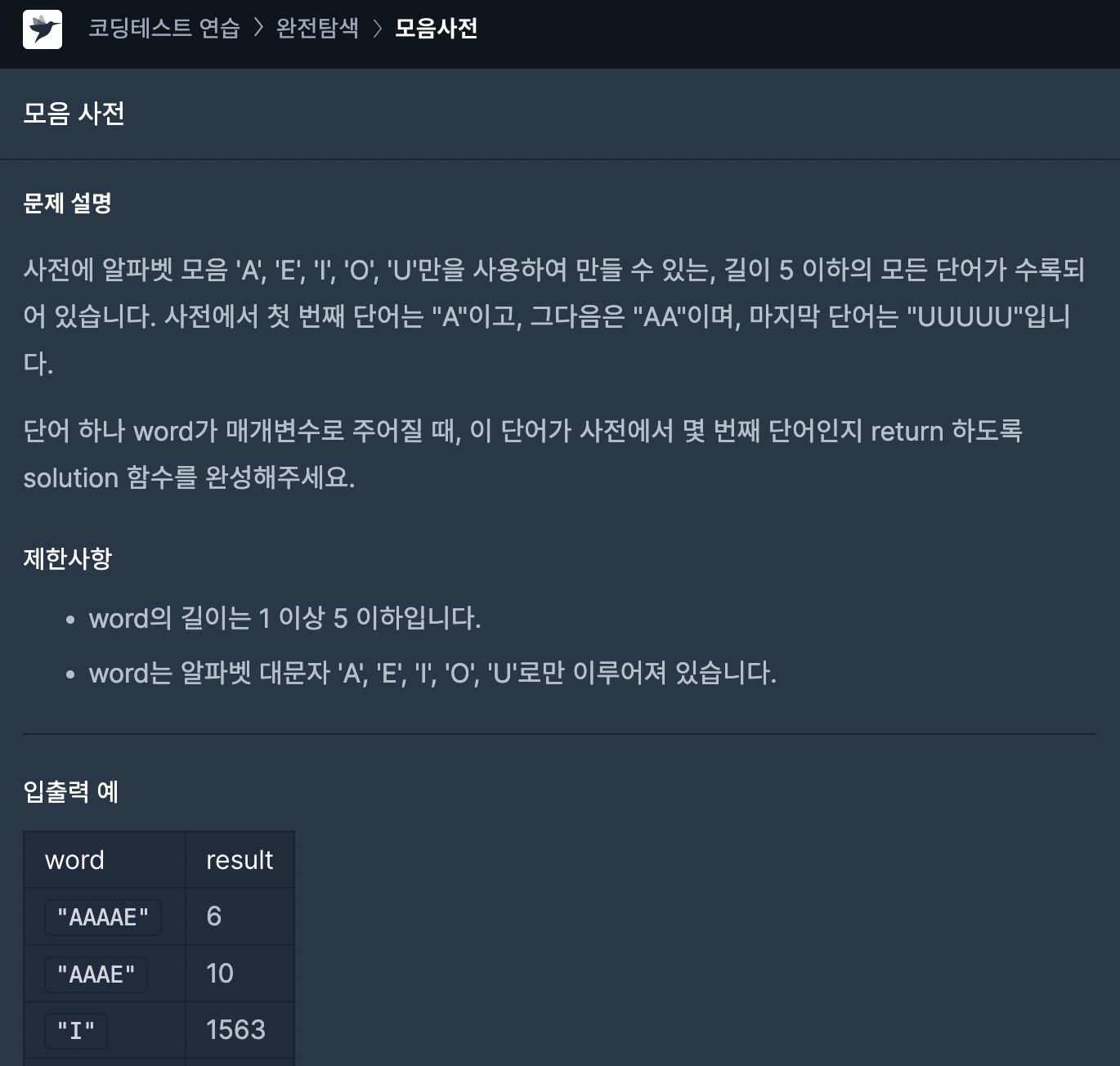
가장 앞자리가 바뀔 때마다 아래 자리 수의 경우의 수 만큼 건너 뛰어야 한다.예를 들어 A -> E로 갈때는 A를 가장 앞글자로 두는 모든 단어들을 건너뛰어야 한다. 그래서 4자리의 모든 경우의 수를 계산하고, 몇 칸 넘어가는지를 곱하면 된다.모든 경우의 수는 제곱 연
59.[프로그래머스] 연속 부분 수열 합의 개수 JAVA
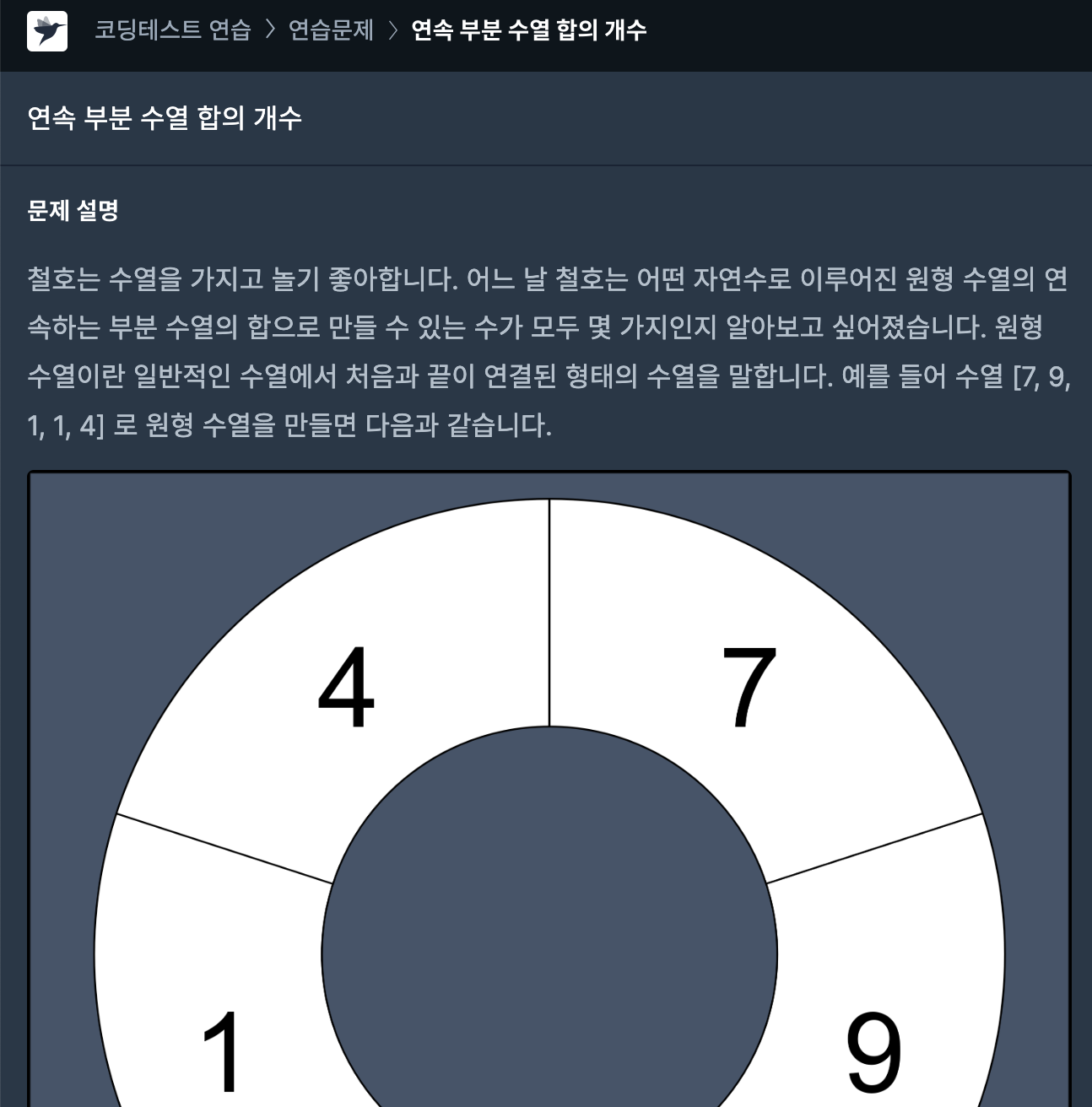
문제링크처음에는 이전처럼 getNextIdx() 메서드를 만들어서, 끝값을 분기했었는데 너무 잦은 메서드 호출이 걱정되었다.어차피 중복 값은 취급하면 안되기 때문에 배열에서 임시로 같은 배열을 뒤에 붙이면 모든 경우의 수를 다룰 수 있다.
60.[프로그래머스] 파일명 정렬 JAVA

문제링크자바 정규식을 활용하면 쉽게 풀이할 수 있다.특정한 로직으로 정렬을 할때는 Comparable을 상속 받고, compareTo 메서드를 오버라이드하여 활용한다.
61.[프로그래머스] 압축 JAVA

문제 링크투 포인트를 이용한 문자열 분리와 해싱을 통해 해결하였다.한글자 단위로는 다 해싱이 되어 있으므로, 두 글자 이상부터 해당 문자열이 사전에 포함되어 있는지 확인한다. 이때 점점 늘려가다가, 없는 순간의 바로 앞칸을 이용하여 최장 길이를 찾는다.반복문 종료 조건
62.[프로그래머스] 괄호 회전하기 JAVA

문제링크기본적으로 스택을 이용한 괄호 유효성 검사 알고리즘이 필요하다.괄호 회전 처리는 인덱스의 증감으로 처리하여 순회하며 개수를 센다.
63.[프로그래머스] 기지국 설치 JAVA
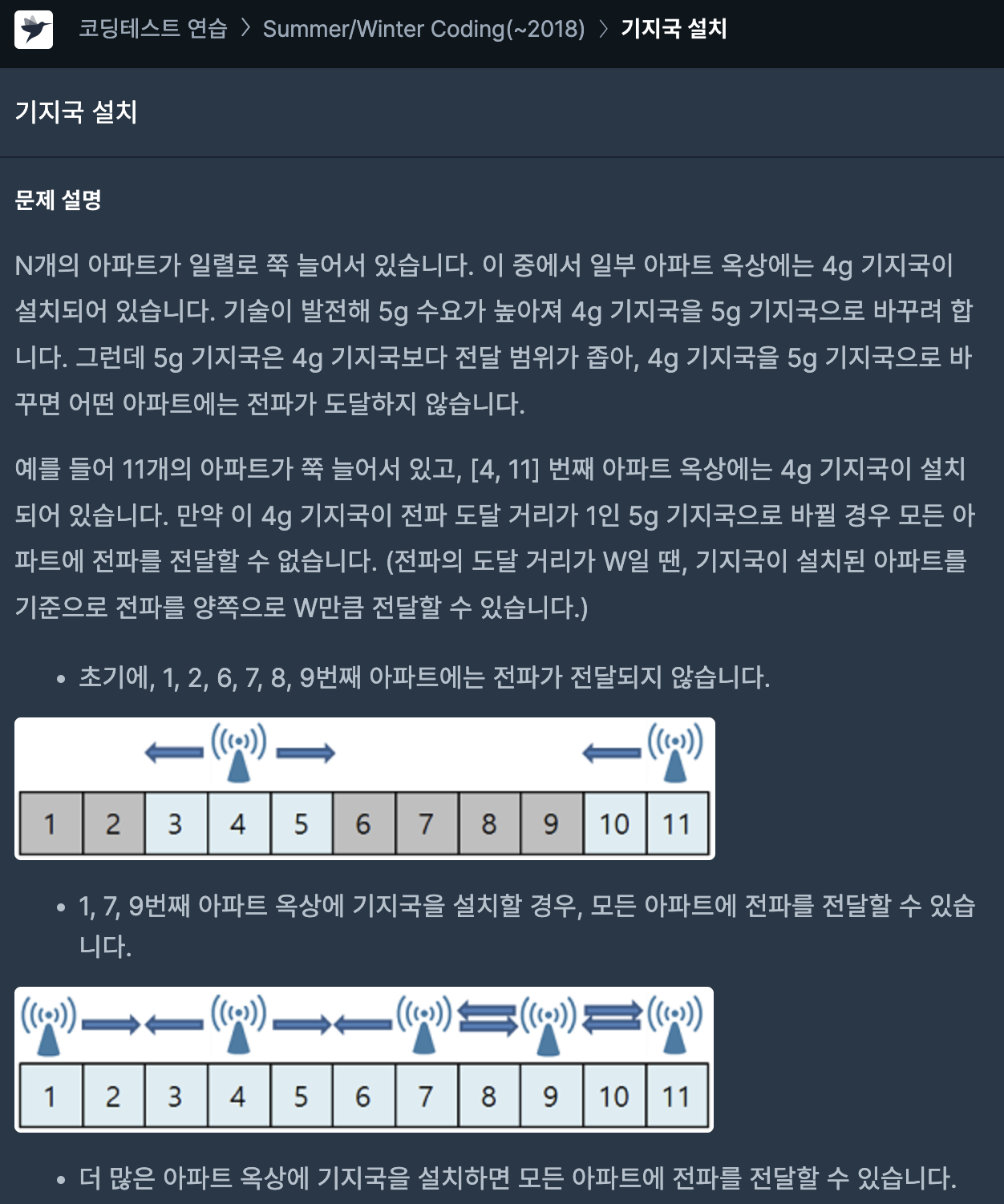
문제 링크n이 크기 때문에 시간복잡도 O(n)이하으로 맞추어야 한다.처음에는 아래 코드로 0.0x수준으로 정확성 테스트를 통과하였지만, 효율성 테스트를 하나도 통과하지 못했다...다시 읽어보니 stations가 오름차순으로 정렬되어 있는 것을 확인하였고, 인덱스 연산에
64.[Softeer] 성적 평가 JAVA
문제링크처음에는 문제가 생각보다 쉽다 생각하고 아래와 같이 정렬과 indexOf 메서드를 활용하였지만 반 이상이 시간초과가 났다... ㅠO(n) 수준 이하로 복잡도를 낮추기 위해서 고민하다가, 수 범위가 1000이하로 좁다는 것을 확인하였다.1000 모든 값에 대해서
65.[Softeer] 슈퍼컴퓨터 클러스터 JAVA
먼저 나의 풀이는 다른 사람들의 풀이와 접근 자체가 다르다. 다른 사람들은 이분탐색으로 풀었는데, 다 풀고 다른 사람 풀이를 보니까 이분탐색으로 푸는 것이 더 좋을 것 같다.이분탐색을 이용할 경우 탐색 자체는 O(logn) 수준이지만, 모든 수를 탐색 당 한 번씩 돌아
66.[Softeer] 통근버스 출발 순서 검증하기 JAVA
문제 링크N 범위는 그렇게 크지 않아서 모든 순열을 조회하며 분기하는 풀이를 떠올렸다. 그런데 시간 복잡고 O(N^3) 수준이라 배제하였다.백준의 가장 \~~ 수열 시리즈의 접근법이 떠올라 dp를 떠올렸고, 전혀 다른 풀이였지만 해결하였다.최종적으로 시간복잡도는 O
67.[Softeer] 플레이페어 JAVA
문제 링크알파벳 <-> 인덱스 변환이 양쪽으로 자주 일어나기 때문에 이 과정에서 시간복잡도를 줄이는 것이 안건이라고 생각했다.암호 생성할 때 2차원 배열에서의 탐색이 필요하기 때문에 2차원 배열에 알파벳을 저장하고, 저장할 때 Map에 <알파벳, 인덱스> 정
68.[프로그래머스] 여행경로 JAVA

문제링크백트래킹 그리만 그려지면 금방 풀리는 문제이다.방문 여부를 포함하고 있는 간선 클래스를 통해 <도시이름-간선리스트> 형태로 map을 구성하여 dfs, 백트래킹을 이어갔다.map을 사용할 때 항상 get이 null을 반환하는지를 조심하자!
69.[프로그래머스] 야근 지수 JAVA

문제링크(https://school.programmers.co.kr/learn/courses/30/lessons/12927제곱 관련 문제가 나오면 제일 많이 사용하는 개념은, 제곱한 두 수의 합이 가장 작은 경우는 두 수의 차가 가장 작을 때라는 것이다. 수학
70.[프로그래머스] 섬 연결하기 JAVA

문제 링크(https://school.programmers.co.kr/learn/courses/30/lessons/42861여러 개의 간선을 지나고, 모든 정점을 방문해야 한다는 점에서 MST(최소 신장 트리)를 떠올렸다.MST 풀이 알고리즘으로는 대표적으로
71.[프로그래머스] 방문길이 JAVA
문제링크(https://school.programmers.co.kr/learn/courses/30/lessons/49994- 처음에는 방문 여부를 체크하면서 정답을 늘려야 하나 고민했지만, set을 이용하면 중복처리를 쉽게 할 수 있을 것 같아서 그 방향으로
72.[프로그래머스] 순위 JAVA

문제링크나보다 강한 사람, 약한 사람의 수가 n-1일 때 그 사람의 순위를 알 수 있다.그래서 단방향 그래프를 이용해 강한 사람, 약한 사람을 dfs를 이용해 찾았다.풀고 난 후 다른 분들은 플로이드-워셜 알고리즘을 이용한 사람들이 많았는데, 비슷한 시간복잡도와 실행시
73.[프로그래머스] 숫자게임 JAVA

문제링크옛날에 어떤 문제인지 정확히 기억은 안 나지만, 이렇게 1대1로 최대한 많이 이겨야 하는 경우에는 최대한 근소한 차이로 이기는 경우를 합치면 되는 경험이 있었다.처음에는 이진탐색을 생각했지만, 배열 정렬로 해결할 수 있을 것 같아 해결하였다.
74.[프로그래머스] 숫자게임 JAVA

문제링크(https://school.programmers.co.kr/learn/courses/30/lessons/12971처음에는 전형적인 dp문제라고 생각이 들었는데, 원형이라서 마지막 인덱스 처리하는 데에 꽤 고민을 많이 했다.점화식 수준에서 분기할 수 있
75.[프로그래머스] 파괴되지 않은 건물 JAVA

문제 링크처음에는 단순히 문제의 순서에 따라 배열을 채웠다. O(n) 수준의 시간 복잡도이지만, 명령어 수가 많아서 효율성 테스트 0점이 나온당,,ㅠ아무리 생각해도 해답이 안 떠올라서, 2차원 누적합이라는 키워드를 얻고 풀이하였다.일반적인 2차원 배열에서의 누적합 방식
76.[프로그래머스] 광물 캐기 JAVA

문제링크단위 수가 작아서 백트래킹을 가장 먼저 떠올렸다.일반적인 백트래킹 형태로 풀이하면 되지만, 한 조건을 사용할 때 5번의 사용이 있다는 것을 잘 구현하면 어려움 없이 구현할 수 있다.
77.[프로그래머스] 합승 택시 요금 JAVA
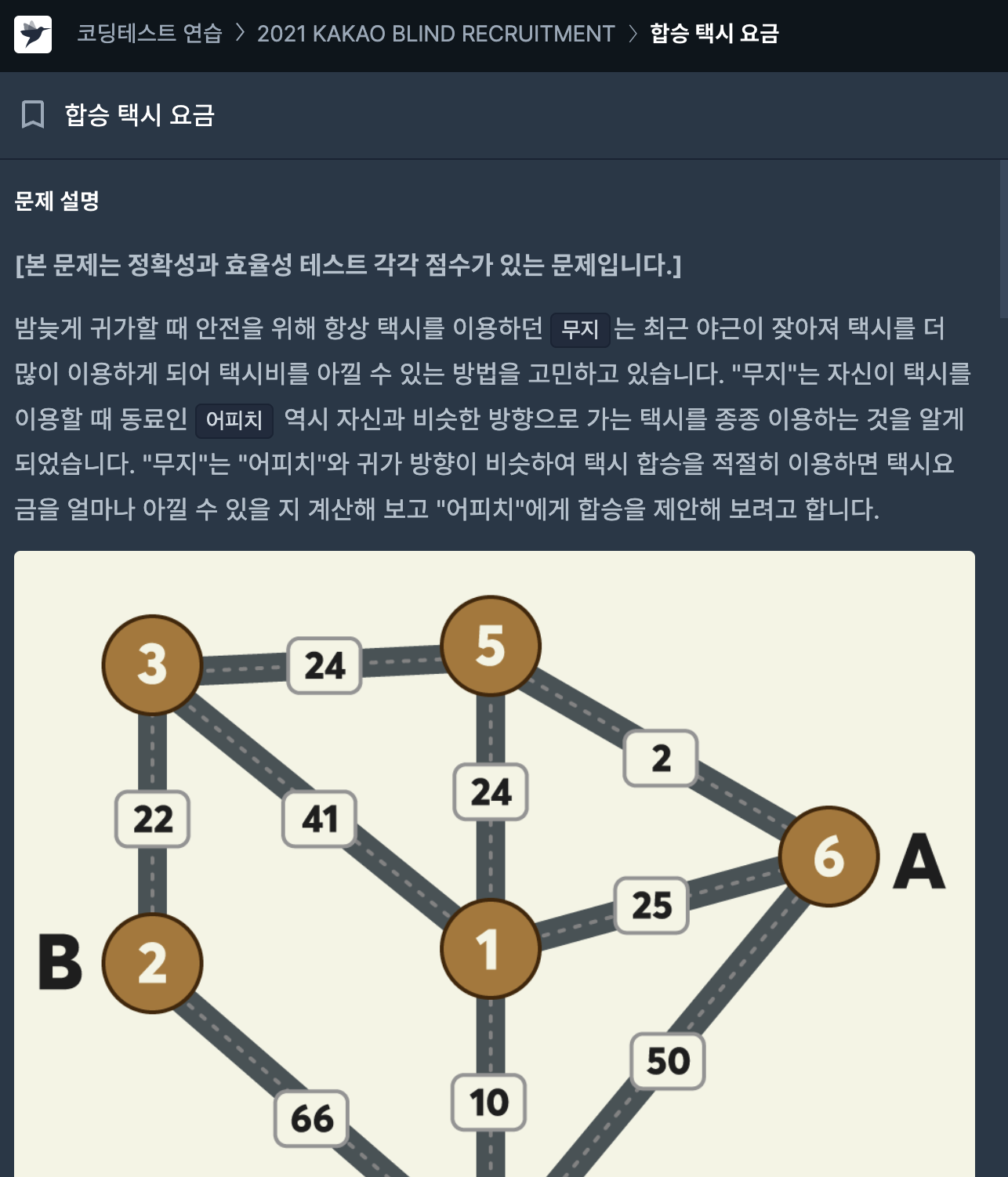
문제링크효율성 점수가 따로 있는 문제였지만, 우선 정점의 최대 개수가 200이라는 점에서 완탐이 가장 먼저 떠올랐다.단순히 두 점에 관한 연산이 아니라 세 점 이상의 경우를 고려해야 했기 때문에 플로이드-워샬 알고리즘으로 각 정점끼리의 최소 비용을 구했다.그리고 출발점
78.[프로그래머스] [PCCP 기출문제] 2번 / 석유 시추 JAVA

문제링크일반적인 bfs 문제다. 한 영역에 대해 라벨링을 하고, map 자료구조에 라벨과 크기를 저장하면 시간을 단축할 수 있다.한 세로줄에 대해 set으로 포함되는 라벨을 저장하면 후에 총합을 구할 때 빠르게 연산할 수 있도록 하였다.