[ICLR 2023] CrossFormer: Transformer Utilizing Cross-Dimension Dependency for Multivariate time series forecasting
Paper Reading
이때까지의 연구와 문제점
많은 트렌스포머 기반의 모델들이 long-term dependency를 잘 포착한다. 하지만, 많은 종류의 트랜스포머 기반의 시계열 모델들이 다른 변수들(Multivariate니까!)사이의 dependency를 중요하게 생각하지 않는다.
MTS에서 변수들 간의 dependency를 포착하기 위해서 cross-dimension dependency를 제안함.
변수들간의 dependency를 고려하지 않으면, 예측이 제한적이라고함.
그래서 이 논문에서는!
Dimension-Segment-Wise(DSW) : input MTS —> 2D Vector array로 임베딩함. (시간과 변수들 사이의 정보를 보존할 수 있다.)
이렇게 모든 변수들사이의 connection을 보기때문에 high-dimensional dataset에서는 computation도 많고 한계점이 생긴다. (Graph Transformer, Sparse transformer등과는 확실하게 다른 것을 알 수 있음.)
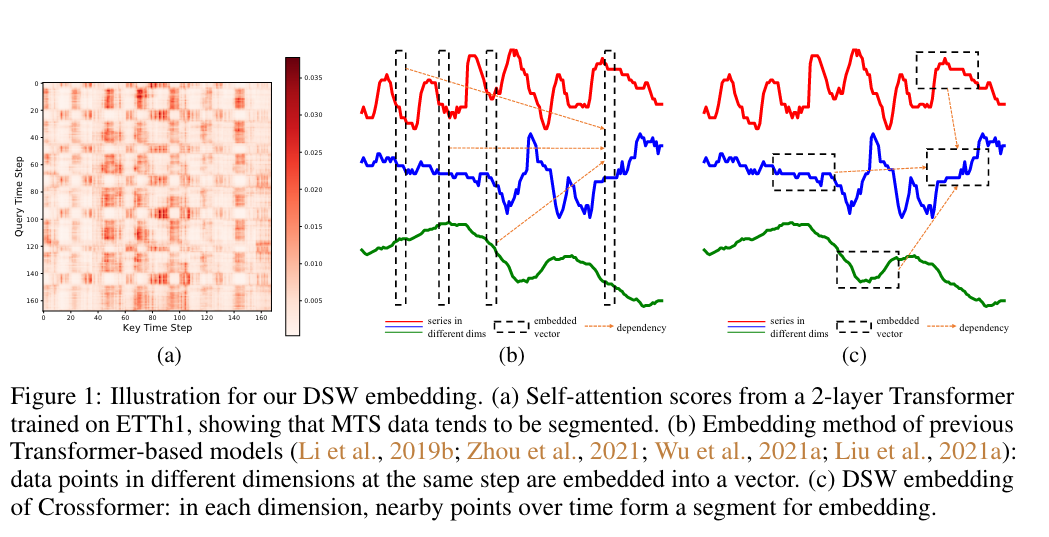
이 그림에서 보여주는 것은 (b)는 기존의 변수들간의 관계를 보지않고 embedding하던 방법론이라면, (c)에서는 이 논문에서 제안하는 DSW 변수들간의 관계를 고려한 embedding 방법을 적용한 것을 보여준다.
그림 (a)를 보면, attention score map은 이 여러개의 구획 (segment)를 구성하는 것을 알 수 있다. (data point가 가까울 수록 비슷한 attention weight를 가진다.)
Two-Stage Attention (TSA) : cross-time / cross-dimension의 dependency를 효율적으로 포착함.
어떻게?
DSW를 통해 임베딩된 2D array는 ViT에서의 이미지 데이터처럼 x,y축이 바뀔 수 없다. 왜냐하면 Time-series에서의 x축과 y축은 각각 시간과 차원이랑는 다른 의미를 가지기 떄문에 바뀔 수 없다. 그래서 self-attention을 그대로 적용해야하는데, 2D array의 self-attention은 complexity가 크기 때문에 이 논문에서는 two-stage attention을 제안한다.

제안한 Two-stage attention은 다음과 같이 dimension 차원에서의 attention과 time 차원에서의 attention 이렇게 2가지이다.
이 둘을 사용해서 Hierarchical Encoder-Decoder구조를 통해서 예측을 한다.
소감..
이 논문의 경우, 시계열예측에서 늘 찝찝했던 변수에 대한 종속성 문제를 짚은 논문이라고 생각한다.
