Ch3 p.90에서 SGDClassifier를 이용한 이진분류가 나왔다. 그런데 SGDClassifier를 비롯하여 SGD에 대한 설명이 부족해서 더 공부해보려고 한다.
SGD에 대해 다루기 전, 오차(/손실)와 오차함수(/손실함수), GD를 먼저 다뤄보려고 한다. (얘네를 알아야지만 SGD의 필요성?을 알 수 있기 때문)
1) 오차
모델은 어떤 방향으로 만들어 나가야 할까?
-> 모델에 입력값을 넣었을 때 나오는 예측값과 실제값(/타깃값)의 차이인 오차(/손실)가 최소화 되도록 만들어야 한다.
이런 오차는 다양한 방법으로 정의할 수 있다.
- Mean Squared Error, MSE

- Rooted Mean Squared Error, RMSE
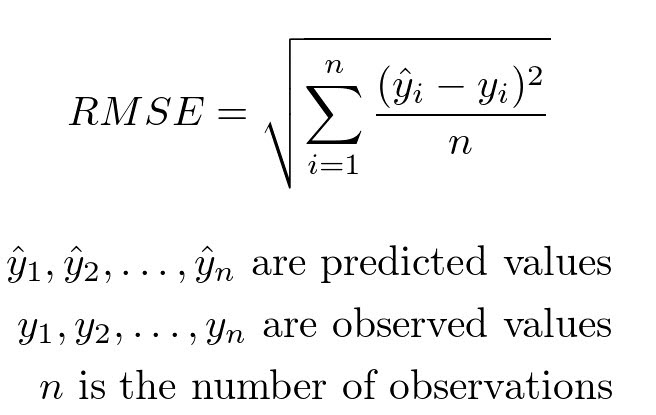
- MAE
- MAPE
- Binary Cross Entropy
- Categorical Cross Entropy
이 외에도 오차를 정의한 다양한 오차 함수(Error Function)/손실 함수(Loss Function)이 있다. 이러한 손실 함수에 대해서는 나중에 자세하게 공부해보고, 지금은 넘어가도록 하자.
이제, 손실 함수를 최소화하려면 어떻게 해야 할까?
2) Gradient Descent, 경사 하강법
손실 함수를 최소화 -> 최적화 -> Optimization
이를 수행하는 알고리즘 -> Optimizer
즉, Optimizer란 주어진 데이터에 맞게 모델 파라미터들을 최적화시켜주는 역할을 한다. Gradient Descent는 그 중 하나로 이 외에도 여러 Optimizer들이 존재한다. 이것도 나중에 다뤄보도록 하자.
Gradient Descent는 이름 그대로 기울기를 이용한다. 우리가 조정하고자 하는 값은 weight(가중치)와 bias이므로 손실 함수를 w와 b에 관한 함수라고 생각하면 된다.
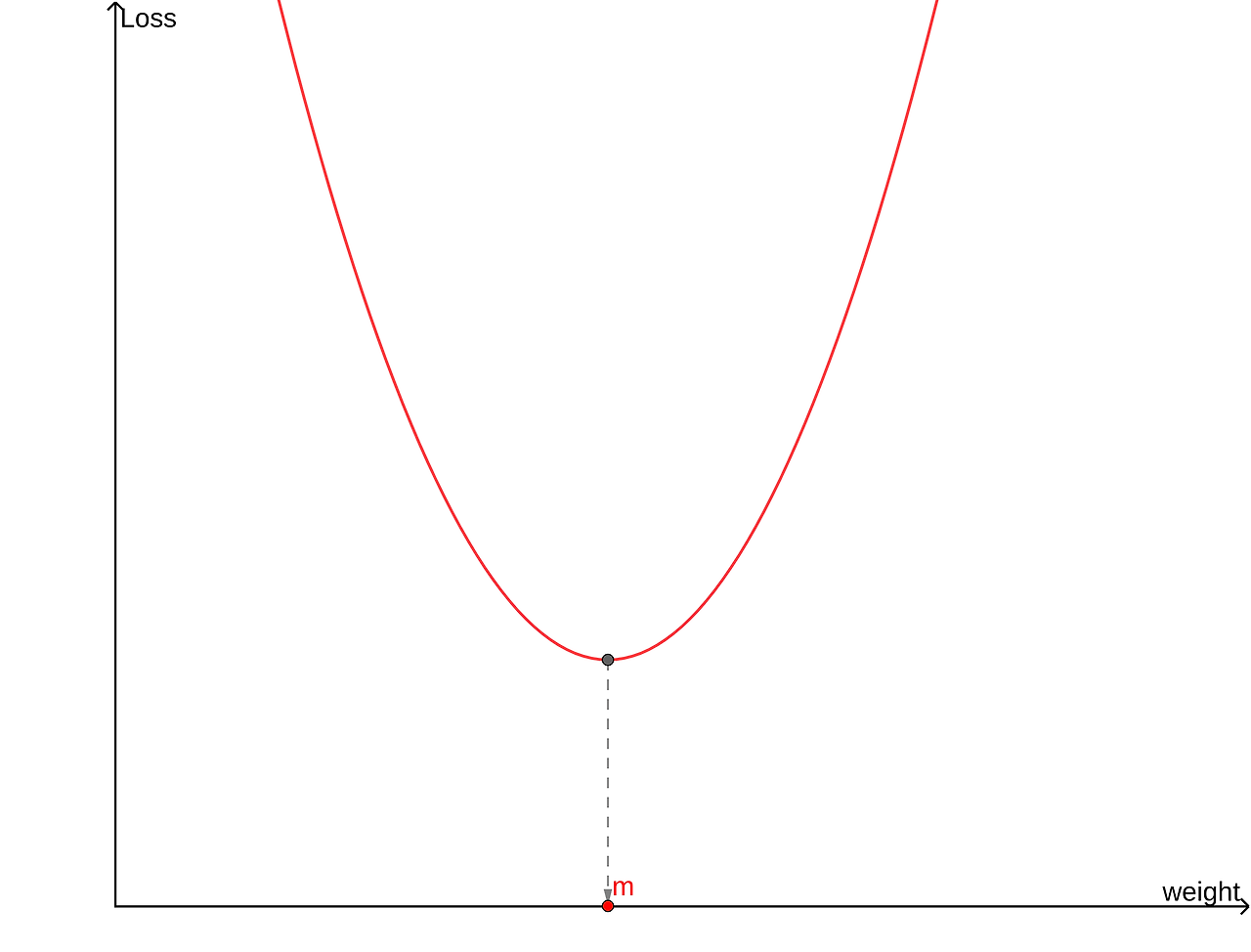
이 함수는 w=m에서 최솟값을 갖는다.
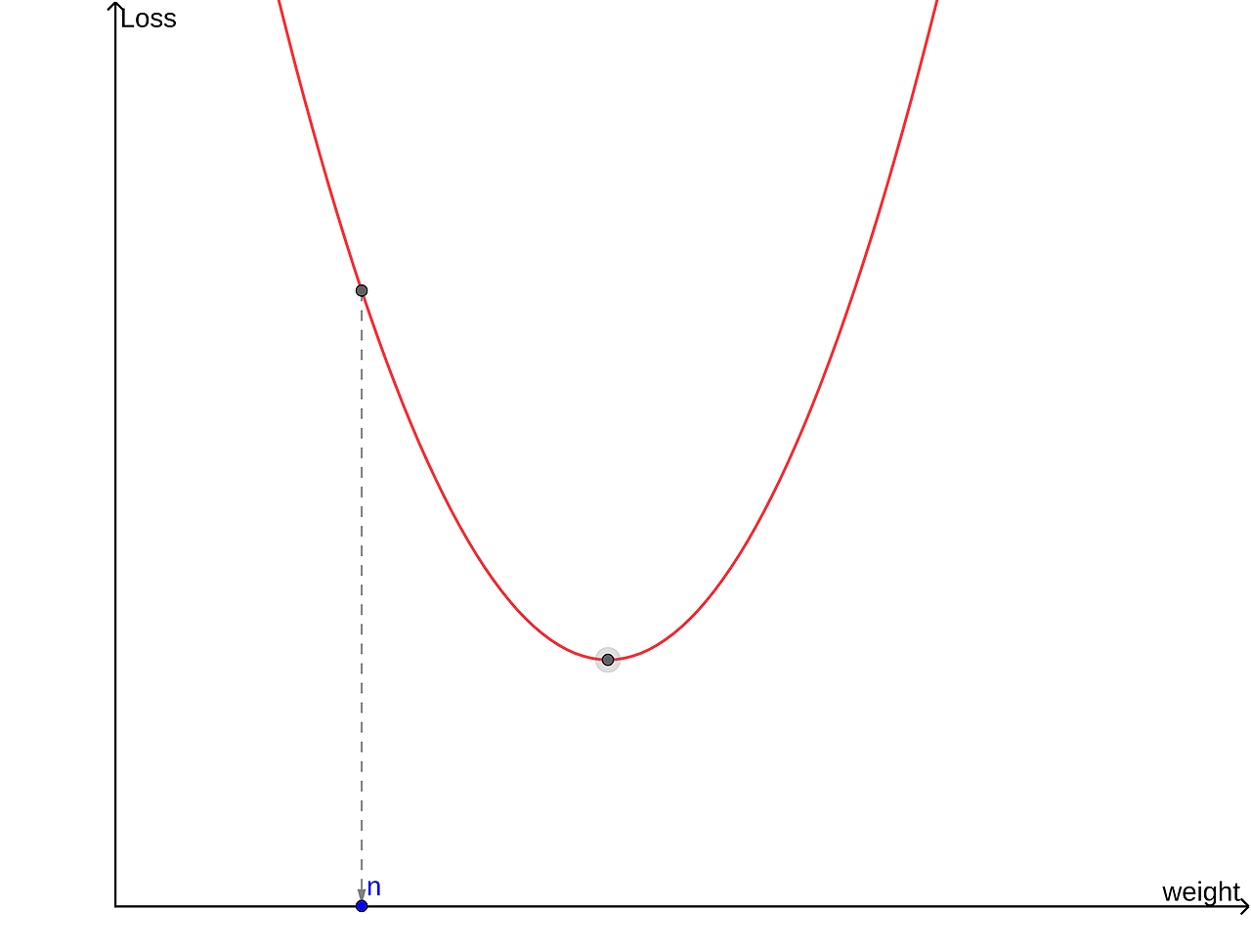
이 함수가 최소가 되려면 w를 양의 방향으로 이동시켜야 한다. -> w=w+양수
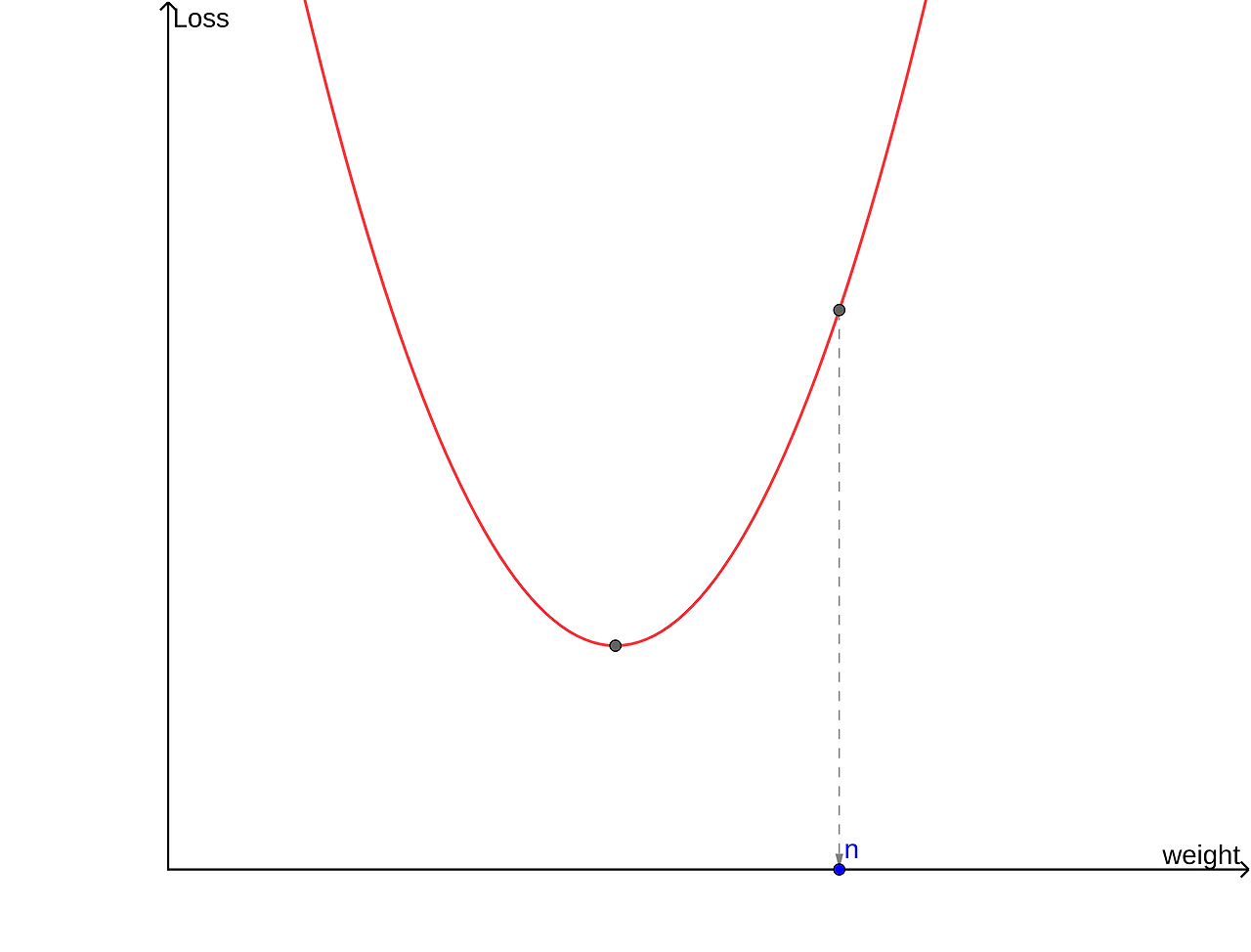
여기서는 w의 값을 음의 방향으로 이동시켜야 한다. -> w=w+음수
Gradient Descent는 기울기를 이용하는 방법이라고 했다. 위 두 경우를 기울기 관점에서 보자.
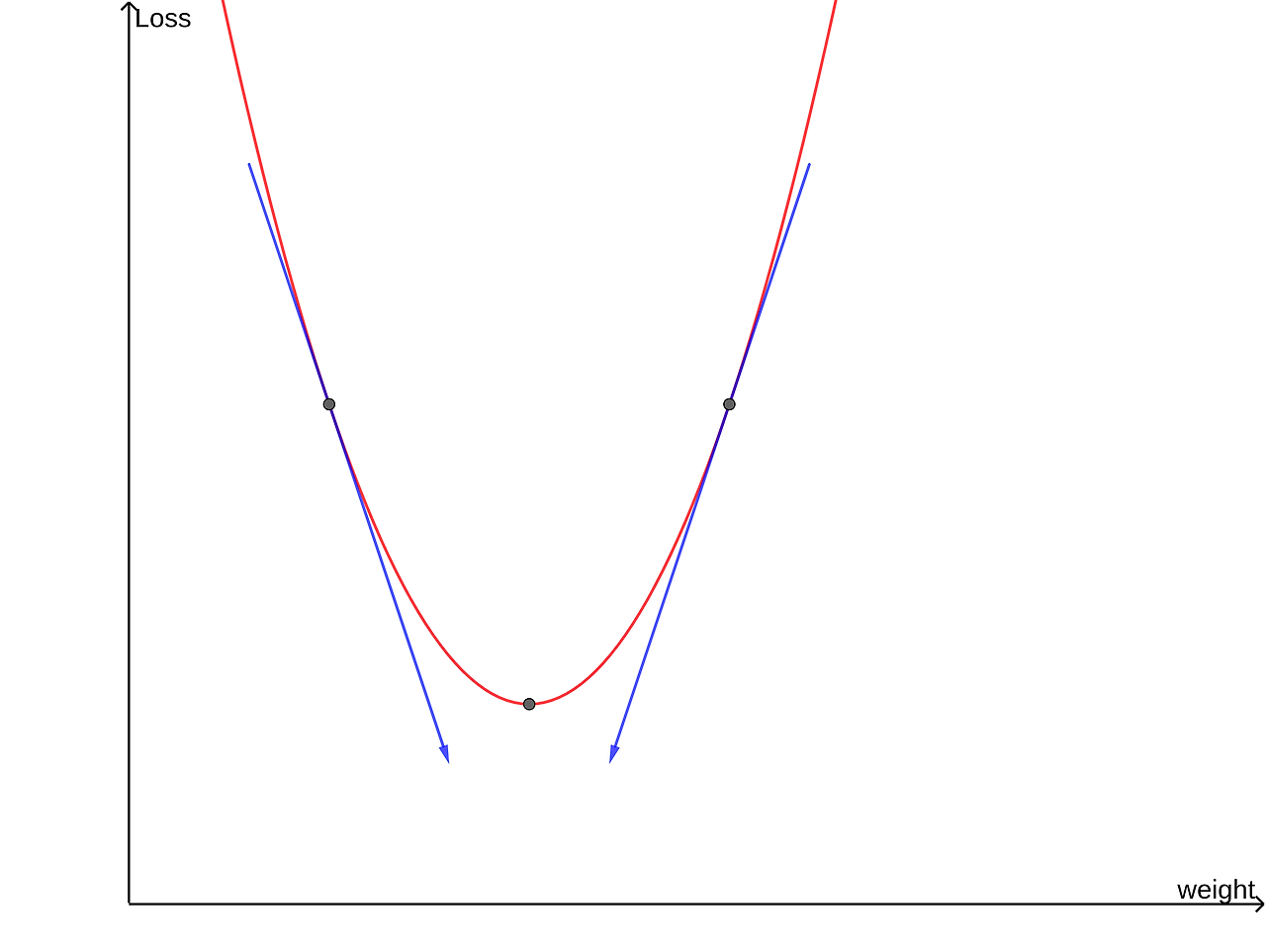
손실 함수의 w에서 미분계수가 양이면 w를 음의 방향으로, 미분계수가 음이면 w를 양의 방향으로 이동시켜야 한다. 이는 아래의 식으로 나타낼 수 있다. 여기서 w는 weight를, alpha는 학습률을 의미한다.

이런 방식으로 w값을 조정하여 손실함수가 최솟값을 갖도록 조정해주는 것이 바로 Gradient Descent이다.
이 방법으로 w값을 조정해주면 좋은 점이 있다.
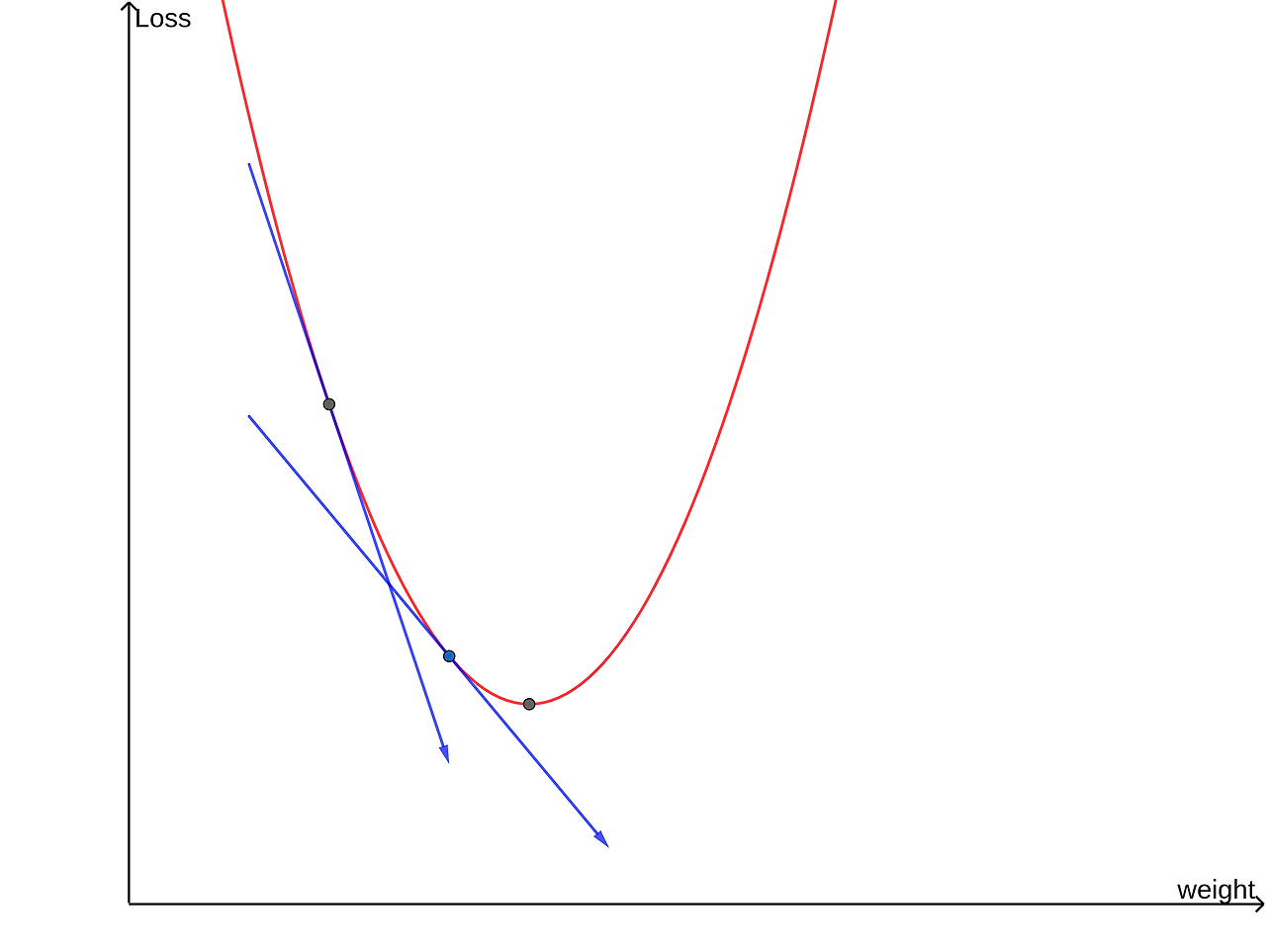
기울기가 크다는 건 극솟값을 갖는 w로부터 멀리 있다는 것을 의미한다. 즉, w의 미분계수의 절댓값과 w가 최솟점으로 이동해야 하는 거리가 비례하기 때문에 위 식을 이용해서 w가 최솟점에서 멀 때는 빠르게, 가까울 때는 천천히 수렴하도록 설정할 수 있고, 이는 alpha->Learning Rate(학습률) 파라미터를 통해 조정할 수 있다.
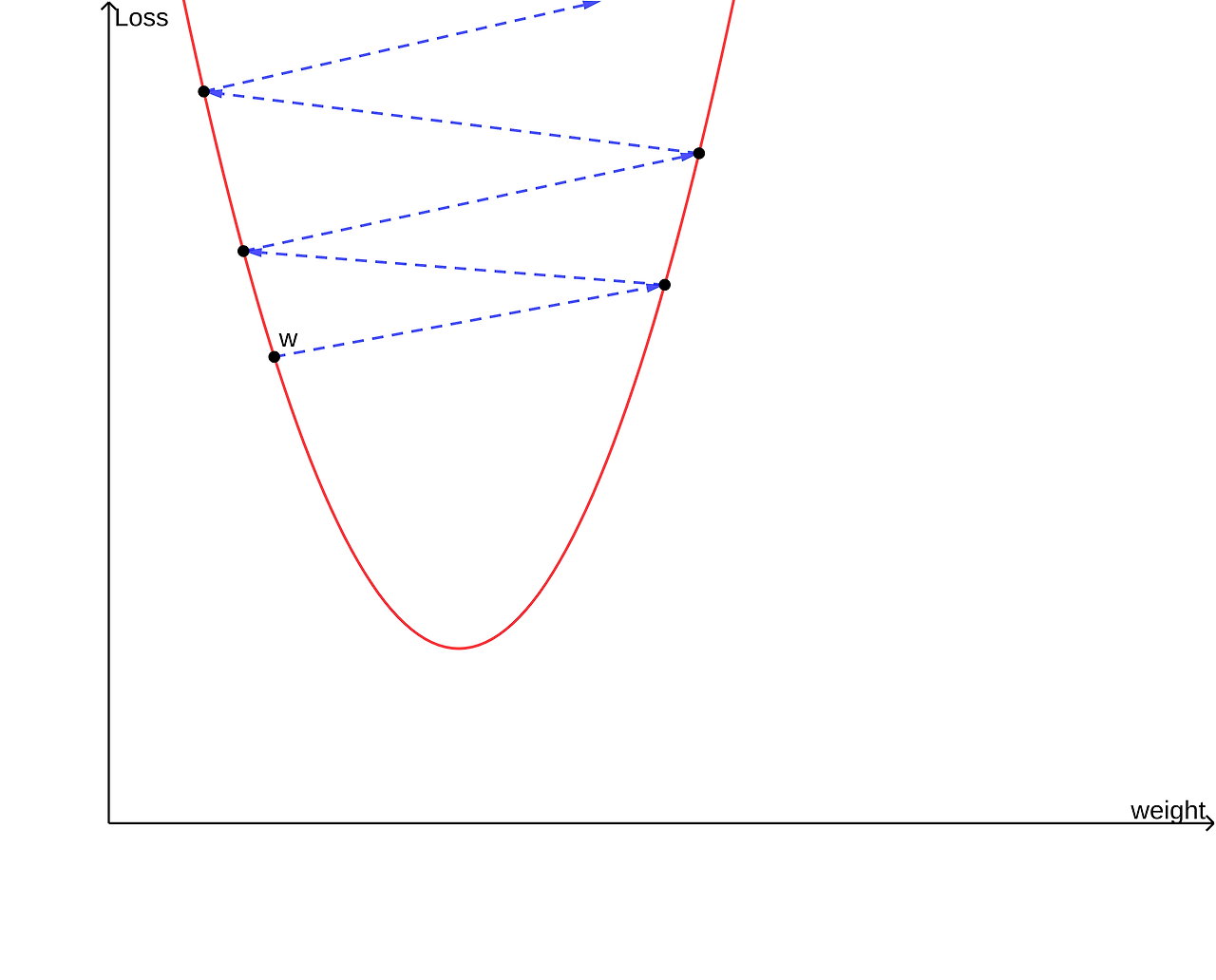
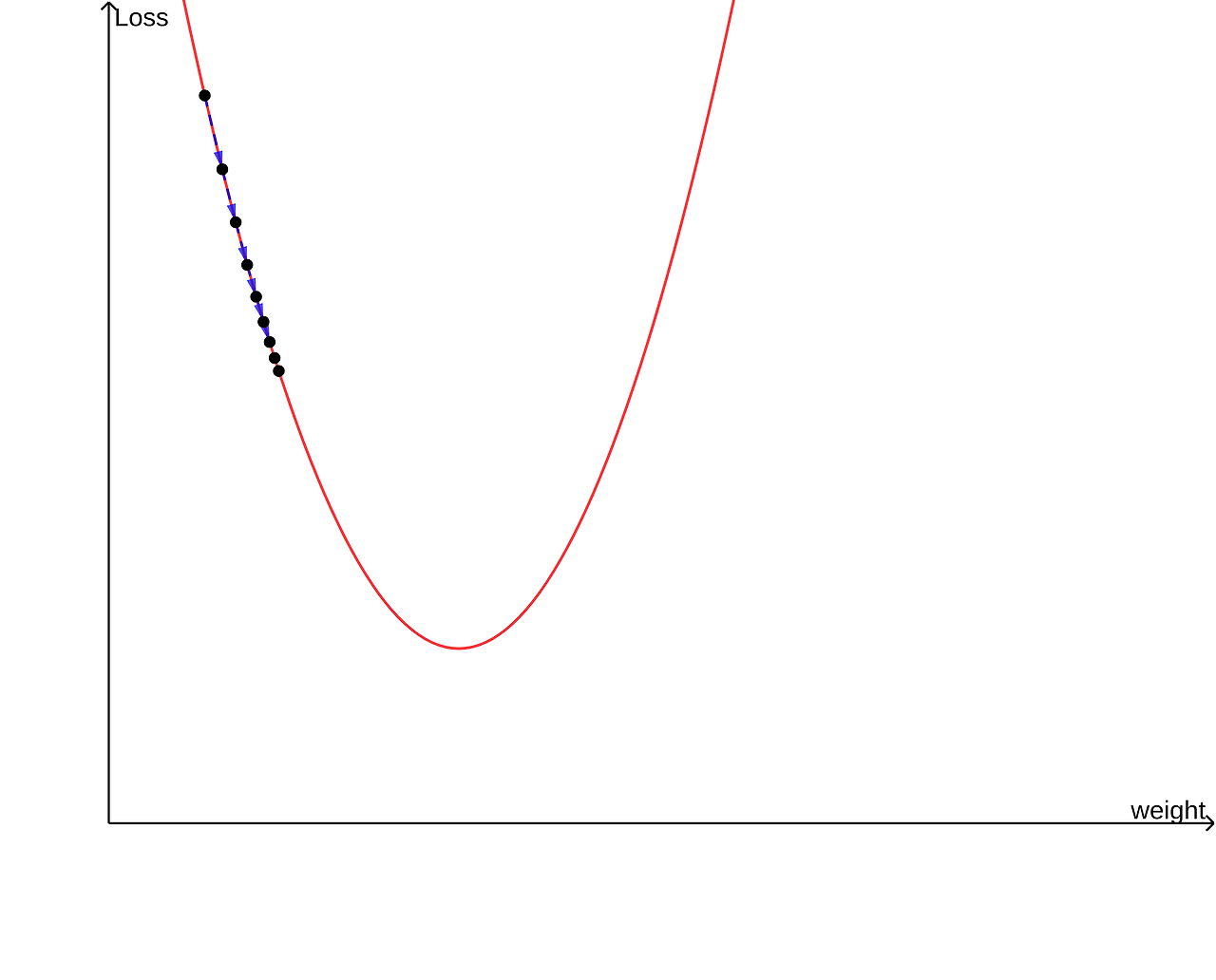
위 두 그래프는 각각 학습률이 매우 큰 경우와 매우 작은 경우다.
weight와 더불어 bias도 같은 방법으로 조정한다.

*손실함수를 미분해서 0이되는 값인 극솟값을 처음부터 찾지 않고 미분계수의 정의를 이용하여 근사하는 이유?
-> 대부분의 모델은 많은 가중치를 갖고 있는데 이런 경우 많은 손실함수들이 closed form이 아니거나 도함수를 구하는 계산이 복잡/불가능할 수 있기 때문
3) Gradient Descent의 한계
Gradient Descent의 한계는 기본적으로 기울기를 이용하여 weight를 업데이트하기 때문에 발생한다.
3-1) 많은 연산량과 컴퓨터 자원 소모
Gradient Descent는 데이터 하나가 모델을 지날 때마다 weight을 한 번씩 업데이트 한다. 가중치가 많은 모델의 경우 모든 가중치에 대해 연산을 진행해야 하므로 많은 연산량이 요구된다. 또한 모델을 학습시킬 때 많은 데이터를 넣기 때문에 이 또한 많은 연산량을 요구하며 많은 컴퓨터 자원을 소모하게 된다. 모델을 평가할 때 정확도 뿐만 아니라 연산량, 학습시간, 메모리 소비량 등도 평가 요소가 되므로 이는 한계점이 될 수 있다.
3-2) Local Minima 문제

우리는 손실함수가 global minimum(전역 최솟값)을 갖는 점의 w값을 찾아야 한다. 하지만 우리가 시작하는 점이 위의 노란점인 경우 전역 최솟값으로 다가오는 와중에 지역 극솟값에 수렴해버릴 가능성이 있다. 지역 극솟값에서의 기울기 또한 0이므로 더이상 다가오지 않고 지역 극솟값에 갇혀 더이상 업데이트되지 못할 수 있다는 것이다.
*Local Minima에 대한 새로운 시각 (https://darkpgmr.tistory.com/148)
-> 2014년에 발표된 논문에 대해 다룬 글. Local Minimum이 형성되기 위해서는 함수의 변화가 모든 축의 방향으로 오목해야 하는데, high dimensional 공간에서는 사실상 발생하기 어려움. 그렇기 때문에 이런 공간에서 발생하는 critical point(일차 미분이 0인 점)는 대부분이 saddle point(어느 방향에서 보면 극댓값이지만 다른 방향에서 보면 극솟값이 되는 점)이며 만약 saddle point가 아니라면 global minimum이거나 이와 유사한 수준의 local minima라는 것.
3-3) Plateau 현상
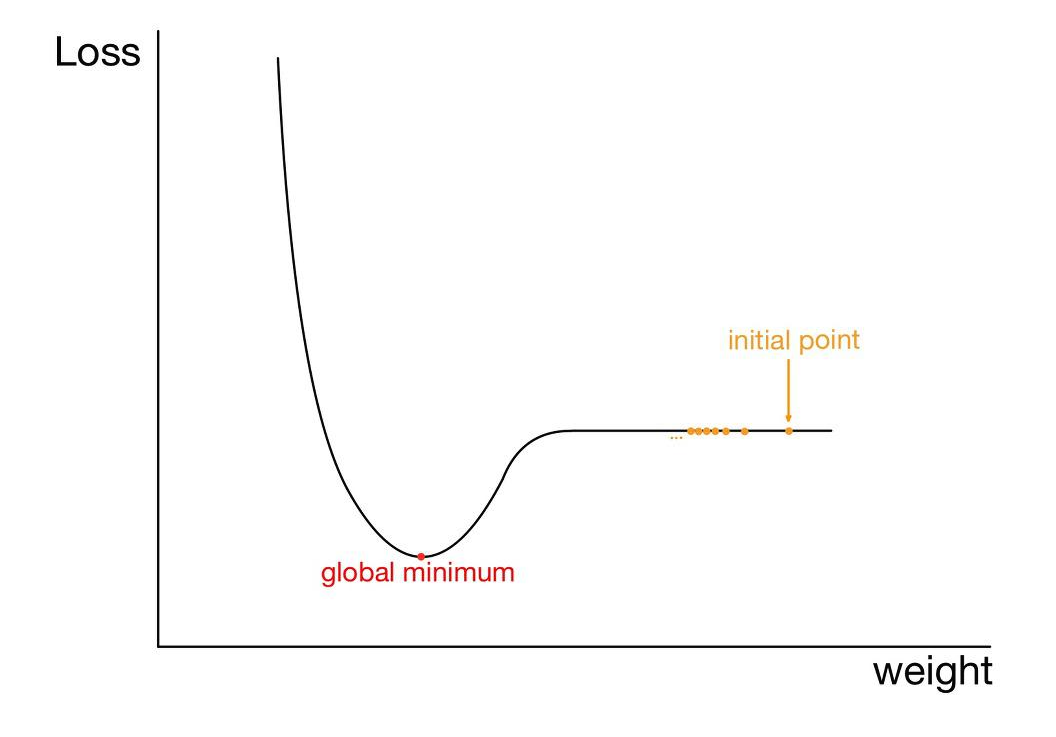
위의 시작점처럼 평탄한 지역에서는 기울기가 0에 수렴하므로 가중치가 업데이트되지 못할 수 있다.
3-4) Oscillation 문제
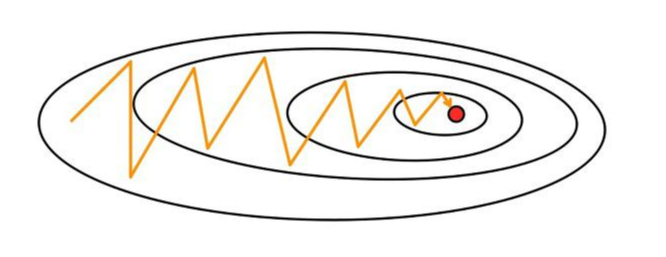
경사 하강법은 시작 지점에서 최적값의 방향으로 수렴하는 것이 아닌, 기울기를 따라 조정되며 수렴한다. 만약 가중치들이 손실 함수에 미치는 영향이 상이하다면 위 그림처럼 크게 진동하며 최적값에 느리게 수렴할 수 있다. 이를 Oscillation(진동) 현상이라고 한다.
진동폭이 크다는 건 가중치가 불안정하게 수렴한다는 것이고, step size(이동 거리)가 크다면 최적값에 수렴하지 않고 발산해버릴 가능성도 있다. 그러므로 가중치가 업데이트될 때 진동폭을 최대한 작게 하는 것도 고려해야 한다.
4) Stochastic Gradient Descent, 확률적 경사 하강법
*batch, epoch, iteration 용어 정리
- batch: 모델의 가중치를 한 번 업데이트할 때 사용하는 데이터들의 집합
- batch size: batch의 크기, ~데이터들의 크기
- epoch: 전체 데이터셋을 이용하여 학습한 횟수
- iteration: 1 epoch에 필요한 batch의 개수
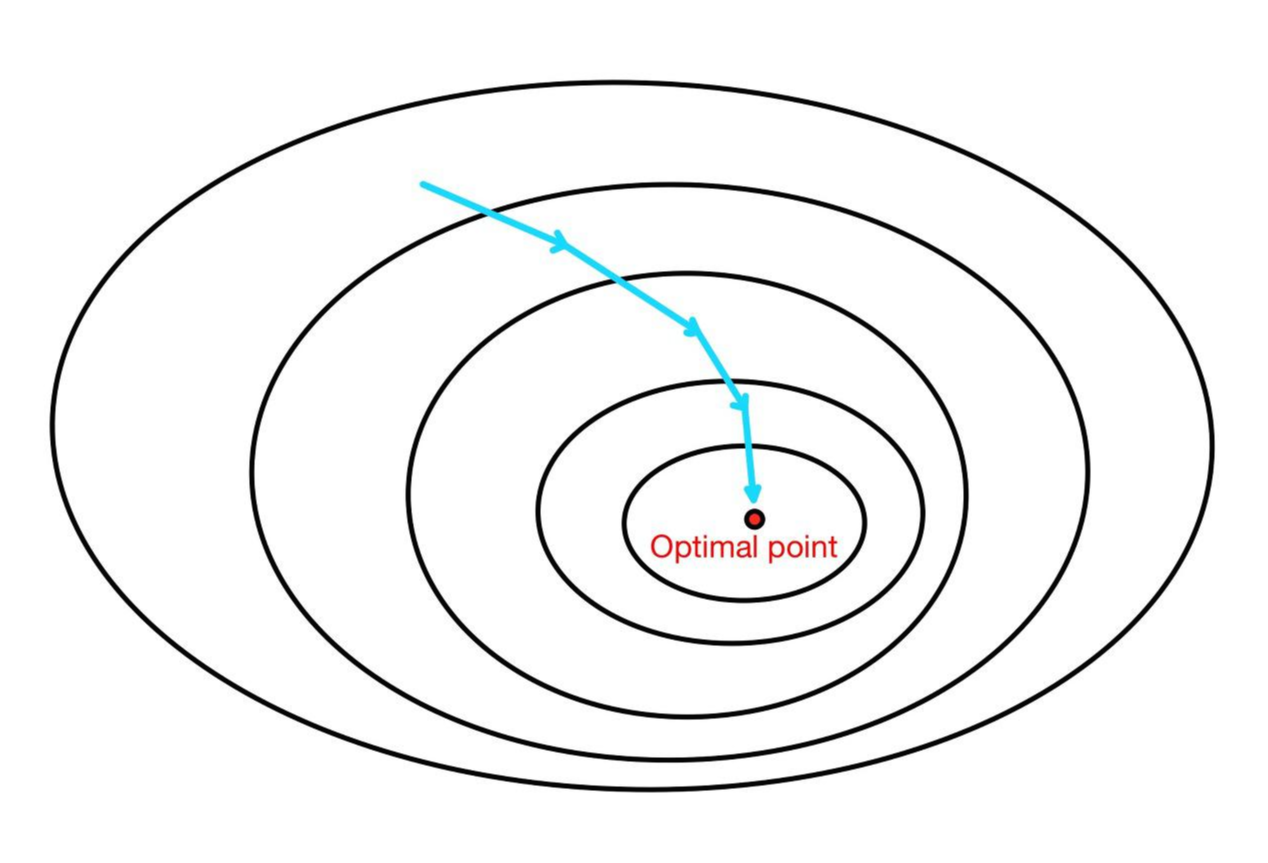
경사 하강법은 한 번의 가중치 업데이트에 모든 데이터를 사용하므로 batch size가 전체 데이터의 수라고 할 수 있다. 그러므로 경사 하강법은 Batch Gradient Descent라고 불리기도 한다.
경사 하강법은 모든 데이터를 이용하여 기울기를 계산하고, 가중치를 업데이트한다. 이는 손실 함수가 최솟값에 수렴할 수 있도록 해주지만 데이터가 많은 경우 연산량이 많고 메모리 소모가 심하며 학습 시간이 증가하여 모델의 성능을 하락시킬 수 있다.
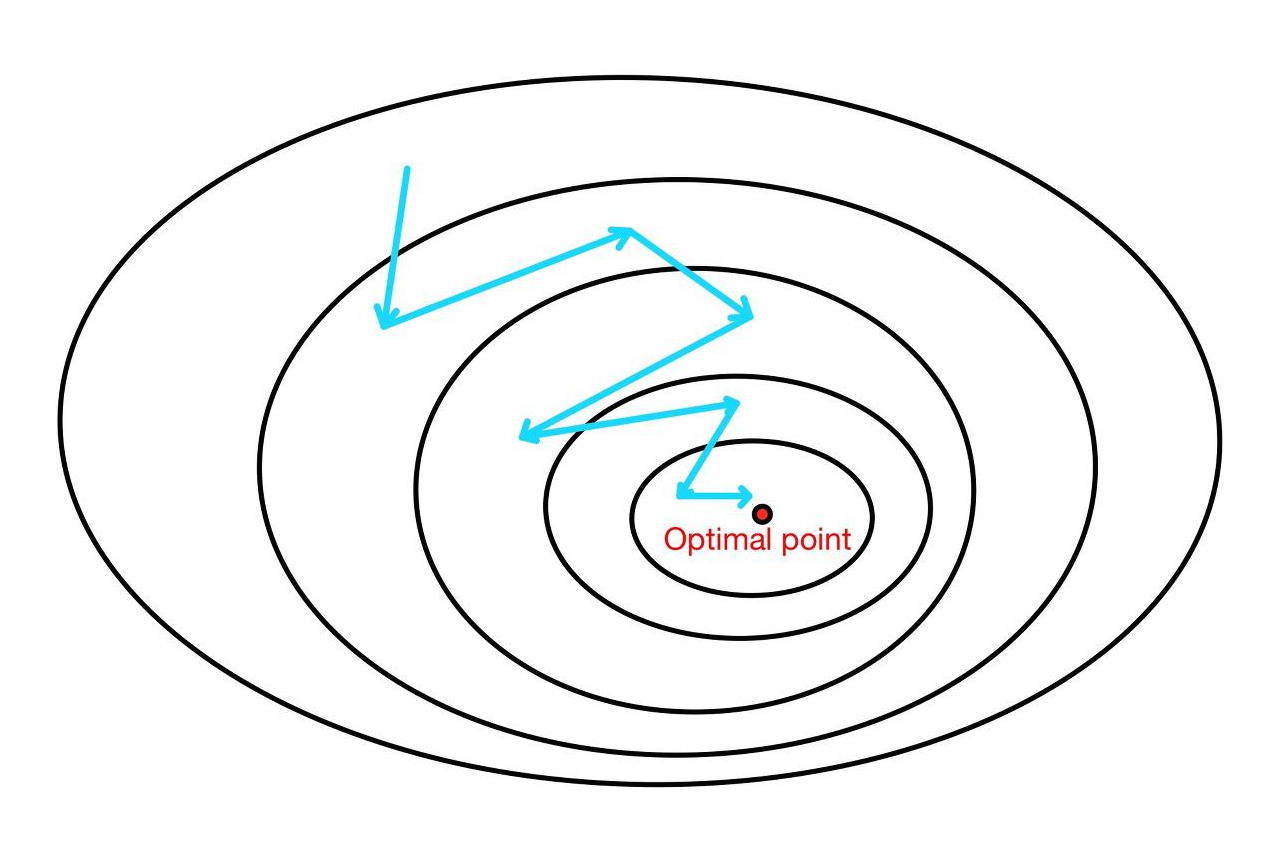
이에 대한 대안으로 나온 Stochastic Gradient Descent는 이름 그대로 확률적으로 데이터를 뽑아 하나의 데이터로 가중치들을 업데이트 해나가는 방법이다.(batch의 크기가 1이라는 것) 이는 연산량이 GD보다 적기 때문에 빠른 수렴 속도를 보이고 메모리 소비량도 적다. 하지만 한 번의 반복에 하나의 데이터만 이용하기 떄문에 수렴하지 않을 가능성 또한 존재하므로 수렴 안정성이 낮고 진폭이 매우 크다.
5) Mini-batch Gradient Descent
mini-batch gradient descent란, 전체 학습 데이터를 mini batch로 나누어 경사 하강법을 진행하는 것을 말한다. BGD(GD)보다 연산량이 적고, SGD보다 수렴성 안정이 보장된다는 장점이 있다.
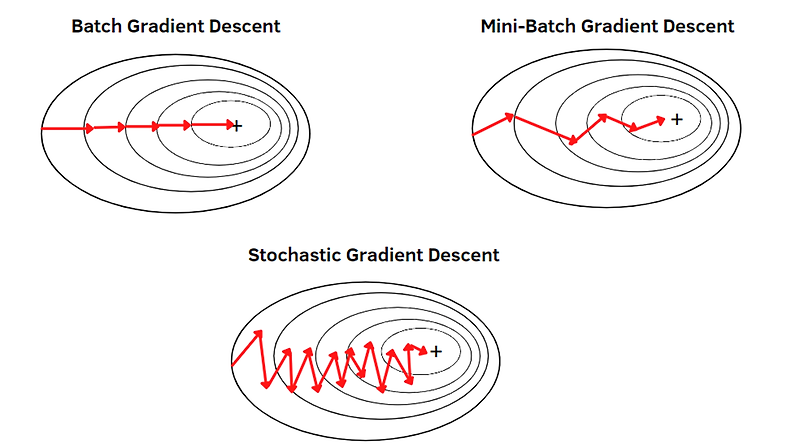
*머신러닝에서 "SGD를 이용한다"라고 하면 대부분 "미니배치 경사 하강법을 사용한다"라고 이해해도 된다.(SGD는 batch size가 1로, 단순하게~)
정보: https://yhyun225.tistory.com/5?category=964332
https://yhyun225.tistory.com/6?category=964332
https://yhyun225.tistory.com/7?category=964332
6) SGDClassifier
*scikit-learn 라이브러리에 있는 함수로, 분류 문제를 다루는 SGDClassifier 외에도 회귀 문제를 다루는 SGDRegressor도 있다.
6-1) 모델 파라미터
class sklearn.linear_model.SGDClassifier(loss='hinge', *, penalty='l2', alpha=0.0001, l1_ratio=0.15, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, epsilon=0.1, n_jobs=None, random_state=None, learning_rate='optimal', eta0=0.0, power_t=0.5, early_stopping=False, validation_fraction=0.1, n_iter_no_change=5, class_weight=None, warm_start=False, average=False)
6-2) 모델 특징
- 선형 분류 모델(Logistic Regression, SVM 등)에 SGD를 적용
- SGD의 특징을 가짐
- 다양한 손실 함수(Logistic Loss, Hinge Loss 등)를 사용할 수 있어 여러 종류의 분류 문제에 적용 가능함
*loss
hinge: SVM에서 사용되는 손실 함수로 이진 분류 문제에서 잘 활용됨
log: Logistic Regression에서 사용되는 손실 함수로, 마찬가지로 이진 분류 문제에서 잘 활용됨
6-3) 왜 binary classifier로 작동하는가?
SGDClassifier는 기본적으로 로지스틱 회귀 또는 서포트 벡터 머신(SVM)과 같은 선형 분류 알고리즘을 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 사용하여 학습시킨다. 여기서 이진 분류기로 작동하는 이유는 y_train_5가 이진 레이블(0과 1)로 되어 있기 때문
- 0: 해당 숫자가 5가 아님
- 1: 해당 숫자가 5임
출처: Hands-On Machine Learning by Aurelien Geron
